Citation: Beijing Chen, Ye Gao, Lingzheng Xu, Xiaopeng Hong, Yuhui Zheng, Yun-Qing Shi. Color image splicing localization algorithm by quaternion fully convolutional networks and superpixel-enhanced pairwise conditional random field[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6907-6922. doi: 10.3934/mbe.2019346

| [1] | G. K. Birajdar and V. H. Mankar, Digital image forgery detection using passive techniques: A survey, Digit. Invest., 10(2013), 226–245. |
| [2] | B. J. Chen, M. Yu, Q. T. Su, et al., Fractional quaternion cosine transform and its application in color image copy-move forgery detection, Multimed. Tools Appl., (2018), 1–17. |
| [3] | C. M. Pun, B. Liu and X. C. Yuan, Multi-scale noise estimation for image splicing forgery detection, J. Vis. Commun. Image Represent., 10(2016), 195–206. |
| [4] | B. Mahdian and S. Saic, Using noise inconsistencies for blind image forensics, Image Vis. Comput., 27(2009), 1497–1503. |
| [5] | S. Lyu, X. Pan and X. Zhang, Exposing region splicing forgeries with blind local noise estimation, Int. J. Comput. Vis., 110(2014), 202–221. |
| [6] | P. Ferrara, T. Bianchi, R. A. De, et al., Image forgery localization via fine-grained analysis of CFA artifacts, IEEE Trans. Inf. Forensic Secur., 10(2013), 226–245. |
| [7] | A. E. Dirik and N. Memon, Image tamper detection based on demosaicing artifacts, In: IEEE International Conference on Image Processing, (2009), 1497–1500. |
| [8] | E. González, A. Sandoval, L. García, et al., Digital image tamper detection technique based on spectrum analysis of CFA artifacts, Sensors, 18(2018), 2804. |
| [9] | Z. Lin, J. He, X. Tang, et al., Fast, automatic and fine-grained tampered JPEG image detection via DCT coefficient analysis, Pattern Recognit., 42(2009), 2492–2501. |
| [10] | T. Bianchi and A. Piva, Image forgery localization via block-grained analysis of JPEG artifacts, IEEE Trans. Inf. Forensic Secur., 7(2012), 1003–1017. |
| [11] | S. M. Ye, Q. Sun and E. C. Chang, Detecting digital image forgeries by measuring inconsistencies of blocking artifact, In: IEEE International Conference on Multimedia and Expo, (2007), 12–15. |
| [12] | W. Li, Y. Yuan and N. Yu, Passive detection of doctored JPEG image via block artifact grid extraction, Signal Process., 89(2009), 1821–1829. |
| [13] | W. Luo, J. Huang and G. Qiu, JPEG error analysis and its applications to digital image forensics, IEEE Trans. Inf. Forensic Secur., 5(2010), 480–491. |
| [14] | F. Huang, J. Huang and Y. Q. Shi, Detecting double JPEG compression with the same quantization matrix, IEEE Trans. Inf. Forensic Secur., 5(2010), 848–856. |
| [15] | A. C. Popescu and H. Farid, Exposing digital forgeries by detecting traces of resampling, IEEE Trans. Signal Process., 53(2005), 758–767. |
| [16] | H. D. Li, W. Q. Luo, X. Q. Qiu, et al., Image forgery localization via integrating tampering possibility maps, IEEE Trans. Inf. Forensic Secur., 12(2017), 1240–1252. |
| [17] | D. Cozzolino, G. Poggi and L. Verdoliva, Recasting residual-based local descriptors as convolutional neural networks: an application to image forgery detection, In: ACM Workshop on Information Hiding and Multimedia Security, (2017), 159–164. |
| [18] | Y. Liu, Q. Guan, X. Zhao, et al., Image forgery localization based on multi-scale convolutional neural networks, In: ACM Workshop on Information Hiding and Multimedia Security, (2018), 85–90. |
| [19] | J. H. Bappy, A. K. Roy, J. Bunk, et al., Exploiting spatial structure for localizing manipulated image regions, In: IEEE International Conference on Computer Vision, (2017), 4970–4979. |
| [20] | Z. Shi, X. Shen and H. Kang, Image manipulation detection and localization based on the dual-domain convolutional veural networks, IEEE Access, 6(2018), 76437–76453. |
| [21] | R. Salloum, Y. Ren and C. C. J. Kuo, Image splicing localization using a multi-task gully convolutional network (MFCN), J. Vis. Commun. Image Represent., 51(2018), 201–209. |
| [22] | B. Liu and C. M. Pun, Locating splicing forgery by fully convolutional networks and conditional random field, Signal Process.Image Commun., 66(2018), 103–112. |
| [23] | B. J. Chen, X. M. Qi, Y. T. Wang, et al., An Improved Splicing Localization Method by Fully Convolutional Networks, IEEE Access, 6(2018), 69472–69480. |
| [24] | J. H. Bappy, C. Simons, L. Nataraj, et al., Hybrid LSTM and encoder-decoder architecture for detection of image forgeries, IEEE Trans. Image Process., 28(2019), 3286–3300. |
| [25] | T. Parcollet, M. Morchid and G. Linarès, Quaternion convolutional neural networks heterogeneous image processing, preprint, arXiv: 1811.02656. |
| [26] | T. A. Ell and S. J. Sangwine, Hypercomplex fourier transforms of color images, IEEE Trans. Image Process., 16(2007), 22–35. |
| [27] | B. J. Chen, G. Coatrieux, G. Chen, et al., Full 4-D quaternion discrete Fourier transform based watermarking for color images, Digit. Signal Proc., 28(2014), 106–119. |
| [28] | N. Matsui, T. Isokawa, H. Kusamichi, et al., Quaternion neural network with geometrical operators, J. Intell. Fuzzy Syst., 15(2004), 149–164. |
| [29] | X. Xu, Z. Guo, C. Song, et al., Multispectral palmprint recognition using a quaternion matrix, Sensors, 12(2012), 4633–4647. |
| [30] | B. J. Chen, J. H. Yang, B. Jeon, et al., Kernel quaternion principal component analysis and its application in RGB-D object recognition, Neurocomputing, 266(2017), 293–303. |
| [31] | G. L. Xu, X. T. Wang and X. G. Xu, Fractional quaternion Fourier transform, convolution and correlation, Signal Process., 88(2008), 2511–2517. |
| [32] | B. J. Chen, C. F. Zhou, B. Jeon, et al., Quaternion discrete fractional random transform for color image adaptive watermarking, Multimed. Tools Appl., 77(2018), 20809–20837. |
| [33] | K. Simonyan and A. Zisserman, Very deep convolutional networks for large-scale image recognition, preprint, arXiv: 1409.1556. |
| [34] | Q. Cui, S. McIntosh and H. Y. Sun, Identifying materials of photographic images and photorealistic computer generated graphics based on deep CNNs, Comput. Mat. Contin., 55(2018), 229–241. |
| [35] | H. Y. Zhao, C. Che, B. Jin, et al., A viral protein identifying framework based on temporal convolutional network, Math. Biosci. Eng., 16(2019), 1709–1717. |
| [36] | L. G. Zheng and C. Song, Fast near-duplicate image detection in Riemannian space by a novel hashing scheme, Comput. Mat. Contin., 56(2018), 529–539. |
| [37] | K. He, X. Zhang, S. Ren, et al., Deep residual learning for image recognition, In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), (2016), 770–778. |
| [38] | X. Zhu, Y. Xu and H. Xu, Quaternion convolutional neural networks, In: European Conference on Computer Vision, (2018), 631–647. |
| [39] | C. J. Gaudet and A. S. Maida, Deep quaternion networks, In: IEEE International Joint Conference on Neural Networks, (2018), 1–8. |
| [40] | S. Ioffe and C. Szegedy, Batch normalization: accelerating deep network training by reducing internal covariate shift, In: International Conference on International Conference on Machine Learning, (2015), 448–456. |
| [41] | E. Shelhamer, J. Long and T. Darrell, Fully Convolutional Networks for Semantic Segmentation, IEEE Trans. Pattern Anal. Mach. Intell., 39(2014), 640–651. |
| [42] | A. Arnab, S. Jayasumana, S. Zheng, et al., Higher order conditional random fields in deep neural networks, In: European Conference on Computer Vision, (2016), 524–540. |
| [43] | Y. H. Zheng, L. Sun, S. F. Wang, et al., Spatially regularized structural support vector machine for robust visual tracking. IEEE Trans. Neural Netw. Learn. Syst., 2018. DOI: 10.1109/tnnls.2018.2855686 |
| [44] | L. Sulimowicz, I. Ahmad and A. Aved, Superpixel-enhanced pairwise conditional random field for semantic segmentation, In: IEEE International Conference on Image Processing, (2018), 271–275. |
| [45] | P. Kohli and P. H. S. Torr, Robust higher order potentials for enforcing label consistency, Int. J. Comput. Vis., 82(2009), 302–324. |
| [46] | J. Dong and W. Wang, CASIA tampered image detection evaluation (TIDE) database, v1.0 and v2.0, Chinese Academy of Sciences, 2011, Available online: http://forensics.idealtest.org/. |
| [47] | T. T. Ng and S. F. Chang, A dataset of authentic and spliced image blocks, Columbia University, 2004, Available online: http://www.ee.columbia.edu/ln/dvmm/downloads/. |
| [48] | M. Zampoglou, S. Papadopoulos and Y. Kompatsiaris, Large-scale evaluation of splicing localization algorithms for web images, Multimed. Tools Appl., 76(2017), 1–34. |
| [49] | F. Xiao, L.Chen, H. Zhu, et al., Anomaly-tolerant network traffic map estimation via noise-immune temporal matrix completion, IEEE J. Sel. Area. Comm., 37(2019), 1192–1204. |
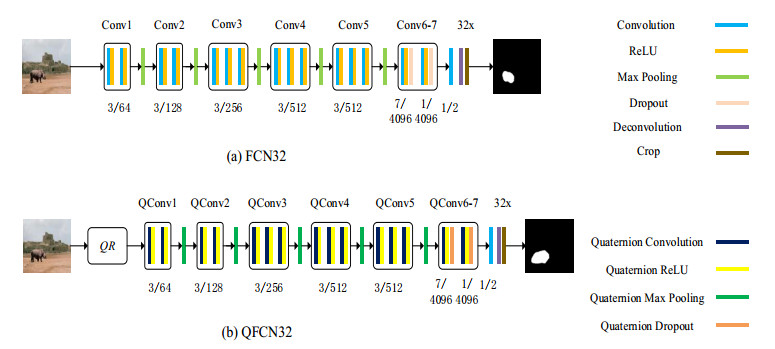
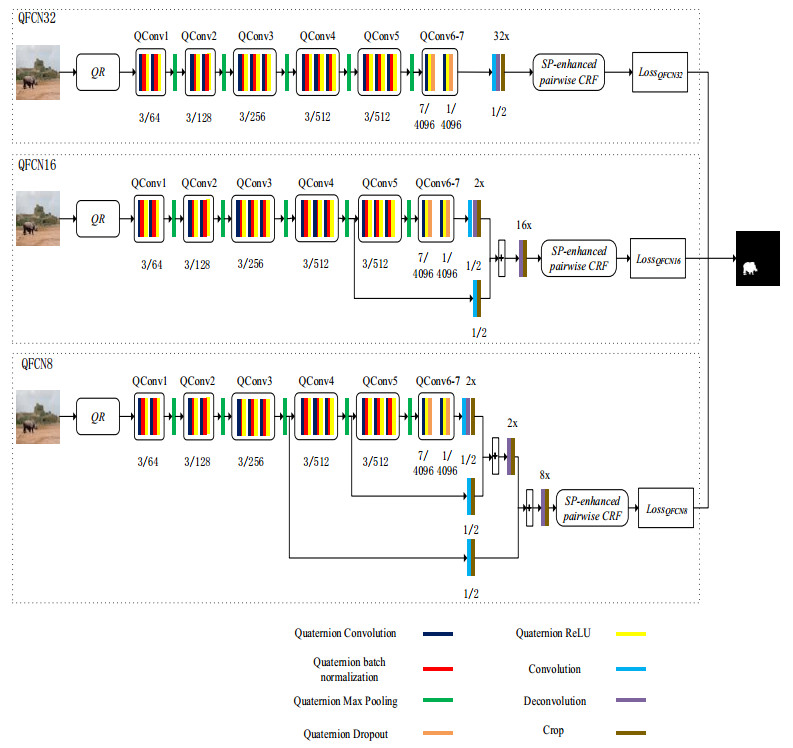

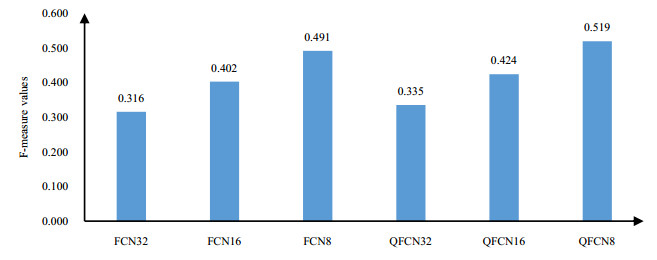
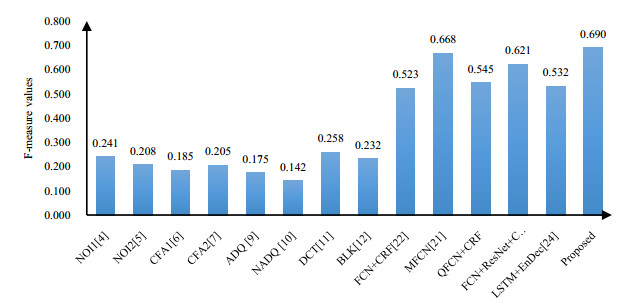
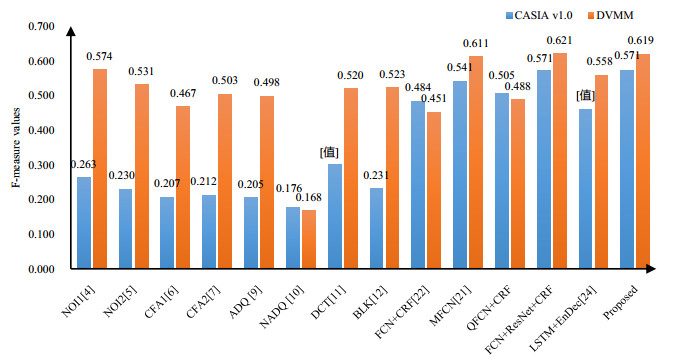

Figures(7) / Tables(2)

Beijing Chen, Ye Gao, Lingzheng Xu, Xiaopeng Hong, Yuhui Zheng, Yun-Qing Shi. Color image splicing localization algorithm by quaternion fully convolutional networks and superpixel-enhanced pairwise conditional random field[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6907-6922. doi: 10.3934/mbe.2019346







 DownLoad:
DownLoad: