Citation: Minh Y Nguyen. Optimal voltage controls of distribution systems with OLTC and shunt capacitors by modified particle swarm optimization: A case study[J]. AIMS Energy, 2019, 7(6): 883-900. doi: 10.3934/energy.2019.6.883

| [1] |
Erbrink JJ, Gulski E, Smit JJ, et al. (2010) Diagnosis of onload tap changer contact degradation by dynamic resistance measurements. IEEE Trans Power Delivery 25: 2121-2131. doi: 10.1109/TPWRD.2010.2050499

|
| [2] | Quevedo J de O, Cazakevicius FE, Beltrame RC, et al. (2016) Analysis and design of an electronic on-load tap changer distribution transformer for automatic voltage regulation. IEEE Trans Ind Electron 64: 883-894. |
| [3] |
Wu W, Tian Z, Zhang B (2017) An exact linearization method for OLTC of transformer in branch flow model. IEEE Trans Power Syst 32: 2475-2476. doi: 10.1109/TPWRS.2016.2603438
|
| [4] |
Asl DK, Mohammadi M, Seifi AR (2019) Holomorphic embedding load flow for unbalanced radial distribution networks with DFIG and tap-changer modelling. IET Gener, Trans Distrib 13: 4263-4273. doi: 10.1049/iet-gtd.2018.6239
|
| [5] |
Hu J, Marinelli M, Coppo M, et al. (2016) Coordinated voltage control of a decoupled three-phase on-load tap changer transformer and photovoltaic inverters for managing unbalanced networks. Electr Power Syst Res 131: 264-274. doi: 10.1016/j.epsr.2015.10.025
|
| [6] |
Liu X, Airchhorn A, Liu L, et al. (2012) Coordinated control of distributed energy storage system with tap changer transformers for voltage rise mitigation under high photovoltaic penetration. IEEE Trans Smart Grid 3: 897-906. doi: 10.1109/TSG.2011.2177501
|
| [7] |
Kraiczy M, Stetz T, Braun M (2018) Parallel operation of transformers with on load tap changer and photovoltaic systems with reactive power control. IEEE Trans Smart Grid 9: 6419-6428. doi: 10.1109/TSG.2017.2712633
|
| [8] | Kraiczy M, Braun M, Wirth G, et al. (2013) Unintended interferences of local voltage control strategies of HV/MV transformer and distributed generators. European PV Solar Energy Conference and Exhibition, Paris. |
| [9] |
Andren F, Bletterie B, Kadam S, et al. (2015) On the stability of local voltage control in distribution networks with a high penetration of inverter based generation. IEEE Trans Ind Electron 62: 2519-2529. doi: 10.1109/TIE.2014.2345347
|
| [10] | Rauma K, Cadoux F, Hadj-SaïD N, et al. (2016) Assessment of the MV/LV on-load tap changer technology as a way to increase LV hosting capacity for photovoltaic power generators. CIRED Workshop 2016, Helsinki, Finland, June 2016. |
| [11] | Navarro-Espinosa A, Ochoa LF (2015) Increasing the PV hosting capacity of LV networks: OLTC-fitted transformers vs. reinforcements. 2015 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA. |
| [12] | Singh P, Bishnoi SK, Meena NK (2019) Moth search optimization for optimal DERS integration in conjunction to oltc tap operations in distribution systems. IEEE Syst J (Early Access): 1-9. |
| [13] |
Franco JF, Procopiou A, Quirós-Tortós J, et al. (2019) Advanced control of OLTC-enabled LV networks with PV systems and electric vehicles. IET Gener, Trans Distrib 13: 2967-2975. doi: 10.1049/iet-gtd.2019.0208
|
| [14] |
Ku T, Lin C, Chen C, et al. (2019) Coordination of transformer on-load tap changer and PV smart inverters for voltage control of distribution feeders. IEEE Trans Ind Appl 55: 256-264. doi: 10.1109/TIA.2018.2870578
|
| [15] |
Ganguly S, Samajpati D (2017) Distributed generation allocation with on-load tap changer on radial distribution networks using adaptive genetic algorithm. Appl Soft Comput 59: 45-67. doi: 10.1016/j.asoc.2017.05.041
|
| [16] | Nijhuis M, Gibescu M, Cobben JFG (2016) Incorporation of on-load tap changer transformers in low-voltage network planning. IEEE PES Innovative Smart Grid Technologies Conference Europe (ISGT-Europe), Ljubljana, Slovenia, Oct. 2016. |
| [17] | Iria J, Heleno M, Candoso G (2019) Optimal sizing and placement of energy storage systems and on-load tap changer transformers in distribution networks. Appl Energy 15: 1147-57. |
| [18] |
Meena NK, Swarnkar A, Gupta N, et al. (2018) Optimal integration of DERs in coordination with existing VRs in distribution networks. IET Gener, Trans Distrib 12: 2520-2529. doi: 10.1049/iet-gtd.2017.1403
|
| [19] |
Nick M, Cherkaoui R, Paolone M (2014) Optimal allocation of dispersed energy storage systems in active distribution networks for energy balance and grid support. IEEE Trans Power Syst 29: 2300-2310. doi: 10.1109/TPWRS.2014.2302020
|
| [20] | IEEE Standard 1547-2018 (2018) IEEE Standard for interconnection and interoperability of distributed energy resources with associated electric power systems interfaces. IEEE Standard Association. |
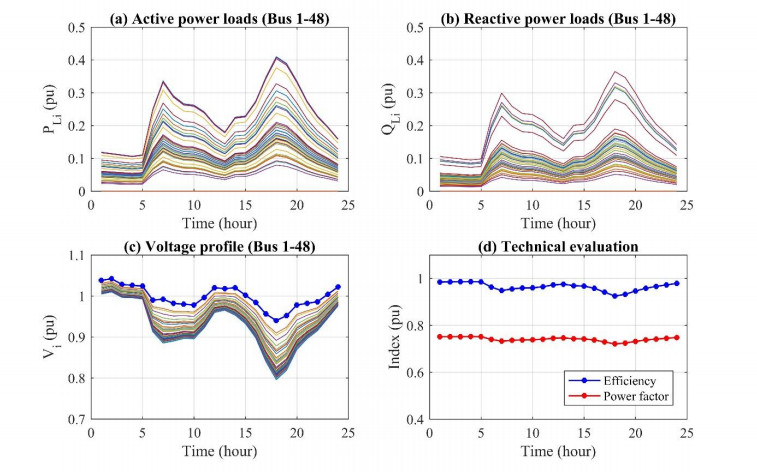
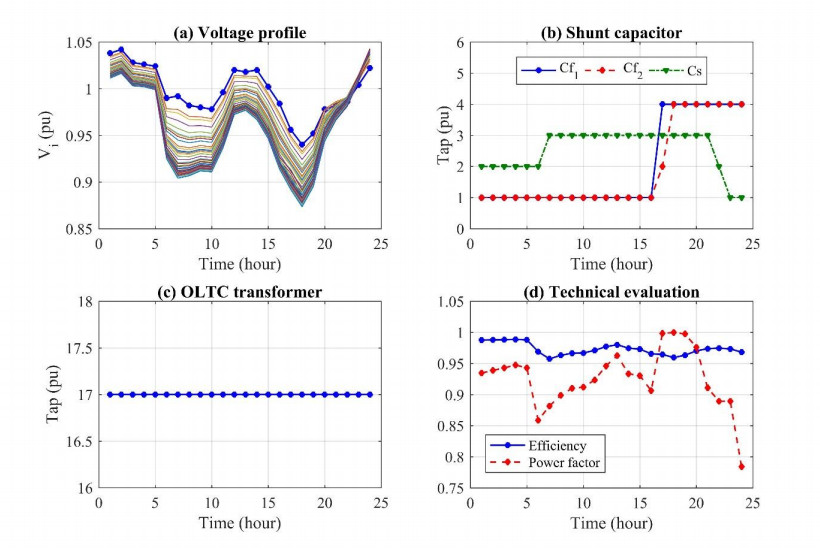
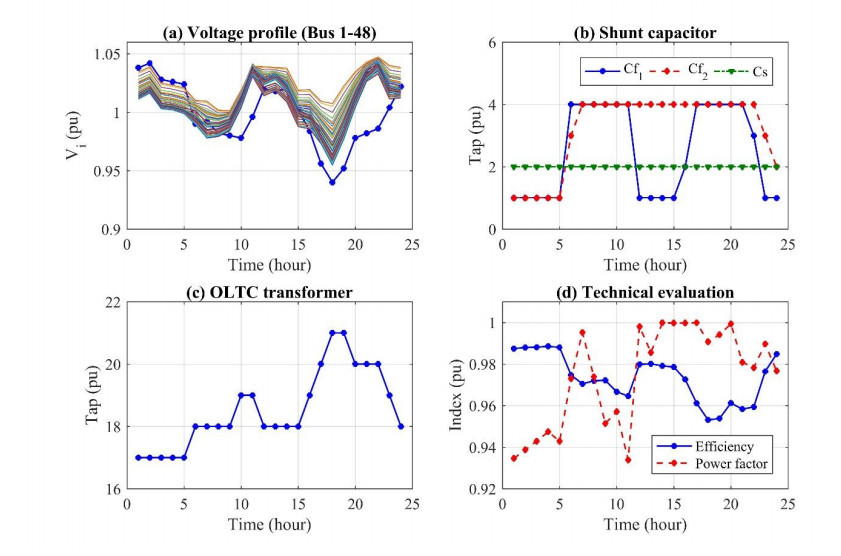
Figures(12)

Minh Y Nguyen. Optimal voltage controls of distribution systems with OLTC and shunt capacitors by modified particle swarm optimization: A case study[J]. AIMS Energy, 2019, 7(6): 883-900. doi: 10.3934/energy.2019.6.883







 DownLoad:
DownLoad: