Citation: Armin Salsani, Abdolhossein Amini, Shahram shariati, Seyed Ali Aghanabati, Mohsen Aleali. Geochemistry, facies characteristics and palaeoenvironmental conditions of the storm-dominated phosphate-bearing deposits of eastern Tethyan Ocean; A case study from Zagros region, SW Iran[J]. AIMS Geosciences, 2020, 6(3): 316-354. doi: 10.3934/geosci.2020019

| [1] | Versfelt Jr PL (2001) Major Hydrocarbon potential in Iran, In: Downey MW, Threet JC, Morgan WA, Petroleum provinces of the twenty first century, American Association of Petroleum Geologists Memorial, 74: 417-427. |
| [2] |
Alavi M (2004) Regional stratigraphy of the Zagros fold-thrust belt of Iran and its proforeland evolution. Am J Sci 304: 1-20. doi: 10.2475/ajs.304.1.1

|
| [3] | James GA, Wynd JG (1965) Stratigraphic Nomenclature of Iranian Oil Consortium Agreement Area. AAPG Bull 49: 2182-2245. |
| [4] | Ala MA, Kinghorn RRF, Rahman M (1980) Organic geochemistry and source rock characteristics of the Zagros petroleum province: South West Iran. J Pet Geol 3: 6l-89. |
| [5] |
Bordenave ML, Bunwood R (1990) Source rock distribution and maturation in the Zagros orogenic belt-provenance of the Asmari and Bangestan reservoir oil accumulations. Org Geochem 16: 369-378. doi: 10.1016/0146-6380(90)90055-5
|
| [6] | Bordenave ML, Huc AY (1995) The Cretaceous source rocks in the Zagros Foothills of Iran. Rev Inst Fr Pet 50: 721-752. |
| [7] |
Daraei M, Amini A, Ansari M (2015) Facies analysis and depositional environment study of the mixed carbonate-evaporite Asmari Formation (Oligo-Miocene) in the sequence stratigraphic framework, NW Zagros, Iran. Carbonates Evaporites 30: 253-272. doi: 10.1007/s13146-014-0207-4
|
| [8] |
Berberian M, King GCP (1981) Towards a paleogeography and tectonic evolution of Iran. Can J Earth Sci 18: 210-265. doi: 10.1139/e81-019
|
| [9] |
Lees GM, Falcon NL (1952) The geographical history of the Mesopotamian plains. Geogr J 118: 24-39. doi: 10.2307/1791234
|
| [10] | Purser BH (1973) Sedimentation around bathymetric highs in the southern Persian Gulf, In: Purser BH, The Persian Gulf: Holocene carbonate sedimentation and diagenesis in a shallow epicontinental sea, Berlin and New York: Springer-Verlag, 157-177. |
| [11] | Kassler P (1973) The structural and geomorphic evolution of the Persian Gulf, In: PurserBH, The Persian Gulf: Holocene carbonate sedimentation and diagenesis in a shallow epicontinental sea, Berlin and New York: Springer-Verlag, 11-32. |
| [12] |
Baltzer F, Purser BH (1990) Modern alluvial fan and deltaic sedimentation in a foreland Tectonic setting: the lower Mesopotamian plain and the Arabian Gulf. Sediment Geol 67: 175-195. doi: 10.1016/0037-0738(90)90034-Q
|
| [13] |
Stocklin JA (1974) Northern Iran: Alborz Mountains, Mesozoic-Cenozoic orogenic Belt, data for orogenic studies. Geological Society of London Special Publication, 4: 213-234. doi: 10.1144/GSL.SP.2005.004.01.12
|
| [14] |
Takin M (1972) Iranian geology and continental drift in the Middle East. Nature 235: 147-150. doi: 10.1038/235147a0
|
| [15] |
Alavi M (2007) Structures of the Zagros fold-thrust belt in Iran. Am J Sci 307: 1064-1095. doi: 10.2475/09.2007.02
|
| [16] | Sharland PR, Archer DM, Casey RB, et al. (2001) Arabian plate sequence stratigraphy. Gulf Petro link: Manama, Bahrain, 371-384. |
| [17] |
Mohseni H, Al-Aasm IS (2004) Tempestite deposits on the storm influenced carbonate ramp: An example from the Pabdeh Formation (Paleogene), Zagros basin, SW Iran. J Pet Geol 27: 163-178. doi: 10.1111/j.1747-5457.2004.tb00051.x
|
| [18] | Mohseni H, Behbahani R, Khodabakhsh S, et al. (2011) Depositional environments and trace fossil assemblages in the Pabdeh Formation (Paleogene). Zagros Basin, Iran. Neues Jahrb Geol Paläontol 262: 59-77. |
| [19] |
Bolourchifard F, Fayazi F, Mehrabi B, et al. (2019) Evidence of high-energy storm and shallow water facies in Pabdeh sedimentary phosphate deposit, Kuhe-Lar-anticline, SW Iran. Carbonate Evaporite 34: 1703-1721. doi: 10.1007/s13146-019-00520-4
|
| [20] |
Bahrami M (2009) Microfacies and Sedimentary Environments of Gurpi and Pabdeh Formations in Southwest of Iran. Am J Appl Sci 6: 1295-1300. doi: 10.3844/ajassp.2009.1295.1300
|
| [21] |
Rezaee P, Nejad SAA (2014) Depositional evolution and sediment facies pattern of the tertiary basin in southern Zagros, South Iran. Asian J Earth Sci 7: 27-39. doi: 10.3923/ajes.2014.27.39
|
| [22] | Wilson JL (1975) Carbonate Facies in Geologic History. Berlin, Germany: Springer-Verlag, 471. |
| [23] | Carozzi AV, Gerber MS (1978) Sedimentary Chert Breccia: A Mississippian Tempestite. J Sediment Pet 48: 705-708. |
| [24] |
Bourgeois JA (1980) Transgressive Shelf Sequence Exhibiting Hummocky Stratification: The Cape Sebastian Sandstone (Upper Cretaceous), Southwestern Oregon. J Sediment Pet 50: 681-702. doi: 10.1306/212F7AC2-2B24-11D7-8648000102C1865D
|
| [25] | Kreisa RD (1981) Storm-Generated Sedimentary Structures in Subtidal Marine with Examples from the Middle and Upper Ordovician of Southwestern Virginia. J Sediment Pet 51: 823-848. |
| [26] | Walker RG (1984) General Introduction: facies, facies sequences and facies models, In: Walker RG, Facies Models, Canada: Geoscience, 1-9. |
| [27] | Vera JA, Molina JM (1998) Shallowing-upward cycles in pelagic troughs. (Upper Jurassic, Subbetic, Southern Spain). Sediment Geol 119: 103-121. |
| [28] | Cheel RJ, Leckie DA (1993) Coarse grained storm beds of the upper Cretaceous Chungo Member (Wapiabi Formation), Southern Alberta, Canadian. J Sediment Pet 62: 933-945. |
| [29] | Molina JM, Ruiz-Ortiz PA, Vera JA (1997) Calcareous tempestites in pelagic facies (Jurassic, Betic Cordilleras, Southern Spain). J Sediment Pet 109: 95-109. |
| [30] | Hips K (1998) Lower Triassic storm-dominated ramp sequence in northern Hungary: an example of evolution from homoclinal through distally steepened ramp to Middle Triassic flat-toped platform, In: Wright V, Burchette TP, Carbonate Ramps, London: Geological Society of London, Special Publication, 149: 315-338. |
| [31] | Abed AM (2013) The eastern Mediterranean phosphorite giants: An interplay between tectonics and upwelling. GeoArabia 18: 67-94. |
| [32] | Jasinski SM (2003) Phosphate rock. United States Geological Survey Minerals Yearbook, 56.1-56.5. |
| [33] | Jasinski SM (2011) Phosphate rock. Mineral Commodity Summaries 2011, United States Geological Survey, United States Government Printing Office, Washington, D.C. |
| [34] | Van Kauwenbergh SJ (2010) World phosphate rock reserves and resources. International Fertilizer Development Center (IFDC), Technical Bulletin no. 75, Muscle Shoals, Alabama, USA, 58. |
| [35] |
Lucas J, Prévôt L (1975) Les marges continentales, pièges géochimiques, l'example de la marge atlantique de l'Afrique a la limite Crétacé-Tertiaire. Bull Soc Géol Fr 7: 496-501. doi: 10.2113/gssgfbull.S7-XVII.4.496
|
| [36] |
Notholt AJG (1980) Economic phosphatic sediments-mode of occurrence and stratigraphical distribution. J Geol Soc Lond 137: 793-805. doi: 10.1144/gsjgs.137.6.0793
|
| [37] | Lucas J, Prévôt L (1995) Tethyan phosphates and bioproductites, In: Nairn AEM, Stehli FG, The Ocean Basins and Margins-The Tethys Ocean, Plenum Press, 8: 367-391. |
| [38] |
Follmi KB (1996) The phosphorus cycle, phosphogenesis and marine phosphate-rich deposits. Earth-Sci Rev 40: 55-124. doi: 10.1016/0012-8252(95)00049-6
|
| [39] |
Soudry D, Glenn CR, Nathan Y, et al. (2006) Evolution of the Tethyan phosphogenesis along the northern edges of the Arabian-African shield during the Cretaceous-Eocene as deduced from temporal variations in Ca and Nd isotopes and rates of P accumulation. Earth-Sci Rev 78: 27-57. doi: 10.1016/j.earscirev.2006.03.005
|
| [40] | Al-Bassam KS (1989) The Akashat phosphate deposits, Iraq. In: NothoIt AJG, Sheldon RP, Davison DF, Phosphate Deposit of the World, Phosphate Rock Resources, Cambridge Univ. Press, 2: 316-322. |
| [41] | Jones RW, Racey A (1994) Cenozoic stratigraphy of the Arabian Peninsula and Gulf. In: Simmons MD, Micropalaeontology and Hydrocarbon Exploration in the Middle East. London, Chapman and Hall, 273-307. |
| [42] | Bramkamp RA (1941) Unpublished report, In: Cavelier C, Geological description of the Qatar Peninsula, Qatar, Bureau de recherches géologiques et minières, 39. |
| [43] |
Soudry D, Nathan Y, Ehrlich S (2013) Geochemical diagenetic trends during phosphorite formation-economic implications: The case of the Negev Campanian phosphorites, Southern. Sedimentology 60: 800-819. doi: 10.1111/j.1365-3091.2012.01361.x
|
| [44] | Follmi KB, Garrison RE (1991) Phosphatic sediments, ordinary or extraordinary deposits? The example of the Miocene Monterey Formation (California), In: Muller DW, McKenzie JA, Weissert H, Geologic Events and Non-Uniform Sedimentation, London, Academic Press, 55-84. |
| [45] | Zaïer A, Beji-Sassi A, Sassi S, et al. (1998) Basin evolution and deposition during the Early Paleocene in Tunisia. In: Macgregor DS, Moody RTJ, ClarkLowes DD, Petroleum Geology of North Africa, London, Geological Society of London Special Publication, 132: 375-393. |
| [46] | Burollet PF (1956) Contribution à l'étude stratigraphique de la Tunisie Centrale. Ann Mines Géol 18: 352. |
| [47] | Fournier D (1978) Nomenclature lithostratigraphique des série du Crétacé supérieur au Tertiaire de Tunisie. Bull Cent Rech Explor Prod Elf-Aquitaine 2: 97-148. |
| [48] | Sassi S (1974) La sédimentation phosphatée au Paléocène dans le Sud et le Centre Ouest de la Tunisie. Thesis Doctorat. d'Etat ès-Sciences, Université de Paris-Orsay, France, 300. |
| [49] | Chaabani F (1995) Dynamique de la partie orientale du bassin de Gafsa au Crétacé ET au Paléogène: Etude minéralogique ET géochimique de la série phosphate Eocène, Tunisie méridionale. Thèse Doc. Etat, Univ. Tunis II. Tunisie. |
| [50] |
Henchiri M, Slim-S'Himi N (2006) Silicification of sulfate evaporites and their carbonate replacement in Eocene marine sediments, Tunisia, two diagenetic trends. Sedimentology 53: 1135-1159. doi: 10.1111/j.1365-3091.2006.00806.x
|
| [51] | Chaabani F, Ounis A (2008) Sequence stratigraphy and depositional environment of phosphorite deposits evolution: case of the Gafsa basin, Tunisia. Conference abstract at the Intern. Geol. Cong. Oslo. |
| [52] |
Galfati I, Sassi AB, Zaier A, et al. (2010) Geochemistry and mineralogy of Paleocene-Eocene Oum El Khecheb phosphorites (Gafsa-Metlaoui Basin) Tunisia. Geochem J 44: 189-210. doi: 10.2343/geochemj.1.0062
|
| [53] |
Kocsis L, Gheerbrant E, Mouflih M, et al. (2014) Comprehensive stable isotope investigation of marine biogenic apatite from the late Cretaceous-early Eocene phosphate series of Morocco. Palaeogeogr Palaeoclimatol Palaeoecol 394: 74-88. doi: 10.1016/j.palaeo.2013.11.002
|
| [54] |
Messadi AM, Mardassi B, Ouali JA, et al. (2016) Sedimentology, diagenesis, clay mineralogy and sequential analysis model of Upper Paleocene evaporitecarbonate ramp succession from Tamerza area (Gafsa Basin: Southern Tunisia). J Afr Earth Sci 118: 205-230. doi: 10.1016/j.jafrearsci.2016.02.020
|
| [55] | El-Naggar ZR, Saif SI, Abdennabi A (1982) Stratigraphical analysis of the phosphate deposits in Northwestern Saudi Arabia. Progress report 1-4 submitted to SANCST, Riyadh. Saudi Arabia. |
| [56] |
Baioumy H, Tada R (2005) Origin of Late Cretaceous phosphorites in Egypt. Cretaceous Res 26: 261-275. doi: 10.1016/j.cretres.2004.12.004
|
| [57] | Scotese CR (2014) The PALEOMAP Project Paleo Atlas for ArcGIS, version 2, Volume 1, Cenozoic Plate Tectonic, Paleogeographic, and Paleoclimatic Reconstructions, PALEOMAP Project, Evanston, IL, Maps 1-15. |
| [58] |
Wade BS, Pearson PN, Berggren, WA, et al. (2011) Review and revision of Cenozoic tropical planktonic foraminiferal biostratigraphy and calibration to the geomagnetic polarity and astronomical time scale. Earth-Sci Rev 104: 111-142. doi: 10.1016/j.earscirev.2010.09.003
|
| [59] | Dunham RJ (1962) Classifications of carbonate rocks according to depositional texture. In: Ham WE, Classification of Carbonate Rocks-A Symposium, AAPG Special Publications, 108-121. |
| [60] | Flugel E (2010) Microfacies of Carbonate Rocks, Analysis, Interpretation and Application, 2nd Edition. Berlin: Springer-Verlag, 984. |
| [61] | Omidvar M, Safari A, Vaziri-Moghaddam H, et al. (2016) Facies analysis and paleoenvironmental reconstruction of upper cretaceous sequences in the eastern Para-Tethys basin, NW Iran. Geol Acta 14: 363-384. |
| [62] |
Baioumy H, Omran M, Fabritius T (2017) Mineralogy, geochemistry and the origin of high-phosphorus oolitic iron ores of Aswan, Egypt. Ore Geol Rev 80: 185-199. doi: 10.1016/j.oregeorev.2016.06.030
|
| [63] |
Donnelly TH, Shergold JH, Southgate PN, et al. (1990) Events leading to global phosphogenesis around the Proterozoic-Cambrian transition, In: Notholt AJG, Jarvis I, Phosphorite research and development, London: Journal Geology Society London. Special Publication, 52: 273-287. doi: 10.1144/GSL.SP.1990.052.01.20
|
| [64] | Trappe J (1998) Phanerozoic phosphorite depositional systems: A dynamic model for a sedimentary resource system, Lecture Notes in Earth Science 76: 1-316. |
| [65] |
Piper DZ (1991) Geochemistry of a Tertiary sedimentary phosphate deposit: Baja California Sur, Mexico. Chem Geol 92: 283-316. doi: 10.1016/0009-2541(91)90075-3
|
| [66] |
Soudry D, Ehrlich S, Yoffe O, et al. (2002) Uranium oxidation state and related variations in geochemistry of phosphorites from the Negev (southern). Chem Geol 189: 213-230. doi: 10.1016/S0009-2541(02)00144-4
|
| [67] | Jarvis I, Burnett WC, Nathan Y, et al. (1994) Phosphorite geochemistry: state-of-the-art and environmental concerns. Eclogae Geol Helv 87: 643-700. |
| [68] |
Garnit H, Bouhlel S, Jarvis I (2017) Geochemistry and depositional environments of Paleocene-Eocene phosphorites: Metlaoui Group, Tunisia. J Afr Earth Sci 134: 704-736. doi: 10.1016/j.jafrearsci.2017.07.021
|
| [69] |
McArthur JM (1985) Francolite geochemistry-compositional controls during formation, diagenesis, metamorphism and weathering. Geochim Cosmochim Acta 49: 23-35. doi: 10.1016/0016-7037(85)90188-7
|
| [70] |
McArthur JM (1978) Systematic variations in the contents of Na, Sr, CO2 and SO4 in marine carbonate fluorapatite and their relation to weathering. Chem Geol 21: 41-52. doi: 10.1016/0009-2541(78)90008-6
|
| [71] | Altschuler ZS (1980) The geochemistry of trace elements in marine phosphorites. Part I: characteristic abundances and enrichment, In: Bentor YK, Marine Phosphorites, London: SEPM Special Publication, 29: 19-30. |
| [72] | Prévôt L (1990) Geochemistry, Petrography, Genesis of Cretaceous-Eocene Phosphorites. Soc Geol Fr Mem 158: 1-232. |
| [73] |
Jiang SY, Zhao HX, Chen YQ, et al. (2007) Trace and rare earth element geochemistry of phosphate nodules from the lower Cambrian black shale sequence in the Mufu Mountain of Nanjing, Jiangsu province, China. Chem Geol 244: 584-604. doi: 10.1016/j.chemgeo.2007.07.010
|
| [74] | Prevot L, Lucas J (1980) Behaviour of some trace elements in phosphatic sedimentary formations. Society of Economic Paleontologists and Mineralogists, Special Publication 29: 31-40. |
| [75] |
Gulbrandsen RA (1966) Chemical composition of the phosphorites of the Phosphoria Formation. Geochim cosmochim Acta. 30: 769-778. doi: 10.1016/0016-7037(66)90131-1
|
| [76] | Slansky M (1986) Geology of sedimentary phosphate (Studies in Geology), 1st English edition, North Oxford Academic Publishers Limited, 59-159. |
| [77] | Iylin AV, Volkov RI (1994) Uranium Geochemistry in Vendian-Cambrian Phosphorites. Geokhimiya 32: 1042-1051. |
| [78] | Sokolov AS (1996) Evolution of Uranium Mineralization in Phosphorites. Geokluntiva 11:1117-1119. |
| [79] | Zanin YN, Zanrirailova AG, Gilinskaya LG, et al. (2000) Uranium in the Sedimentary Apatite during Catagenesis. Geokhimiya 5: 502-509. |
| [80] |
Baturin GN, Kochenov AV (2001) Uranium in phosphorites. Lithol Miner Resour 36: 303-321. doi: 10.1023/A:1010406103447
|
| [81] |
Smirnov KM, Men'shikov YA, Krylova OK, et al. (2015) Form of Uranium Found in Phosphate Ores in Northern Kazakhstan. At Energy 118: 337-340. doi: 10.1007/s10512-015-0003-9
|
| [82] |
Cunha CSM, da Silva YJAB, Escobar MEO, et al. (2018) Spatial variability and geochemistry of rare earth elements in soils from the largest uranium-phosphate deposit of Brazil. Environ Geochem Health 40: 1629-1643. doi: 10.1007/s10653-018-0077-0
|
| [83] | Lucas J, Prevot J, Larnboy M (1978) Les phosphorites de in marge norde de I' Espagne, Cl imie mineralogy, Genese. Oceanol Acta 1: 55-72. |
| [84] | Saigal N, Banerjee DM (1987) Proterozoic phosphorites of India: updated information. Part 1: Petrography, In: Kale VS, Phansalkar VG, Purana Basins of Peninsular India, India: Geological Society of India Memoir, 6: 471-486. |
| [85] | Dooley JH (2001) Baseline Concentrations of Arsenic, Beryllium and Associated Elements in Glauconite and Glauconitic Soils in the New Jersey Coastal Plain, The New Jersey Geological Survey, Investigation Report, Trenton NJ, 238. |
| [86] |
Barringer JL, Reilly PA, Eberl DD, et al. (2011) Arsenic in sediments, groundwater, and stream water of a glauconitic Coastal Plain terrain, New Jersey, USA. Appl Geochem 26: 763-776. doi: 10.1016/j.apgeochem.2011.01.034
|
| [87] | Liu YG, Mia MRU, Schmitt RA (1988) Cerium: A chemical tracer for paleo oceanic redox conditions. Geochim Cosmochim Acta 52: 2362-2371. |
| [88] |
German CR, Elderfield H (1990) Application of the Ce anomaly as a paleoredox indicator: the ground rules. Paleoceanography 5: 823-833. doi: 10.1029/PA005i005p00823
|
| [89] |
Murray RW, Brink MRB, Ten Gerlach DC, et al. (1991) Rare earth, major, and trace elements in chert from the Franciscan Complex and Monterey Group, California: Assessing REE sources to fine-grained marine sediments. Geochim Cosmochim Acta 55: 1875-1895. doi: 10.1016/0016-7037(91)90030-9
|
| [90] |
Nath BN, Roelandts I, Sudhakar M, et al. (1992) Rare Earth Element patterns of the Central Indian Basin sediments related to their lithology. Geophys Res Lett 19: 1197-1200. doi: 10.1029/92GL01243
|
| [91] | Madhavaraju J, Ramasamy S (1999) Rare earth elements in Limestones of Kallankurichchi Formation of Ariyalur Group, Tiruchirapalli Cretaceous, Tamil Nadu. J Geol Soc India 54: 291-301. |
| [92] |
Armstrong-Altrin JS, Verma SP, Madhavaraju J, et al. (2003) Geochemistry of Late Miocene Kudankulam Limestones, South India. Int Geol Rev 45: 16-26. doi: 10.2747/0020-6814.45.1.16
|
| [93] |
Madhavaraju J, González-León CM, Lee YI, et al. (2010) Geochemistry of the Mural Formation (Aptian-Albian) of the Bisbee Group, Northern Sonora, Mexico. Cretac Res 31: 400-414. doi: 10.1016/j.cretres.2010.05.006
|
| [94] |
Wang YL, Liu YG, Schmitt RA (1986) Rare earth element geochemistry of South Atlantic deep sea sediments: Ce anomaly change at ~54 My. Geochim Cosmochim Acta 50: 1337-1355. doi: 10.1016/0016-7037(86)90310-8
|
| [95] |
Kato Y, Nakao K, Isozaki Y (2002) Geochemistry of Late Permian to Early Triassic pelagic cherts from southwest Japan: implications for an oceanic redox change. Chem Geol 182: 15-34. doi: 10.1016/S0009-2541(01)00273-X
|
| [96] |
Kamber BS, Webb GE (2001) The geochemistry of late Archaean microbial carbonate: implications for ocean chemistry and continental erosion history. Geochim Cosmochim Acta 65: 2509-2525. doi: 10.1016/S0016-7037(01)00613-5
|
| [97] |
Kemp RA, Trueman CN (2003) Rare earth elements in Solnhofen biogenic apatite: geochemical clues to the palaeoenvironment. Sediment Geol 155: 109-127. doi: 10.1016/S0037-0738(02)00163-X
|
| [98] |
Bakkiaraj D, Nagendra R, Nagarajan R, et al. (2010) Geochemistry of Siliciclastic rocks of Sillakkudi Formation, Cauvery Basin, Southern India; Implications for Provenance. J Geol Soc India 76: 453-467. doi: 10.1007/s12594-010-0128-3
|
| [99] |
McArthur JM, Walsh JN (1984) Rare-earth geochemistry of phosphorites. Chem Geol 47: 191-220. doi: 10.1016/0009-2541(84)90126-8
|
| [100] |
Kidder DL, Krishnaswamy R, Mapes RH (2003) Elemental mobility in phosphatic shales during concretion growth and implications for provenance analysis. Chem Geol 198: 335-353. doi: 10.1016/S0009-2541(03)00036-6
|
| [101] | Cossa M (1878) Sur la diffusion de cerium, du lanthane et du didyme, extract of a letter from Cossa to Sella, presented by Freny. C R Ac Sci 87: 378-388. |
| [102] | McKelvey VE (1967) Rare Earths in Western Phosphate Rocks. US Geological Survey Professional paper, 1-17. |
| [103] |
Kocsis L, Gheerbrant E, Mouflih M, et al. (2016) Gradual changes in upwelled seawater conditions (redox, pH) from the late Cretaceous through early Paleogene at the northwest coast of Africa: negative Ce anomaly trend recorded in fossil bio-apatite. Chem Geol 421: 44-54. doi: 10.1016/j.chemgeo.2015.12.001
|
| [104] | Altschuler ZS, Berman S, Cuttiti F (1967) Rare earths in phosphorites-geochemistry and potential recovery, U. S. Geological Survey Professional paper, 575: 1-9. |
| [105] |
Kon Y, Hoshino M, Sanematsu K, et al. (2014) Geochemical characteristics of apatite in heavy REE-rich deep-sea mud from Minami-Torishima area, southeastern Japan. Resour Geol 64: 47-57. doi: 10.1111/rge.12026
|
| [106] | Taylor SR (1985) An examination of the geochemical record preserved in sedimentary rocks. In: Taylor SR, McLennan SM, The Continental Crust; Its composition and evolution, Blackwell, Oxford, 312. |
| [107] |
Shields G, Stille P (2001) Diagenetic constraints on the use of cerium anomalies as palaeoseawater redox proxies: an isotopic and REE study of Cambrian phosphorites. Chem Geo 175: 29-48. doi: 10.1016/S0009-2541(00)00362-4
|
| [108] |
Elderfield H, Greaves MJ (1982) The rare earth elements in seawater. Nature 296: 214-219. doi: 10.1038/296214a0
|
| [109] |
De Baar HJW, Bacon MP, Brewer PG (1985) Rare earth elements in the Pacific and Atlantic Oceans. Geochim Cosmochim Acta 49: 1943-1959. doi: 10.1016/0016-7037(85)90089-4
|
| [110] |
Pattan JN, Pearce NJG, Mislankar PG (2005) Constraints in using Cerium-anomaly of bulk sediments as an indicator of paleo bottom water redox environment: A case study from the Central Indian Ocean Basin. Chem Geol 221: 260-278. doi: 10.1016/j.chemgeo.2005.06.009
|
| [111] |
Daesslé LW, Carriquiry JD (2008) Rare Earth and Metal Geochemistry of Land and SubmarinePhosphorites in the Baja California Peninsula, Mexico. Mar Georesour Geotechnol 26: 340-349. doi: 10.1080/10641190802382633
|
| [112] | Stoneley R (1990) The Arabian continental margin in Iran during the late Cretaceous, In: Roberston AHF, Searl MP, Ries A, The geology and tectonics of the Oman region, London: Geological Society of London Special Publication, 49: 787-795. |
| [113] |
Bolourchifard F, Fayazi F, Mehrabi B, et al. (2019) Evidence of high-energy storm and shallow water facies in Pabdeh sedimentary phosphate deposit, Kuhe-Lar-anticline, SW Iran. Carbonate Evaporite 34: 1703-1721. doi: 10.1007/s13146-019-00520-4
|
| [114] | Daneshian J, Shariati S, Salsani A (2015) Biostratigraphy and planktonic foraminiferal abundance in the phosphate bearing pabdeh Formation of the lar mountains (SW Iran). Neues Jahrb Geol Paläontol 278: 175-189. |
| [115] |
Rees A, Thomas A, Lewis M, et al. (2014) Lithostratigraphy and palaeoenvironments of the Cambrian in SW Wales. Geol Soc London 42: 33-100. doi: 10.1144/M42.2
|
| [116] |
Vaziri-Moghaddam H, Kimiagari M, Taheri A (2006) Depositional environment and sequence stratigraphy of the Oligo-MioceneAsmari Formationin SW Iran. Facies 52: 41-51. doi: 10.1007/s10347-005-0018-0
|
| [117] | Murris RJ (1980) Middle East: stratigraphic evolution and oil habitat. Am Assoc Pet Geol Bull 64: 597-618. |
| [118] |
Price NB, Calvert SE (1978) The geochemistry of phosphorites from the Namibian shelf. Chem Geol 23: 151-170. doi: 10.1016/0009-2541(78)90072-4
|
| [119] |
Froelich PN, Arthur MA, Burnett WC, et al. (1988) Early diagenesis in organic matter in Peru continental margin sediments: Phosphorite precipitation. Mar Geol 80: 309-343. doi: 10.1016/0025-3227(88)90095-3
|
| [120] |
Tribovillard N, Algeo TJ, Lyons T, et al. (2006) Trace metals as paleoredox and paleoproductivity proxies: an update. Chem Geol 232: 12-32. doi: 10.1016/j.chemgeo.2006.02.012
|
| [121] | MacLeod KG, Irving AJ (1996) Correlation of cerium anomalies with indicators of paleoenvironment. J Sediment Res 66: 948-988. |
| [122] |
Shields G, Stille P, Brasier MD, et al. (1997) Stratified oceans and oxygenation of the late Proterozoic environment: a post glacial geochemical record from the Neoproterozoic of W Mongolia. Terra Nov 9: 218-222. doi: 10.1111/j.1365-3121.1997.tb00016.x
|
 geosci-06-03-019-s001.pdf geosci-06-03-019-s001.pdf |
 |
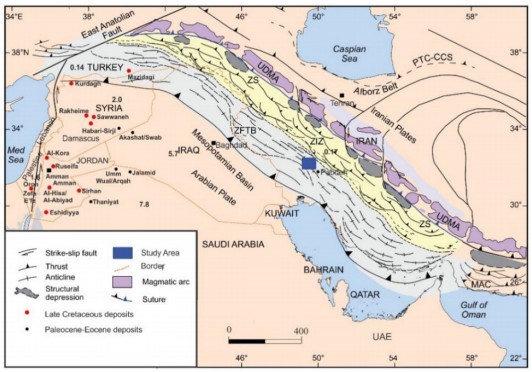
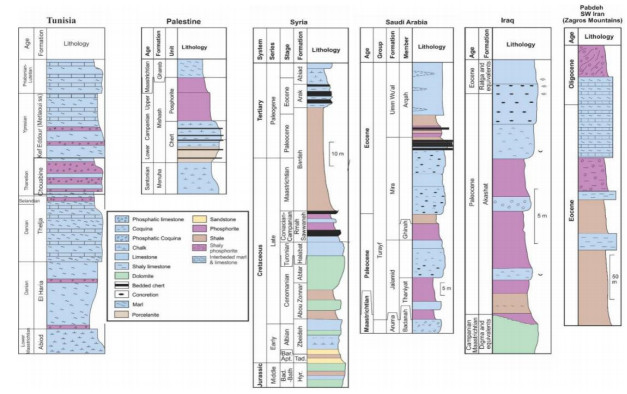
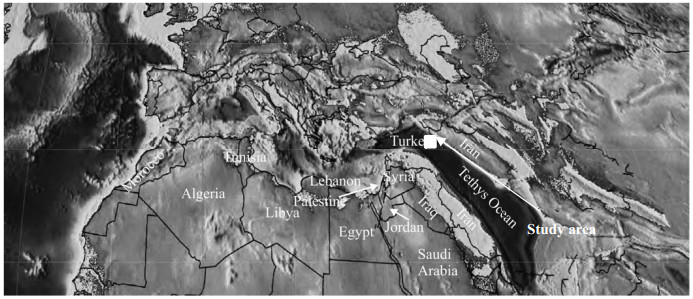
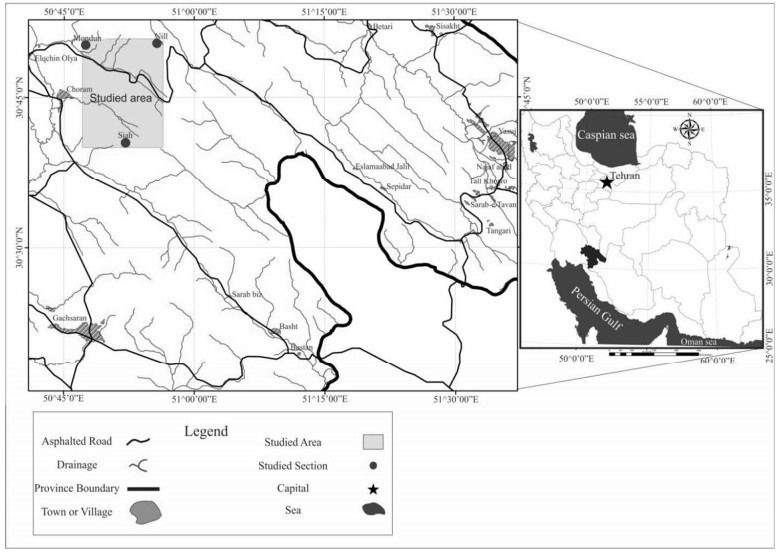




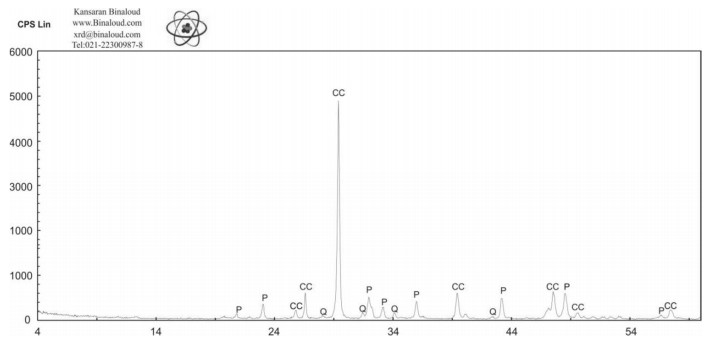
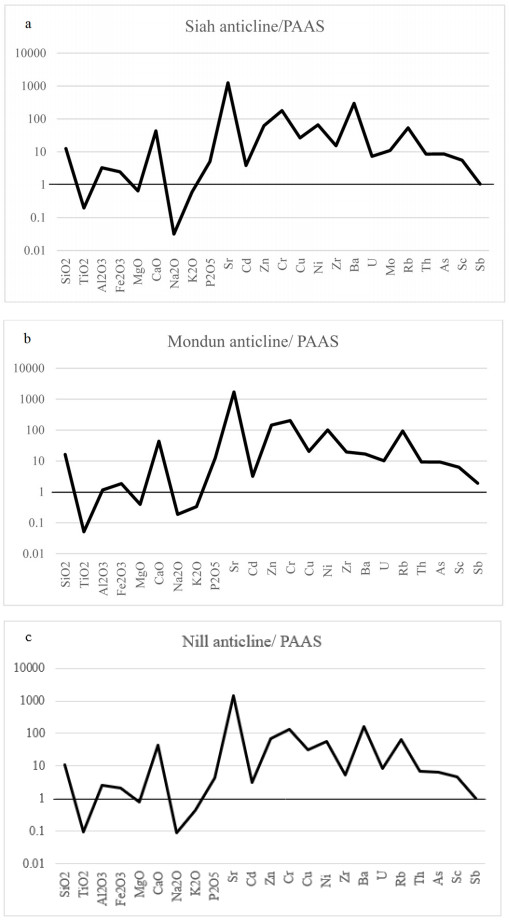


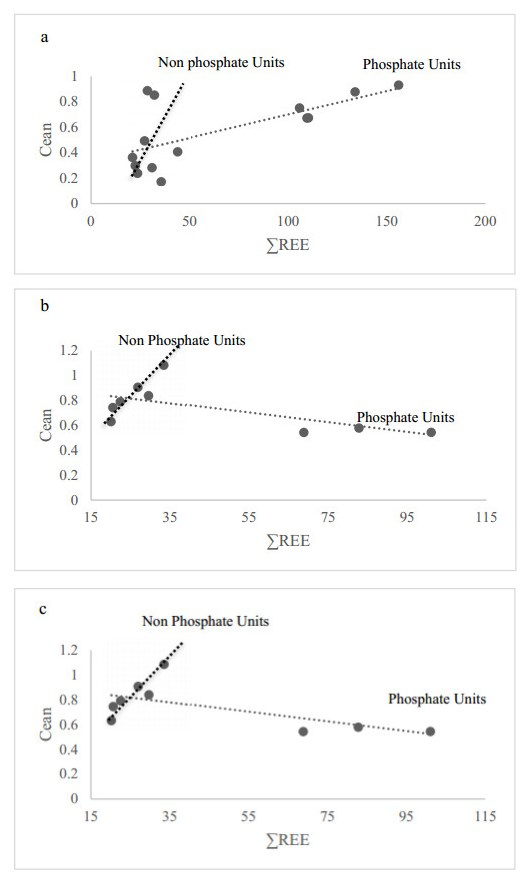

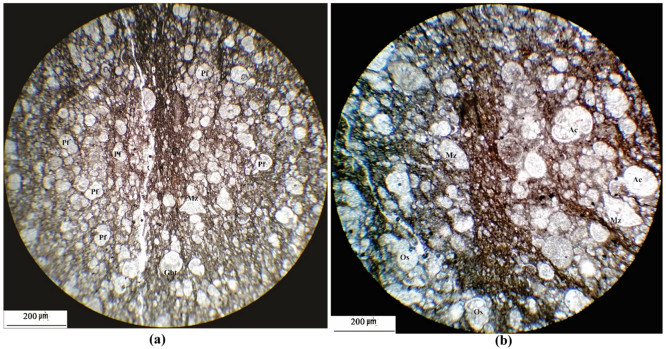


Figures(18) / Tables(5)

Armin Salsani, Abdolhossein Amini, Shahram shariati, Seyed Ali Aghanabati, Mohsen Aleali. Geochemistry, facies characteristics and palaeoenvironmental conditions of the storm-dominated phosphate-bearing deposits of eastern Tethyan Ocean; A case study from Zagros region, SW Iran[J]. AIMS Geosciences, 2020, 6(3): 316-354. doi: 10.3934/geosci.2020019







 DownLoad:
DownLoad: