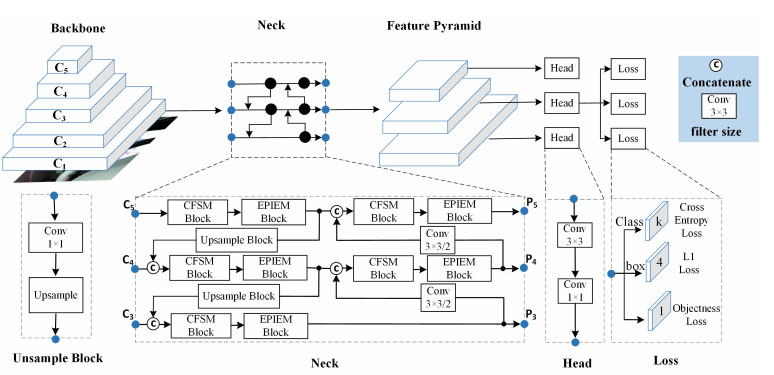
Real-time and efficient driver distraction detection is of great importance for road traffic safety and assisted driving. The design of a real-time lightweight model is crucial for in-vehicle edge devices that have limited computational resources. However, most existing approaches focus on lighter and more efficient architectures, ignoring the cost of losing tiny target detection performance that comes with lightweighting. In this paper, we present MTNet, a lightweight detector for driver distraction detection scenarios. MTNet consists of a multidimensional adaptive feature extraction block, a lightweight feature fusion block and utilizes the IoU-NWD weighted loss function, all while considering the accuracy gain of tiny target detection. In the feature extraction component, a lightweight backbone network is employed in conjunction with four attention mechanisms strategically integrated across the kernel space. This approach enhances the performance limits of the lightweight network. The lightweight feature fusion module is designed to reduce computational complexity and memory access. The interaction of channel information is improved through the use of lightweight arithmetic techniques. Additionally, CFSM module and EPIEM module are employed to minimize redundant feature map computations and strike a better balance between model weights and accuracy. Finally, the IoU-NWD weighted loss function is formulated to enable more effective detection of tiny targets. We assess the performance of the proposed method on the LDDB benchmark. The experimental results demonstrate that our proposed method outperforms multiple advanced detection models.
Citation: Zhiqin Zhu, Shaowen Wang, Shuangshuang Gu, Yuanyuan Li, Jiahan Li, Linhong Shuai, Guanqiu Qi. Driver distraction detection based on lightweight networks and tiny object detection[J]. Mathematical Biosciences and Engineering, 2023, 20(10): 18248-18266. doi: 10.3934/mbe.2023811
Real-time and efficient driver distraction detection is of great importance for road traffic safety and assisted driving. The design of a real-time lightweight model is crucial for in-vehicle edge devices that have limited computational resources. However, most existing approaches focus on lighter and more efficient architectures, ignoring the cost of losing tiny target detection performance that comes with lightweighting. In this paper, we present MTNet, a lightweight detector for driver distraction detection scenarios. MTNet consists of a multidimensional adaptive feature extraction block, a lightweight feature fusion block and utilizes the IoU-NWD weighted loss function, all while considering the accuracy gain of tiny target detection. In the feature extraction component, a lightweight backbone network is employed in conjunction with four attention mechanisms strategically integrated across the kernel space. This approach enhances the performance limits of the lightweight network. The lightweight feature fusion module is designed to reduce computational complexity and memory access. The interaction of channel information is improved through the use of lightweight arithmetic techniques. Additionally, CFSM module and EPIEM module are employed to minimize redundant feature map computations and strike a better balance between model weights and accuracy. Finally, the IoU-NWD weighted loss function is formulated to enable more effective detection of tiny targets. We assess the performance of the proposed method on the LDDB benchmark. The experimental results demonstrate that our proposed method outperforms multiple advanced detection models.

| [1] |
A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, Adv. Neural Inform. Process. Syst., 6 (2017), 84–90. https://doi.org/10.1145/3065386 doi: 10.1145/3065386

|
| [2] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [3] | J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You only look once: Unified, real-time object detection, preprint, arXiv: 1506.02640. |
| [4] | J. Redmon, A. Farhadi, Yolov3: An incremental improvement, preprint, arXiv: 1804.02767. |
| [5] | Ultralytics, Yolov5, 2021. Available from: https://github.com/ultralytics/yolov5. |
| [6] |
A. Misra, S. Samuel, S. Cao, K. Shariatmadari, Detection of driver cognitive distraction using machine learning methods, IEEE Access, 11 (2023), 18000–18012. https://doi.org/10.1109/ACCESS.2023.3245122 doi: 10.1109/ACCESS.2023.3245122
|
| [7] |
S. M. Iranmanesh, H. N. Mahjoub, H. Kazemi, Y. P. Fallah, An adaptive forward collision warning framework design based on driver distraction, IEEE Trans. Intell. Trans. Syst., 19 (2018), 3925–3934. https://doi.org/10.1109/TITS.2018.2791437 doi: 10.1109/TITS.2018.2791437
|
| [8] | A. Jamsheed V., B. Janet, U. S. Reddy, Real time detection of driver distraction using cnn, in 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), (2020), 185–191. https://doi.org/10.1109/ICSSIT48917.2020.9214233 |
| [9] |
C. Huang, X. Wang, J. Cao, S. Wang, Y. Zhang, Hcf: A hybrid cnn framework for behavior detection of distracted drivers, IEEE access, 8 (2020), 109335–109349. https://doi.org/10.1109/ACCESS.2020.3001159 doi: 10.1109/ACCESS.2020.3001159
|
| [10] | C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethinking the inception architecture for computer vision, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2016), 2818–2826. https://doi.org/10.1109/CVPR.2016.308 |
| [11] | F. Chollet, Xception: Deep learning with depthwise separable convolutions, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2017), 1251–1258. https://doi.org/10.1109/CVPR.2017.195 |
| [12] |
F. Sajid, A. R. Javed, A. Basharat, N. Kryvinska, A. Afzal, M. Rizwan, An efficient deep learning framework for distracted driver detection, IEEE Access, 9 (2021), 169270–169280. https://doi.org/10.1109/ACCESS.2021.3138137 doi: 10.1109/ACCESS.2021.3138137
|
| [13] |
D. L. Nguyen, M. D. Putro, K. H. Jo, Driver behaviors recognizer based on light-weight convolutional neural network architecture and attention mechanism, IEEE Access, 10 (2022), 71019–71029. https://doi.org/10.1109/ACCESS.2022.3187185 doi: 10.1109/ACCESS.2022.3187185
|
| [14] | F. N. Iandola, S. Han, M. W. Moskewicz, K. Ashraf, W. J. Dally, K. Keutzer, Squeezenet: Alexnet-level accuracy with 50x fewer parameters and¡ 0.5 mb model size, preprint, arXiv: 1602.07360. |
| [15] | A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, et al., Mobilenets: Efficient convolutional neural networks for mobile vision applications, preprint, arXiv: 1704.04861. |
| [16] | M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L. C. Chen, Mobilenetv2: Inverted residuals and linear bottlenecks, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2018), 4510–4520. https://doi.org/10.1109/CVPR.2018.00474 |
| [17] | A. Howard, M. Sandler, G. Chu, L. C. Chen, B. Chen, M. Tan, et al., Searching for mobilenetv3, in Proceedings of the IEEE/CVF international conference on computer vision, (2019), 1314–1324. https://doi.org/10.1109/ICCV.2019.00140 |
| [18] | X. Zhang, X. Zhou, M. Lin, J. Sun, Shufflenet: An extremely efficient convolutional neural network for mobile devices, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2018), 6848–6856. https://doi.org/10.1109/CVPR.2018.00716 |
| [19] | N. Ma, X. Zhang, H. T. Zheng, J. Sun, Shufflenet v2: Practical guidelines for efficient cnn architecture design, in Proceedings of the European conference on computer vision (ECCV), (2018), 116–131. https://doi.org/10.1007/978-3-030-01264-9 |
| [20] | C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, et al., Going deeper with convolutions, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2015), 1–9. https://doi.org/10.1109/CVPR.2015.7298594 |
| [21] | S. Ioffe, C. Szegedy, Batch normalization: Accelerating deep network training by reducing internal covariate shift, in International conference on machine learning, (2015), 448–456. |
| [22] | C. Szegedy, S. Ioffe, V. Vanhoucke, A. Alemi, Inception-v4, inception-resnet and the impact of residual connections on learning, preprint, arXiv: 1602.07261. |
| [23] | M. Tan, Q. Le, Efficientnet: Rethinking model scaling for convolutional neural networks, in International conference on machine learning, (2019), 6105–6114. |
| [24] | M. Tan, Q. Le, Efficientnetv2: Smaller models and faster training, in International conference on machine learning, (2021), 10096–10106. |
| [25] | K. Han, Y. Wang, Q. Tian, J. Guo, C. Xu, C. Xu, Ghostnet: More features from cheap operations, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, (2020), 1580–1589. https://doi.org/10.1109/CVPR42600.2020.00165 |
| [26] | J. He, S. Erfani, X. Ma, J. Bailey, Y. Chi, X. Hua, Alpha-iou: A family of power intersection over union losses for bounding box regression, preprint, arXiv: 2110.13675. |
| [27] |
C. Deng, M. Wang, L. Liu, Y. Liu, Y. Jiang, Extended feature pyramid network for small object detection, IEEE Trans. Multimedia, 24 (2021), 1968–1979. https://doi.org/10.1109/TMM.2021.3074273 doi: 10.1109/TMM.2021.3074273
|
| [28] | X. Yang, J. Yang, J. Yan, Y. Zhang, T. Zhang, Z. Guo, et al., Scrdet: Towards more robust detection for small, cluttered and rotated objects, in Proceedings of the IEEE/CVF international conference on computer vision, (2019), 8232–8241. https://doi.org/10.1109/ICCV.2019.00832 |
| [29] | H. Li, J. Li, H. Wei, Z. Liu, Z. Zhan, Q. Ren, Slim-neck by gsconv: A better design paradigm of detector architectures for autonomous vehicles, preprint, arXiv: 2206.02424. |
| [30] | J. Chen, S. h. Kao, H. He, W. Zhuo, S. Wen, C. H. Lee, et al., Run, don't walk: Chasing higher flops for faster neural networks, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2023), 12021–12031. https://doi.org/10.1109/CVPR52729.2023.01157 |
| [31] |
V. M. Panaretos, Y. Zemel, Statistical aspects of wasserstein distances, Annual Rev. Stat. Appl., 6 (2019), 405–431. https://doi.org/10.1146/annurev-statistics-030718-104938 doi: 10.1146/annurev-statistics-030718-104938
|
| [32] | J. Wang, C. Xu, W. Yang, L. Yu, A normalized gaussian wasserstein distance for tiny object detection, preprint, arXiv: 2110.13389. |
| [33] | S. Farm, State farm distracted driver detection, Technical report, 2016. Available from: : https://www.kaggle.com//state-farm-distracted-driver-detection. |
| [34] | Z. Zhu, D. Liang, S. Zhang, X. Huang, B. Li, S. Hu, Traffic-sign detection and classification in the wild, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2016), 2110–2118. https://doi.org/10.1109/CVPR.2016.232 |
| [35] | Y. Li, P. Xu, Z. Zhu, X. Huang, G. Qi, Real-time driver distraction detection using lightweight convolution neural network with cheap multi-scale features fusion block, in Proceedings of 2021 Chinese Intelligent Systems Conference: Volume II, Springer, (2022), 232–240. |
| [36] | M. Tan, Q. V. Le, Mixconv: Mixed depthwise convolutional kernels, preprint, arXiv: 1907.09595. |
| [37] | A. Howard, C. Zhu, J. Chen, X. Wang, W. Wu, Y. He, et al., Mobilenext: Rethinking bottleneck structure for efficient mobile network design, preprint, arXiv: 2003.10888. |
| [38] | Z. Zhu, Z. Yao, G. Qi, N. Mazur, P. Yang, B. Cong, Associative learning mechanism for drug-target interaction prediction, CAAI Trans. Intell. Technol., (2023). https://doi.org/10.1049/cit2.12194 |
| [39] |
Z. Zhu, X. He, G. Qi, Y. Li, B. Cong, Y. Liu, Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal mri, Inform. Fusion, 91 (2023), 376–387. https://doi.org/10.1016/j.inffus.2022.10.022 doi: 10.1016/j.inffus.2022.10.022
|













Figures(14) / Tables(3)

Zhiqin Zhu, Shaowen Wang, Shuangshuang Gu, Yuanyuan Li, Jiahan Li, Linhong Shuai, Guanqiu Qi. Driver distraction detection based on lightweight networks and tiny object detection[J]. Mathematical Biosciences and Engineering, 2023, 20(10): 18248-18266. doi: 10.3934/mbe.2023811







 DownLoad:
DownLoad: