Citation: Alessio Russo, Francisco J Escobedo, Stefan Zerbe. Quantifying the local-scale ecosystem services provided by urban treed streetscapes in Bolzano, Italy[J]. AIMS Environmental Science, 2016, 3(1): 58-76. doi: 10.3934/environsci.2016.1.58

| [1] | Grimm NB, Faeth SH, Golubiewski NE, et al. (2008) Global change and the ecology of cities. Science 319: 756-760. |
| [2] |
Bonan GB (2000) The microclimates of a suburban Colorado (USA) landscape and implications for planning and design. Landscape urban plan 49: 97-114. doi: 10.1016/S0169-2046(00)00071-2

|
| [3] |
Taleb D, Abu-Hijleh B (2013) Urban heat islands: Potential effect of organic and structured urban configurations on temperature variations in Dubai, UAE. Renewable Energy 50: 747-762. doi: 10.1016/j.renene.2012.07.030
|
| [4] |
Holderness T, Barr S, Dawson R, et al. (2013) An evaluation of thermal Earth observation for characterizing urban heatwave event dynamics using the urban heat island intensity metric. Int j remote sens 34: 864-884. doi: 10.1080/01431161.2012.714505
|
| [5] |
Hansen J, Sato M, Ruedy R (2012) Perception of climate change. Proceedings of the National Academy of Sciences of the United States of America 109: E2415-2423. doi: 10.1073/pnas.1205276109
|
| [6] |
Son JY, Lee JT, Brooke Anderson G, et al. (2012) The impact of heat waves on mortality in seven major cities in Korea. Environ health persp 120: 566-571. doi: 10.1289/ehp.1103759
|
| [7] | D’Ippoliti D, Michelozzi P, Marino C, et al (2010) The impact of heat waves on mortality in 9 European cities: Results from the EuroHEAT project. Environmental Health 9: 37. |
| [8] |
Hajat S, Armstrong B, Baccini M, et al. (2006) Impact of high temperatures on mortality: Is there an added heat wave effect? Epidemiology 17: 632-638. doi: 10.1097/01.ede.0000239688.70829.63
|
| [9] |
Conti S, Meli P, Minelli G, et al. (2005) Epidemiologic study of mortality during the Summer 2003 heat wave in Italy. Environmental Research 98: 390-399. doi: 10.1016/j.envres.2004.10.009
|
| [10] | Heidt V, Neef M (2008) Benefits of Urban Green Space for Improving Urban Climate. In: Carreiro MM, Song YC, Wu J (eds) Ecology, Planning, and Management of Urban Forests. Springer, New York, 84-96. |
| [11] |
Demuzere M, Orru K, Heidrich O, et al. (2014) Mitigating and adapting to climate change: Multi-functional and multi-scale assessment of green urban infrastructure. J Environ Manage 146: 107-115. doi: 10.1016/j.jenvman.2014.07.025
|
| [12] |
Escobedo FJ, Adams DC, Timilsina N (2015) Urban forest structure effects on property value. Ecosystem Services 12: 209-217. doi: 10.1016/j.ecoser.2014.05.002
|
| [13] |
Li W, Saphores JDM, Gillespie TW (2015) A comparison of the economic benefits of urban green spaces estimated with NDVI and with high-resolution land cover data. Landscape urban plan 133: 105-117. doi: 10.1016/j.landurbplan.2014.09.013
|
| [14] |
Vandermeulen V, Verspecht A, Vermeire B, et al. (2011) The use of economic valuation to create public support for green infrastructure investments in urban areas. Landscape urban plan 103: 198-206. doi: 10.1016/j.landurbplan.2011.07.010
|
| [15] |
Bertram C, Rehdanz K (2015) Preferences for cultural urban ecosystem services: Comparing attitudes, perception, and use. Ecosystem Services 12: 187-199. doi: 10.1016/j.ecoser.2014.12.011
|
| [16] | Andersson E, Tengö M, McPhearson T, et al. (2014) Cultural ecosystem services as a gateway for improving urban sustainability. Ecosystem Services 12: 165-168. |
| [17] | Tyrväinen L, Pauleit S, Seeland K, et al. (2005) Benefits and Uses of Urban Forests and Trees. In: Konijnendijk C, Nilsson K, Randrup T, Schipperijn J (eds) Urban Forests and Trees. Springer Berlin Heidelberg, 81-114. |
| [18] |
Escobedo FJ, Nowak DJ (2009) Spatial heterogeneity and air pollution removal by an urban forest. Landscape urban plan 90: 102-110. doi: 10.1016/j.landurbplan.2008.10.021
|
| [19] |
Escobedo FJ, Kroeger T, Wagner JE (2011) Urban forests and pollution mitigation: analyzing ecosystem services and disservices. Environmental pollution 159: 2078-2087. doi: 10.1016/j.envpol.2011.01.010
|
| [20] |
Nowak DJ, Crane DE, Stevens JC (2006) Air pollution removal by urban trees and shrubs in the United States. Urban For Urban Gree 4: 115-123. doi: 10.1016/j.ufug.2006.01.007
|
| [21] |
Pugh TAM, MacKenzie AR, Whyatt JD, et al. (2012) Effectiveness of Green Infrastructure for Improvement of Air Quality in Urban Street Canyons. Environ Sci Technol 46: 7692-7699. doi: 10.1021/es300826w
|
| [22] |
Strohbach MW, Haase D (2012) Above-ground carbon storage by urban trees in Leipzig, Germany: Analysis of patterns in a European city. Landscape urban plan 104: 95-104. doi: 10.1016/j.landurbplan.2011.10.001
|
| [23] |
Nowak DJ, Crane DE (2002) Carbon storage and sequestration by urban trees in the USA. Environmental pollution 116: 381-389. doi: 10.1016/S0269-7491(01)00214-7
|
| [24] | Jo H-K, McPherson EG (1995) Carbon Storage and Flux in Urban Residential Greenspace. J Environ Manage 45: 109-133. |
| [25] |
Liu C, Li X (2012) Carbon storage and sequestration by urban forests in Shenyang, China. Urban For Urban Gree 11: 121-128. doi: 10.1016/j.ufug.2011.03.002
|
| [26] |
Russo A, Escobedo FJ, Timilsina N, et al. (2015) Transportation carbon dioxide emission offsets by public urban trees: A case study in Bolzano, Italy. Urban For Urban Gree 14: 398-403. doi: 10.1016/j.ufug.2015.04.002
|
| [27] |
Weissert LF, Salmond JA, Schwendenmann L (2014) A review of the current progress in quantifying the potential of urban forests to mitigate urban CO2 emissions. Urban Climate 8: 100-125. doi: 10.1016/j.uclim.2014.01.002
|
| [28] |
Hardin PJ, Jensen RR (2007) The effect of urban leaf area on summertime urban surface kinetic temperatures: A Terre Haute case study. Urban For Urban Gree 6: 63-72. doi: 10.1016/j.ufug.2007.01.005
|
| [29] |
Rosenfeld AH, Akbari H, Bretz S, et al. (1995) Mitigation of urban heat islands: materials, utility programs, updates. Energ Buildings 22: 255-265. doi: 10.1016/0378-7788(95)00927-P
|
| [30] | Akbari H (2002) Shade trees reduce building energy use and CO2 emissions from power plants. Environmental pollution 116 Suppl: S119-126. |
| [31] |
Georgi NJ, Zafiriadis K (2006) The impact of park trees on microclimate in urban areas. Urban Ecosystems 9: 195-209. doi: 10.1007/s11252-006-8590-9
|
| [32] | Georgi JN, Dimitriou D (2010) The contribution of urban green spaces to the improvement of environment in cities: Case study of Chania, Greece. Building Environ 45: 1401-1414. |
| [33] | Coronel AS, Feldman SR, Jozami E, et al. (2015) Effects of urban green areas on air temperature in a medium-sized Argentinian city. AIMS Environmental Science 2: 803–826 |
| [34] | Starke WB, Simonds JO (2013) Landscape Architecture: A Manual of Environmental Planning and Design, Fifth edit. McGraw-Hill Professional. |
| [35] | Konijnendijk CC, Annerstedt M, Nielsen AB, et al. (2013) Benefits of Urban Parks—A systematic review. Copenhagen & Alnarp. |
| [36] |
Williams K, O’Brien L, Stewart A (2013) Urban health and urban forestry: How can forest management agencies help? Arboricultural Journal 35: 119-133. doi: 10.1080/03071375.2013.852358
|
| [37] | Yang W, Omaye ST (2009) Air pollutants, oxidative stress and human health. Mutation Research/Genetic Toxicology and Environmental Mutagenesis 674: 45-54. |
| [38] | Sicard P, Lesne O, Alexandre N, et al. (2011) Air quality trends and potential health effects – Development of an aggregate risk index. Atmospheric Environment 45: 1145-1153. |
| [39] | Cheng Z, Jiang J, Fajardo O, et al. (2012) Characteristics and health impacts of particulate matter pollution in China (2001-2011). Atmospheric Environment 65: 186-194. |
| [40] |
Takano T, Nakamura K, Watanabe M (2002) Urban residential environments and senior citizens’ longevity in megacity areas: the importance of walkable green spaces. J epidemiol commun h 56: 913-918. doi: 10.1136/jech.56.12.913
|
| [41] |
Tanaka A, Takano T, Nakamura K, et al. (1996) Health levels influenced by urban residential conditions in a megacity—Tokyo. Urban Studies 33: 879-894. doi: 10.1080/00420989650011645
|
| [42] | Tzoulas K, Korpela K, Venn S, et al. (2007) Promoting ecosystem and human health in urban areas using Green Infrastructure: A literature review. Landscape urban plan 81: 167-178. |
| [43] | Picot X (2004) Thermal comfort in urban spaces: impact of vegetation growth. Energ Buildings 36: 329-334. |
| [44] |
Lafortezza R, Carrus G, Sanesi G, et al. (2009) Benefits and well-being perceived by people visiting green spaces in periods of heat stress. Urban For Urban Gree 8: 97-108. doi: 10.1016/j.ufug.2009.02.003
|
| [45] |
Armson D, Stringer P, Ennos AR (2012) The effect of tree shade and grass on surface and globe temperatures in an urban area. Urban For Urban Gree 11: 245-255. doi: 10.1016/j.ufug.2012.05.002
|
| [46] |
Maher BA, Ahmed IAM, Davison B, et al. (2013) Impact of roadside tree lines on indoor concentrations of traffic-derived particulate matter. Environ sci technol 47: 13737-13744. doi: 10.1021/es404363m
|
| [47] |
Roy S, Byrne J, Pickering C (2012) A systematic quantitative review of urban tree benefits, costs, and assessment methods across cities in different climatic zones. Urban for urban gree 11: 351-363. doi: 10.1016/j.ufug.2012.06.006
|
| [48] | Ahern J (2012) Urban landscape sustainability and resilience: the promise and challenges of integrating ecology with urban planning and design. Landscape Ecology 28: 1203-1212. |
| [49] | Maes J, Egoh B, Willemen L, et al (2012) Mapping ecosystem services for policy support and decision making in the European Union. Ecosystem Services 1: 31-39. |
| [50] |
Kandziora M, Burkhard B, Müller F (2013) Mapping provisioning ecosystem services at the local scale using data of varying spatial and temporal resolution. Ecosystem Services 4: 47-59. doi: 10.1016/j.ecoser.2013.04.001
|
| [51] |
Taleghani M, Sailor DJ, Tenpierik M, et al. (2014) Thermal assessment of heat mitigation strategies: The case of Portland State University, Oregon, USA. Building Environ 73: 138-150. doi: 10.1016/j.buildenv.2013.12.006
|
| [52] | Nowak DJ, Hoehn RE, Bodine AR, et al. (2013) Urban forest structure, ecosystem services and change in Syracuse, NY. Urban Ecosystems. doi: 10.1007/s11252-013-0326-z |
| [53] |
Lovell ST, Taylor JR (2013) Supplying urban ecosystem services through multifunctional green infrastructure in the United States. Landscape Ecology 28: 1447-1463. doi: 10.1007/s10980-013-9912-y
|
| [54] | Siena F, Buffoni A (2007) Inquinamento atmosferico e verde urbano. Il modello UFORE, un caso di studio. Sherwood 138: 17-21. |
| [55] |
Paoletti E (2009) Ozone and urban forests in Italy. Environmental pollution 157: 1506-1512. doi: 10.1016/j.envpol.2008.09.019
|
| [56] |
Manes F, Incerti G, Salvatori E, et al. (2012) Urban ecosystem services: Tree diversity and stability of tropospheric ozone removal. Ecological Applications 22: 349-360. doi: 10.1890/11-0561.1
|
| [57] |
Papa S, Bartoli G, Nacca F, et al. (2012) Trace metals, peroxidase activity, PAHs contents and ecophysiological changes in Quercus ilex leaves in the urban area of Caserta (Italy). J environ manage 113: 501-509. doi: 10.1016/j.jenvman.2012.05.032
|
| [58] |
Gratani L, Varone L (2007) Plant crown traits and carbon sequestration capability by Platanus hybrida Brot. in Rome. Landscape urban plan 81: 282-286. doi: 10.1016/j.landurbplan.2007.01.006
|
| [59] | Baraldi R, Rapparini F, Tosi G, et al. (2010) New aspects on the impact of vegetation in urban environment. Acta Horticulturae 881: 543-546. |
| [60] | Russo A, Escobedo FJ, Timilsina N, et al. (2014) Assessing urban tree carbon storage and sequestration in Bolzano, Italy. International Journal of Biodiversity Science, Ecosystem Services & Management 10: 54-70. |
| [61] | Sanesi G, Chiarello F (2006) Residents and urban green spaces: The case of Bari. Urban For Urban Gree 4: 125-134. |
| [62] | Secco G, Zulian G (2008) Modeling the Social Benefits of Urban Parks for Users. In: Carreiro M, Song Y-C, Wu J (eds) Ecology, Planning, and Management of Urban Forests SE - 20. Springer New York, 312-335. |
| [63] |
Paoletti E, Bardelli T, Giovannini G, et al. (2011) Air quality impact of an urban park over time. Procedia Environmental Sciences 4: 10-16. doi: 10.1016/j.proenv.2011.03.002
|
| [64] | Gratani L, Varone L (2006) Carbon sequestration by Quercus ilex L. and Quercus pubescens Willd. and their contribution to decreasing air temperature in Rome. Urban Ecosystems 9: 27-37. |
| [65] |
Konijnendijk CC, Ricard RM, Kenney A, et al. (2006) Defining urban forestry—A comparative perspective of North America and Europe. Urban For Urban Gree 4: 93-103. doi: 10.1016/j.ufug.2005.11.003
|
| [66] | Maes J, Teller A, Erhard M, et al (2013) Mapping and Assessment of Ecosystems and their Services. An analytical framework for ecosystem assessments under action 5 of the EU biodiversity strategy to 2020. Luxembourg: Publications office of the European Union. |
| [67] | European Commission (2013) Air Quality Standards. Available from: http://ec.europa.eu/environment/air/quality/standards.htm. |
| [68] | Bolzano Statistics Office (2012) Bolzano 2012 City Figures. Available from: http://www.comune.bolzano.it/UploadDocs/11430_Bolzano_2012.pdf |
| [69] | Chiesura A, Mirabile M (2012) Il verde urbano. In: Qualità dell’ambiente urbano, 33/2012 ed., Roma: ISPRA, 346-349. |
| [70] | Russo A (2013) Quantifying and modeling ecosystem services provided by urban greening in cities of the Southern Alps, N Italy. Dissertation. University of Bologna, Italy. |
| [71] | Autonomous Province of Bolzano (2012) Meteorological Service of the Autonomous Province of Bolzano, historical data. Available from: http://www.provincia.bz.it/meteo/dati-storici.asp. |
| [72] | Bolzano Provincial Environment Agency (2010) Program for reducing NO2 pollution. Available from: http://www.comune.bolzano.it/ambiente_context02.jsp?ID_LINK=3681&area=68 |
| [73] | Natural England (2013) Green Infrastructure—Valuation Tools Assessment. Exeter |
| [74] |
Forman RTT (1964) Growth under Controlled Conditions to Explain the Hierarchical Distributions of a Moss, Tetraphis pellucida. Ecological Monographs 34: 1. doi: 10.2307/1948461
|
| [75] | O’Neill RV, Deangelis DL, Waide JB, et al. (1986) A Hierarchical Concept of Ecosystems. Princeton University Press, New Jersey. |
| [76] | Forman RTT (2008) Urban Regions: Ecology and Planning Beyond the City (Cambridge Studies in Landscape Ecology). Cambridge University Press New York. |
| [77] | Park S, Tuller SE, Jo M (2014) Application of Universal Thermal Climate Index (UTCI) for microclimatic analysis in urban thermal environments. Landscape urban plan 125: 146-155. |
| [78] |
Baró F, Chaparro L, Gómez-Baggethun E, et al. (2014) Contribution of ecosystem services to air quality and climate change mitigation policies: The case of urban forests in Barcelona, Spain. Ambio 43: 466-479. doi: 10.1007/s13280-014-0507-x
|
| [79] | Nowak DJ, Crane DE, Stevens JC, et al. (2008) A ground-based method of assessing urban forest structure and ecosystem services. Arboriculture and Urban Forestry 34: 347-358. |
| [80] | Bruse M (2012) ENVI-met. Available from: http://www.envi-met.com/. |
| [81] | Wania A, Bruse M, Blond N, et al. (2012) Analysing the influence of different street vegetation on traffic-induced particle dispersion using microscale simulations. J environ manage 94: 91-101. |
| [82] | DeFries R, Pagiola S, Adamowicz W, et al. (2005) Analytical Approaches for Assessing Ecosystem Condition and Human Well-being. In: Hassan R, Scholes R, Ash N (eds) Ecosystems and Human Well-being: Current State and Trends, Volume 1. Washington, Covelo, London: Island Press, 37-71. |
| [83] | Wälchli G (2012) Ecosystem services as an economic strategy? i-Tree : a tool for the economic assessment of urban trees. Summary. Dissertation. Zürcher Hochschule für Angewandte Wissenschaften. |
| [84] | Chaparro L, Terradas J (2009) Ecological Services of Urban Forest in Barcelona. Centre de Recerca Ecològica i Aplicacions Forestals, Universitat Autònoma de Barcelona, Bellaterra, Spain. 96 p. Available from: https://www.itreetools.org/resources/reports/Barcelona%20Ecosystem%20Analysis.pdf |
| [85] |
Tallis M, Taylor G, Sinnett D, et al. (2011) Estimating the removal of atmospheric particulate pollution by the urban tree canopy of London, under current and future environments. Landscape urban plan 103: 129-138. doi: 10.1016/j.landurbplan.2011.07.003
|
| [86] | Rogers K, Hansford D, Sunderland T, et al. (2011) Measuring the ecosystem services of Torbay’s trees : the Torbay i-Tree Eco pilot project. In: Urban Trees Research Conference. Forestry Commission, Edinburgh, 18-26. |
| [87] |
Carnielo E, Zinzi M (2013) Optical and thermal characterisation of cool asphalts to mitigate urban temperatures and building cooling demand. Building Environ 60: 56-65. doi: 10.1016/j.buildenv.2012.11.004
|
| [88] | Johansson E, Spangenberg J, Gouvêa ML, et al. (2013) Scale-integrated atmospheric simulations to assess thermal comfort in different urban tissues in the warm humid summer of São Paulo, Brazil. Urban Climate 6: 24-43. |
| [89] |
Fahmy M, Sharples S, Yahiya M (2010) LAI based trees selection for mid latitude urban developments: A microclimatic study in Cairo, Egypt. Building Environ 45: 345-357. doi: 10.1016/j.buildenv.2009.06.014
|
| [90] | van Hoof J (2008) Forty years of Fanger’s model of thermal comfort: comfort for all? Indoor air 18: 182-201. |
| [91] | Honjo T (2009) Thermal comfort in outdoor environment. Global Environmental Research: 43-47. |
| [92] |
Chen L, Ng E (2012) Outdoor thermal comfort and outdoor activities: A review of research in the past decade. Cities 29: 118-125. doi: 10.1016/j.cities.2011.08.006
|
| [93] |
Berkovic S, Yezioro A, Bitan A (2012) Study of thermal comfort in courtyards in a hot arid climate. Solar Energy 86: 1173-1186. doi: 10.1016/j.solener.2012.01.010
|
| [94] |
Hirabayashi S, Kroll CN, Nowak DJ (2011) Component-based development and sensitivity analyses of an air pollutant dry deposition model. Environ Modell Softw 26: 804-816. doi: 10.1016/j.envsoft.2010.11.007
|
| [95] | NOAA (2012) NOAA’s National Climatic Data Center (NCDC). Available from: http://gis.ncdc.noaa.gov/map/viewer/#app=cdo. Accessed 30 Dec 2012. |
| [96] | Nowak DJ, Crane DE, Stevens JC, et al. (2003) The urban forest effects (UFORE) model: Field data collection manual. Syracuse, NY. |
| [97] | Nowak DJ, Crane DE, Stevens JC, et al. (2002) Brooklyn’s urban forest. Gen. Tech. Rep. NE-290. Newtown Square, PA. |
| [98] | Brown RD, Gillespie TJ (1995) Microclimatic Landscape Design: Creating Thermal Comfort and Energy Efficiency, 1st ed. Wiley, John & Sons. |
| [99] |
Vailshery LS, Jaganmohan M, Nagendra H (2013) Effect of street trees on microclimate and air pollution in a tropical city. Urban For Urban Gree 12: 408-415. doi: 10.1016/j.ufug.2013.03.002
|
| [100] |
Bowler DE, Buyung-Ali L, Knight TM, et al. (2010) Urban greening to cool towns and cities: A systematic review of the empirical evidence. Landscape urban plan 97: 147-155. doi: 10.1016/j.landurbplan.2010.05.006
|
| [101] |
Ng E, Chen L, Wang Y, et al. (2012) A study on the cooling effects of greening in a high-density city: An experience from Hong Kong. Building Environ 47: 256-271. doi: 10.1016/j.buildenv.2011.07.014
|
| [102] |
Johansson E, Emmanuel R (2006) The influence of urban design on outdoor thermal comfort in the hot, humid city of Colombo, Sri Lanka. Int j biometeorol 51: 119-133. doi: 10.1007/s00484-006-0047-6
|
| [103] |
Perini K, Magliocco A (2014) Effects of vegetation, urban density, building height, and atmospheric conditions on local temperatures and thermal comfort.Urban For Urban Gree 13: 495-506. doi: 10.1016/j.ufug.2014.03.003
|
| [104] | Buffoni A, Toccafondi P, Pinzauti S (2007) A green system project for pollution mitigation. Available from: http://ambiente.comune.forli.fc.it/public/cms_page_media/48/Sintesi%20Relazione%20Verde%20Urbano%20Forl%C3%AC_784_6788.pdf |
| [105] |
Jim CY, Chen WY (2008) Assessing the ecosystem service of air pollutant removal by urban trees in Guangzhou (China). J environ manage 88: 665-676. doi: 10.1016/j.jenvman.2007.03.035
|
| [106] |
Tiwary A, Sinnett D, Peachey C, et al. (2009) An integrated tool to assess the role of new planting in PM10 capture and the human health benefits: a case study in London. Environmental pollution 157: 2645-2653. doi: 10.1016/j.envpol.2009.05.005
|
| [107] |
Benjamin MT, Winer AM (1998) Estimating the ozone-forming potential of urban trees and shrubs. Atmospheric Environment 32: 53-68. doi: 10.1016/S1352-2310(97)00176-3
|
| [108] |
Calfapietra C, Fares S, Manes F, et al. (2013) Role of Biogenic Volatile Organic Compounds (BVOC) emitted by urban trees on ozone concentration in cities: a review. Environmental pollution 183: 71-80. doi: 10.1016/j.envpol.2013.03.012
|
| [109] |
Skelhorn C, Lindley S, Levermore G (2014) The impact of vegetation types on air and surface temperatures in a temperate city: A fine scale assessment in Manchester, UK. Landscape urban plan 121: 129-140. doi: 10.1016/j.landurbplan.2013.09.012
|
| [110] |
Manning W (2008) Plants in urban ecosystems: Essential role of urban forests in urban metabolism and succession toward sustainability. Int J Sust Dev World Ecol 15: 362-370. doi: 10.3843/SusDev.15.4:12
|
| [111] | Morani A, Nowak D, Hirabayashi S, et al. (2014) Comparing i-Tree modeled ozone deposition with field measurements in a periurban Mediterranean forest. Environmental pollution 195C: 202-209. |
| [112] | Pataki DE, Carreiro MM, Cherrier J, et al. (2011) Coupling biogeochemical cycles in urban environments: ecosystem services, green solutions, and misconceptions. Front Ecol Environ 9: 27-36. |
| [113] | Bealey WJ, McDonald G, Nemitz E, et al. (2007) Estimating the reduction of urban PM10 concentrations by trees within an environmental information system for planners. J environ manage 85: 44-58. |
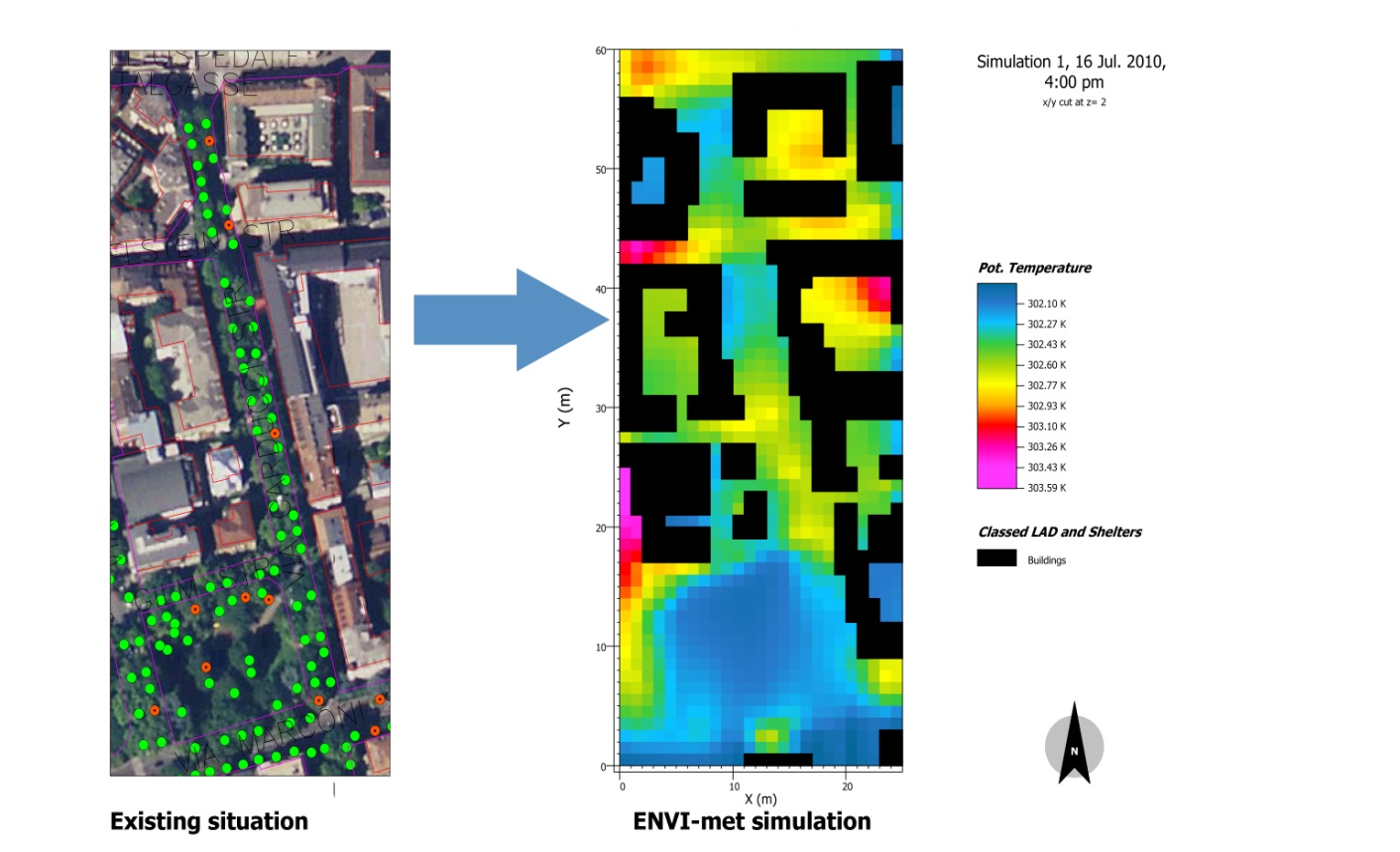
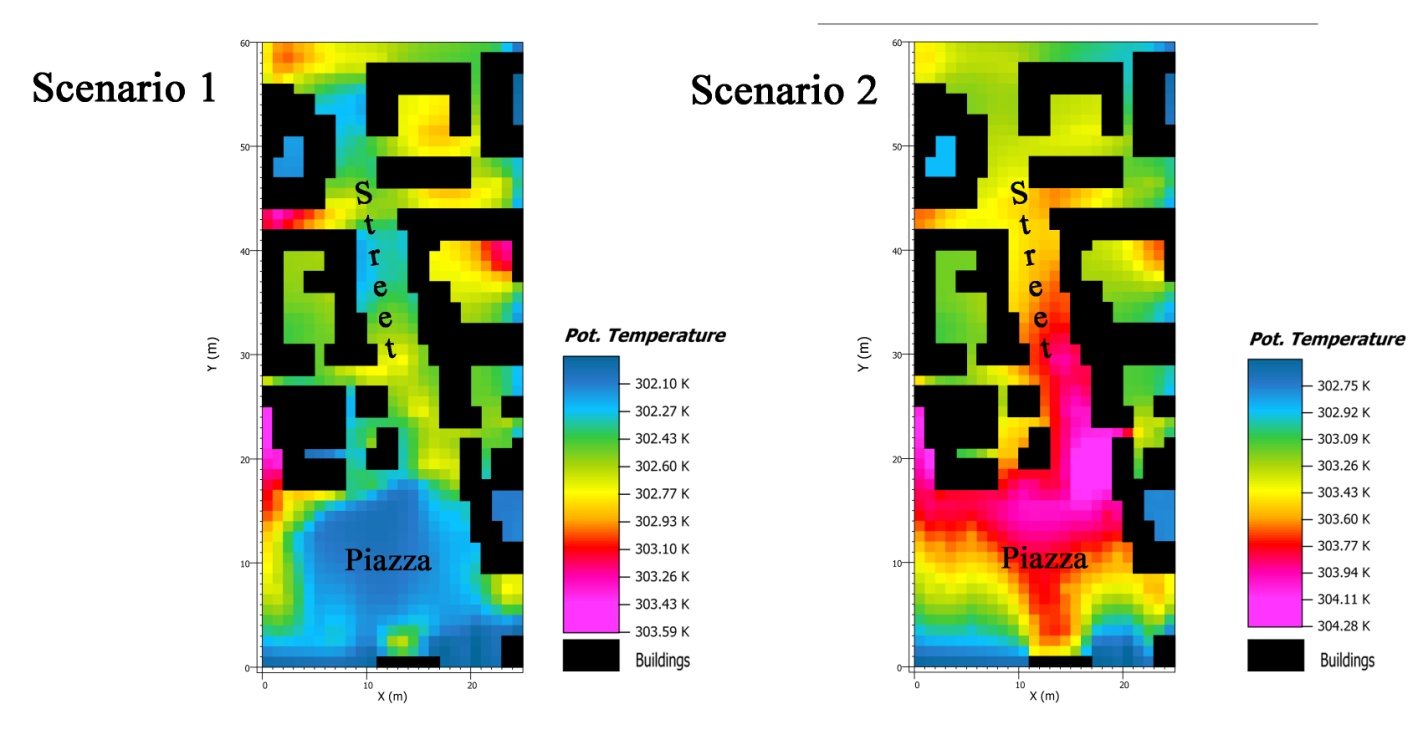
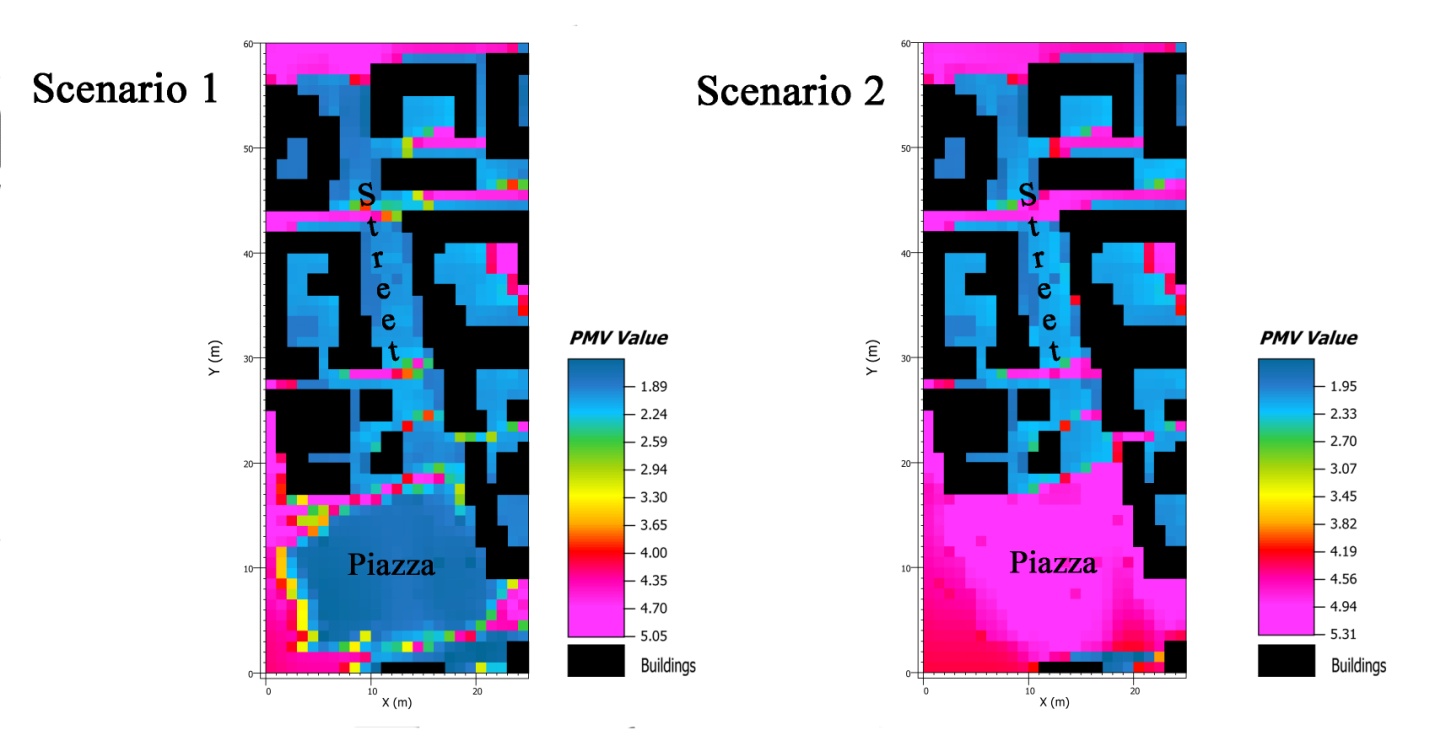
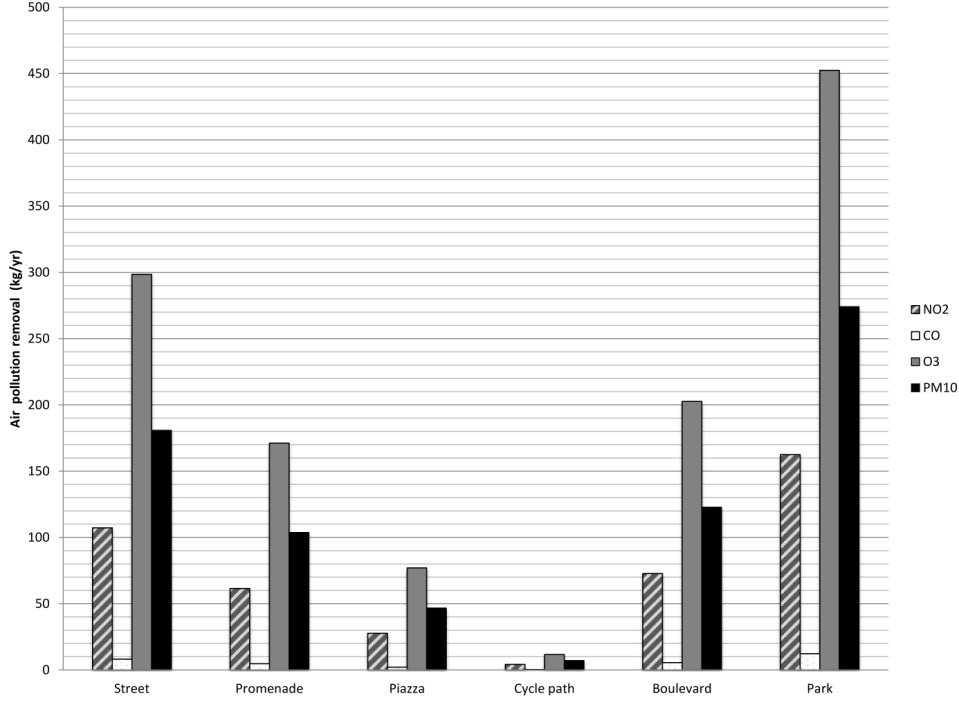
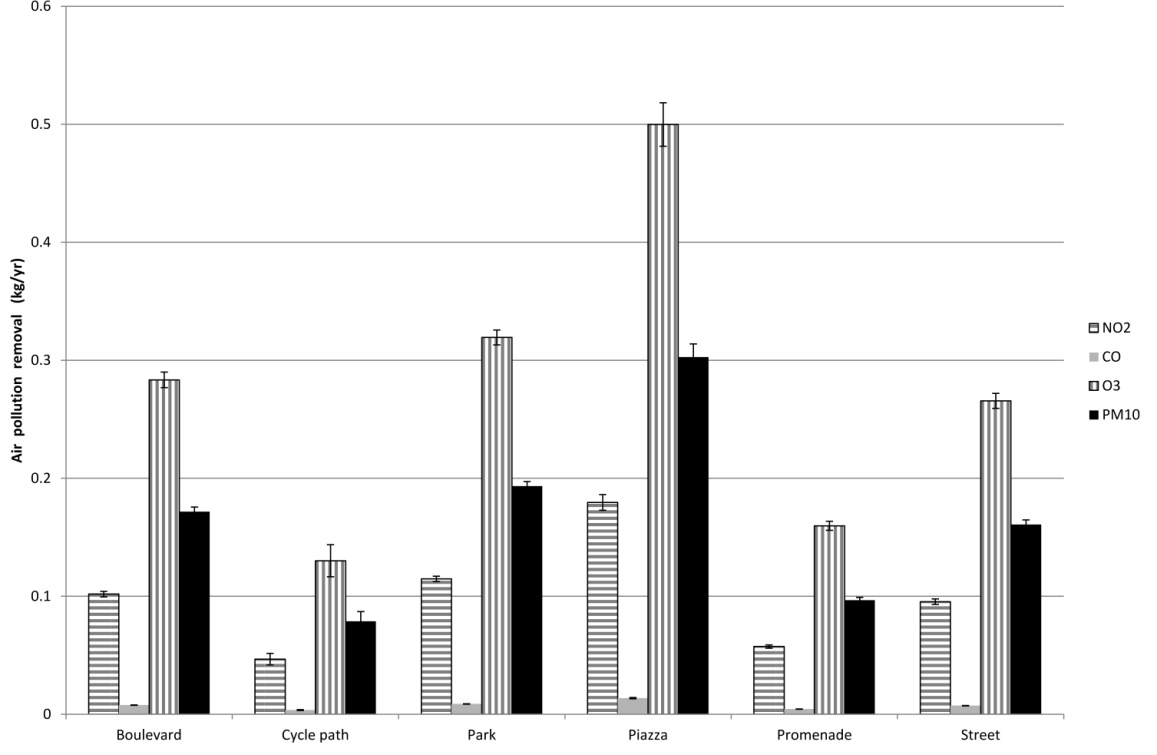
Figures(5) / Tables(2)

Alessio Russo, Francisco J Escobedo, Stefan Zerbe. Quantifying the local-scale ecosystem services provided by urban treed streetscapes in Bolzano, Italy[J]. AIMS Environmental Science, 2016, 3(1): 58-76. doi: 10.3934/environsci.2016.1.58







 DownLoad:
DownLoad: