Citation: Hao Shen, Xiao-Dong Weng, Du Yang, Lei Wang, Xiu-Heng Liu. Long noncoding RNA MIR22HG is down-regulated in prostate cancer[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1776-1786. doi: 10.3934/mbe.2020093

| [1] | M. R. Pickard, M. Mourtada-Maarabouni, G. T. Williams, Long non-coding RNA GAS5 regulates apoptosis in prostate cancer cell lines, Biochim. Biophys. Acta Mol. Basis Dis., 1832 (2013), 1613-1623. |
| [2] | S. Cao, W. Liu, F. Li, W. Zhao, C. Qin, Decreased expression of lncRNA GAS5 predicts a poor prognosis in cervical cancer, Int. J. Clin. Exp. Pathol., 7 (2014), 6776-6783. |
| [3] | X. H. Liu, M. Sun, F. Q. Nie, Y. B. Ge, E. B. Zhang, D. D. Yin, et al., Lnc RNA HOTAIR functions as a competing endogenous RNA to regulate HER2 expression by sponging miR-331-3p in gastric cancer, Mol. Cancer, 13 (2014), 92. |
| [4] | X. H. Liu, Z. L. Liu, M. Sun, J. Liu, Z. X. Wang, W. De, The long non-coding RNA HOTAIR indicates a poor prognosis and promotes metastasis in non-small cell lung cancer, BMC Cancer, 13 (2013), 464. |
| [5] | D. Chakravarty, A. Sboner, S. S. Nair, E. Giannopoulou, R. Li, S. Hennig, et al., The oestrogen receptor alpha-regulated lncRNA NEAT1 is a critical modulator of prostate cancer, Nat. Commun., 5 (2014), 5383. |
| [6] | C. Sun, S. Li, F. Zhang, Y. Xi, L. Wang, Y. Bi, et al., Long non-coding RNA NEAT1 promotes non-small cell lung cancer progression through regulation of miR-377-3p-E2F3 pathway, Oncotarget, 7 (2016), 51784-51814. |
| [7] | J. Fang, C. C. Sun, C. Gong, Long noncoding RNA XIST acts as an oncogene in non-small cell lung cancer by epigenetically repressing KLF2 expression, Biochem. Biophys. Res. Commun., 478 (2016), 811-817. |
| [8] | N. M. White, S. G. Zhao, J. Zhang, E. B. Rozycki, H. X. Dang, S. D. Mcfadden, et al., Multi-institutional Analysis Shows that Low PCAT-14 Expression Associates with Poor Outcomes in Prostate Cancer, Eur. Urol., 71 (2017), 257-266. |
| [9] | Y. Zhang, S. Pitchiaya, M. Cieslik, Y. S. Niknafs, J. C. Y. Tien, Y. Hosono, et al., Analysis of the androgen receptor-regulated lncRNA landscape identifies a role for ARLNC1 in prostate cancer progression, Nat. Genet., 50 (2018), 814-824. |
| [10] | J. Qin, H. Ning, Y. Zhou, Y. Hu, L. Yang, R. Huang, LncRNA MIR31HG overexpression serves as poor prognostic biomarker and promotes cells proliferation in lung adenocarcinoma, Biomed. Pharmacother., 99 (2018), 363-368. |
| [11] | J. Li, Q. M. Wu, X. Q. Wang, C. Q. Zhang, Long Noncoding RNA miR210HG Sponges miR-503 to Facilitate Osteosarcoma Cell Invasion and Metastasis, DNA Cell Biol., 36 (2017), 1117-1125. |
| [12] | Z. Cui, X. An, J. Li, Q. Liu, W. Liu, LncRNA MIR22HG negatively regulates miR-141-3p to enhance DAPK1 expression and inhibits endometrial carcinoma cells proliferation, Biomed. Pharmacother., 104 (2018), 223-228. |
| [13] | D. Y. Zhang, X. J. Zou, C. H. Cao, T. Zhang, L. Lei, X. L. Qi, et al., Identification and Functional Characterization of Long Non-coding RNA MIR22HG as a Tumor Suppressor for Hepatocellular Carcinoma, Theranostics, 8 (2018), 3751-3765. |
| [14] | U. R. Chandran, C. Ma, R. Dhir, M. Bisceglia, M. Lyons-Weiler, W. Liang, et al., Gene expression profiles of prostate cancer reveal involvement of multiple molecular pathways in the metastatic process, BMC Cancer, 7 (2007), 64. |
| [15] | Y. P. Yu, D. Landsittel, L. Jing, J. Nelson, B. Ren, L. Liu, et al., Gene expression alterations in prostate cancer predicting tumor aggression and preceding development of malignancy, J. Clin. Oncol., 22 (2004), 2790-2799. |
| [16] | M. S. Arredouani, B. Lu, M. Bhasin, M. Eljanne, W. Yue, J. M. Mosquera, et al., Identification of the transcription factor single-minded homologue 2 as a potential biomarker and immunotherapy target in prostate cancer, Clin. Cancer Res., 15 (2009), 5794-5802. |
| [17] | H. Satake, K. Tamura, M. Furihata, T. Anchi, H. Sakoda, C. Kawada, et al., The ubiquitin-like molecule interferon-stimulated gene 15 is overexpressed in human prostate cancer, Oncol. Rep., 23 (2010), 11-16. |
| [18] | J. R. Prensner, W. Chen, M. K. Iyer, Q. Cao, T. Ma, S. Han, et al., PCAT-1, a long noncoding RNA, regulates BRCA2 and controls homologous recombination in cancer, Cancer Res., 74 (2014), 1651-1660. |
| [19] | J. H. Li, S. Liu, H. Zhou, L. H. Qu, J. H. Yang, starBase v2.0: Decoding miRNA-ceRNA, miRNA-ncRNA and protein-RNA interaction networks from large-scale CLIP-Seq data, Nucleic Acids Res., 42 (2014), D92-D97. |
| [20] | J. H. Yang, J. H. Li, P. Shao, H. Zhou, Y. Q. Chen, L. H. Qu, starBase: A database for exploring microRNA-mRNA interaction maps from Argonaute CLIP-Seq and Degradome-Seq data, Nucleic Acids Res., 39 (2011), D202-D209. |
| [21] | X. Filella, E. Fernandez-Galan, R. F. Bonifacio, L. Foj, Emerging biomarkers in the diagnosis of prostate cancer, Pharmgenomics Pers. Med., 11 (2018), 83-94. |
| [22] | B. Yang, X. Tang, Z. Wang, D. Sun, X. Wei, Y. Ding, TUG1 promotes prostate cancer progression by acting as a ceRNA of miR-26a, Biosci. Rep., 38 (2018). |
| [23] | A. Matjasic, M. Tajnik, E. Bostjancic, M. Popovic, B. Matos, D. Glavac, Identifying novel glioma-associated noncoding RNAs by their expression profiles, Int. J. Genomics, 2017 (2017), 2312318. |
| [24] | P. Gu, X. Chen, R. Xie, J. Han, W. Xie, B. Wang, et al., lncRNA HOXD-AS1 Regulates Proliferation and Chemo-Resistance of Castration-Resistant Prostate Cancer via Recruiting WDR5, Mol. Ther., 25 (2017), 1959-1973. |
| [25] | Y. Lu, X. Zhao, Q. Liu, C. Li, R. Graves-Deal, Z. Cao, et al., lncRNA MIR100HG-derived miR-100 and miR-125b mediate cetuximab resistance via Wnt/beta-catenin signaling, Nat. Med., 23 (2017), 1331-1341. |
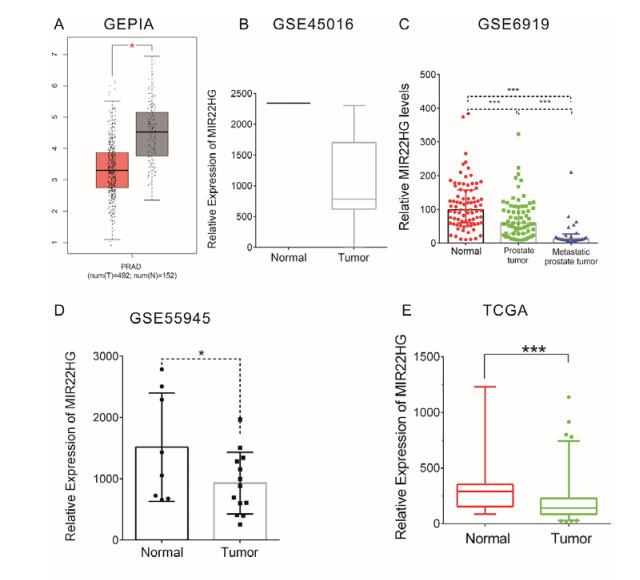
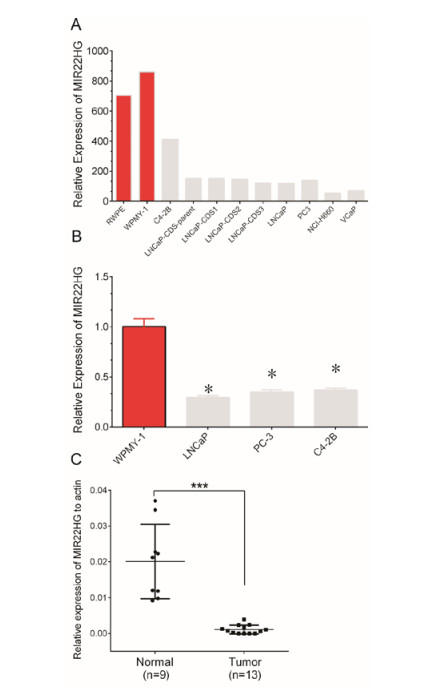
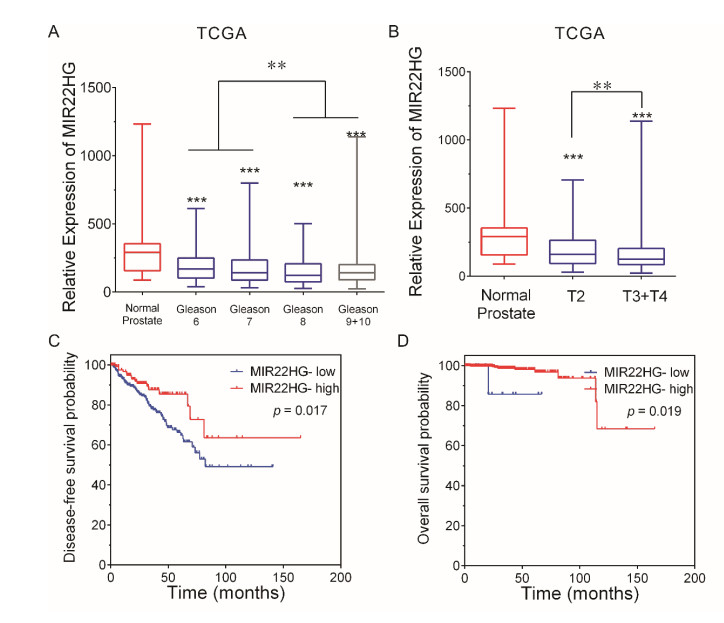
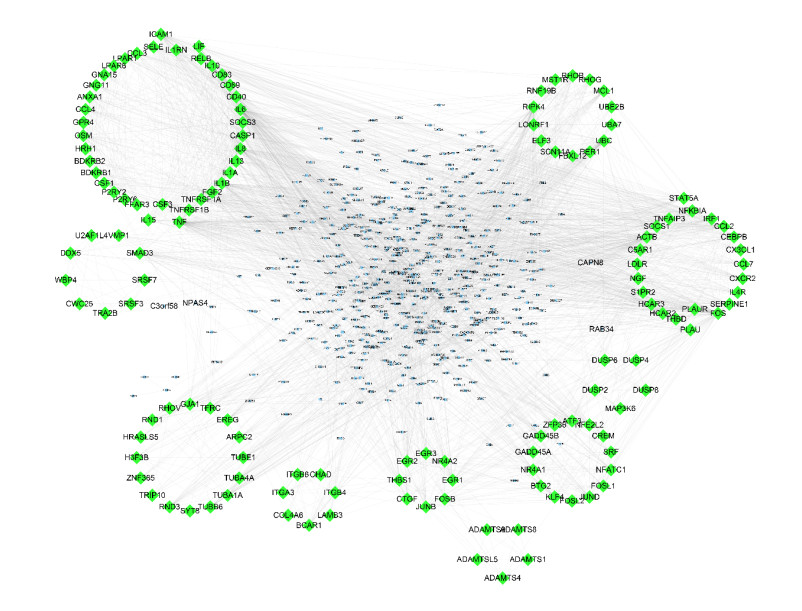
Figures(5)

Hao Shen, Xiao-Dong Weng, Du Yang, Lei Wang, Xiu-Heng Liu. Long noncoding RNA MIR22HG is down-regulated in prostate cancer[J]. Mathematical Biosciences and Engineering, 2020, 17(2): 1776-1786. doi: 10.3934/mbe.2020093







 DownLoad:
DownLoad: