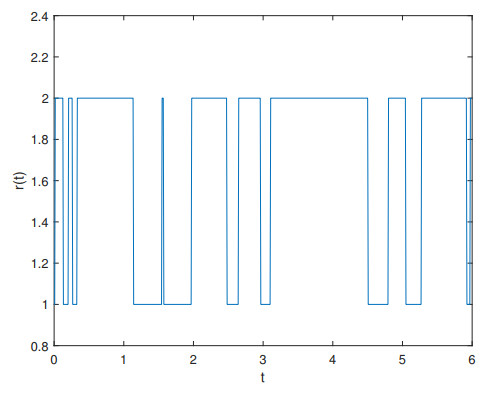
This paper is concerned with almost sure exponential synchronization of multilayer complex networks with Markovian switching via aperiodically intermittent discrete observation noise. First, Markovian switching and multilayer interaction factors are taken into account simultaneously, which make our system more general compared with the existing literature. Meanwhile, the network architecture may be undirected or directed, and consequently, the adjacency matrix is symmetrical and asymmetrical. Second, the control strategy is based on aperiodically intermittent discrete observation noise, where the average control rate is integrated to depict the distributions of work/rest intervals of the control strategy from an overall perspective. Third, different from the work about $ p $th moment exponential synchronization of network systems, by utilizing M-matrix theory and various stochastic analysis techniques including the Itô formula, the Gronwall inequality, and the Borel-Cantelli lemma, some criteria on almost sure exponential synchronization of multilayer complex networks with Markovian switching have been constructed and the upper bound of the duration time has been also estimated. Finally, several numerical simulations are exhibited to validate the effectiveness and feasibility of our analytical findings.
Citation: Li Liu, Yinfang Song, Hong Yu, Gang Zhang. Almost sure exponential synchronization of multilayer complex networks with Markovian switching via aperiodically intermittent discrete observa- tion noise[J]. AIMS Mathematics, 2024, 9(10): 28828-28849. doi: 10.3934/math.20241399
This paper is concerned with almost sure exponential synchronization of multilayer complex networks with Markovian switching via aperiodically intermittent discrete observation noise. First, Markovian switching and multilayer interaction factors are taken into account simultaneously, which make our system more general compared with the existing literature. Meanwhile, the network architecture may be undirected or directed, and consequently, the adjacency matrix is symmetrical and asymmetrical. Second, the control strategy is based on aperiodically intermittent discrete observation noise, where the average control rate is integrated to depict the distributions of work/rest intervals of the control strategy from an overall perspective. Third, different from the work about $ p $th moment exponential synchronization of network systems, by utilizing M-matrix theory and various stochastic analysis techniques including the Itô formula, the Gronwall inequality, and the Borel-Cantelli lemma, some criteria on almost sure exponential synchronization of multilayer complex networks with Markovian switching have been constructed and the upper bound of the duration time has been also estimated. Finally, several numerical simulations are exhibited to validate the effectiveness and feasibility of our analytical findings.

| [1] |
J. M. Carrasco, L. G. Franquelo, J. T. Bialasiewicz, E. Galvan, R. C. PortilloGuisado, M. A. M. Prats, et al., Power-electronic systems for the grid integration of renewable energy sources: a survey, IEEE T. Ind. Electron., 53 (2006), 1002–1016. https://doi.org/10.1109/TIE.2006.878356 doi: 10.1109/TIE.2006.878356

|
| [2] |
C. J. Melián, J. Bascompte, P. Jordano, V. Krivan, Diversity in a complex ecological network with two interaction types, Oikos, 118 (2009), 122–130. https://doi.org/10.1111/j.1600-0706.2008.16751.x doi: 10.1111/j.1600-0706.2008.16751.x
|
| [3] |
J. Y. Lin, Y. F. Ban, Complex network topology of transportation systems, Transport Rev., 33 (2013), 658–685. https://doi.org/10.1080/01441647.2013.848955 doi: 10.1080/01441647.2013.848955
|
| [4] |
X. Wang, X. Z. Liu, K. She, S. M. Zhong, Pinning impulsive synchronization of complex dynamical networks with various time-varying delay sizes, Nonlinear Anal.-Hybri., 26 (2017), 307–318. https://doi.org/10.1016/j.nahs.2017.06.005 doi: 10.1016/j.nahs.2017.06.005
|
| [5] |
X. S. Yang, J. Q. Lu, Finite-time synchronization of coupled networks with Markovian topology and impulsive effects, IEEE T. Automat. Contr., 61 (2016), 2256–2261. https://doi.org/10.1109/TAC.2015.2484328 doi: 10.1109/TAC.2015.2484328
|
| [6] |
L. Zou, Z. D. Wang, H. J. Gao, X. H. Liu, Event-triggered state estimation for complex networks with mixed time delays via sampled data information: the continuous-time case, IEEE T. Cybernetics, 45 (2015), 2804–2815. https://doi.org/10.1109/TCYB.2014.2386781 doi: 10.1109/TCYB.2014.2386781
|
| [7] |
Y. H. Deng, Z. H. Meng, H. Q. Lu, Adaptive event-triggered state estimation for complex networks with nonlinearities against hybrid attacks, AIMS Mathematics, 7 (2022), 2858–2877. https://doi.org/10.3934/math.2022158 doi: 10.3934/math.2022158
|
| [8] |
P. Wan, Z. G. Zeng, Synchronization of delayed complex networks on time scales via aperiodically intermittent control using matrix-based convex combination method, IEEE T. Neur. Net. Lear., 34 (2023), 2938–2950. https://doi.org/10.1109/TNNLS.2021.3110321 doi: 10.1109/TNNLS.2021.3110321
|
| [9] |
K. Ding, Q. X. Zhu, Fuzzy model-based quantitative control for prefixed time synchronization of stochastic reaction-diffusion complex networks under cyber-attacks, IEEE T. Autom. Sci. Eng., 2023 (2023), 3329239. https://doi.org/10.1109/TASE.2023.3329239 doi: 10.1109/TASE.2023.3329239
|
| [10] |
J. C. Jiang, X. D. Liu, Z. W. Wang, W. P. Ding, S. T. Zhang, H. Xu, Large group decision-making with a rough integrated asymmetric cloud model under multi-granularity linguistic environment, Inform. Sciences, 678 (2024), 120994. https://doi.org/10.1016/j.ins.2024.120994 doi: 10.1016/j.ins.2024.120994
|
| [11] |
J. C. Jiang, X. D. Liu, Z. W. Wang, W. P. Ding, S. T. Zhang Large group emergency decision-making with bi-directional trust in social networks: A probabilistic hesitant fuzzy integrated cloud approach, Inform. Fusion, 102 (2024), 102062. https://doi.org/10.1016/j.inffus.2023.102062 doi: 10.1016/j.inffus.2023.102062
|
| [12] |
W. T. Hua, Y. T. Wang, C. Y. Liu, New method for global exponential synchronization of multi-link memristive neural networks with three kinds of time-varying delays, Appl. Math. Comput., 471 (2024), 128593. https://doi.org/10.1016/j.amc.2024.128593 doi: 10.1016/j.amc.2024.128593
|
| [13] |
J. Liu, Z. H. Xu, L. Xue, Y. B. Wu, C. Y. Sun, Practical fixed-time synchronization of multilayer networks via intermittent event-triggered control, IEEE T. Syst. Man Cy-S., 54 (2024), 2626–2637. https://doi.org/10.1109/TSMC.2023.3341847 doi: 10.1109/TSMC.2023.3341847
|
| [14] |
Y. Ren, H. J. Jiang, C. Hu, Bipartite synchronization of multilayer signed networks under aperiodic intermittent-based adaptive dynamic event-triggered control, ISA T., 144 (2024), 72–85. https://doi.org/10.1016/j.isatra.2023.10.015 doi: 10.1016/j.isatra.2023.10.015
|
| [15] |
Y. Guo, Y. Z. Li, Bipartite leader-following synchronization of fractional-order delayed multilayer signed networks by adaptive and impulsive controllers, Appl. Math. Comput., 430 (2022), 127243. https://doi.org/10.1016/j.amc.2022.127243 doi: 10.1016/j.amc.2022.127243
|
| [16] |
Y. Xu, T. Lin, X. Z. Liu, W. X. Li, Exponential bipartite synchronization of fractional-order multilayer signed networks via hybrid impulsive control, IEEE T. Cybernetics, 53 (2023), 3926–3938. https://doi.org/10.1109/TCYB.2022.3190413 doi: 10.1109/TCYB.2022.3190413
|
| [17] |
N. Yang, L. T. Liu, H. Su, Stability of multi-link delayed impulsive stochastic complex networks with Markovian switching, J. Franklin I., 360 (2023), 12922–12940. https://doi.org/10.1016/j.jfranklin.2023.10.002 doi: 10.1016/j.jfranklin.2023.10.002
|
| [18] |
Y. Guo, B. D. Chen, Y. B. Wu, Finite-time synchronization of stochastic multi-links dynamical networks with Markovian switching topologies, J. Franklin I., 357 (2020), 359–384. https://doi.org/10.1016/j.jfranklin.2019.11.045 doi: 10.1016/j.jfranklin.2019.11.045
|
| [19] |
C. Gao, B. B. Guo, Y. Xiao, J. C. Bao, Aperiodically synchronization of multi-links delayed complex networks with semi-Markov jump and their numerical simulations to single-link robot arms, Neurocompting, 575 (2024), 127286. https://doi.org/10.1016/j.neucom.2024.127286 doi: 10.1016/j.neucom.2024.127286
|
| [20] |
J. M. Zhou, C. M. Zhang, H. L. Chen, Exponential stability of stochastic multi-layer complex network with regime-switching diffusion via aperiodically intermittent control, Inform. Sciences, 662 (2024), 120241. https://doi.org/10.1016/j.ins.2024.120241 doi: 10.1016/j.ins.2024.120241
|
| [21] |
S. Li, C. Y. Lv, X. H. Ding, Synchronization of stochastic hybrid coupled systems with multi-weights and mixed delays via aperiodically adaptive intermittent control, Nonlinear Anal.-Hybri., 35 (2020), 100819. https://doi.org/10.1016/j.nahs.2019.100819 doi: 10.1016/j.nahs.2019.100819
|
| [22] |
D. S. Xu, T. Wang, H. Su, Aperiodically intermittent pinning discrete-time observation control for exponential synchronization of stochastic multilayer coupled systems, Neurocomputing, 505 (2022), 203–213. https://doi.org/10.1016/j.neucom.2022.07.020 doi: 10.1016/j.neucom.2022.07.020
|
| [23] |
S. Li, Y. H. Zhang, H. Su, Almost sure synchronization of multilayer networks via intermittent pinning noises: A white-noise-based time-varying coupling, IEEE T. Circuits-I, 68 (2021), 3460–3473. https://doi.org/10.1109/TCSI.2021.3082005 doi: 10.1109/TCSI.2021.3082005
|
| [24] |
X. R. Mao, Stochastic stabilization and destabilization, Syst. Control Lett., 23 (1994), 279–290. https://doi.org/10.1016/0167-6911(94)90050-7 doi: 10.1016/0167-6911(94)90050-7
|
| [25] |
F. Q. Deng, Q. Luo, X. R. Mao, Stochastic stabilization of hybrid differential equations, Automatica, 48 (2012), 2321–2328. https://doi.org/10.1016/j.automatica.2012.06.044 doi: 10.1016/j.automatica.2012.06.044
|
| [26] |
X. Chen, X. Xiong, M. H. Zhang, W. Li, Public authority control strategy for opinion evolution in social networks, Chaos, 26 (2016), 083105. https://doi.org/10.1063/1.4960121 doi: 10.1063/1.4960121
|
| [27] |
X. X. Liao, X. Mao, Exponential stability and instability of stochastic neural networks, Stoch. Anal. Appl., 14 (1996), 165–185. https://doi.org/10.1080/07362999608809432 doi: 10.1080/07362999608809432
|
| [28] |
B. Zhang, C. C. Lim, P. Shi, S. L. Xie, F. Q. Deng, Stabilization of a class of nonlinear systems with random disturbance via intermittent stochastic noise, IEEE T. Automat. Contr., 65 (2020), 1318–1324. https://doi.org/10.1109/TAC.2019.2926890 doi: 10.1109/TAC.2019.2926890
|
| [29] |
L. Liu, M. Perc, J. D. Cao, Aperiodically intermittent stochastic stabilization via discrete time or delay feedback control, Sci. China Inf. Sci., 62 (2019), 72201. https://doi.org/10.1007/s11432-018-9600-3 doi: 10.1007/s11432-018-9600-3
|
| [30] |
X. R. Mao, Stabilization of continuous-time hybrid stochastic differential equations by discrete-time feedback control, Automatica, 49 (2013), 3677–3681. https://doi.org/10.1016/j.automatica.2013.09.005 doi: 10.1016/j.automatica.2013.09.005
|
| [31] |
X. R. Mao, Almost sure exponential stabilization by discrete-time stochastic feedback control, IEEE T. Automat. Contr., 61 (2016), 1619–1624. https://doi.org/10.1109/TAC.2015.2471696 doi: 10.1109/TAC.2015.2471696
|
| [32] |
Y. Zhao, Q. X. Zhu, Stabilization of highly nonlinear neutral stochastic systems with Markovian switching by periodically intermittent feedback control, Int. J. Robust Nonlin., 32 (2022), 10201–10214. https://doi.org/10.1002/rnc.6403 doi: 10.1002/rnc.6403
|
| [33] |
Y. Zhao, Q. X. Zhu, Stabilization of stochastic highly nonlinear delay systems with neutral-term, IEEE T. Automat. Contr., 68 (2023), 2544–2551. https://doi.org/10.1109/TAC.2022.3186827 doi: 10.1109/TAC.2022.3186827
|
| [34] |
C. X. Zhang, Q. X. Zhu, Exponential stability of random perturbation nonlinear delay systems with intermittent stochastic noise, J. Franklin I., 360 (2023), 792–812. https://doi.org/10.1016/j.jfranklin.2022.12.004 doi: 10.1016/j.jfranklin.2022.12.004
|
| [35] |
Y. B. Wu, J. L. Zhu, W. X. Li, Intermittent discrete observation control for synchronization of stochastic neural networks, IEEE T. Cybernetics, 50 (2020), 2414–2424. https://doi.org/10.1109/TCYB.2019.2930579 doi: 10.1109/TCYB.2019.2930579
|
| [36] |
X. L. He, C. K. Ahn, P. Shi, Periodically intermittent stabilization of neural networks based on discrete-time observations, IEEE T. Circuits-II, 67 (2020), 3497–3501. https://doi.org/10.1109/TCSII.2020.3005901 doi: 10.1109/TCSII.2020.3005901
|
| [37] |
W. Mao, S. R. You, Y. A. Jiang, X. R. Mao, Stochastic stabilization of hybrid neural networks by periodically intermittent control based on discrete-time state observations, Nonlinear Anal.-Hybri., 48 (2023), 101331. https://doi.org/10.1016/j.nahs.2023.101331 doi: 10.1016/j.nahs.2023.101331
|
| [38] |
Y. B. Wu, Y. C. Li, W. X. Li, Almost surely exponential synchronization of complex dynamical networks under aperiodically intermittent discrete observations noise, IEEE T. Cybernetics, 52 (2022), 2663–2674. https://doi.org/10.1109/TCYB.2020.3022296 doi: 10.1109/TCYB.2020.3022296
|
| [39] |
X. L. He, H. Y. Zhang, Exponential synchronization of complex networks via feedback control and periodically intermittent noise, J. Franklin I., 359 (2022), 3614–3630. https://doi.org/10.1016/j.jfranklin.2022.03.010 doi: 10.1016/j.jfranklin.2022.03.010
|
| [40] |
J. Respondek, Matrix black box algorithms-A survey, Bulletin of the Polish Academy of Sciences. Technical Sciences, 70 (2022), e140535. https://doi.org/10.24425/bpasts.2022.140535 doi: 10.24425/bpasts.2022.140535
|
| [41] |
A. Khan, T. Abdeljawad, M. A. Alqudah, Neural networking study of worms in a wireless sensor model in the sense of fractal fractional, AIMS Mathematics, 8 (2023), 26406–26424. https://doi.org/10.3934/math.20231348 doi: 10.3934/math.20231348
|
| [42] |
A. Khan, H. M. Hashim, T. Abdeljawad, Q. M. Al-Mdallal, H. Khan, Stability analysis of fractional nabla difference COVID-19 model, Results Phys., 22 (2021), 103888. https://doi.org/10.1016/j.rinp.2021.103888 doi: 10.1016/j.rinp.2021.103888
|
| [43] |
P. Bedi, A. Kumar, T. Abdeljawad, A. Khan, Study of Hilfer fractional evolution equations by the properties of controllability and stability, Alex. Eng. J., 60 (2021), 3741–3749. https://doi.org/10.1016/j.aej.2021.02.014 doi: 10.1016/j.aej.2021.02.014
|
| [44] |
H. Khan, J. F. Gomez-Aguilar, T. Abdeljawad, A. Khan, Existence results and stability criteria for ABC-fuzzy-Volterra integro-differential equation, Fractals, 28 (2020), 2040048. https://doi.org/10.1142/S0218348X20400484 doi: 10.1142/S0218348X20400484
|
| [45] |
A. Khan, T. Abdeljawad, On existence results of coupled pantograph discrete fractional order difference equations with numerical application, Results in Control and Optimization, 13 (2023), 100307. https://doi.org/10.1016/j.rico.2023.100307 doi: 10.1016/j.rico.2023.100307
|
| [46] |
W. H. Qi, G. D. Zong, J. Cheng, T. C. Jiao Robust finite-time stabilization for positive delayed semi-Markovian switching systems, Appl. Math. Comput., 351 (2019), 139–152. https://doi.org/10.1016/j.amc.2018.12.069 doi: 10.1016/j.amc.2018.12.069
|
| [47] |
B. Wang, Q. X. Zhu, S. B. Li, Stability analysis of discrete-time semi-Markov jump linear systems with time delay, IEEE T. Automat. Contr., 68 (2023), 6758–6765. https://doi.org/10.1109/TAC.2023.3240926 doi: 10.1109/TAC.2023.3240926
|



Figures(4)

Li Liu, Yinfang Song, Hong Yu, Gang Zhang. Almost sure exponential synchronization of multilayer complex networks with Markovian switching via aperiodically intermittent discrete observa- tion noise[J]. AIMS Mathematics, 2024, 9(10): 28828-28849. doi: 10.3934/math.20241399







 DownLoad:
DownLoad: