Citation: Khang Duy Vu Nguyen, Khoa Dang Nguyen Vo. Magnetite nanoparticles-TiO2 nanoparticles-graphene oxide nanocomposite: Synthesis, characterization and photocatalytic degradation for Rhodamine-B dye[J]. AIMS Materials Science, 2020, 7(3): 288-301. doi: 10.3934/matersci.2020.3.288

| [1] |
Eckert H, Bobeth M, Teixeira S, et al. (2015) Modeling of photocatalytic degradation of organic components in water by nanoparticle suspension. Chem Eng J 261: 67-75. doi: 10.1016/j.cej.2014.05.147

|
| [2] |
Martins PM, Ferreira C, Silva A, et al. (2018) TiO2/graphene and TiO2/graphene oxide nanocomposites for photocatalytic applications: A computer modeling and experimental study. Compos Part B-Eng 145: 39-46. doi: 10.1016/j.compositesb.2018.03.015
|
| [3] | Luo Y, Guo W, Ngo HH, et al. (2014) A review on the occurrence of micropollutants in the aquatic environment and their fate and removal during wastewater treatment. Sci Total Environ 473: 619-641. |
| [4] |
Raghavan N, Thangavel S, Sivalingam Y, et al. (2018) Investigation of photocatalytic performances of sulfur based reduced graphene oxide-TiO2 nanohybrids. Appl Surf Sci 449: 712-718. doi: 10.1016/j.apsusc.2018.01.043
|
| [5] |
Anandan S, Ikuma Y, Niwa K (2010) An overview of semi-conductor photocatalysis: modification of TiO2 nanomaterials. Solid State Phenom 162: 239-260. doi: 10.4028/www.scientific.net/SSP.162.239
|
| [6] |
Coelho LL, Hotza D, Estrella AS, et al. (2019) Modulating the photocatalytic activity of TiO2 (P25) with lanthanum and graphene oxide. J Photoch Photobio A 372: 1-10. doi: 10.1016/j.jphotochem.2018.11.048
|
| [7] |
Timoumi A, Alamri SN, Alamri H (2018) The development of TiO2-graphene oxide nano composite thin films for solar cells. Results Phys 11: 46-51. doi: 10.1016/j.rinp.2018.06.017
|
| [8] |
Chen C, Cai W, Long M, et al. (2010) Synthesis of visible-light responsive graphene oxide/TiO2 composites with p/n heterojunction. ACS Nano 4: 6425-6432. doi: 10.1021/nn102130m
|
| [9] |
Rambabu Y, Kumar U, Singhal N, et al. (2019) Photocatalytic reduction of carbon dioxide using graphene oxide wrapped TiO2 nanotubes. Appl Surface Sci 485: 48-55. doi: 10.1016/j.apsusc.2019.04.041
|
| [10] |
Rambabu Y, Jaiswal M, Roy SC (2015) Enhanced photoelectrochemical performance of multi-leg TiO2 nanotubes through efficient light harvesting. J Phys D Appl Phys 48: 295302. doi: 10.1088/0022-3727/48/29/295302
|
| [11] |
Kozlova EA, Vorontsov AV (2006) Noble metal and sulfuric acid modified TiO2 photocatalysts: Mineralization of organophosphorous compounds. Appl Catal B-Environ 63: 114-123. doi: 10.1016/j.apcatb.2005.09.020
|
| [12] |
Wu MC, Huang WK, Lin TH, et al. (2019) Photocatalytic hydrogen production and photodegradation of organic dyes of hydrogenated TiO2 nanofibers decorated metal nanoparticles. Appl Surface Sci 469: 34-43. doi: 10.1016/j.apsusc.2018.10.240
|
| [13] |
Marschall R, Wang L (2014) Non-metal doping of transition metal oxides for visible-light photocatalysis. Catal Today 225: 111-135. doi: 10.1016/j.cattod.2013.10.088
|
| [14] |
Martins P, Gomez V, Lopes A, et al. (2014) Improving photocatalytic performance and recyclability by development of Er-doped and Er/Pr-codoped TiO2/poly(vinylidene difluoride)-trifluoroethylene composite membranes. J Phys Chem C 118: 27944-27953. doi: 10.1021/jp509294v
|
| [15] |
Almeida NA, Martins PM, Teixeira S, et al. (2016) TiO2/graphene oxide immobilized in P (VDF-TrFE) electrospun membranes with enhanced visible-light-induced photocatalytic performance. J Mater Sci 51: 6974-6986. doi: 10.1007/s10853-016-9986-4
|
| [16] | Yusoff AHM, Salimi MN, Jamlos MF (2017) A review: Synthetic strategy control of magnetite nanoparticles production. Adv Nano Res 6: 1-19. |
| [17] |
Hossain MT, Hossain MM, Begum MHA, et al. (2018) Magnetite (Fe3O4) nanoparticles for chromium removal. Bangladesh J Sci Ind Res 53: 219-224. doi: 10.3329/bjsir.v53i3.38269
|
| [18] |
Smith AT, LaChance AM, Zeng S, et al. (2019) Synthesis, properties, and applications of graphene oxide/reduced graphene oxide and their nanocomposites. Nano Mater Sci 1: 31-47. doi: 10.1016/j.nanoms.2019.02.004
|
| [19] |
Cui Y, Kundalwal S, Kumar S (2016) Gas barrier performance of graphene/polymer nanocomposites. Carbon 98: 313-333. doi: 10.1016/j.carbon.2015.11.018
|
| [20] | Gebrezgiabher M, Gebreslassie G, Gebretsadik T, et al. (2019) A C-doped TiO2/Fe3O4 nanocomposite for photocatalytic dye degradation under natural sunlight irradiation. J Compos Sci 3: 1-11. |
| [21] |
Ma P, Jiang W, Wang F, et al. (2013) Synthesis and photocatalytic property of Fe3O4@TiO2 core/shell nanoparticles supported by reduced graphene oxide sheets. J Alloy Compd 578: 01-506. doi: 10.1016/j.jallcom.2013.05.028
|
| [22] |
Stefan M, Pana O, Leostean C, et al. (2014) Synthesis and characterization of Fe3O4-TiO2 core-shell nanoparticles. J Appl Phys 116: 114312. doi: 10.1063/1.4896070
|
| [23] |
Xin T, Ma M, Hepeng Z, et al. (2014) A facile approach for the synthesis of magnetic separable Fe3O4@TiO2, core-shell nanocomposites as highly recyclable photocatalysts. Appl Surface Sci 288: 51-59. doi: 10.1016/j.apsusc.2013.09.108
|
| [24] |
Tan L, Zhang X, Liu Q, et al. (2015) Synthesis of Fe3O4@TiO2 core-shell magnetic composites for highly efficient sorption of uranium (VI). Colloid Surface A 469: 279-286. doi: 10.1016/j.colsurfa.2015.01.040
|
| [25] |
Liang Y, He X, Chen L, et al. (2014) Preparation and characterization of TiO2-graphene@Fe3O4 magnetic composite and its application on the removal of trace microcystin-LR. RSC Adv 4: 56883-56891. doi: 10.1039/C4RA08258C
|
| [26] |
Cruz M, Gomez C, Duran-Valle CJ, et al. (2017) Bare TiO2 and graphene oxide TiO2 photocatalysts on the degradation of selected pesticides and influence of the water matrix. Appl Surface Sci 416: 1013-1021. doi: 10.1016/j.apsusc.2015.09.268
|
| [27] |
Sharma M, Behl K, Nigam S, et al. (2018) TiO2-GO nanocomposite for photocatalysis and environmental applications: A green synthesis approach. Vacuum 156: 434-439. doi: 10.1016/j.vacuum.2018.08.009
|
| [28] | Thongpool V, Phunpueok A, Jaiyen S (2018) Preparation, characterization and photocatalytic activity of ternary graphene-Fe3O4:TiO2. Dig J Nanomater Bios 13: 499-504. |
| [29] |
Hummers Jr WS, Offeman RE (1958) Preparation of graphitic oxide. J Am Chem Soc 80: 1339. doi: 10.1021/ja01539a017
|
| [30] |
Marcano DC, Kosynkin DV, Berlin JM, et al. (2010) Improved synthesis of graphene oxide. ACS nano 4: 4806-4814. doi: 10.1021/nn1006368
|
| [31] |
Emiru TF, Ayele DW (2017) Controlled synthesis, characterization and reduction of graphene oxide: A convenient method for large scale production. Egypt J Basic Appl Sci 4: 74-79. doi: 10.1016/j.ejbas.2016.11.002
|
| [32] |
Manalu SP, Natarajan TS, De Guzman M, et al. (2018) Synthesis of ternary g-C3N4/Bi2MoO6/TiO2 nanotube composite photocatalysts for the decolorization of dyes under visible light and direct sunlight irradiation. Green Process Synth 7: 493-505. doi: 10.1515/gps-2017-0077
|
| [33] | Bordbar AK, Rastegari AA, Amiri R, et al. (2014) Characterization of modified magnetite nanoparticles for albumin immobilization. Biotechnol Res Int 2014: 705068. |
| [34] |
Benjwal P, Kumar M, Chamoli P, et al. (2015) Enhanced photocatalytic degradation of methylene blue and adsorption of arsenic(III) by reduced graphene oxide (rGO)-metal oxide (TiO2/Fe3O4) based nanocomposites. RSC Adv 5: 73249-73260. doi: 10.1039/C5RA13689J
|
| [35] | Zheng K, Zhang T, Lin P, et al. (2015) 4-Nitroaniline degradation by TiO2 catalyst doping with manganese. J Chem 2015: 382376. |
| [36] |
Yang X, Chen W, Huang J, et al. (2015) Rapid degradation of methylene blue in a novel heterogeneous Fe3O4@rGO@TiO2-catalyzed photo-Fenton system. Sci Rep 5: 10632. doi: 10.1038/srep10632
|
| [37] |
Khashan S, Dagher S, Tit N, et al. (2017) Novel method for synthesis of Fe3O4@TiO2 Core/Shell Nanoparticles. Surf Coat Tech 322: 92–98. doi: 10.1016/j.surfcoat.2017.05.045
|
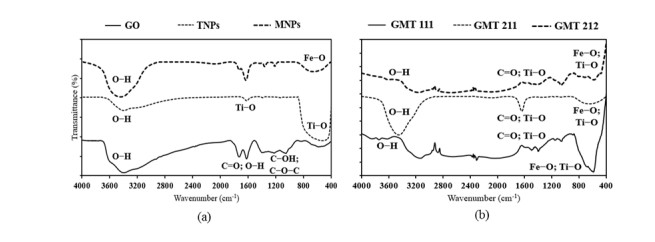
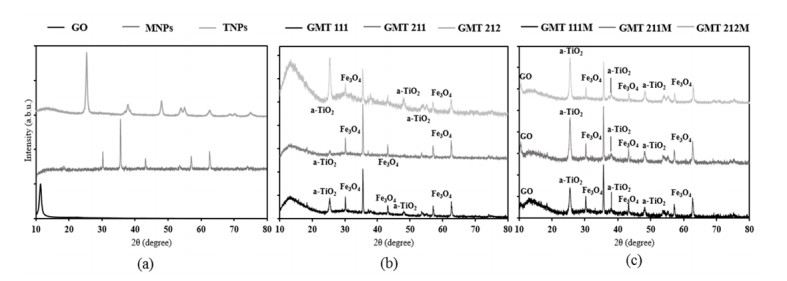
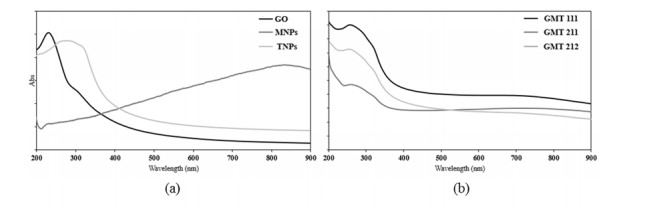


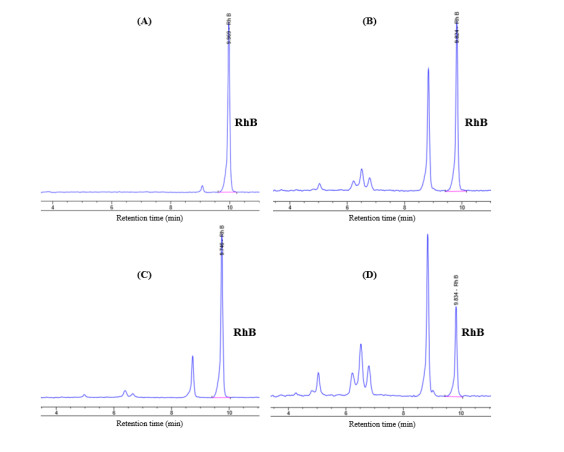
Figures(6) / Tables(4)

Khang Duy Vu Nguyen, Khoa Dang Nguyen Vo. Magnetite nanoparticles-TiO2 nanoparticles-graphene oxide nanocomposite: Synthesis, characterization and photocatalytic degradation for Rhodamine-B dye[J]. AIMS Materials Science, 2020, 7(3): 288-301. doi: 10.3934/matersci.2020.3.288







 DownLoad:
DownLoad: