Citation: Yan Li, Yuzhang Zhu, Guiping Dai, Dongjuan Wu, Zhenzhen Gao, Lei Zhang, Yaohua Fan. Screening and validating the core biomarkers in patients with pancreatic ductal adenocarcinoma[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 910-927. doi: 10.3934/mbe.2020048

| [1] | V. Canzoniert, M. Berretta, A. Buonadonna, et al., Solid pseudopapillary tumour of the pancreas, Lancet Oncol., 4 (2003), 225-6. |
| [2] | M. Noë, N. Rezaee, K. Asrani, et al., Immunolabeling of Cleared Human Pancreata Provides Insights into Three-dimensional Pancreatic Anatomy and Pathology, Am. J. Pathol., 188 (2018), 1530-1535. |
| [3] | N. Martinez-Bosch, J. Vinaixa and P. Navarro, Immune Evasion in Pancreatic Cancer: From Mechanisms to Therapy, Cancers, 10 (2018), 6. |
| [4] | C. Napoli, N. Sperandio, R. T. Lawlor, et al., Urine metabolic signature of pancreatic ductal adenocarcinoma by 1H nuclear magnetic resonance: Identification, mapping, and evolution, J. Proteome Res., 11 (2011), 1274-1283. |
| [5] | B. J. Raphael, R. H. Hruban, A. J. Aguirre, et al., Integrated Genomic Characterization of Pancreatic Ductal Adenocarcinoma, Cancer Cell, 32 (2017), 185-203. |
| [6] | V. P. Groot, N. Rezaee, W. C. Wu, et al., Patterns, Timing, and Predictors of Recurrence Following Pancreatectomy for Pancreatic Ductal Adenocarcinoma, Ann. Surg., 267(2018), 936-945. |
| [7] | J. Kim, W. R. Bamlet, A. L. Oberg, et al., Detection of early pancreatic ductal adenocarcinoma with thrombospondin-2 and CA19-9 blood markers, Sci. Trans. Med., 9 (2017), eaah5583. |
| [8] | P. T. Nelson, D. A. Baldwin, L. M. Scearce, et al., Microarray-based, high-throughput gene expression profiling of microRNAs, Nat. Methods, 1 (2004), 155-161. |
| [9] | N. Li, L. Li, and Y. Chen, The Identification of Core Gene Expression Signature in Hepatocellular Carcinoma, Oxid. Med. Cell. Longevity, 2018 (2018), 1-15. |
| [10] | M. A. Fernández, C. Rueda and S. D. Peddada, Identification of a core set of signature cell cycle genes whose relative order of time to peak expression is conserved across species,Nucleic Acids Res., 40 (2012), 2823-2832. |
| [11] | S. Yao, and T. Liu, Analysis of differential gene expression caused by cervical intraepithelial neoplasia based on GEO database, Oncol. Lett., 15 (2018), 8319-8324. |
| [12] | M. D. Young, M. J. Wakefield, J. K. Smyth, et al., Gene ontology analysis for RNA-seq: Accounting for selection bias, Genome Biol., 11 (2010), R14. |
| [13] | E. Altermann, and T. R. Klaenhammer, Pathway Voyager: Pathway mapping using the Kyoto Encyclopedia of Genes and Genomes (KEGG) database, BMC Genomics,6 (2005), 60. |
| [14] | G. Dennis, B. T. Sherman, D. A. Hosack, et al., DAVID: Database for Annotation, Visualization, and Integrated Discovery, Genome Biol., 4 (2003), R60. |
| [15] | Z. Tang, C. Li, B. Kang, et al., GEPIA: A web server for cancer and normal gene expression profiling and interactive analyses, Nucleic Acids Res., 45 (2017), W98-W102. |
| [16] |
H. Feng, J. Chen, H. Wang, et al., Roflumilast reverses polymicrobial sepsis-induced liver damage by inhibiting inflammation in mice, Lab. Invest., 97 (2017), 1008-1019. doi: 10.1038/labinvest.2017.59

|
| [17] | Z. Zhou, Y. Cheng, Y. Jiang, et al., Ten hub genes associated with progression and prognosis of pancreatic carcinoma identified by co-expression analysis, Int. J. Biol. Sci., 14 (2018), 124-136. |
| [18] | A. Adamska, A. Domenichini, and M. Falasca, Pancreatic Ductal Adenocarcinoma: Current and Evolving Therapies, Int. J. Mol. Sci., 18 (2017), 1338. |
| [19] | E. S. Knudsen, P. Vail, U. Balaji, et al., Stratification of Pancreatic Ductal Adenocarcinoma: Combinatorial Genetic, Stromal, and Immunological Markers, Clin. Cancer Res., 23 (2017), 4429-4440. |
| [20] | S. Govindan, T. Cardillo, C. D'Souza, et al., Therapy of human colonic and lung cancer xenografts with SN-38 conjugates of anti-CEACAM5 and anti-EGP-1 humanized monoclonal antibodies, Mol. Cancer Ther., 6 (2007). |
| [21] | R. D. Blumenthal, E. Leon, H. J. Hansen, et al., Expression patterns of CEACAM5 and CEACAM6 in primary and metastatic cancers, BMC Cancer, 7 (2007), 2. |
| [22] | E. Powell, J. Shao, H. M. Picon, et al., A functional genomic screen in vivo identifies CEACAM5 as a clinically relevant driver of breast cancer metastasis, NPJ. Breast Cancer, 4 (2018), 9. |
| [23] | F. Gebauer, D. Wicklein, J. Horst, et al., Carcinoembryonic antigen-related cell adhesion molecules (CEACAM) 1, 5 and 6 as biomarkers in pancreatic cancer, Plos One, 9 (2014), e113023. |
| [24] | S. Bröer and U. Gether, The solute carrier 6 family of transporters, Br. J. Pharmacol., 167 (2012), 256-278. |
| [25] | A. R. Penheiter, S. Erdogan, S. J. Murphy, et al., Transcriptomic and Immunohistochemical Profiling of SLC6A14 in Pancreatic Ductal Adenocarcinoma, Biomed. Res. Int., 2015 (2015), 593572. |
| [26] |
L. Samluk, M. Czeredys, K. Skowronek, et al., Protein kinase C regulates amino acid transporter ATB0,+,Biochem. Biophys. Res. Commun., 422 (2012), 64-69. doi: 10.1016/j.bbrc.2012.04.106
|
| [27] | A. P. Singh, S. Arora, A. Bhardwaj, et al., CXCL12/CXCR4 protein signaling axis induces sonic hedgehog expression in pancreatic cancer cells via extracellular regulated kinase- and Akt kinase-mediated activation of nuclear factor κB: Implications for bidirectional tumor-stromal interactions, J. Biol. Chem., 287 (2012), 39115-39124. |
| [28] | E. L. Heinrich, W. Lee, J. Lu, et al., Chemokine CXCL12 activates dual CXCR4 and CXCR7-mediated signaling pathways in pancreatic cancer cells, J. Transl. Med., 10 (2012), 68. |
| [29] | F. Sieero, C.Biben, L. Martínez-Muñoz, et al., Disrupted cardiac development but normal hematopoiesis in mice deficient in the second CXCL12/SDF-1 receptor, CXCR7, Proc. Natl. Acad. Sci. U. S. A., 104 (2007), 14759-14764. |
| [30] | K. Cui, W. Zhao, C. Wang, et al., The CXCR4-CXCL12 Pathway Facilitates the Progression of Pancreatic Cancer Via Induction of Angiogenesis and Lymphangiogenesis, J. Surg. Res., 171 (2011), 143-150. |
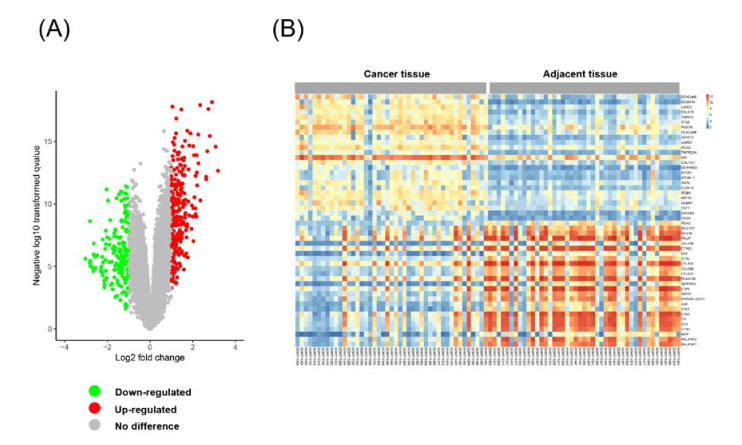
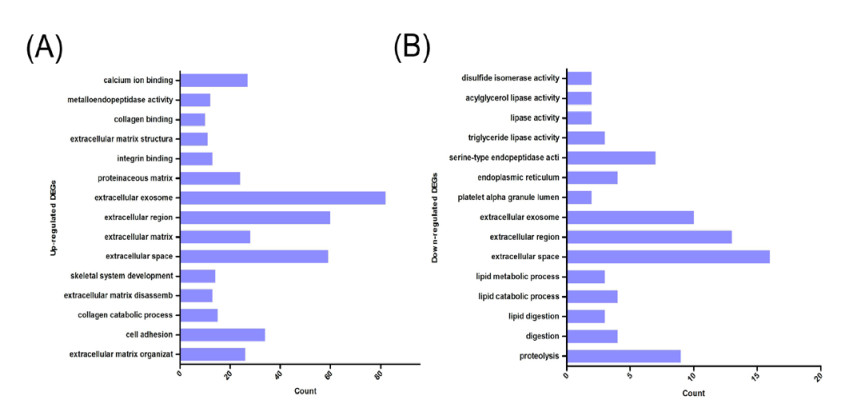
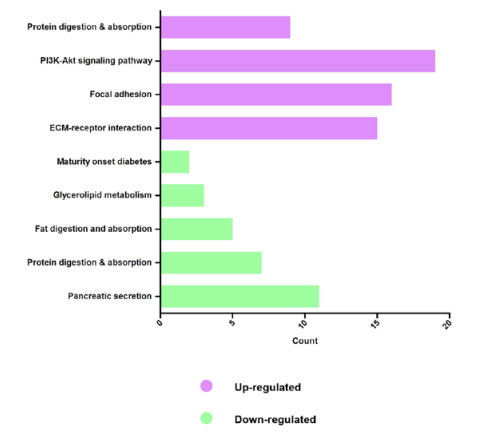
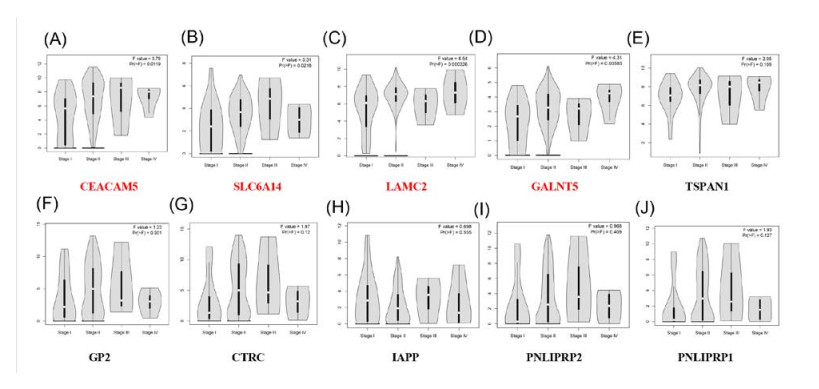
Figures(9) / Tables(3)

Yan Li, Yuzhang Zhu, Guiping Dai, Dongjuan Wu, Zhenzhen Gao, Lei Zhang, Yaohua Fan. Screening and validating the core biomarkers in patients with pancreatic ductal adenocarcinoma[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 910-927. doi: 10.3934/mbe.2020048







 DownLoad:
DownLoad: