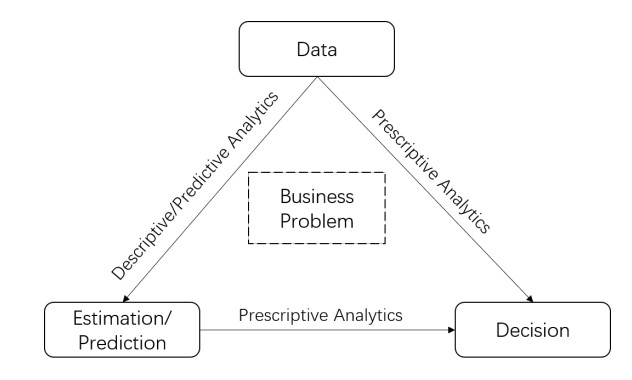
The development of the Internet of things (IoT) and online platforms enables companies and governments to collect data from a much broader spatial and temporal area in the logistics industry. The huge amount of data provides new opportunities to handle uncertainty in optimization problems within the logistics system. Accordingly, various prescriptive analytics frameworks have been developed to predict different parts of uncertain optimization problems, including the uncertain parameter, the combined coefficient consisting of the uncertain parameter, the objective function, and the optimal solution. This tutorial serves as the pioneer to introduce existing literature on state-of-the-art prescriptive analytics methods, such as the predict-then-optimize framework, the smart predict-then-optimize framework, the weighted sample average approximation framework, the empirical risk minimization framework, and the kernel optimization framework. Based on these frameworks, this tutorial further proposes possible improvements and practical tips to be considered when we use these methods. We hope that this tutorial will serve as a reference for future prescriptive analytics research on the logistics system in the era of big data.
Citation: Xuecheng Tian, Ran Yan, Shuaian Wang, Yannick Liu, Lu Zhen. Tutorial on prescriptive analytics for logistics: What to predict and how to predict[J]. Electronic Research Archive, 2023, 31(4): 2265-2285. doi: 10.3934/era.2023116
The development of the Internet of things (IoT) and online platforms enables companies and governments to collect data from a much broader spatial and temporal area in the logistics industry. The huge amount of data provides new opportunities to handle uncertainty in optimization problems within the logistics system. Accordingly, various prescriptive analytics frameworks have been developed to predict different parts of uncertain optimization problems, including the uncertain parameter, the combined coefficient consisting of the uncertain parameter, the objective function, and the optimal solution. This tutorial serves as the pioneer to introduce existing literature on state-of-the-art prescriptive analytics methods, such as the predict-then-optimize framework, the smart predict-then-optimize framework, the weighted sample average approximation framework, the empirical risk minimization framework, and the kernel optimization framework. Based on these frameworks, this tutorial further proposes possible improvements and practical tips to be considered when we use these methods. We hope that this tutorial will serve as a reference for future prescriptive analytics research on the logistics system in the era of big data.

| [1] |
W. Wang, Y. Wu, Is uncertainty always bad for the performance of transportation systems, Commun. Transp. Res., 1 (2021), 100021. https://doi.org/10.1016/j.commtr.2021.100021 doi: 10.1016/j.commtr.2021.100021

|
| [2] |
D. Bertsimas, N. Koduri, Data-driven optimization: A Reproducing Kernel Hilbert Space approach, Oper. Res., 70 (2021), 454–471. https://doi.org/10.1287/opre.2020.2069 doi: 10.1287/opre.2020.2069
|
| [3] | J. R. Birge, F. Louveaux, Introduction to Stochatic Programming, Springer, New York, 2011. https://doi.org/10.1007/978-1-4614-0237-4 |
| [4] | A. Ben-Tal, L. E. Ghaoui, A. Nemirovski, Robust Programming, Princeton University Press, Princeton, 2009. |
| [5] |
D. Bertsimas, D. B. Brown, C. Caramanis, Theory and applications of robust optimization, SIAM Rev., 53 (2011), 464–501. https://doi.org/10.1137/080734510 doi: 10.1137/080734510
|
| [6] |
A. J. Kleywegt, A. Shapiro, T. Homem-de Mello, The sample average approximation for stochastic discrete optimization, SIAM J. Optim., 12 (2002), 479–502. https://doi.org/10.1137/S1052623499363220 doi: 10.1137/S1052623499363220
|
| [7] |
D. Bertsimas, V. Gupta, N. Kallus, Data-driven robust optimization, Math. Program., 167 (2018), 235–292. https://doi.org/10.1007/s10107-017-1125-8 doi: 10.1007/s10107-017-1125-8
|
| [8] |
E. Delage, Y. Ye, Distributionally robust optimization under moment uncertainty with application to data-driven problems, Oper. Res., 58 (2010), 595–612. https://doi.org/10.1287/opre.1090.0741 doi: 10.1287/opre.1090.0741
|
| [9] |
L. He, S. Liu, Z. J. M. Shen, Smart urban transport and logistics: {A} business analytics perspective, Prod. Oper. Manag., 31 (2022), 3771–3787. https://doi.org/10.1111/poms.13775 doi: 10.1111/poms.13775
|
| [10] |
L. He, H. Y. Mak, Y. Rong, Z. J. M. Shen, Service region design for urban electric vehicle sharing systems, Manuf. Serv. Oper. Manag., 19 (2017), 309–327. https://doi.org/10.1287/msom.2016.0611 doi: 10.1287/msom.2016.0611
|
| [11] |
M. Lu, Z. Chen, S. Shen, Optimizing the profitability and quality of service in carshare systems under demand uncertainty, Manuf. Serv. Oper. Manag., 20 (2018), 162–180. https://doi.org/10.1287/msom.2017.0644 doi: 10.1287/msom.2017.0644
|
| [12] |
R. Cui, S. Gallino, A. Moreno, D. J. Zhang, The operational value of social media information, Prod. Oper. Manag., 27 (2018), 1749–1769. https://doi.org/10.1111/poms.12707 doi: 10.1111/poms.12707
|
| [13] |
J. Carlsson, S. Song, Coordinated logistics with a truck and a drone, Manag. Sci., 64 (2018), 4052–4069. https://doi.org/10.1287/mnsc.2017.2824 doi: 10.1287/mnsc.2017.2824
|
| [14] |
Z. Zou, H. Younes, S. Erdoğan, J. Wu, Exploratory analysis of real-time e-scooter trip data in Washington, DC, Transp. Res. Rec., 2674 (2020), 285–299. https://doi.org/10.1177/0361198120919760 doi: 10.1177/0361198120919760
|
| [15] |
C. Glaeser, M. Fisher, X. Su, Optimal retail location: Empirical methodology and application to practice: Finalist–2017 M & SOM practice-based research competition, Manuf. Serv. Oper. Manag., 21 (2019), 86–102. https://doi.org/10.1287/msom.2018.0759 doi: 10.1287/msom.2018.0759
|
| [16] |
D. Bertsimas, Y. Sian Ng, J. Yan, Joint frequency-setting and pricing optimization on multimodal transit networks at scale, Transp. Sci., 54 (2020), 839–853. https://doi.org/10.1287/trsc.2019.0959 doi: 10.1287/trsc.2019.0959
|
| [17] |
D. Bertsimas, A. Delarue, P. Jaillet, S. Martin, Travel time estimation in the age of big data, Oper. Res., 67 (2019), 498–515. https://doi.org/10.1287/opre.2018.1784 doi: 10.1287/opre.2018.1784
|
| [18] |
H. de Vries, J. van de Klundert, A. Wagelmans, The roadside healthcare facility location problem a managerial network design challenge, Prod. Oper. Manag., 29 (2020), 1165–1187. https://doi.org/10.1111/poms.13152 doi: 10.1111/poms.13152
|
| [19] |
J. Boutilier, T. Chan, Ambulance emergency response optimization in developing countries, Oper. Res., 68 (2020), 1315–1334. https://doi.org/10.1287/opre.2019.1969 doi: 10.1287/opre.2019.1969
|
| [20] |
E. Gralla, J. Goentzel, C. Fine, Problem formulation and solution mechanisms: A behavioral study of humanitarian transportation planning, Prod. Oper. Manag., 25 (2016), 22–35. https://doi.org/10.1111/poms.12496 doi: 10.1111/poms.12496
|
| [21] |
Z. Hao, L. He, Z. Hu, J. Jiang, Robust vehicle pre-allocation with uncertain covariates, Prod. Oper. Manag., 29 (2020), 955–972. https://doi.org/10.1111/poms.13143 doi: 10.1111/poms.13143
|
| [22] |
A. Kabra, E. Belavina, K. Girotra, Bike-share systems: Accessibility and availability, Manag. Sci., 66 (2020), 3803–3824. https://doi.org/10.1287/mnsc.2019.3407 doi: 10.1287/mnsc.2019.3407
|
| [23] |
S. Liu, L. He, Z. J. M. Shen, On-time last-mile delivery: Order assignment with travel-time predictors, Manag. Sci., 67 (2021), 4095–4119. https://doi.org/10.1287/mnsc.2020.3741 doi: 10.1287/mnsc.2020.3741
|
| [24] |
S. Steinker, K. Hoberg, U. Thonemann, The value of weather information for e-commerce operations, Prod. Oper. Manag., 26 (2017), 1854–1874. https://doi.org/10.1111/poms.12721 doi: 10.1111/poms.12721
|
| [25] |
M. Ang, Y. Lim, M. Sim, Robust storage assignment in unit-load warehouses, Manag. Sci., 58 (2012), 2114–2130. https://doi.org/10.1287/mnsc.1120.1543 doi: 10.1287/mnsc.1120.1543
|
| [26] |
M. Lim, H. Mak, Y. Rong, Toward mass adoption of electric vehicles: Impact of the range and resale anxieties, Manuf. Serv. Oper. Manag., 17 (2015), 101–119. https://doi.org/10.1287/msom.2014.0504 doi: 10.1287/msom.2014.0504
|
| [27] |
J. Carlsson, M. Behroozi, K. Mihic, Wasserstein distance and the distributionally robust TSP, Oper. Res., 66 (2018), 1603–1624. https://doi.org/10.1287/opre.2018.1746 doi: 10.1287/opre.2018.1746
|
| [28] |
G. Baloch, F. Gzara, Strategic network design for parcel delivery with drones under competition, Transp. Sci., 54 (2020), 204–228. https://doi.org/10.1287/trsc.2019.0928 doi: 10.1287/trsc.2019.0928
|
| [29] |
J. Shu, M. Chou, Q. Liu, C. Teo, I. Wang, Models for effective deployment and redistribution of bicycles within public bicycle-sharing systems, Oper. Res., 61 (2013), 1346–1359. https://doi.org/10.1287/opre.2013.1215 doi: 10.1287/opre.2013.1215
|
| [30] |
G. Cachon, K. Daniels, R. Lobel, The role of surge pricing on a service platform with self-scheduling capacity, Manuf. Serv. Oper. Manag., 19 (2017), 368–384. https://doi.org/10.1287/msom.2017.0618 doi: 10.1287/msom.2017.0618
|
| [31] |
S. Datner, T. Raviv, M. Tzur, D. Chemla, Setting inventory levels in a bike sharing network, Transp. Sci., 53 (2019), 62–76. https://doi.org/10.1287/trsc.2017.0790 doi: 10.1287/trsc.2017.0790
|
| [32] |
H. Abouee-Mehrizi, O. Berman, S. Sharma, Optimal joint replenishment and transshipment policies in a multi-period inventory system with lost sales, Oper. Res., 63 (2015), 342–350. https://doi.org/10.1287/opre.2015.1358 doi: 10.1287/opre.2015.1358
|
| [33] |
R. Yuan, S. Graves, T. Cezik, Velocity-based storage assignment in semi-automated storage systems, Prod. Oper. Manag., 28 (2019), 354–373. https://doi.org/10.1111/poms.12925 doi: 10.1111/poms.12925
|
| [34] |
Q. Deng, X. Fang, Y. Lim, Urban consolidation center or peer-to-peer platform? The solution to urban last-mile delivery, Prod. Oper. Manag., 30 (2021), 997–1013. https://doi.org/10.1111/poms.13289 doi: 10.1111/poms.13289
|
| [35] |
Z. Wang, J. Sheu, C. Teo, G. Xue, Robot scheduling for mobile-rack warehouses: Human–robot coordinated order picking systems, Prod. Oper. Manag., 31 (2022), 98–116. https://doi.org/10.1111/poms.13406 doi: 10.1111/poms.13406
|
| [36] |
W. Qi, L. Li, S. Liu, Z. J. M. Shen, Shared mobility for last-mile delivery: Design, operational prescriptions, and environmental impact, Manuf. Serv. Oper. Manag., 20 (2018), 737–751. https://doi.org/10.1287/msom.2017.0683 doi: 10.1287/msom.2017.0683
|
| [37] |
B. Yildiz, M. Savelsbergh, Provably high-quality solutions for the meal delivery routing problem, Transp. Sci., 53 (2019), 1372–1388. https://doi.org/10.1287/trsc.2018.0887 doi: 10.1287/trsc.2018.0887
|
| [38] |
M. Ulmer, B. Thomas, A. Campbell, N. Woyak, The restaurant meal delivery problem: Dynamic pickup and delivery with deadlines and random ready times, Transp. Sci., 55 (2021), 75–100. https://doi.org/10.1287/trsc.2020.1000 doi: 10.1287/trsc.2020.1000
|
| [39] |
S. Jain, G. Shao, S. J. Shin, Manufacturing data analytics using a virtual factory representation, Int. J. Prod. Res., 55 (2017), 5450–5464. https://doi.org/10.1080/00207543.2017.1321799 doi: 10.1080/00207543.2017.1321799
|
| [40] |
A. Nasrollahzadeh, A. Khademi, M. Mayorga, Real-time ambulance dispatching and relocation, Manuf. Serv. Oper. Manag., 20 (2018), 467–480. https://doi.org/10.1287/msom.2017.0649 doi: 10.1287/msom.2017.0649
|
| [41] |
X. Li, X. Zhao, W. Pu, P. Chen, F. Liu, Z. He, Optimal decisions for operations management of BDAR: A military industrial logistics data analytics perspective, Comput. Ind. Eng., 137 (2019), 106100. https://doi.org/10.1016/j.cie.2019.106100 doi: 10.1016/j.cie.2019.106100
|
| [42] |
S. Chung, Applications of smart technologies in logistics and transport: A review, Transp. Res. Part E Logist. Transp. Rev., 153 (2021), 102455. https://doi.org/10.1016/j.tre.2021.102455 doi: 10.1016/j.tre.2021.102455
|
| [43] |
H. Mak, Y. Rong, Z. J. M. Shen, Infrastructure planning for electric vehicles with battery swapping, Manag. Sci., 59 (2013), 1557–1575. https://doi.org/10.1287/mnsc.1120.1672 doi: 10.1287/mnsc.1120.1672
|
| [44] |
L. He, G. Ma, W. Qi, X. Wang, Charging an electric vehicle-sharing fleet, Manuf. Serv. Oper. Manag., 23 (2021), 471–487. https://doi.org/10.1287/msom.2019.0851 doi: 10.1287/msom.2019.0851
|
| [45] |
T. Chan, D. Demirtas, R. Kwon, Optimizing the deployment of public access defibrillators, Manag. Sci., 62 (2016), 3617–3635. https://doi.org/10.1287/mnsc.2015.2312 doi: 10.1287/mnsc.2015.2312
|
| [46] |
T. Chan, Z. J. M. Shen, A. Siddiq, Robust defibrillator deployment under cardiac arrest location uncertainty via row-and-column generation, Oper. Res., 66 (2018), 358–379. https://doi.org/10.1287/opre.2017.1660 doi: 10.1287/opre.2017.1660
|
| [47] |
J. Carlsson, M. Behroozi, R. Devulapalli, X. Meng, Household-level economies of scale in transportation, Oper. Res., 64 (2016), 1372–1387. https://doi.org/10.1287/opre.2016.1533 doi: 10.1287/opre.2016.1533
|
| [48] |
T. Huang, D. Bergman, R. Gopal, Predictive and prescriptive analytics for location selection of add-on retail products, Prod. Oper. Manag., 28 (2019), 1858–1877. https://doi.org/10.1111/poms.13018 doi: 10.1111/poms.13018
|
| [49] |
N. Salari, S. Liu, Z. J. M. Shen, Real-time delivery time forecasting and promising in online retailing: When will your package arrive, Manuf. Serv. Oper. Manag., 24 (2022), 1421–1436. https://doi.org/10.1287/msom.2022.1081 doi: 10.1287/msom.2022.1081
|
| [50] |
A. Gunasekaran, T. Papadopoulos, R. Dubey, S. Wamba, S. Childe, B. Hazen, et al., Big data and predictive analytics for supply chain and organizational performance, J. Bus. Res., 70 (2017), 308–317. https://doi.org/10.1016/j.jbusres.2016.08.004 doi: 10.1016/j.jbusres.2016.08.004
|
| [51] |
A. Nguyen, L. Zhou, V. Spiegler, P. Ieromonachou, Y. Lin, Big data analytics in supply chain management: A state-of-the-art literature review, Comput. Oper. Res., 98 (2018), 254–264. https://doi.org/10.1016/j.cor.2017.07.004 doi: 10.1016/j.cor.2017.07.004
|
| [52] |
G. Wang, A. Gunasekaran, E. Ngai, T. Papadopoulos, Big data analytics in logistics and supply chain management: Certain investigations for research and applications, Int. J. Prod. Res., 176 (2016), 98–110. https://doi.org/10.1016/j.ijpe.2016.03.014 doi: 10.1016/j.ijpe.2016.03.014
|
| [53] | A. Elmachtoub, P. Grigas, Smart "predict, then optimize", Manag. Sci., 68 (2022), 9–26. https://doi.org/10.1287/mnsc.2020.3922 |
| [54] |
D. Bertsimas, N. Kallus, From predictive to prescriptive analytics, Manag. Sci., 66 (2020), 1025–1044. https://doi.org/10.1287/mnsc.2018.3253 doi: 10.1287/mnsc.2018.3253
|
| [55] |
P. Notz, R. Pibernik, Prescriptive analytics for flexible capacity management, Manag. Sci., 68 (2022), 1756–1775. https://doi.org/10.1287/mnsc.2020.3867 doi: 10.1287/mnsc.2020.3867
|
| [56] |
G. Ban, C. Rudin, The big data newsvendor: Practical insights from machine learning, Oper. Res., 67 (2019), 90–108. https://doi.org/10.1287/opre.2018.1757 doi: 10.1287/opre.2018.1757
|
| [57] |
Y. Ran, S. Wang, K. Fagerholt, A semi-"smart predict then optimize" (semi-SPO) method for efficient ship inspection, Transp. Res. Part B Methodol., 142 (2020), 100–125. https://doi.org/10.1016/j.trb.2020.09.014 doi: 10.1016/j.trb.2020.09.014
|
| [58] |
S. Wang, X. Tian, R. Yan, Y Liu, A deficiency of prescriptive analytics—No perfect predicted value or predicted distribution exists, Electron. Res. Arch., 30 (2022), 3586–3594. https://doi.org/10.3934/era.2022183 doi: 10.3934/era.2022183
|
| [59] |
S. Wang, R. Yan, "Predict, then optimize" with quantile regression: A global method from predictive to prescriptive analytics and applications to multimodal transportation, Multimodal Transp., 1 (2022), 100035. http://doi.org/10.1016/j.multra.2022.100035 doi: 10.1016/j.multra.2022.100035
|
| [60] | J. Kotary, F. Fioretto, P. Van Hentenryck, B. Wilder, End-to-end constrained optimization learning: A survey, in Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, (2021), 4475–4482. https://doi.org/10.24963/ijcai.2021/610 |
| [61] | A. Ferber, B. Wilder, B. Dilkina, M. Tambe, MIPaaL: Mixed integer program as a layer, in Proceedings of the AAAI Conference on Artificial Intelligence, (2020), 1504–1511. https://doi.org/10.1609/aaai.v34i02.5509 |
| [62] | B. Wilder, B. Dilkina, M. Tambe, Melding the data-decisions pipeline: Decision-focused learning for combinatorial optimization, in Proceedings of the AAAI Conference on Artificial Intelligence, (2019), 1658–1665. https://doi.org/10.1609/aaai.v33i01.33011658 |
| [63] | J. Mandi, E. Demirovi, P. Stuckey, T. Guns, Smart predict-and-optimize for hard combinatorial optimization problems, in Proceedings of the AAAI Conference on Artificial Intelligence, (2020), 1603–1610. https://doi.org/10.1609/aaai.v34i02.5521 |
| [64] | M. Mulamba, J. Mandi, M. Diligenti, M. Lombardi, V. Bucarey, T. Guns, Contrastive losses and solution caching for predict-and-optimize, in Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, (2021), 2833–2840. https://doi.org/10.24963/ijcai.2021/390 |
| [65] | N. Kallus, Recursive partitioning for personalization using observational data, in Proceedings of the 34th International Conference on Machine Learning, (2017), 1789–1798. |
| [66] | D. Bertsimas, J. Dunn, N. Mundru, Optimal prescriptive trees, INFORMS J. Optim., 1 (2019), 164–183. https://doi.org/10.1287/ijoo.2018.0005 |
| [67] | A. Elmachtoub, J. Liang, R. Mcnellis, Decision trees for decision-making under the predict-then-optimize framework, in Proceedings of the 37th International Conference on Machine Learning, (2020), 2858–2867. |
| [68] | N. Kallus, X. Mao, Stochastic optimization forests, Manag. Sci., 2022 (2022). https://doi.org/10.1287/mnsc.2022.4458 |
Figures(1) / Tables(1)
Xuecheng Tian, Ran Yan, Shuaian Wang, Yannick Liu, Lu Zhen. Tutorial on prescriptive analytics for logistics: What to predict and how to predict[J]. Electronic Research Archive, 2023, 31(4): 2265-2285. doi: 10.3934/era.2023116







 DownLoad:
DownLoad: