Citation: Davide De Gaetano. Forecasting volatility using combination across estimation windows: An application to S&P500 stock market index[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 7195-7216. doi: 10.3934/mbe.2019361

| [1] | B. Rossi and A. Inoue, Out-of-sample forecast tests robust to the choice of window size, J. Bus. Econ. Stat., 30 (2012), 432–453. |
| [2] | D. E. Rapach and J. K. Strauss, Structural breaks and GARCH models of exchange rate volatility, J. Appl. Econom., 23 (2008), 65–90. |
| [3] | D. E. Rapach, J. K. Strauss and M. E. Wohar, Chapter 10 Forecasting Stock Return Volatility in the Presence of Structural Breaks, in Forecasting in the presence of structural breaks and model uncertainty, Emerald Group Publishing Limited, (2008), 381–416. |
| [4] | A. Timmermann, Chapter 4 Forecast combinations, in Handbook of economic forecasting, (2006), 135–196. |
| [5] | M. H. Pesaran and A. Timmermann, Selection of estimation windows in the presence of breaks, J. Econometrics, 137 (2007), 134–161. |
| [6] | J. Tian and H. M. Anderson, Forecast combinations under structural break uncertainty, Int. J. Forecasting, 30 (2014), 161–175. |
| [7] | M. H. Pesaran, A. Pick and M. Pranovich, Optimal forecasts in the presence of structural breaks, J. Econometrics, 177 (2013), 134–152. |
| [8] | K. Assenmacher-Wesche and M. H. Pesaran, Forecasting the Swiss economy using VECX models: An exercise in forecast combination across models and observation windows, Nat. Inst. Econ. Rev., 203 (2008), 91–108. |
| [9] | M. H. Pesaran, T. Schuermann and L. V. Smith, Forecasting economic and financial variables with global VARs, Int. J. Forecasting, 25 (2009), 642–675. |
| [10] | A. Schrimpf and Q. Wang, A reappraisal of the leading indicator properties of the yield curve under structural instability, Int. J. Forecasting, 26 (2010), 836–857. |
| [11] | D. De Gaetano, Forecast combinations in the presence of structural breaks: Evidence from U.S. equity markets, Math., 6 (2018), 34. |
| [12] | M. H. Pesaran and A. Pick, Forecast combination across estimation windows, J. Bus. Econ. Stat., 29 (2011), 307–318. |
| [13] | T. E. Clark and M. W. McCracken, Improving forecast accuracy by combining recursive and rolling forecasts, Int. Econ. Rev., 50 (2009), 363–395. |
| [14] | D. De Gaetano, Forecast Combinations for Structural Breaks in Volatility: Evidence from BRICS Countries, J. Risk. Financ. Manag., 11 (2018), 64. |
| [15] | D. De Gaetano, Forecasting with GARCH models under structural breaks: An approach based on combinations across estimation windows, Commun. Stat. Simulat. Comput., 6 (2018), 1–19. |
| [16] | P. R. Hansen, A. Lunde and J. M. Nason, The model confidence set, Econometrica, 79 (2011), 453–497. |
| [17] | F. X. Diebold, Modelling the persistence of conditional variance: A comment, Economet. Rev., 5 (1986), 51–56. |
| [18] | T. Mikosh and C. Stărică, Nonstationarities in financial time series, the long-range dependence and the IGARCH effects, Rev. Econ. Stat., 86 (2004), 378–390. |
| [19] | E. Hillebrand, Neglecting parameter changes in GARCH models, J. Econometrics, 129 (2005), 121–138. |
| [20] | S. Hwang and P. L. V. Pereira, Small sample properties of GARCH estimates and persistence, Eur. J. Financ., 12 (2006), 473–494. |
| [21] | T. Bollerslev, Generalized Autoregressive Conditional Heteroskedasticity, J. Econometrics, 31 (1986), 307–332. |
| [22] | D. B. Nelson, Conditional heteroschedasticity in asset returns: A new approach, Econometrica, 59 (1991), 217–235. |
| [23] | L. R. Glosten, R. Jagannathan and D. E. Runkle, On the Relation between the expected value and the volatility of the nominal excess return on stocks, J. Financ., 48 (1993), 1779–1801. |
| [24] | C. Forbes, M. Evans, N. Hastings, et al., Statistical distributions, 2nd edition, John Wiley & Sons, 2011. |
| [25] | J. Nyblom, Testing for the constancy of parameters over time, J. Am. Stat. Assoc., 84 (1989), 223–230. |
| [26] | B. E. Hansen, Tests for parameter instability in regressions with I (1) processes, J. Bus. Econ. Stat., 20 (2002), 45–59. |
| [27] | A. Sansó, V. Arragó and J. L. Carrion-i-Silvestre, Testing for change in the unconditional variance of financial time series, Rev. Econ. Financ., 4 (2004), 32–53. |
| [28] | C. Inclan and G. C. Tiao, Use of cumulative sums of squares for retrospective detection of changes in variance, J. Am. Stat. Assoc., 89 (1994), 913–923. |
| [29] | W. K. Newey and K. D. West, Automatic Lag Selection in Covariance Matrix estimation, Rev. Econ. Stud., 61 (1994), 631–654. |
| [30] | G. J. Ross, Modelling financial volatility in the presence of abrupt changes, Physica. A, 392 (2013), 350–360. |
| [31] | J. G. MacKinnon, Computing numerical distribution functions in econometrics, in High Performance Computing Systems and Applications, Kluwer, (2000), 455–471. |
| [32] | A. J. Patton, Volatility forecast comparison using imperfect volatility proxies, J. Econometrics, 160 (2011), 246–256. |
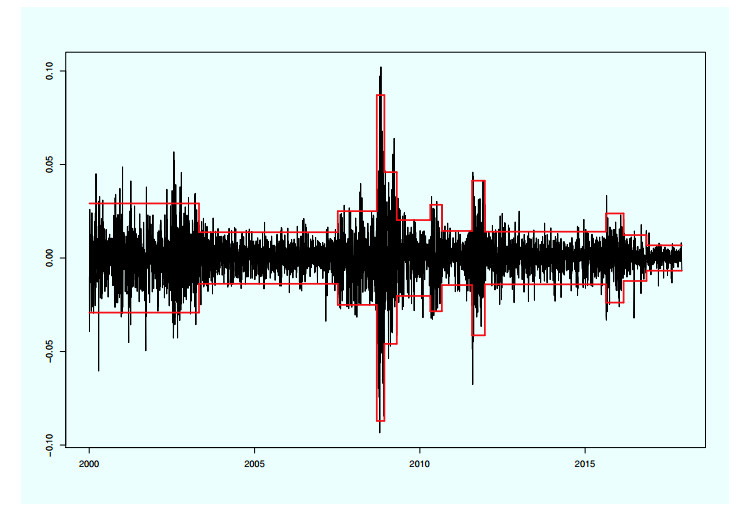
Figures(1) / Tables(11)

Davide De Gaetano. Forecasting volatility using combination across estimation windows: An application to S&P500 stock market index[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 7195-7216. doi: 10.3934/mbe.2019361







 DownLoad:
DownLoad: