Citation: Takvor Soukissian, Anastasios Papadopoulos, Panagiotis Skrimizeas, Flora Karathanasi, Panagiotis Axaopoulos, Evripides Avgoustoglou, Hara Kyriakidou, Christos Tsalis, Antigoni Voudouri, Flora Gofa, Petros Katsafados. Assessment of offshore wind power potential in the Aegean and Ionian Seas based on high-resolution hindcast model results[J]. AIMS Energy, 2017, 5(2): 268-289. doi: 10.3934/energy.2017.2.268

| [1] | European Wind Energy Association, The European offshore wind industry-key trends and statistics 2015. European Wind Energy Association, 2016. Available from: https://www.ewea.org/fileadmin/files/library/publications/statistics/EWEA-European-Offshore-Statistics- 2015.pdf. |
| [2] |
Bilgili M, Yasar A, Simsek E (2011) Offshore wind power development in Europe and its comparison with onshore counterpart. Renew Sust Energ Rev 15: 905–915. doi: 10.1016/j.rser.2010.11.006

|
| [3] | Perveen R, Kishor N, Mohanty SR (2014) Off-shore wind farm development: present status and challenges. Renew Sust Energ Rev 29: 780–792. |
| [4] |
Soukissian TH, Papadopoulos A (2015) Effects of different wind data sources in offshore wind power assessment. Renew Energ 77: 101–114. doi: 10.1016/j.renene.2014.12.009
|
| [5] |
Colmenar SA, Perera PJ, Borge DD, et al. (2016) Offshore wind energy: a review of the current status, challenges and future development in Spain. Renew Sust Energ Rev 64: 1–18. doi: 10.1016/j.rser.2016.05.087
|
| [6] | European Wind Energy Association, Wind in power: 2015 European statistics. European Wind Energy Association, 2016. Available from: http://www.ewea.org/fileadmin/files/library/ publications/ statistics/ EWEA-Annual-Statistics-2015.pdf. |
| [7] |
Soukissian T, Reizopoulou S, Drakopoulou P, et al. (2016) Greening offshore wind with the smart wind chart evaluation tool. Web Ecol 16: 73–80. doi: 10.5194/we-16-73-2016
|
| [8] | Kaldellis JK, Apostolou D, Kapsali M, et al. (2016) Environmental and social footprint of offshore wind energy. Comparison with onshore counterpart. Renew Energ 92: 543–556. |
| [9] | Brownlee MTJ, Hallo JC, Jodice LW, et al. (2015) Attitudes toward offshore wind energy development. J Leisure Res 47: 263–284. |
| [10] |
Westerberg V, Jacobsen JB, Lifran R (2013) The case for offshore wind farms, artificial reefs and sustainable tourism in the French Mediterranean. Tourism Manag 34: 172–183. doi: 10.1016/j.tourman.2012.04.008
|
| [11] | DIRM Méditerranée, Document de planification: Le développement de l'éolien en mer Méditerranée. France: Préfecture maritime de la Méditerranée, Préfecture de région Provence Alpes Côte d'Azur, 2015. Available from: http://www.dirm.mediterranee.developpement-durable.gouv.fr/ IMG/pdf/ Document_de_planification_pour_transmission.pdf. |
| [12] | 4C Offshore, Two more French Floaters get approved! 4C Offshore, 2016. Available from: http://www.4coffshore.com/windfarms/two-more-french-floaters-get-approved!-nid4813.html. |
| [13] |
Rodrigues S, Restrepo C, Kontos E, et al. (2015) Trends of offshore wind projects. Renew Sust Energ Rev 49: 1114–1135. doi: 10.1016/j.rser.2015.04.092
|
| [14] |
Westerberg V, Jacobsen JB, Lifran R (2015) Offshore wind farms in Southern Europe-determining tourist preference and social acceptance. Energ Res Soc Sci 10: 165–179. doi: 10.1016/j.erss.2015.07.005
|
| [15] |
Zountouridou EI, Kiokes GC, Chakalis S, et al. (2015) Offshore floating wind parks in the deep waters of Mediterranean Sea. Renew Sust Energ Rev 51: 433–448. doi: 10.1016/j.rser.2015.06.027
|
| [16] |
Onea F, Deleanu L, Rusu L, et al. (2016) Evaluation of the wind energy potential along the Mediterranean Sea coasts. Energ Explor Exploit 34: 766–792. doi: 10.1177/0144598716659592
|
| [17] |
Balog I, Ruti PM, Tobin I, et al. (2016) A numerical approach for planning offshore wind farms from regional to local scales over the Mediterranean. Renew Energ 85: 395–405. doi: 10.1016/j.renene.2015.06.038
|
| [18] |
Kotroni V, Lagouvardos K, Lykoudis S (2014) High-resolution model-based wind atlas for Greece. Renew Sust Energ Rev 30: 479–489. doi: 10.1016/j.rser.2013.10.016
|
| [19] |
Emmanouil G, Galanis G, Kalogeri C, et al. (2016) 10-year high resolution study of wind, sea waves and wave energy assessment in the Greek offshore areas. Renew Energ 90: 399–419. doi: 10.1016/j.renene.2016.01.031
|
| [20] | Soukissian T, Karathanasi F, Axaopoulos P (2017) Satellite-based offshore wind resource assessment in the Mediterranean Sea. IEEE J Oceanic Eng 42: 73–86. |
| [21] |
Soukissian TH (2014) Probabilistic modeling of directional and linear characteristics of wind and sea states. Ocean Eng 91: 91–110. doi: 10.1016/j.oceaneng.2014.08.018
|
| [22] |
Song M, Chen K, Zhang X, et al. (2016) Optimization of wind turbine micro-siting for reducing the sensitivity of power generation to wind direction. Renew Energ 85: 57–65. doi: 10.1016/j.renene.2015.06.033
|
| [23] |
Watson SJ (2014) Quantifying the variability of wind energy. Wires Energ Environ 3: 330–342. doi: 10.1002/wene.95
|
| [24] | EMODnet, EMODnet Bathymetry portal. EMODnet, 2016. Available from: http://www.emodnet-hydrography.eu/. |
| [25] |
Caralis G, Chaviaropoulos P, Ruiz Albacete V, et al. (2016) Lessons learnt from the evaluation of the feed-in tariff scheme for offshore wind farms in Greece using a Monte Carlo approach. J Wind Eng Ind Aerod 157: 63–75. doi: 10.1016/j.jweia.2016.08.008
|
| [26] | Greek Parliament, Governmental Gazette, A' No. 149/9-8-2016, L. 4414/2016. Official Government Gazette of the Hellenic Republic. |
| [27] | European Commission, Official Journal of the European Union, Guidelines on State aid for environmental protection and energy 2014-2020 (2014/C 200/01). European Commission, 2014. Available from: http://eur-lex.europa.eu/legal-content/EN/TXT/PDF/?uri=CELEX:52014XC 0628(01)&from=EN. |
| [28] | Karathanasi FE, Soukissian TH, Axaopoulos PG (2016) Calibration of wind directions in the Mediterranean Sea. In: Proceedings of the 26th International Ocean and Polar Engineering Conference; 2016; Rhodes, Greece, 491–497. |
| [29] | Fisher N (1995) Statistical analysis of circular data. 1st ed. Cambridge: Cambridge University Press, 294. |
| [30] | Jammalamadaka R, SenGupta A (2001) Topics in circular statistics. Singapore: World Scientific Publishing Co. Pte. Ltd., 334. |
| [31] | Hansen FV (1993) Surface roughness lengths. White Sands Missile Range, New Mexico: U.S. Army Research Laboratory, 1–40. |
| [32] |
Shu ZR, Li QS, He YC, et al. (2016) Observations of offshore wind characteristics by Doppler-LiDAR for wind energy applications. Appl Energ 169: 150–163. doi: 10.1016/j.apenergy.2016.01.135
|
| [33] |
Papadopoulos A, Katsafados P (2009) Verification of operational weather forecasts from the POSEIDON system across the Eastern Mediterranean. Nat Hazards Earth Syst Sci 9: 1299–1306. doi: 10.5194/nhess-9-1299-2009
|
| [34] | Papadopoulos A, Korres G, Katsafados P, et al. (2011) Dynamic downscaling of the ERA-40 data using a mesoscale meteorological model. Mediterranean Mar Sci 12: 183–198. |
| [35] | Ferrier BS, Jin Y, Lin Y, et al. (2002) Implementation of a new grid-scale cloud and precipitation scheme in the NCEP Eta Model. 19th Conference on weather analysis and forecasting/15th Conference on numerical weather prediction. San Antonio: Am Meteorol Soc, 280–283. |
| [36] | Janjic ZI, Gerrity JP, Nickovic S (2001) An alternative approach to nonhydrostatic modeling. Mon Weather Rev 129: 1164–1178. |
| [37] | Janjić ZI (1994) The step-mountain Eta coordinate model: further developments of the convection, viscous sublayer, and turbulence closure schemes. Mon Weather Rev 122. |
| [38] |
Chen F, Janjić Z, Mitchell K (1997) Impact of atmospheric surface-layer parameterizations in the new land-surface scheme of the NCEP mesoscale eta model. Bound Lay Meteorol 85: 391–421. doi: 10.1023/A:1000531001463
|
| [39] | Lacis AA, Hansen J (1974) A parameterization for the absorption of solar radiation in the earth's atmosphere. J Atmos Sci 31: 118–133. |
| [40] |
Schwarzkopf MD, Fels SB (1991) The simplified exchange method revisited: an accurate, rapid method for computation of infrared cooling rates and fluxes. J Geophys Res 96: 9075–9096. doi: 10.1029/89JD01598
|
| [41] | Soukissian T, Chronis G (2000) Poseidon: a marine environmental monitoring, forecasting and information system for the Greek Seas. Mediterranean Mar Sci 1: 71–78. |
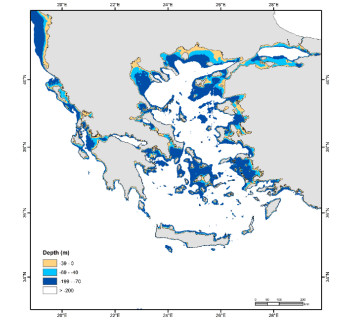
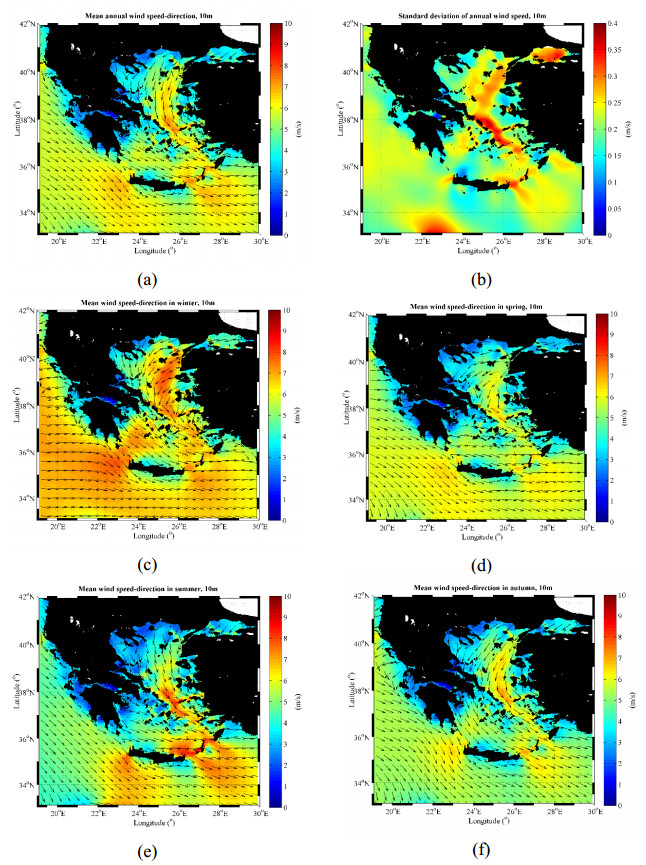

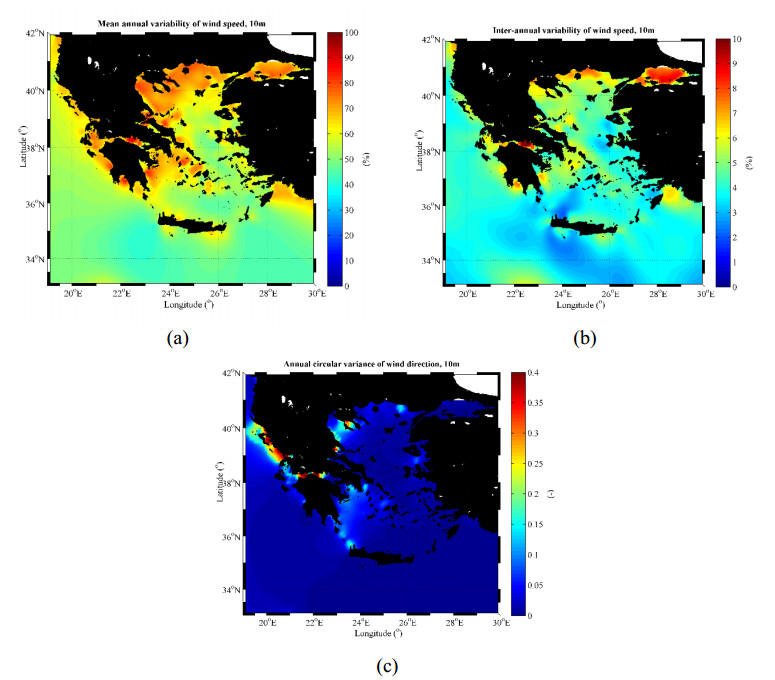
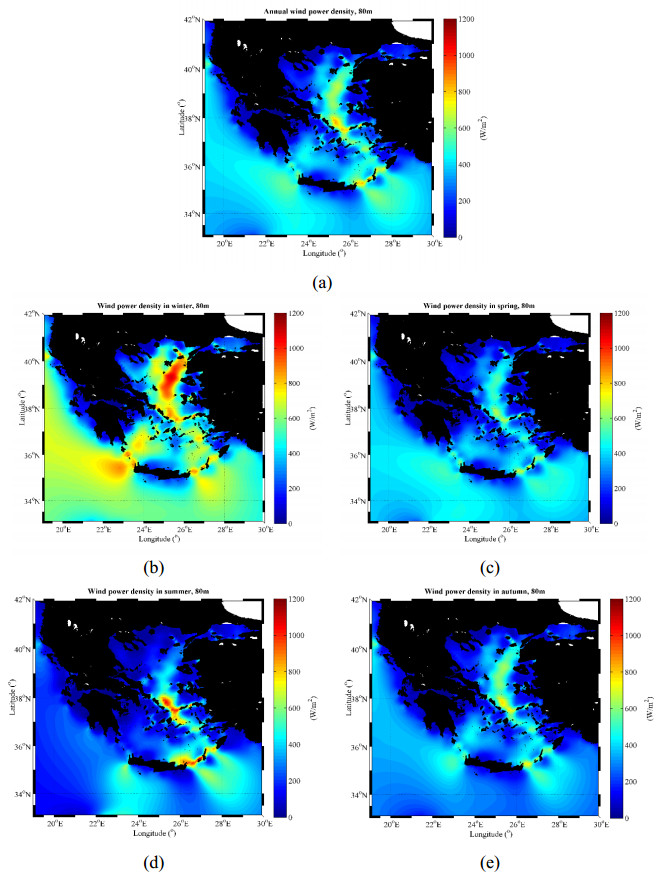

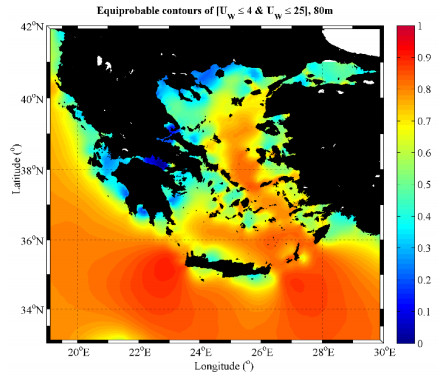
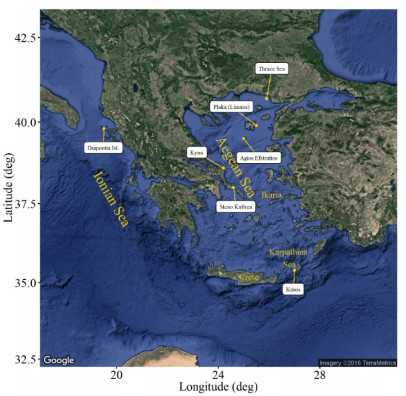
Figures(8) / Tables(6)

Takvor Soukissian, Anastasios Papadopoulos, Panagiotis Skrimizeas, Flora Karathanasi, Panagiotis Axaopoulos, Evripides Avgoustoglou, Hara Kyriakidou, Christos Tsalis, Antigoni Voudouri, Flora Gofa, Petros Katsafados. Assessment of offshore wind power potential in the Aegean and Ionian Seas based on high-resolution hindcast model results[J]. AIMS Energy, 2017, 5(2): 268-289. doi: 10.3934/energy.2017.2.268







 DownLoad:
DownLoad: