Citation: Wolf-Gerrit Früh. From local wind energy resource to national wind power production[J]. AIMS Energy, 2015, 3(1): 101-120. doi: 10.3934/energy.2015.1.101

| [1] | Adler J, (2010) R in a nutshell. O'Reilly: Beijing Sebastopol. |
| [2] | Albadi M H, El-Saadany E F, (2010) Overview of wind power intermittency impacts on power systems. Electric Power Systems Research, 80(6):627-632. |
| [3] | Baeyens E, Bitar E Y, Khargonekar P P, Poolla K, (2013) Coalitional aggregation of wind power. IEEE Transactions on Power Systems, 28(4):3774-3784. |
| [4] | Bludszuweit H, Dominguez-Navarro J A, Llombart A, (2008) Statistical analysis of wind power forecast error. IEEE Transactions on Power Systems, 23(3):983-991. |
| [5] | Chalkiadakis G, Robu V, Kota R, Rogers A, Jennings N R, (2011) Cooperatives of distributed energy resources for eficient virtual power plants. In: The Tenth International Conference on Autonomous Agents and Multiagent Systems (AAMAS-2011), 2: 787 - 794. |
| [6] |
Coker P, Barlow J, Cockerill T, Shipworth D, (2013) Measuring significant variability characteristics: An assessment of three UK renewables. Renewable Energy, 53:111-120. doi: 10.1016/j.renene.2012.11.013

|
| [7] | Cradden L C, Harrison G P, Chick J P, (2012) Will climate change impact on wind power development in the UK? Climatic Change, 115(3-4):837-852. |
| [8] |
Davy T, Woods M, Russell C, Coppin P, (2010) Statistical downscaling of wind variability from meteorological fields. Boundary-Layer Meteorology, 135:161-175. doi: 10.1007/s10546-009-9462-7
|
| [9] | de Boer H S, Grond L, Moll H, Benders R, (2014) The application of power-to-gas, pumped hydro storage and compressed air energy storage in an electricity system at different wind power penetration levels. Energy, 72(0):360 -370. |
| [10] | DECC, (2012) Electricity generation costs. Technical report, UK Department of Energy and Climate Change, October2012. |
| [11] | Earl N, Dorling S, Hewston R, von Glasow R, (2013) 1980-2010 variability in UK surface wind climate. Journal of Climate, 26(4):1172-1191. |
| [12] | Fabbri A, Gomez T, Roman S, Abbad J R, Quezada V H M, (2005) Assessment of the cost associated with wind generation prediction errors in a liberalized electricity market. IEEE Transactions on Power Systems Transactions on Power Systems, 20(3):1440-1446. |
| [13] | Fertig E, Apt J, Jaramillo P, Katzenstein W, (2012) The effect of long-distance interconnection on wind power variability. Environmental Research Letters, 7(3): 034017. |
| [14] |
Foley A M, Leahy P G, Marvuglia A, and McKeogh A J, (2012) Current methods and advances in forecasting of wind power generation. Renewable Energy, 37:1 - 8. doi: 10.1016/j.renene.2011.05.033
|
| [15] |
Fruh W-G, (2013) Long-term wind resource and uncertainty estimation using wind records from Scotland as example. Renewable Energy, 50:1014 - 1026. doi: 10.1016/j.renene.2012.08.047
|
| [16] | Fruh W-G, (2014) How much can regional aggregation of wind farms and smart grid demand management facilitate wind energy integration? In: Proceedings of the World Renewable Energy Congress-XIII "Renewable Energy in the Service of Mankind", 3-8 August, 2014, London, UK. |
| [17] | Fruh W-G, (2013) Energy storage requirements to match wind generation and demand applied to the UK network. In: International Conference on Renewable Energies and Power Quality (ICREPQ'13), Renewable Energy and Power Quality Journal 11. |
| [18] | Gahleitner G, (2013) Hydrogen from renewable electricity: An international review of power-to-gas pilot plants for stationary applications. International Journal of Hydrogen Energy, 38(5):2039 - 2061. |
| [19] | Hasche B, (2010) General statistics of geographically dispersed wind power. Wind Energy, 13(8):773-784. |
| [20] | Hornik K, (2011) The R FAQ. ISBN 3-900051-08-9. Available at http://CRAN.R-project.org/doc/FAQ/R-FAQ.html |
| [21] | Katzenstein W, Fertig E, Apt J, (2010) The variability of interconnected wind plants. Energy Policy, 38(8):4400 -4410. |
| [22] | Liu S, Jian J, Wang Y, Liang J, (2013) A robust optimization approach to wind farm diversification. International Journal of Electrical Power & Energy Systems, 53:409-415. |
| [23] | Liu X, (2011) Impact of beta-distributed wind power on economic load dispatch. Electric Power Components and Systems, 39(8):768-779. |
| [24] | Marques de S a J P, editor, (2007) Applied Statistics Using SPSS, STATISTICA, MATLAB and R. Springer-Verlag: Berlin Heidelberg New York. |
| [25] | National Grid, (2013) Electricity ten year statement (ETYS). Technical report, National Grid. |
| [26] | National Grid, (2013) Half-hourly demand data. Available from http://www2.nationalgrid.com/UK/Industryinformation/ Electricity-transmission-operational-data |
| [27] |
Nolan P, Lynch P, McGrath R, Semmler T, Wang S, (2012) Simulating climate change and its effects on the wind energy resource of Ireland. Wind Energy, 15:593 - 608. doi: 10.1002/we.489
|
| [28] | Pand zi c H, Morales J M, Conejo A J, Kuzle I, (2013) Offering model for a virtual power plant based on stochastic programming. Applied Energy, 105(0):282 - 292. |
| [29] | Pritchard G, (2011) Short-term variations in wind power: some quantile-type models for probabilistic forecasting. Wind Energy, 14(2):255-269. |
| [30] | Sinden G, (2007) Characteristics of the UK wind resource: Long-term patterns and relationship to electricity demand. Energy Policy, 35(1):112 - 127. |
| [31] | Skittides C, Fruh W-G, (2013) Wind speed forecasting using singular systems analysis. In: International Conference on Renewable Energies and Power Quality (ICREPQ'13), Renewable Energy and Power Quality Journal 11. |
| [32] | Sturt A, Strbac G, (2011) Time series modelling of power output for large-scale wind fleets. Wind Energy, 14(8):953-966. |
| [33] | Tapiador F J, (2009) Assessment of renewable energy potential through satellite data and numerical models. Energy & Environmental Science, 2(11):1142-1161. |
| [34] | Tarroja B, Mueller F, Eichman J D, Brouwer J, Samuelsen S, (2011) Spatial and temporal analysis of electric wind generation intermittency and dynamics. Renewable Energy, 36(12):3424-3432. |
| [35] | Tascikaraoglu A, Erdinc O, Uzunoglu M, Karakas A, (1014) An adaptive load dispatching and forecasting strategy for a virtual power plant including renewable energy conversion units. Applied Energy, 119(0):445 - 453. |
| [36] | UK Meteorological Ofice, (2011) MIDAS Land Surface Stations data (1853-current). NCAS British Atmospheric Data Centre. Available from http://badc.nerc.ac.uk/view/badc.nerc.ac.uk ATOM dataent ukmo-midas. |
| [37] | Watson S J, Kritharas P, Hodgson G J, (2015) Wind speed variability across the UK between 1957 and 2011. Wind Energy, 18(1): 21 - 42. |
| [38] | Zhang G, Wan X, (2014) A wind-hydrogen energy storage system model for massive wind energy curtailment. International Journal of Hydrogen Energy, 39(3):1243-1252. |
| [39] | Zhang Z-S, Sun Y-Z, Gao D W, Lin J, Cheng L, (2013) A versatile probability distribution model for wind power forecast errors and its application in economic dispatch. IEEE Transactions on Power Systems Transactions on Power Systems, 28(3):3114-3125. |

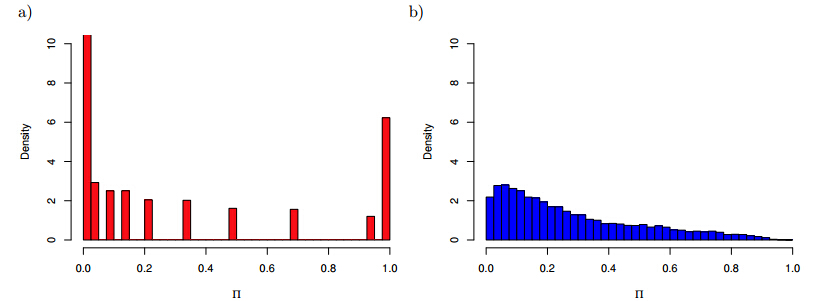
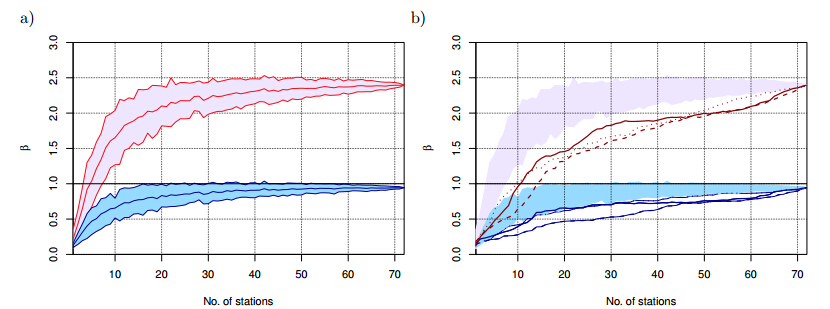
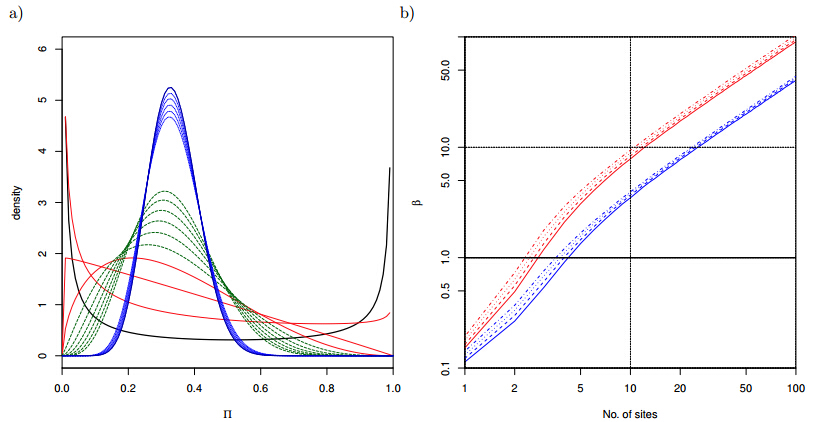
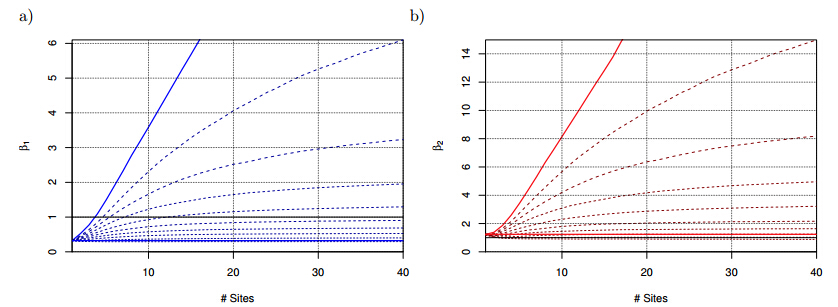

Figures(13)

Wolf-Gerrit Früh. From local wind energy resource to national wind power production[J]. AIMS Energy, 2015, 3(1): 101-120. doi: 10.3934/energy.2015.1.101







 DownLoad:
DownLoad: