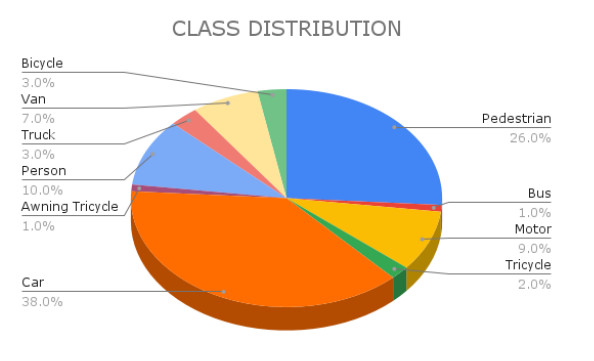
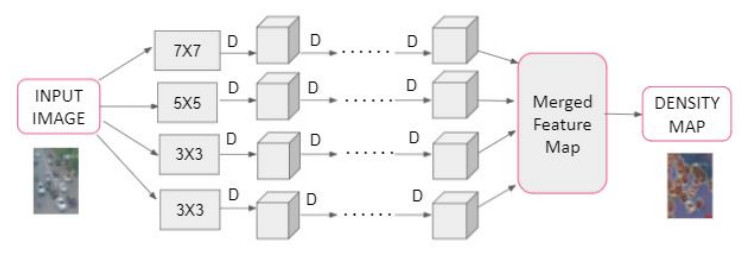
Unmanned Aerial Vehicles have proven to be helpful in domains like defence and agriculture and will play a vital role in implementing smart cities in the upcoming years. Object detection is an essential feature in any such application. This work addresses the challenges of object detection in aerial images like improving the accuracy of small and dense object detection, handling the class-imbalance problem, and using contextual information to boost the performance. We have used a density map-based approach on the drone dataset VisDrone-2019 accompanied with increased receptive field architecture such that it can detect small objects properly. Further, to address the class imbalance problem, we have picked out the images with classes occurring fewer times and augmented them back into the dataset with rotations. Subsequently, we have used RetinaNet with adjusted anchor parameters instead of other conventional detectors to detect aerial imagery objects accurately and efficiently. The performance of the proposed three step pipeline of implementing object detection in aerial images is a significant improvement over the existing methods. Future work may include improvement in the computations of the proposed method, and minimising the effect of perspective distortions and occlusions.
Citation: Vishal Pandey, Khushboo Anand, Anmol Kalra, Anmol Gupta, Partha Pratim Roy, Byung-Gyu Kim. Enhancing object detection in aerial images[J]. Mathematical Biosciences and Engineering, 2022, 19(8): 7920-7932. doi: 10.3934/mbe.2022370
Unmanned Aerial Vehicles have proven to be helpful in domains like defence and agriculture and will play a vital role in implementing smart cities in the upcoming years. Object detection is an essential feature in any such application. This work addresses the challenges of object detection in aerial images like improving the accuracy of small and dense object detection, handling the class-imbalance problem, and using contextual information to boost the performance. We have used a density map-based approach on the drone dataset VisDrone-2019 accompanied with increased receptive field architecture such that it can detect small objects properly. Further, to address the class imbalance problem, we have picked out the images with classes occurring fewer times and augmented them back into the dataset with rotations. Subsequently, we have used RetinaNet with adjusted anchor parameters instead of other conventional detectors to detect aerial imagery objects accurately and efficiently. The performance of the proposed three step pipeline of implementing object detection in aerial images is a significant improvement over the existing methods. Future work may include improvement in the computations of the proposed method, and minimising the effect of perspective distortions and occlusions.

| [1] |
S. H. Alsamhi, O. Ma, M. S. Ansari, F. A. Almalki, Survey on collaborative smart drones and internet of things for improving smartness of smart cities, IEEE Access, 7 (2019), 128125–128152. https://doi.org/10.1109/ACCESS.2019.2934998 doi: 10.1109/ACCESS.2019.2934998

|
| [2] | M. A. Khan, B. A. Alvi, A. Safi, I. U. Khan, Drones for good in smart cities: A review, in International Conference on Electrical, Electronics, Computers, Communication, Mechanical and Computing (EECCMC), (2018), 1–6. |
| [3] | R. B. Girshick, Fast R-CNN, in 2015 IEEE International Conference on Computer Vision (ICCV), (2015), 1440–1448. https://doi.org/10.1109/ICCV.2015.169 |
| [4] | K. He, G. Gkioxari, P. Dollár, R. B. Girshick, Mask R-CNN, in 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 2980–2988. https://doi.org/10.1109/ICCV.2017.322 |
| [5] | S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: Towards real-time object detection with region proposal networks, in IEEE Transactions on Pattern Analysis and Machine Intelligence, 39 (2017), 1137–1149. https://doi.org/10.1109/TPAMI.2016.2577031 |
| [6] | J. Redmon, S. Divvala, R. B. Girshick, A. Farhadi, You Only Look Once: Unified, real-time object detection, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 779–788. https://doi.org/10.1109/CVPR.2016.91 |
| [7] | W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. E. Reed, C. Y. Fu, et al., SSD: Single Shot MultiBox Detector, in European Conference on Computer Vision, (2016), 21–37. https://doi.org/10.1007/978-3-319-46448-0_2 |
| [8] | T. Y. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ramanan, et al., Microsoft COCO: Common Objects in Context, in European Conference on Computer Vision, (2014), 740–755. https://doi.org/10.1007/978-3-319-10602-1_48 |
| [9] |
M. Everingham, S. Eslami, L. Gool, C. K. I. Williams, J. Winn, A. Zisserman, The pascal visual object classes challenge: A retrospective, Int. J. Comput. Vision, 111 (2014), 98–136. https://doi.org/10.1007/s11263-014-0733-5 doi: 10.1007/s11263-014-0733-5
|
| [10] |
Y. Zhang, J. Chu, L. Leng, J. Miao, Mask-refined r-cnn: A network for refining object details in instance segmentation, Sensors, 20 (2020), 1010. https://doi.org/10.3390/s20041010 doi: 10.3390/s20041010
|
| [11] |
J. Chu, Z. Guo, L. Leng, Object detection based on multi-layer convolution feature fusion and online hard example mining, IEEE Access, 6 (2018), 19959–19967. https://doi.org/10.1109/ACCESS.2018.2815149 doi: 10.1109/ACCESS.2018.2815149
|
| [12] | A. Geiger, P. Lenz, C. Stiller, R. Urtasun, Vision meets robotics: The kitti dataset, Int. J. Rob. Res., 32 (2013), 1231–1237. https://doi.org/10.1177%2F0278364913491297 |
| [13] | D. Du, Y. Zhang, Z. Wang, Z. Wang, Z. Song, Z. Liu, et al., VisDrone-DET2019: The vision meets drone object detection in image challenge results, in 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), (2019), 213–226. https://doi.org/10.1109/ICCVW.2019.00030 |
| [14] | G. S. Xia, X. Bai, J. Ding, Z. Zhu, S. J. Belongie, J. Luo, et al., DOTA: A large-scale dataset for object detection in aerial images, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 3974–3983. https://doi.org/10.1109/CVPR.2018.00418 |
| [15] |
J. Jiang, F. Liu, W. W. Ng, Q. Tang, W. Wang, Q. V. Pham, Dynamic incremental ensemble fuzzy classifier for data streams in green internet of things, IEEE Trans. Green Commun. Networking, (2022), 1. https://doi.org/10.1109/TGCN.2022.3151716 doi: 10.1109/TGCN.2022.3151716
|
| [16] |
Y. Yang, W. Wang, L. Liu, K. Dev, N. M. F. Qureshi, AoI optimization in the UAV-aided traffic monitoring network under attack: A stackelberg game viewpoint, IEEE Trans. Intell. Transp. Syst., (2022), 1–10. https://doi.org/10.1109/TITS.2022.3157394 doi: 10.1109/TITS.2022.3157394
|
| [17] |
S. Behera, D. P. Dogra, M. K. Bandyopadhyay, P. P. Roy, Crowd characterization in surveillance videos using deep-graph convolutional neural network, IEEE Trans. Cybern., (2021), 1–12. https://doi.org/10.1109/TCYB.2021.3126434 doi: 10.1109/TCYB.2021.3126434
|
| [18] |
K. K. Santhosh, D. P. Dogra, P. P. Roy, Anomaly detection in road traffic using visual surveillance: A survey, ACM Comput. Surv., 53 (2020), 1–26. https://doi.org/10.1145/3417989 doi: 10.1145/3417989
|
| [19] |
N. M. Balamurugan, S. Mohan, M. Adimoolam, A. John, W. Wang, DOA tracking for seamless connectivity in beamformed iot-based drones, Comput. Stand. Interfaces, 79 (2022), 103564. https://doi.org/10.1016/j.csi.2021.103564 doi: 10.1016/j.csi.2021.103564
|
| [20] | P. Keserwani, P. P. Roy, Text region conditional generative adversarial network for text concealment in the wild, in IEEE Transactions on Circuits and Systems for Video Technology, 32 (2022), 3152–3163. https://doi.org/10.1109/TCSVT.2021.3103922 |
| [21] | P. Keserwani, A. Dhankhar, R. Saini, P. P. Roy, Quadbox: Quadrilateral bounding box based scene text detection using vector regression, in IEEE Access, 9 (2021), 36802–36818. https://doi.org/10.1109/ACCESS.2021.3063030 |
| [22] | J. Li, X. Liang, Y. Wei, T. Xu, J. Feng, S. Yan, Perceptual generative adversarial networks for small object detection, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 1951–1959. https://doi.org/10.1109/CVPR.2017.211 |
| [23] | F. O. Unel, B. Özkalayci, C. Çigla, The power of tiling for small object detection, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), (2019), 582–591. https://doi.org/10.1109/CVPRW.2019.00084 |
| [24] | F. Yang, H. Fan, P. Chu, E. Blasch, H. Ling, Clustered object detection in aerial images, in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 8310–8319. https://doi.org/10.1109/ICCV.2019.00840 |
| [25] | H. Wang, Z. Wang, M. Jia, A. Li, T. Feng, W. Zhang, et al., Spatial attention for multi-scale feature refinement for object detection, in 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), (2019), 64–72. https://doi.org/10.1109/ICCVW.2019.00014 |
| [26] | C. Li, T. Yang, S. Zhu, C. Chen, S. Guan, Density map guided object detection in aerial images, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), (2020), 737–746. https://doi.org/10.1109/CVPRW50498.2020.00103 |
| [27] | Y. Zhang, D. Zhou, S. Chen, S. Gao, Y. Ma, Single-image crowd counting via multi-column convolutional neural network, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016) 589–597. https://doi.org/10.1109/CVPR.2016.70 |
| [28] | F. Yu, V. Koltun, Multi-scale context aggregation by dilated convolutions, preprint, arXiv: 1511.07122. |
| [29] | Y. Zhang, T. Shen, Small object detection with multiple receptive fields, in IOP Conference Series: Earth and Environmental Science, 440 (2020), 32093. https://doi.org/10.1088/1755-1315/440/3/032093 |
| [30] | D. Masko, P. Hensman, The impact of imbalanced training data for convolutional neural networks, Degree Project in Computer Science, KTH Royal Institute of Technology, 2015. |
| [31] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, preprint, arXiv: 1409.1556. |
| [32] |
T. Y. Lin, P. Goyal, R. B. Girshick, K. He, P. Dollár, Focal loss for dense object detection, IEEE Trans. Pattern Anal. Mach. Intell., (2017), 2999–3007. https://doi.org/10.1109/ICCV.2017.324 doi: 10.1109/ICCV.2017.324
|
| [33] | K. Chen, J. Wang, J. Pang, Y. Cao, Y. Xiong, X. Li, S. Sun, et al., MMDetection: Open MMLab detection toolbox and benchmark, preprint, arXiv: 1906.07155. |




Figures(6) / Tables(2)

Vishal Pandey, Khushboo Anand, Anmol Kalra, Anmol Gupta, Partha Pratim Roy, Byung-Gyu Kim. Enhancing object detection in aerial images[J]. Mathematical Biosciences and Engineering, 2022, 19(8): 7920-7932. doi: 10.3934/mbe.2022370







 DownLoad:
DownLoad: