Citation: Chengyu Hu, Junyi Cai, Deze Zeng, Xuesong Yan, Wenyin Gong, Ling Wang. Deep reinforcement learning based valve scheduling for pollution isolation in water distribution network[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 105-121. doi: 10.3934/mbe.2020006

| [1] | S. E. Hrudey, Safe drinking water: lessons from recent outbreaks in affluent nations, 2005. |
| [2] | D. J. Kroll, Securing our water supply: protecting a vulnerable resource. PennWell Books, 2006. |
| [3] | S. Rathi and R. Gupta, A simple sensor placement approach for regular monitoring and contamination detection in water distribution networks, KSCE J. Civ. Eng., 20 (2016), 597-608. |
| [4] | C. Hu, G. Ren, C. Liu, et al., A spark-based genetic algorithm for sensor placement in large scale drinking water distribution systems, Cluster Comput., 20 (2017), 1089-1099. |
| [5] | X. Yan, K. Yang, C. Hu, et al., Pollution source positioning in a water supply network based on expensive optimization, Desalin Water Treat, 110 (2018), 308-318. |
| [6] | H. Wang and K. W. Harrison, Improving efficiency of the bayesian approach to water distribution contaminant source characterization with support vector regression, J. Water Res. Pl., 140 (2012), 3-11. |
| [7] | X. Yan, J. Zhao, C. Hu, et al., Multimodal optimization problem in contamination source determination of water supply networks, Swarm Evol. Comput., 2017. |
| [8] | W. Gong, Y. Wang, Z. Cai, et al., Finding multiple roots of nonlinear equation systems via a repulsion-based adaptive differential evolution, IEEE T. Syst. Man Cy., (2018), 1-15. |
| [9] | A. Afshar and M. A. Marino, Multiobjective consequent management of a contaminated network under pressure-deficient conditions, J. Am. Water Works. Ass., 106 2014. |
| [10] | T. Ren, S. Li, X. Zhang, et al., Maximum and minimum solutions for a nonlocal p-laplacian fractional differential system from eco-economical processes, Bound Value Probl., 2017 (2017), 118. |
| [11] | T. Ren, X. H. Lu, Z. Z. Bao, et al., The iterative scheme and the convergence analysis of unique solution for a singular fractional differential equation from the eco-economic complex system's co-evolution process, Complexity, 2019. |
| [12] | A. Preis and A. Ostfeld, Multiobjective contaminant response modeling for water distribution systems security, J. Hydroinform., 10 (2008), 267-274. |
| [13] | A. Afshar and E. Najafi, Consequence management of chemical intrusion in water distribution networks under inexact scenarios, J. Hydroinform., 16 (2014), 178-188. |
| [14] | D. Silver, A. Huang, C. J. Maddison, et al., Mastering the game of go with deep neural networks and tree search, Nature, 529 (2016), 484. |
| [15] | B. G. Kim, Y. Zhang, M. van der Schaar, et al., Dynamic pricing and energy consumption scheduling with reinforcement learning, IEEE T. Smart Grid, 7 (2016), 2187-2198. |
| [16] | M. H. Moghadam and S. M. Babamir, Makespan reduction for dynamic workloads in cluster-based data grids using reinforcement-learning based scheduling, J. Comput. Sci-neth., 2017. |
| [17] | S. Rathi and R. Gupta, A critical review of sensor location methods for contamination detection in water distribution networks, Water Qual. Res. J. Can., 50 (2015), 95-108. |
| [18] | T. P. Lambrou, C. C. Anastasiou, C. G. Panayiotou, et al., A low-cost sensor network for real-time monitoring and contamination detection in drinking water distribution systems, IEEE Sens. J., 14 (2014), 2765-2772. |
| [19] | D. Zeng, L. Gu, L. Lian, et al., On cost-efficient sensor placement for contaminant detection in water distribution systems, IEEE T. Ind. Inform., (2016), 1-1. |
| [20] | L. Perelman and A. Ostfeld, Operation of remote mobile sensors for security of drinking water distribution systems, Water Res., 47 (2013), 4217-4226. |
| [21] | M. R. Bazargan-Lari, An evidential reasoning approach to optimal monitoring of drinking water distribution systems for detecting deliberate contamination events, J. Clean Prod., 78 (2014), 1-14. |
| [22] | A. Poulin, A. Mailhot, P. Grondin, et al., Optimization of operational response to contamination in water networks, in WDSA 2006, (2008), 1-15. |
| [23] | A. Poulin, A. Mailhot, N. Periche, et al., "Planning unidirectional flushing operations as a response to drinking water distribution system contamination," J. Water Res Pl., 136 (2010), 647-657. |
| [24] | M. Gavanelli, M. Nonato, A. Peano, et al., Genetic algorithms for scheduling devices operation in a water distribution system in response to contamination events, 7245 (2012), 124-135. |
| [25] | A. Rasekh and K. Brumbelow, Water as warning medium: Food-grade dye injection for drinking water contamination emergency response, J. Water Res. Pl., 140 (2014), 12-21. |
| [26] | A. Rasekh, M. E. Shafiee, E. Zechman, et al., Sociotechnical risk assessment for water distribution system contamination threats, J. Hydroinform, 16 (2014), 531-549. |
| [27] | A. Rasekh and K. Brumbelow, Drinking water distribution systems contamination management to reduce public health impacts and system service interruptions, Environ. Model Softw., 51 (2014), 12-25. |
| [28] | M. Knowles, D. Baglee and S. Wermter, Reinforcement learning for scheduling of maintenance, in Research and Development in Intelligent Systems XXVII. Springer, (2011), 409-422. |
| [29] | K. L. A. Yau, K. H. Kwong and C. Shen, Reinforcement learning models for scheduling in wireless networks, Front Comput. Sci-Chi., 7 (2013), 754-766. |
| [30] | L. A. Rossman et al., Epanet 2: users manual, 2000. |
| [31] | R. S. Sutton and A. G. Barto, Reinforcement learning: An introduction, in Neural Information Processing Systems, 1999. |
| [32] | V. Mnih, K. Kavukcuoglu, D. Silver, et al., Playing atari with deep reinforcement learning, ArXiv, abs/1312.5602, 2013. |
| [33] | Y. Xuesong, S. Jie, and H. Chengyu, Research on contaminant sources identification of uncertainty water demand using genetic algorithm, Cluster Comput., 20, (2017), 1007-1016. |
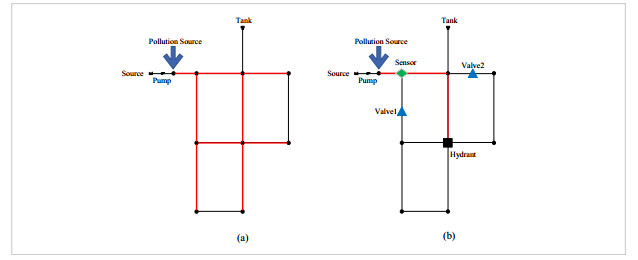
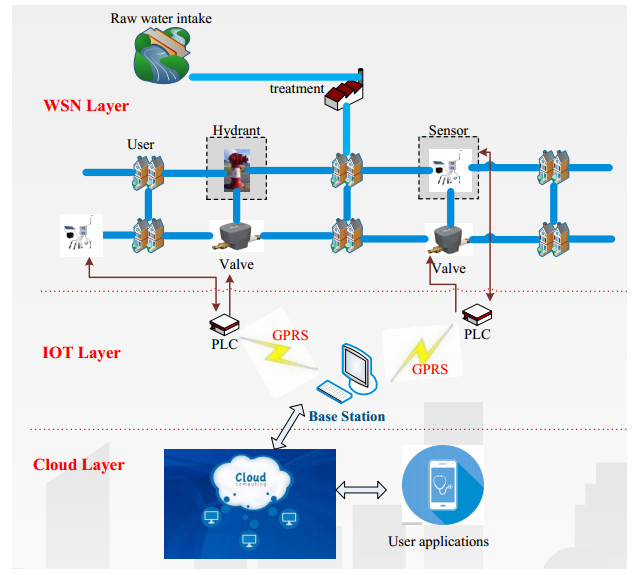
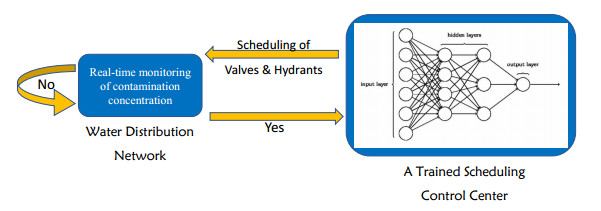
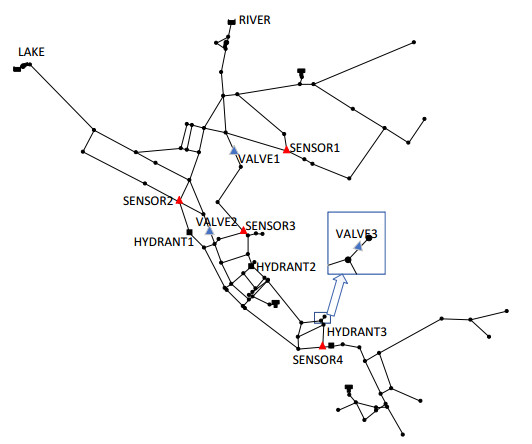
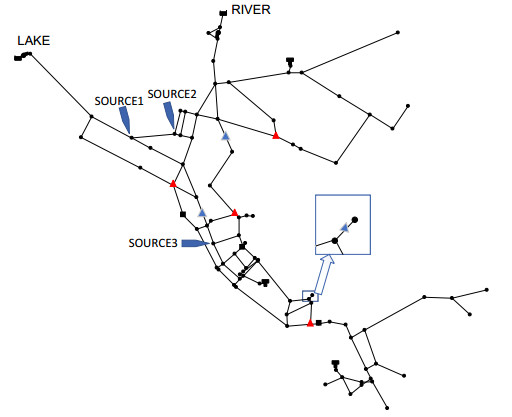

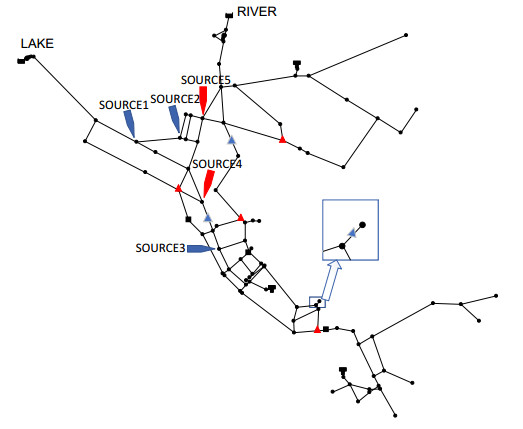
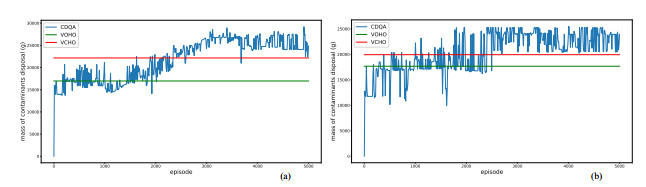
Figures(8) / Tables(3)

Chengyu Hu, Junyi Cai, Deze Zeng, Xuesong Yan, Wenyin Gong, Ling Wang. Deep reinforcement learning based valve scheduling for pollution isolation in water distribution network[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 105-121. doi: 10.3934/mbe.2020006







 DownLoad:
DownLoad: