Citation: Rachel R. Sleeter, William Acevedo, Christopher E. Soulard, Benjamin M. Sleeter. Methods used to parameterize the spatially-explicit components of a state-and-transition simulation model[J]. AIMS Environmental Science, 2015, 2(3): 668-693. doi: 10.3934/environsci.2015.3.668

| [1] |
Vitousek PM, Mooney HA, Lubchenco J, et al. (1997) Human domination of earth's ecosystems. Science 277: 494-499. doi: 10.1126/science.277.5325.494

|
| [2] | DeFries RS, Foley JA, Asner GP (2004) Land-use choices: Balancing human needs and ecosystem function. Front Ecol Environ 2: 249-257. |
| [3] | IPCC (2000) In: Watson, R.T., Noble, I.R., Bolin, B., Ravindranath, N.H., Verardo, D.J., Dokken, D.J. (Eds.), Land Use, Land-Use Change, and Forestry. Special Report of the Intergovernmental Panel on Climate Change. Cambridge University Press, Cambridge, United Kingdom and New York, NY, USA, p. 377. |
| [4] | Foley JA, Defries R, Asner GP, et al. (2005) Global consequences of land use. Science 309: 570-574. |
| [5] |
Pielke RA (2005) Land use and climate change. Science 310: 1625-1626. doi: 10.1126/science.1120529
|
| [6] | Alcamo J (2008) Searching for the future of land: scenarios from the local to global scale. In: Alcamo J (Ed.), Environmental Futures: The Practice of Environmental Scenario Analysis. Elsevier, Amsterdam, The Netherlands. |
| [7] | USGCRP, The National Global Change Research Plan 2012-2021: A Strategic Plan for the U.S. Global Change Research Program. 132 pp. The U.S. Global Change Research Program Washington, D.C., 2012, Available from: http://downloads.globalchange.gov/strategic-plan/2012/usgcrp-strategic-plan-2012.pdf |
| [8] |
Strengers B, Leemans R, Eickhout B, et al. (2004) The land-use projections and resulting emissions in the IPCC SRES scenarios as simulated by the IMAGE 2.2 model. GeoJournal 61: 381-393. doi: 10.1007/s10708-004-5054-8
|
| [9] | National Research Council (2014) Advancing Land Change Modeling: Opportunities and Research Requirements. Washington, DC: The National Academies Press. |
| [10] | Soares-Filho BS, Nepstad DC, Curran LM, et al. (2006) Modeling conservation in the Amazon basin. Nature 440: 520-523. |
| [11] | Eastman JR (2007) The Land Change Modeler, a software extension for ArcGIS. Worcester, Mass.: Clark University. |
| [12] | Matthews RB, Gilbert NG, Roach A, et al. (2007) Agent-based land-use models: A review of applications. Landscape Ecol 22: 1447-1459. |
| [13] |
Acosta-Michlik L, Espaldon V (2008) Assessing vulnerability of selected farming communities in the Philippines based on behavioural model of agent's adaptation to global environmental change. Glob Environ Chang 18: 554-563. doi: 10.1016/j.gloenvcha.2008.08.006
|
| [14] | Brown DG, Page SE, Riolo R, et al. (2004) Agent based and analytical modeling to evaluate the effectiveness of greenbelts. Environ Modell Softw 19: 1097-1109. |
| [15] |
Verburg PH (2002) Land use change modelling at the regional scale: The CLUE-S model. Environ Manage 30: 391-405. doi: 10.1007/s00267-002-2630-x
|
| [16] | Burnham BO (1973) Markov intertemporal land use simulation model. South J Agr Econ 5: 253-258. |
| [17] | Baker WL (1989) A review of models of landscape change. Landscape Ecol 2: 111-133. |
| [18] | Turner M (1987) Spatial simulation of landscape changes in Georgia: A comparison of 3 transition models. Landscape Ecol 1: 29-36. |
| [19] | Daniels CJ, Frid L (2011) Predicting landscape vegetation dynamics using state-and-transition simulation models, In Proceedings of the First Landscape State-and-Transition Simulation Modeling Conference, Portland, OR, USA, 14-16 June 2011; Kerns, B.K., Shlisky, A.J., Daniel, C.J., Eds.; U.S. Department of Agriculture, Forest Service, Pacific Northwest Research Station: Portland, OR, USA, 2012; pp.5-22. |
| [20] | Sleeter BM, Sohl T, Bouchard MA, et al. (2012) Scenarios of land use and land cover change in the conterminous U.S.: Utilizing the special report on emission scenarios at ecoregional scales. Glob Environ Chang 22: 896-914. |
| [21] |
Omernik JM (1987) Ecoregions of the conterminous U.S. Ann Assoc Am Geogr 77: 118-125. doi: 10.1111/j.1467-8306.1987.tb00149.x
|
| [22] | Sleeter BM, Liu J, Daniel C, et al. (2015) An integrated approach to modeling changes in land use, land cover, and disturbance and their impact on ecosystem carbon dynamics: a case study in the Sierra Nevada Mountains of California. AIMS Environ Sci 2: 577-606. |
| [23] | Nakicenovic N, Swart R (Eds.) (2000) IPCC Special Report on Emission Scenarios; Cambridge University Press; Cambridge, UK; p. 570. |
| [24] |
Sleeter BM, Sohl T, Loveland T, et al. (2013) Land-cover change in the conterminous United States from 1973 to 2000. Glob Environ Chang 23: 733-748. doi: 10.1016/j.gloenvcha.2013.03.006
|
| [25] | EPA (U.S. Environmental Protection Agency), Primary distinguishing characteristics of Level III ecoregions of the continental United States. Environmental Protection Agency, 1999. Available from: http://www.epa.gov/wed/pages/ecoregions/level_iii.htm |
| [26] | Gallant AL, Loveland T, Sohl T, et al. (2004) Using an ecoregion framework to analyze land-cover and land-use dynamics. Environ Manage 34: S89-S110. |
| [27] | Soulard CE and Acevedo W, Multi-temporal harmonization of independent land-use/land-cover datasets for the conterminous U.S. American Geophysical Union, 2013. Available from: http://adsabs.harvard.edu/abs/2013AGUFM.B41E0448S |
| [28] | McConnell WJ, Moran EF (Eds.) (2001) Meeting in the middle: the challenge of meso-level integration. An international workshop on the harmonization of land-use and land-cover classification. LUCC Report Series No. 5. Anthropological Center for Training and Research on Global Environmental Change - Indiana University and LUCC International Project Office, Louvain-la-Neuve. |
| [29] |
Jansen LJM, Groom GB, Carrai G (2008) Land-cover harmonisation and semantic similarity: some methodological issues. J Land Use Sci 3:131-160. doi: 10.1080/17474230802332076
|
| [30] | Homer C, Dewitz J, Fry J, et al. (2007) Completion of the 2001 national land cover database for the conterminous U.S. Photogramm Eng Remote Sens 73: 337-341. |
| [31] | Vogelmann JE, Howard SM, Yang L, et al. (2001) Completion of the 1990's national land cover data set for the conterminous U.S. Photogramm Eng Remote Sens 67: 650-662. |
| [32] | Fry J, Xian G, Jin S, et al. (2011) Completion of the 2006 national land cover database for the conterminous U.S. Photogramm Eng Remote Sens 77:858-864. |
| [33] |
Jin S, Yang L, Danielson P (2013) A comprehensive change detection method for updating the National Land Cover Database to circa 2011. Remote Sens Environ 132: 159-175. doi: 10.1016/j.rse.2013.01.012
|
| [34] | LANDFIRE: LANDFIRE Existing Vegetation Type layer. U.S. Department of Interior, Geological Survey, 2013 June last update. Available from: http://landfire.cr.usgs.gov/viewer/ (accessed 1 October 2012) |
| [35] | U.S Department of Agriculture, National Agricultural Statistics Service (2011) Cropland Data Layer. Available from http://nassgeodata.gmu.edu/CropScape/ (accessed on 1 October 2012). |
| [36] | U.S. Geological Survey, Gap Analysis Program (GAP). May 2011. National Land Cover, Version 2 |
| [37] |
Hansen MC, Potapov PV, Moore R, et al. (2013) High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 342: 850-853. doi: 10.1126/science.1244693
|
| [38] | LANDFIRE: LANDFIRE Disturbance (1999-2010). U.S. Department of Interior, Geological Survey, 2013 June last update. Available from: http://landfire.cr.usgs.gov/viewer/ (accessed on 1 October 2012). |
| [39] |
Roy DP, Ju J, Kline K, et al. (2010) Web-enabled Landsat data (WELD): Landsat ETM+ composited mosaics of the conterminous U.S. Remote Sens Environ 114: 35-49. doi: 10.1016/j.rse.2009.08.011
|
| [40] | Eidenshink J, Schwind B, Brewer K, et al. (2007) A project for monitoring trends in burn severity. Fire Ecol Spec Issue 3: 3-21. |
| [41] | Anderson JR, Hardy E, Roach JT, et al. (1976) A land use and land cover classification scheme for use with remote sensor data. U.S. Geological Survey, Reston, VA. USA, Professional Paper 964. |
| [42] |
Pan Y, Chen JM, Birdsey R, et al. (2011) Age structure and disturbance legacy of North American forests. Biogeosciences 8: 715-732. doi: 10.5194/bg-8-715-2011
|
| [43] |
Masek JG, Huang R, Wolfe R, et al. (2008) North American forest disturbance mapped from a decadal Landsat record. Remote Sens Environ 112: 2914- 2926. doi: 10.1016/j.rse.2008.02.010
|
| [44] |
Huang C, Goward SN, Masek JG, et al. (2010) An automated approach for reconstructing recent forest disturbance history using dense Landsat time series stacks. Remote Sens Environ 114: 183-198. doi: 10.1016/j.rse.2009.08.017
|
| [45] |
Tobler W (1970) A computer movie simulating urban growth in the Detroit region. Econ Geogr 46: 234-240. doi: 10.2307/143141
|
| [46] | U.S. Geological Survey GAP. Protected Areas Database of the United States (PAD-US), version 1.3 Combined Feature Class. 2012. Available from: http://gapanalysis.usgs.gov/padus/ (accessed on 13 November 2013). |
| [47] | Natural Resources Conservation Service. Soil Survey Geographic (SSURGO) Database. U.S. Department of Agriculture, 2011. Available from: http://soildatamart.nrcs.usda.gov (accessed on 22 November 2013). |
| [48] | Sleeter R, Gould M (2007) Geographic Information System Software to Remodel Population Data Using Dasymetric Mapping Methods; U.S. Geological Survey Techniques and Methods 11-C2; U.S. Geological Survey, Reston, VA. USA, p. 15. |
| [49] | Wilson BT, Woodall CW, DM Griffith (2013) Imputing forest carbon stock estimates from inventory plots to a nationally continuous coverage. Carbon Balance Manag 8: 1-15. |
| [50] | IMAGE team (2001) The IMAGE 2.2 implementation of the SRES scenarios: climate change scenarios resulting from runs with several GCMs. RIVM CD-ROM Publication 481508019, National Institute of Public Health and the Environment, Bilthoven. |
| [51] |
Van Vuuren D, Edmonds JA, Kainuma M, et al. (2011) The Representative Concentration Pathways: An Overview. Climatic Change 109: 5-31. doi: 10.1007/s10584-011-0148-z
|
| [52] |
Wilson TS, Sleeter BM, Sleeter RR, et al. (2014) Land use threats and protected areas: a scenario-based, landscape level approach. Land 3: 362-389. doi: 10.3390/land3020362
|
| [53] | Sleeter BM (2008) Late 20th century land change in the Central California Valley Ecoregion. California Geographer 48:27-60 |
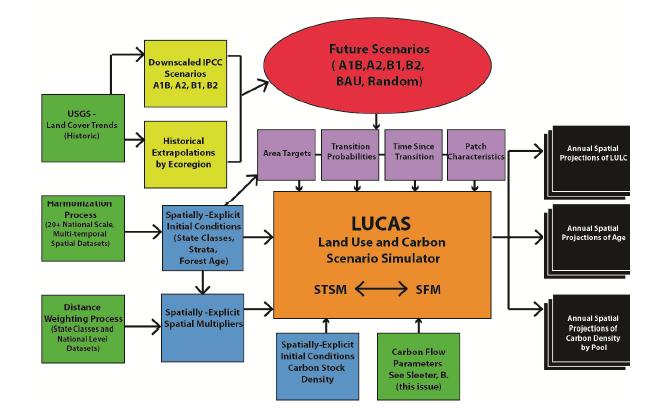
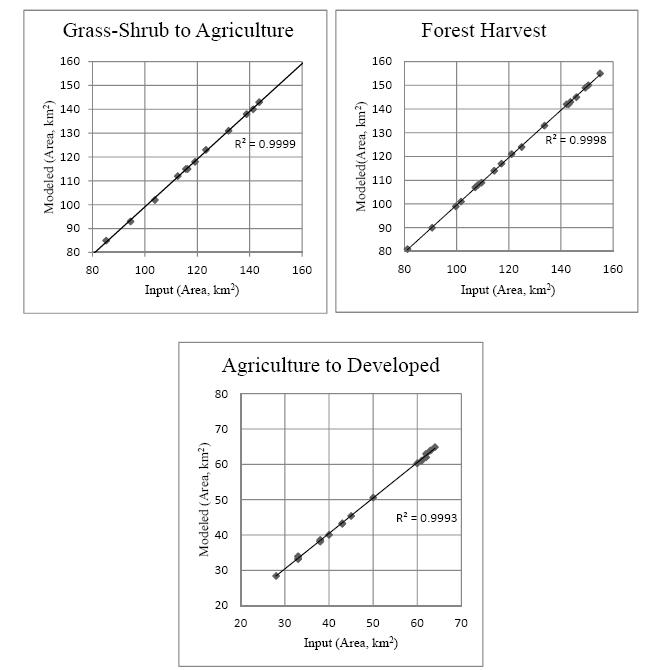
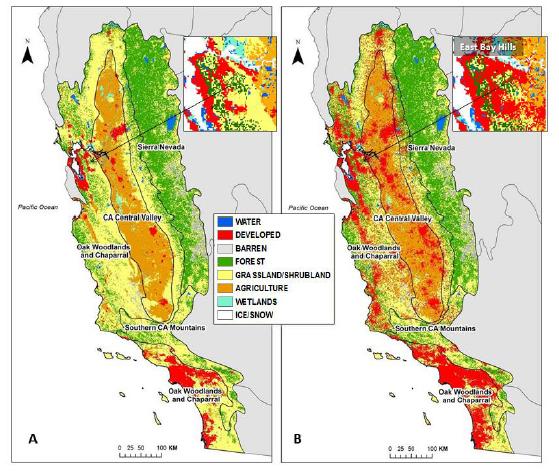
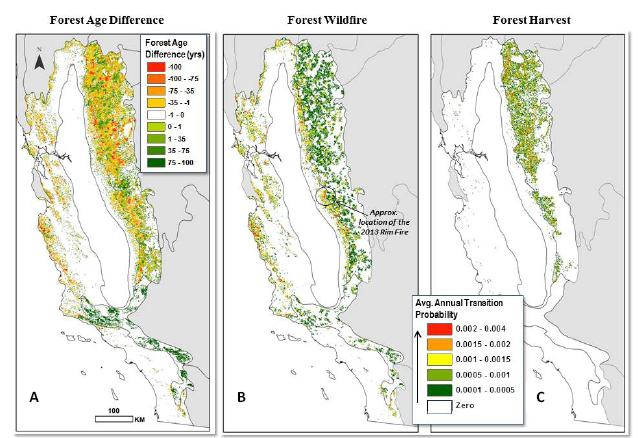
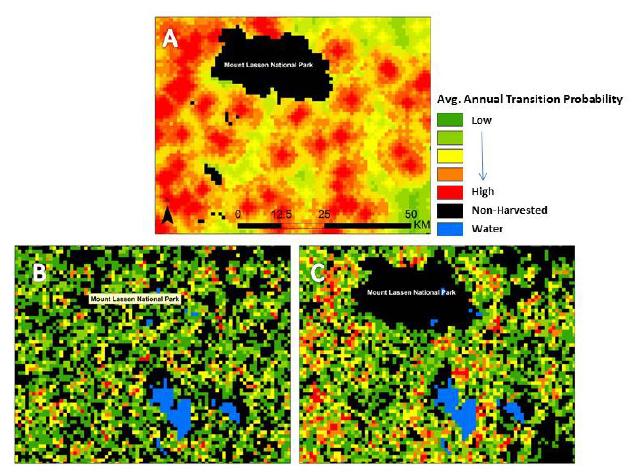
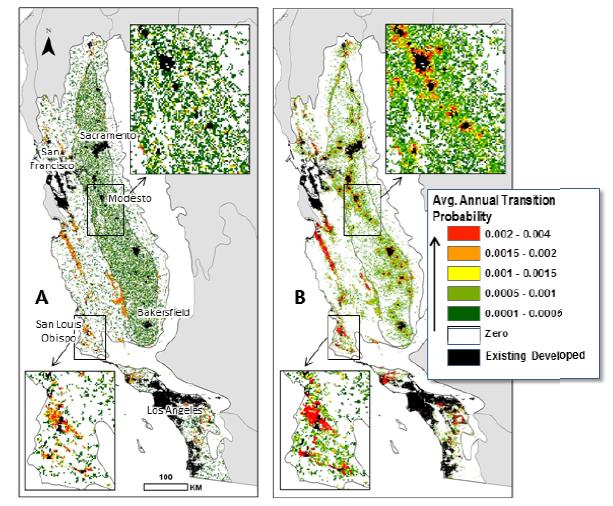
Figures(10)

Rachel R. Sleeter, William Acevedo, Christopher E. Soulard, Benjamin M. Sleeter. Methods used to parameterize the spatially-explicit components of a state-and-transition simulation model[J]. AIMS Environmental Science, 2015, 2(3): 668-693. doi: 10.3934/environsci.2015.3.668







 DownLoad:
DownLoad: