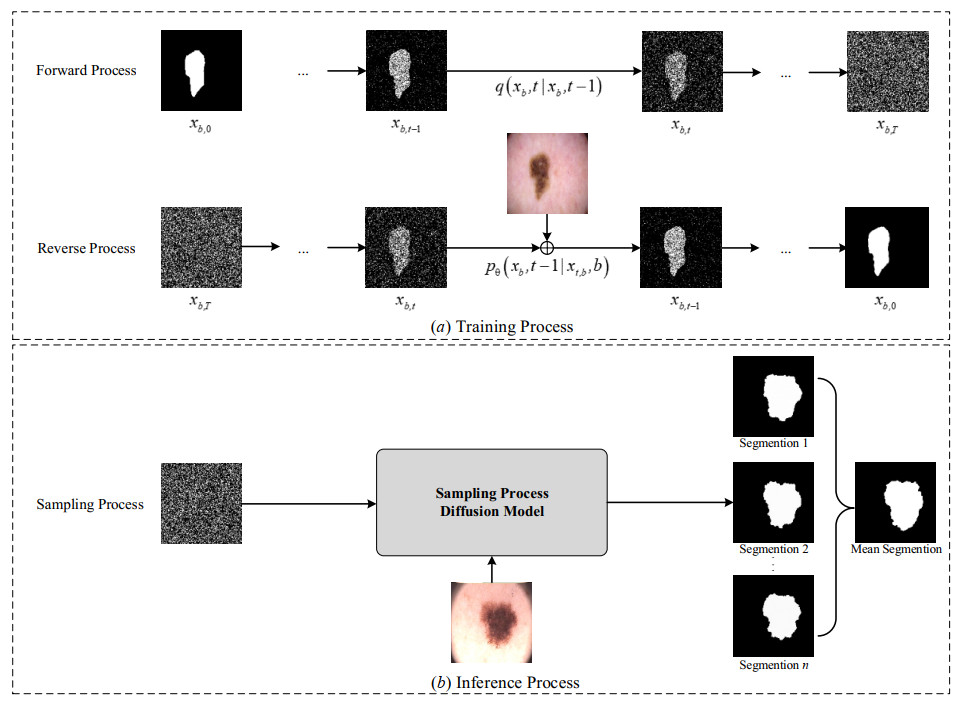
Denoising diffusion probabilistic models (DDPM) have had remarkable success in image generation. Inspired by this, recent medical image segmentation tasks have started to use diffusion-based methods. These methods leverage iterations and sampling to generate smoother and more representative implicit integration. However, current diffusion-based segmentation models mainly rely on traditional neural networks and seldom focus on effectively interacting semantic and noise information. Moreover, they usually use a single network architecture instead of a hybrid one combining CNN and Transformer. To address limitations, we propose a dual-path U-Net segmentation diffusion (DPUSegDiff) model. It comprises two U-shaped networks based on the edge augmented local encoder (EALE) and the mixed transformer global encoder (MTGE). EALE uses the Sobel operator for local feature extraction, and MTGE has a cross-attention mechanism to facilitate information interaction. To integrate information from both paths selectively and adaptively, we design a bilateral gated transformer module (BGTM) to combine deep semantic information effectively. Experiments on three segmentation tasks—skin lesions, polyps, and brain tumors—show that the proposed DPUSegDiff outperforms other state-of-the-art (SOTA) methods in segmentation performance and generalization ability. The code has been released on GitHub (https://github.com/Fanyyz/DPUSegDiff).
Citation: Yazhuo Fan, Jianhua Song, Yizhe Lu, Xinrong Fu, Xinying Huang, Lei Yuan. DPUSegDiff: A Dual-Path U-Net Segmentation Diffusion model for medical image segmentation[J]. Electronic Research Archive, 2025, 33(5): 2947-2971. doi: 10.3934/era.2025129
Denoising diffusion probabilistic models (DDPM) have had remarkable success in image generation. Inspired by this, recent medical image segmentation tasks have started to use diffusion-based methods. These methods leverage iterations and sampling to generate smoother and more representative implicit integration. However, current diffusion-based segmentation models mainly rely on traditional neural networks and seldom focus on effectively interacting semantic and noise information. Moreover, they usually use a single network architecture instead of a hybrid one combining CNN and Transformer. To address limitations, we propose a dual-path U-Net segmentation diffusion (DPUSegDiff) model. It comprises two U-shaped networks based on the edge augmented local encoder (EALE) and the mixed transformer global encoder (MTGE). EALE uses the Sobel operator for local feature extraction, and MTGE has a cross-attention mechanism to facilitate information interaction. To integrate information from both paths selectively and adaptively, we design a bilateral gated transformer module (BGTM) to combine deep semantic information effectively. Experiments on three segmentation tasks—skin lesions, polyps, and brain tumors—show that the proposed DPUSegDiff outperforms other state-of-the-art (SOTA) methods in segmentation performance and generalization ability. The code has been released on GitHub (https://github.com/Fanyyz/DPUSegDiff).

| [1] |
S. Minaee, Y. Boykov, F. Porikli, A. Plaza, N. Kehtarnavaz, D. Terzopoulos, Image segmentation using deep learning: A survey, IEEE Trans. Pattern Anal. Mach. Intell., 44 (2022), 3523–3542. https://doi.org/10.1109/TPAMI.2021.3059968 doi: 10.1109/TPAMI.2021.3059968

|
| [2] |
R. Wang, T. Lei, R. Cui, B. Zhang, H. Meng, A. K. Nandi, Medical image segmentation using deep learning: A survey, IET Image Process., 16 (2022), 1243–1267. https://doi.org/10.1049/ipr2.12419 doi: 10.1049/ipr2.12419
|
| [3] |
U. Ilhan, A. Ilhan, Brain tumor segmentation based on a new threshold approach, Procedia Comput. Sci., 120 (2017), 580–587. https://doi.org/10.1016/j.procs.2017.11.282 doi: 10.1016/j.procs.2017.11.282
|
| [4] |
A. Pratondo, C. K. Chui, S. H. Ong, Integrating machine learning with region-based active contour models in medical image segmentation, J. Visual Commun. Image Represent., 43 (2017), 1–9. https://doi.org/10.1016/j.jvcir.2016.11.019 doi: 10.1016/j.jvcir.2016.11.019
|
| [5] |
P. Singh, Y. P. Huang, An ambiguous edge detection method for computed tomography scans of Coronavirus Disease 2019 cases, IEEE Trans. Syst. Man Cybern.: Syst., 54 (2024), 352–364. https://doi.org/10.1109/TSMC.2023.3307393 doi: 10.1109/TSMC.2023.3307393
|
| [6] |
P. Singh, Y. P. Huang, AKDC: Ambiguous kernel distance clustering algorithm for COVID-19 CT scans analysis, IEEE Trans. Syst. Man Cybern.: Syst., 54 (2024), 6218–6229. https://doi.org/10.1109/TSMC.2024.3418411 doi: 10.1109/TSMC.2024.3418411
|
| [7] |
P. Singh, S. S. Bose, A quantum-clustering optimization method for COVID-19 CT scan image segmentation, Expert Syst. Appl., 185 (2021), 115637. https://doi.org/10.1016/j.eswa.2021.115637 doi: 10.1016/j.eswa.2021.115637
|
| [8] |
E. Shelhamer, J. Long, T. Darrell, Fully convolutional networks for semantic segmentation, IEEE Trans. Pattern Anal. Mach. Intell., 39 (2017), 640–651. https://doi.org/10.1109/TPAMI.2016.2572683 doi: 10.1109/TPAMI.2016.2572683
|
| [9] | O. Ronneberger, P. Fischer, T. Brox, U-Net: Convolutional networks for biomedical image segmentation, in Medical Image Computing and Computer-Assisted Intervention - MICCAI 2015, Lecture Notes in Computer Science, Springer, 9351 (2015), 234–241.https://doi.org/10.1007/978-3-319-24574-4_28 |
| [10] |
Y. Fan, J. Song, L. Yuan, Y. Jia, HCT-Unet: Multi-target medical image segmentation via a hybrid CNN-transformer Unet incorporating multi-axis gated multi-layer perceptron, Vis. Comput., 41 (2024), 3457–3472. https://doi.org/10.1007/s00371-024-03612-y doi: 10.1007/s00371-024-03612-y
|
| [11] |
A. Pratondo, C. K. Chui, S. H. Ong, Robust edge-stop functions for edge-based active contour models in medical image segmentation, IEEE Signal Process. Lett., 23 (2016), 222–226. https://doi.org/10.1109/LSP.2015.2508039 doi: 10.1109/LSP.2015.2508039
|
| [12] | J. Ho, A. Jain, P. Abbeel, Denoising diffusion probabilistic models, in Proceedings of the 34th International Conference on Neural Information Processing Systems (NIPS'20), Curran Associates Inc., (2020), 6840–6851. |
| [13] |
H. Li, Y. Yang, M. Chang, S. Chen, H. Feng, Z. Xu, et al., SRDiff: Single image super-resolution with diffusion probabilistic models, Neurocomputing, 479 (2022), 47–59. https://doi.org/10.1016/j.neucom.2022.01.029 doi: 10.1016/j.neucom.2022.01.029
|
| [14] | J. Whang, M. Delbracio, H. Talebi, C. Saharia, A. G. Dimakis, P. Milanfar, Deblurring via stochastic refinement, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2022), 16272–16282. https://doi.org/10.1109/CVPR52688.2022.01581 |
| [15] | B. Xia, Y. Zhang, S. Wang, Y. Wang, X. Wu, Y. Tian, DiffIR: Efficient diffusion model for image restoration, in 2023 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, (2023), 13049–13059. https://doi.org/10.1109/ICCV51070.2023.01204 |
| [16] | I. J. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, et al., Generative adversarial networks, preprint, arXiv: 1406.2661. |
| [17] |
B. Lei, Z. Xia, F. Jiang, X. Jiang, Z. Ge, Y. Xu, et al., Skin lesion segmentation via generative adversarial networks with dual discriminators, Med. Image Anal., 64 (2020), 101716. https://doi.org/10.1016/j.media.2020.101716 doi: 10.1016/j.media.2020.101716
|
| [18] | A. Rahman, J. M. J. Valanarasu, I. Hacihaliloglu, V. M. Patel, Ambiguous medical image segmentation using diffusion models, in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2023), 11536–11546, https://doi.org/10.1109/CVPR52729.2023.01110 |
| [19] |
A. Kazerouni, E. K. Aghdam, M. Heidari, R. Azad, M. Fayyaz, I. Hacihaliloglu, et al., Diffusion models in medical imaging: A comprehensive survey, Med. Image Anal., 88 (2023), 102846. https://doi.org/10.1016/j.media.2023.102846 doi: 10.1016/j.media.2023.102846
|
| [20] | T. Amit, T. Shaharbany, E. Nachmani, L. Wolf, SegDiff: Image segmentation with diffusion probabilistic models, preprint, arXiv: 2112.00390. |
| [21] | J. Wolleb, R. Sandkühler, F. Bieder, P. Valmaggia, P. C. Cattin, Diffusion models for implicit image segmentation ensembles, preprint, arXiv: 2112.03145. |
| [22] | J. Wu, R. Fu, H. Fang, Y. Zhang, Y. Yang, H. Xiong, et al., MedSegDiff: Medical image segmentation with diffusion probabilistic model, preprint, arXiv. 2211.00611. |
| [23] | L. C. Chen, Y. Zhu, G. Papandreou, F. Schroff, H. Adam, Encoder-decoder with atrous separable convolution for semantic image segmentation, in Computer Vision – ECCV 2018, Springer, (2018), 833–851. https://doi.org/10.1007/978-3-030-01234-2_49 |
| [24] | Z. Zhou, M. M. R. Siddiquee, N. Tajbakhsh, J. Liang, UNet++: A nested U-Net architecture for medical image segmentation, in Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support (DLMIA), Springer, 11045 (2018), 3–11. https://doi.org/10.1007/978-3-030-00889-5_1 |
| [25] | H. Huang, L. Lin, R. Tong, H. Hu, Q. Zhang, Y. Iwamoto, et al., UNet 3+: A full-scale connected UNet for medical image segmentation, in 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, (2020), 1055–1059, https://doi.org/10.1109/ICASSP40776.2020.9053405 |
| [26] | X. Xiao, S. Lian, Z. Luo, S. Li, Weighted Res-UNet for high-quality retina vessel segmentation, in 2018 9th International Conference on Information Technology in Medicine and Education (ITME), IEEE, (2018), 327–331, https://doi.org/10.1109/ITME.2018.00080 |
| [27] | O. Oktay, J. Schlemper, L. L. Folgoc, M. Lee, M. Heinrich, K. Misawa, et al., Attention U-Net: Learning where to look for the pancreas, preprint, arXiv: 1804.03999. |
| [28] |
Z. Gu, J. Cheng, H. Fu, K. Zhou, H. Hao, Y. Zhao, CE-Net: Context encoder network for 2D medical image segmentation, IEEE Trans. Med. Imaging, 38 (2019), 2281–2292. https://doi.org/10.1109/TMI.2019.2903562 doi: 10.1109/TMI.2019.2903562
|
| [29] | Ö. Çiçek, A. Abdulkadir, S. S. Lienkamp, T. Brox, O. Ronneberger, 3D U-Net: Learning dense volumetric segmentation from sparse annotation, in Medical Image Computing and Computer-Assisted Intervention (MICCAI), Springer, 9901 (2016), 424–432. https://doi.org/10.1007/978-3-319-46723-8_49 |
| [30] | F. Milletari, N. Navab, S. A. Ahmadi, V-Net: Fully convolutional neural networks for volumetric medical image segmentation, in 2016 Fourth International Conference on 3D Vision (3DV), IEEE, (2016), 565–571. https://doi.org/10.1109/3DV.2016.79 |
| [31] | J. Chen, Y. Lu, Q. Yu, X. Luo, E. Adeli, Y. Wang, et al., TransUNet: Transformers make strong encoders for medical image segmentation, preprint, arXiv: 2102.04306. |
| [32] | A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, et al., An image is worth 16 × 16 words: Transformers for image recognition at scale, preprint, arXiv: 2010.11929. |
| [33] | H. Cao, Y. Wang, J. Chen, D. Jiang, X. Zhang, Q. Tian, et al., Swin-Unet: Unet-like pure transformer for medical image segmentation, in Computer Vision – ECCV 2022 Workshops, Springer, 13803 (2023), 205–218. https://doi.org/10.1007/978-3-031-25066-8_9 |
| [34] | Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., Swin transformer: Hierarchical vision transformer using shifted windows, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, (2021), 9992–10002. https://doi.org/10.1109/ICCV48922.2021.00986 |
| [35] | X. Huang, Z. Deng, D. Li, X. Yuan, MISSFormer: An effective medical image segmentation transformer, preprint, arXiv: 2109.07162. |
| [36] |
Z. Zhu, X. He, G. Qi, Y. Li, B. Cong, Y. Liu, Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal MRI, Inf. Fusion, 91 (2023), 376–387. https://doi.org/10.1016/j.inffus.2022.10.022 doi: 10.1016/j.inffus.2022.10.022
|
| [37] |
R. Wang, S. Chen, C. Ji, J. Fan, Y. Li, Boundary-aware context neural network for medical image segmentation, Med. Image Anal., 78 (2022), 102395. https://doi.org/10.1016/j.media.2022.102395 doi: 10.1016/j.media.2022.102395
|
| [38] | Y. Lin, D. Zhang, X. Fang, Y. Chen, K. Cheng, H. Chen, Rethinking boundary detection in deep learning models for medical image segmentation, preprint, arXiv. 2305.00678. |
| [39] |
N. Mathur, S. Mathur, D. Mathur, A novel approach to improve Sobel edge detector, Procedia Comput. Sci., 93 (2016), 431–438. https://doi.org/10.1016/j.procs.2016.07.230 doi: 10.1016/j.procs.2016.07.230
|
| [40] | A. Elnakib, G. Gimel'farb, J. S. Suri, A. El-Baz, Medical image segmentation: A brief survey, in Multi Modality State-of-the-Art Medical Image Segmentation and Registration Methodologies, Springer, (2011), 1–39. https://doi.org/10.1007/978-1-4419-8204-9_1 |
| [41] | J. Wu, W. Ji, H. Fu, M. Xu, Y. Jin, Y. Xu, MedSegDiff-V2: Diffusion-based medical image segmentation with Transformer, preprint, arXiv: 2301.11798. |
| [42] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [43] | W. Peebles, S. Xie, Scalable diffusion models with transformers, preprint, arXiv: 2212.09748. |
| [44] | F. Chollet, Xception: Deep learning with depthwise separable convolutions, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2017), 1800–1807. https://doi.org/10.1109/CVPR.2017.195 |
| [45] | N. Codella, V. Rotemberg, P. Tschandl, M. E. Celebi, S. Dusza, D. Gutman, et al., Skin lesion analysis toward melanoma detection 2018: A challenge hosted by the International Skin Imaging Collaboration (ISIC), preprint, arXiv: 1902.03368. |
| [46] | T. Mendonça, P. M. Ferreira, J. S. Marques, A. R. Marcal, J. Rozeira, PH2 - A dermoscopic image database for research and benchmarking, in Proceedings of the 35th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), IEEE, (2013), 5437–5440. https://doi.org/10.1109/EMBC.2013.6610779 |
| [47] | H. Wang, P. Cao, J. Wang, O. R. Zaiane, UCTransNet: Rethinking the skip connections in U-Net from a channel-wise perspective with transformer, preprint, arXiv: 2109.04335. |
| [48] |
J. Bernal, F. J. Sánchez, G. Fernández-Esparrach, D. Gil, C. Rodríguez, F. Vilariño, WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians, Comput. Med. Imaging Graphics, 43 (2015), 99–111. https://doi.org/10.1016/j.compmedimag.2015.02.007 doi: 10.1016/j.compmedimag.2015.02.007
|
| [49] | R. Azad, M. Asadi-Aghbolaghi, M. Fathy, S. Escalera, Bi-directional ConvLSTM U-Net with densely connected convolutions, preprint, arXiv: 1909.00166. |
| [50] |
B. H. Menze, A. Jakab, S. Bauer, J. Kalpathy-Cramer, K. Farahani, J. Kirby, et al., The multimodal brain tumor image segmentation benchmark (BRATS), IEEE Trans. Med. Imaging, 34 (2014), 1993–2024. https://doi.org/10.1109/TMI.2014.2377694 doi: 10.1109/TMI.2014.2377694
|









Figures(10) / Tables(4)
Yazhuo Fan, Jianhua Song, Yizhe Lu, Xinrong Fu, Xinying Huang, Lei Yuan. DPUSegDiff: A Dual-Path U-Net Segmentation Diffusion model for medical image segmentation[J]. Electronic Research Archive, 2025, 33(5): 2947-2971. doi: 10.3934/era.2025129







 DownLoad:
DownLoad: