




| Holling type | Definition | Generalized form |
| Ⅱ | $ p(u)=\frac{mu}{u+k} $ | |
| Ⅲ | $ p(u)=\frac{mu^2}{u^2+k} $ | $ p(u)=\frac{mu^2}{k_1u^2+k_2u+1}(k_2>-2\sqrt{k_1}) $ |
| Ⅳ | $ p(u)=\frac{mu}{u^2+k} $ | $ p(u)=\frac{mu}{k_1u^2+k_2u+1}(k_2>-2\sqrt{k_1}) $ |
Citation: Daphiny Pottmaier, Marcello Baricco. Materials for hydrogen storage and the Na-Mg-B-H system[J]. AIMS Energy, 2015, 3(1): 75-100. doi: 10.3934/energy.2015.1.75
| [1] | Tianhui Sha, Yikai Zhang, Yong Peng, Wanzeng Kong . Semi-supervised regression with adaptive graph learning for EEG-based emotion recognition. Mathematical Biosciences and Engineering, 2023, 20(6): 11379-11402. doi: 10.3934/mbe.2023505 |
| [2] | Dingxin Xu, Xiwen Qin, Xiaogang Dong, Xueteng Cui . Emotion recognition of EEG signals based on variational mode decomposition and weighted cascade forest. Mathematical Biosciences and Engineering, 2023, 20(2): 2566-2587. doi: 10.3934/mbe.2023120 |
| [3] | Yanling An, Shaohai Hu, Shuaiqi Liu, Bing Li . BiTCAN: An emotion recognition network based on saliency in brain cognition. Mathematical Biosciences and Engineering, 2023, 20(12): 21537-21562. doi: 10.3934/mbe.2023953 |
| [4] | Zhijing Xu, Yang Gao . Research on cross-modal emotion recognition based on multi-layer semantic fusion. Mathematical Biosciences and Engineering, 2024, 21(2): 2488-2514. doi: 10.3934/mbe.2024110 |
| [5] | Yunyuan Gao, Zhen Cao, Jia Liu, Jianhai Zhang . A novel dynamic brain network in arousal for brain states and emotion analysis. Mathematical Biosciences and Engineering, 2021, 18(6): 7440-7463. doi: 10.3934/mbe.2021368 |
| [6] | Jia-Gang Qiu, Yi Li, Hao-Qi Liu, Shuang Lin, Lei Pang, Gang Sun, Ying-Zhe Song . Research on motion recognition based on multi-dimensional sensing data and deep learning algorithms. Mathematical Biosciences and Engineering, 2023, 20(8): 14578-14595. doi: 10.3934/mbe.2023652 |
| [7] | Anlu Yuan, Tieyi Zhang, Lingcong Xiong, Zhipeng Zhang . Torque control strategy of electric racing car based on acceleration intention recognition. Mathematical Biosciences and Engineering, 2024, 21(2): 2879-2900. doi: 10.3934/mbe.2024128 |
| [8] | Basem Assiri, Mohammad Alamgir Hossain . Face emotion recognition based on infrared thermal imagery by applying machine learning and parallelism. Mathematical Biosciences and Engineering, 2023, 20(1): 913-929. doi: 10.3934/mbe.2023042 |
| [9] | C Willson Joseph, G. Jaspher Willsie Kathrine, Shanmuganathan Vimal, S Sumathi., Danilo Pelusi, Xiomara Patricia Blanco Valencia, Elena Verdú . Improved optimizer with deep learning model for emotion detection and classification. Mathematical Biosciences and Engineering, 2024, 21(7): 6631-6657. doi: 10.3934/mbe.2024290 |
| [10] | Teng Fei, Hongjun Wang, Lanxue Liu, Liyi Zhang, Kangle Wu, Jianing Guo . Research on multi-strategy improved sparrow search optimization algorithm. Mathematical Biosciences and Engineering, 2023, 20(9): 17220-17241. doi: 10.3934/mbe.2023767 |
The study of the long term symbiosis and complex dynamics among different interacting species is a hot topic and has attracted more and more attention of mathematicians and biologists over decades. Under the observations of interactions between various species, researchers purposed many appropriated mathematical models. Among these models, the Lotka-Volterra predator-prey model proposed by Lotka[1] and Volterra[2] is a widely known model due to its universal application and significance. Now, the various Lotka-Volterra models are developed to study the complex population dynamics in different ecological situations. Hence, taking into consideration prey competition and different functional responses, the original Lotka-Volterra model is extended to the generalized Gause type case[3,4]
|
$ dudt=au−bu2−vp(u),dvdt=v(−c+dp(u)), $
|
(1.1) |
where $ u $ and $ v $ separately represent the amount of prey and predators; $ a $ and $ b $ separately represent the intrinsic growth rate and compete rate of prey; $ c $ and $ d $ separately represent the death rate and maximal growth rate of predators; $ p(u) $ is the functional response describes the variation of the amount of prey affected by the attacks of predators.
However, it is worth noticing that not only is there competition among prey, but predators also compete each other for the limited resource such as the size of the habitat to live and reproduce [5]. Hence, by introducing predator competition, system (1.1) can be rewritten as
|
$ dudt=au−bu2−vp(u),dvdt=v(−c+dp(u))−hv2, $
|
(1.2) |
where $ h $ is the competition rate of predators. This is the well-known Bazykin's predator-prey model proposed in [6].
The functional response $ p(u) $ is usually classified into four types firstly purposed by the biologist Holling [7,8], for example the Holling Type Ⅰ functional response
|
$ p(u)={muα,u<α,m,u>α, $
|
(1.3) |
where $ m $ is a maximal per capita consumption rate and $ \alpha $ is the half-saturation constant-the prey's number at which the per capita consumption rate is half of its maximum $ m $, and other three Holling Type functional responses, see Table 1. Note that these functional response are all bounded function which is suitable for actual field data and the Holling type Ⅰ functional response (1.3) is continuous but not smooth, which is also called the piecewise-smooth Holling type Ⅰ functional response.
| Holling type | Definition | Generalized form |
| Ⅱ | $ p(u)=\frac{mu}{u+k} $ | |
| Ⅲ | $ p(u)=\frac{mu^2}{u^2+k} $ | $ p(u)=\frac{mu^2}{k_1u^2+k_2u+1}(k_2>-2\sqrt{k_1}) $ |
| Ⅳ | $ p(u)=\frac{mu}{u^2+k} $ | $ p(u)=\frac{mu}{k_1u^2+k_2u+1}(k_2>-2\sqrt{k_1}) $ |
 DownLoad:
CSV
DownLoad:
CSV
Recent researches related to the Bazykin's model with different functional responses obtain some interesting complex dynamics and bifurcations. For example, Bzaykin [9] showed that there is a threshold value $ c_1 $ such that system (1.2) with the functional response $ p(u) = mu $ has the globally asymptotically stable boundary equilibrium $ (\frac{a}{b}, 0) $ if $ c > c_1 $ and the unique globally asymptotically stable positive equilibrium if $ c < c_1 $; many researchers [5,6,9,10,11,12,13,14,15,16,17] including Bazykin et al.[5,6,9,10], Hainzl et al.[11,12] and Lu and Huang[13] investigated system (1.2) with Holling type Ⅱ functional response by the theoretical analysis or numerical methods and got complex dynamics and rich bifurcation phenomenons such as the location and stability of equilibriums, the existence of limit cycles, the degenerate Bogdanov-Takens bifurcation, the Hopf bifurcation, etc.
In this paper, we investigate Bazykin's predator-prey model (1.2) with piecewise smooth Holling type Ⅰ functional response (1.3). Before going into details, we apply the following rescaling transformation
|
$ ˉu=uα,ˉv=mvaα,ˉt=at $
|
and removing the bar notation, then the system (1.2) can be rewrote as the following non-dimensional system
|
$ dudt=u(1−bu)−vp(u)=f(u,v),dvdt=ϵv(p(u)−c−hv)=ϵg(u,v) $
|
(1.4) |
with
|
$ p(u)={u,u<1,1,u>1, $
|
where $ u $ and $ v $ are the non-dimensional variables; $ b = \dfrac{bd}{a} $, $ \epsilon = \dfrac{dm}{a} $, $ h = \dfrac{ha\alpha}{dm^2} $ and $ c = \dfrac{c}{dm} $ are non-dimensional parameters. Furthermore, we assume the growth rate of predators is much smaller than that of prey which means that system (1.4) is a piecewise-smooth slow-fast system with the small parameter $ 0 < \epsilon\ll1 $. Note that our assumption is reasonable because species at different trophic levels have different growth rates, which may vary several orders of magnitude, and the growth time of individuals increases gradually from the bottom of the food chain to the top [18]. Moreover, many observations of interactions between prey and predators such as hares and lynx [19], phytoplankton and zooplankton [20], insects and birds [21], etc. indicate the prey grow much faster than predators.
So far, there are few studies on the slow-fast Bazykin's model and these studies mainly focus on the dynamics of the model (1.2) with smooth Holling Ⅱ functional response [15,16] such as relaxation oscillation cycles, canard phenomenon and so on. Hence, Our main aim in this paper is to study the dynamics of the slow-fast Bazykin's model with a piecewise-smooth functional response (1.4) by using the geometrical singular perturbation theory [22,23,24,25,26,27,28,29] and piecewise-smooth dynamical system theory [30,31,32,33,34,35]. For the various values of parameters, we will show that there are the coexistence of two relaxation oscillation cycles with different stability, an unstable relaxation oscillation cycle surrounded by a stable homoclinic cycle and a heteroclinic cycle enclosing an unstable relaxation oscillation cycle. Furthermore, the system (1.4) undergoes a series of bifurcations such as Saddle-node bifurcation and Discontinuous saddle-node bifurcation of codimension $ 1 $. Moreover, we also give some conditions of the global stability of the unique positive equilibrium. Numerical simulations with the help of the "PPlane8" tool of Matlab [36] are presented to illustrate the theoretical results.
The rest of this paper is organized as follows. In Section $ 2 $, we study the critical manifold and the existence and types of equilibriums of system (1.4). In Section $ 3 $, we show that the dynamics and bifurcations of system (1.4) such as relaxation oscillation cycles, homoclinic cycle, heteroclinic cycle, etc. A brief discussion is given in the last section.
Based on the ecological viewpoint, we are keen on the dynamics of the system (1.4) in the first quadrant $ R^2_{+} = \{(u, v)\mid u\geq0, v\geq0\} $ and the switching boundary $ \Sigma = \{(u, v)\mid u = 1\} $ splits the first quadrant into two regions denoted by $ \Sigma^{(-)} = \{(u, v)\mid 0 < u < 1, v\geq0\} $ and $ \Sigma^{(+)} = \{(u, v)\mid u > 1, v\geq0\} $. The system (1.4) is smooth in $ \Sigma^{(\mp)} $ and determined by the following systems
|
$ dudt=u(1−bu−v)=f(−)(u,v),dudt=ϵv(u−c−hv)=ϵg(−)(u,v),(u,v)∈Σ(−) $
|
and
|
$ dudt=u(1−bu)−v=f(+)(u,v),dudt=ϵv(1−c−hv)=ϵg(+)(u,v),(u,v)∈Σ(+). $
|
Since the vector field is locally Lipschitz, the fundamental existence and uniqueness theory is true for the system (1.4) [31]. Note that the trajectories of the system (1.4) transversally pass through the switching boundary $ \Sigma $. Moreover, in order to guarantee the density of preys can support the growth of predators, we assume throughout the paper that $ 0 < b < \frac{1}{4} $ and $ 0 < c < 1 $. These are also the necessary condition for the existence of relaxation oscillation cycles. Hence, we will study the system (1.4) in the parametric region
| $ D = \left\{\eta = (b, h, c)\mid 0 < b < \dfrac{1}{4}, 0 < c < 1, h > 0\right\}. $ |
Before going into the detail dynamics, we firstly show some basic properties of the system (1.4).
Lemma 2.1. The system (1.4) has the invariant set
| $ \Omega = \left\{(u, v)\mid 0\leq u\leq\dfrac{1}{b}, 0\leq v\leq \dfrac{1-bc}{bh}\right\} $ |
and it also has no limit cycle which is entirely lied in the region $ \Sigma^{(-)} $.
Proof. It is clear that $ u = 0 $ and $ v = 0 $ are two invariant straight lines of system (1.4) and the boundary of set $ \Omega $ is
|
$ ∂Ω=L1∪L2∪L3∪L4,L1={(u,v)∣u=1b,0≤v≤1−bcbh},L2={(u,v)∣0≤u≤1b,v=1−bcbh},L3={(u,v)∣u=0,0≤v≤1−eceh},L4={(u,v)∣0≤u≤1b,v=0}. $
|
For $ (u, v)\in\partial\Omega $, we have
|
$ dudt|(u,v)∈L1=−v<0,dvdt|(u,v)∈L2={ϵ(1−c)(bu−1)bh<0,0<u<1,ϵ(1−1b)<0,0≤u≤1b,dvdt|u=0=−v(c+hv)<0,dudt|v=0=u(1−bu){≥0,0<u≤1b,<0,u>1b, $
|
which means that the vector field of the system (1.4) in the line $ \partial\Omega $ never points outside. Hence, any trajectories of the system (1.4) are confined in the set $ \Omega $ as they enter $ \Omega $ in finite time.
For $ (u, v)\in\Sigma^{(-)} $, we construct the Dulac function $ \varphi(u, v) = \frac{1}{uv} $ and have
|
$ ∂φf∂u+ϵ∂φg∂v=−bv−ϵhu $
|
which implies the system (1.4) has no limit cycles in the region $ \Sigma^{(-)} $ because of the Dulac's criteria.
Hence, if the system (1.4) has a limit cycle, it will either entirely locate in the region $ \Sigma^{(+)} $ or consist of trajectories in the regions $ \Sigma^{(+)} $ and $ \Sigma^{(-)} $ and transversally pass through the switching boundary $ \Sigma $.
Under the time scale transformation $ \tau = \epsilon t $, we can get the equivalent system
|
$ ϵdudτ=u(1−bu)−vp(u),dvdτ=v(p(u)−c−hv). $
|
(2.1) |
The systems (1.4) and (2.1) are individually known as the fast system and the slow system because of their different time scales. By setting $ \epsilon = 0 $ in systems (1.4) and (2.1), we get the degenerate system
|
$ 0=u(1−bu)−vp(u),dvdt=v(p(u)−c−hv) $
|
(2.2) |
and the layer system
|
$ dudt=u(1−bu)−vp(u),dvdt=0. $
|
(2.3) |
Hence, the critical manifold is
|
$ S0={(u,v)∣u(1−bu)−vp(u)=0}=S10∪S20∪S30, $
|
which is composed of the singular points of layer system (2.3) and can be divided into three parts as follows, see Figure 1,
|
$ S10={(u,v)∣u=0,v>0},S20={(u,v)∣0<u<1,v=1−bu≜H1(u)},S30={(u,v)∣1<u<1b,v=u(1−bu)≜H2(u)}. $
|
Note that the sub-manifold $ S^2_0 $ is a normally hyperbolic attracting sub-manifold and the non-normally hyperbolic points $ A(0, 1) $ and $ M(\frac{1}{2b}, \frac{1}{4b}) $ separately split the sub-manifolds $ S^1_0 $ and $ S^3_0 $ into the normally hyperbolic attracting sub-manifolds
|
$ S1a0={(u,v)∣u=0,v>1},S3a0={(u,v)∣12b<u<1b,v=H2(u)} $
|
and normally hyperbolic repelling sub-manifolds
|
$ S1r0={(u,v)∣u=0,0<v<1},S3r0={(u,v)∣1<u<12b,v=H2(u)}. $
|

For $ 0 < \epsilon\ll1 $, the Fenichel theory [22,23] indicates the normally hyperbolic attracting sub-manifolds $ S^2_0 $, $ S^{1a}_0 $ and $ S^{3a}_0 $ can be perturbed to the attracting slow manifolds $ S^2_{\epsilon} $, $ S^{1a}_{\epsilon} $ and $ S^{3a}_{\epsilon} $ and the normally hyperbolic repelling sub-manifolds $ S^{1r}_0 $ and $ S^{3r}_0 $ can be perturbed to the repelling slow manifolds $ S^{1r}_{\epsilon} $ and $ S^{3r}_{\epsilon} $. Hence, the trajectory starting near $ S^{1a}_0 $ is attracted to the $ v $-axis, then it moves down with $ O(\epsilon) $ speed. It is clear that the trajectory passes the non-hyperbolic point $ A(0, 1) $ and leaves the $ O(\epsilon) $ neighborhood of $ S^{1r}_0 $ at the point $ (0, p_\epsilon(v)) $ satisfying $ \lim\limits_{\epsilon\to0}p_{\epsilon}(v) = p_0(v) $. The function $ p_0(v) $ is called the entry-exit function [28,29] and satisfies the following lemma.
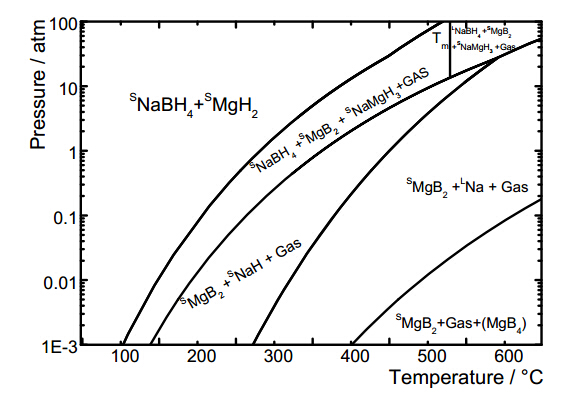
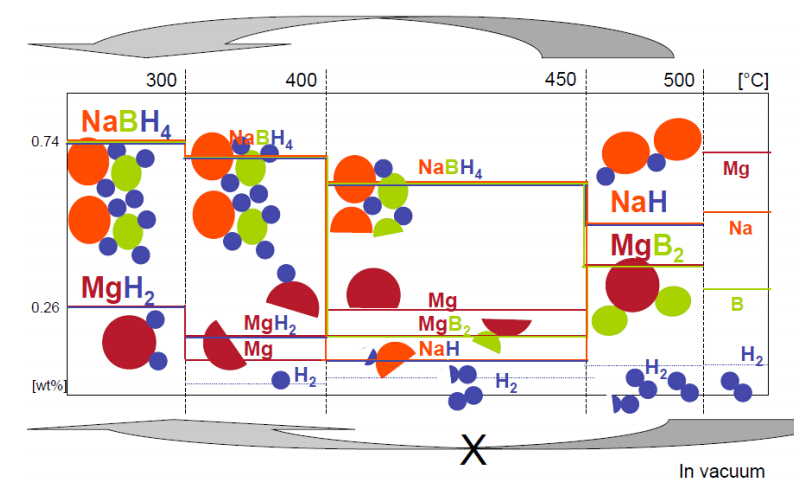
Lemma 2.2. For system (1.4) and $ v_0\in(1, +\infty) $, there is a unique $ p_0(v_0)\in (0, 1) $ satisfying
|
$ ∫p0(v0)v0s−1s(hs+c)ds=0. $
|
(2.4) |
Proof. Let
|
$ I(˜v)=∫˜vv0s−1s(hs+c)ds=(1h+1c)lnh˜v+chv0+c−1cln˜vv0, $
|
(2.5) |
it is easy to verify that $ I(1) < 0 $ and $ \lim\limits_{\tilde{v}\to0}I(\tilde{v}) = +\infty $. Since
|
$ I′(˜v)=˜v−1˜v(h˜v+c)<0,˜v∈(0,1), $
|
there is a unique $ \tilde{v}^*\in(0, 1) $ such that $ I(v^*) = 0 $ which implies $ p_0(v_0) = v^* $.
Note that the above proof indicates the entry-exit function $ p_0(v_0) $ is monotone decreasing function in $ (1, +\infty) $.
In this subsection, we mainly study the existence and stability of equilibriums of system (1.4). We can get the equilibriums by a straight calculation of the following equations
|
$ f(−)(u,v)=0,g(−)(u,v)=0,0<u<1,f(+)(u,v)=0,g(+)(u,v)=0,u>1 $
|
(2.6) |
and the dynamics of system (1.4) near these equilibriums are determined by the Jacobian matrix of system (1.4) at these equilibriums, which is given by
|
$ J(−)=(1−2bu∗−v∗−u∗ϵu∗ϵ(u∗−c−2hu∗)),(u∗,v∗)∈Σ(−) $
|
and
|
$ J(+)=(1−2bu∗−10ϵ(1−c−2hu∗)),(u∗,v∗)∈Σ(+) $
|
here $ (u^*, v^*) $ is the coordinate of these equilibriums. Now, set
| $ h_1 = 4b(1-c)\quad \mbox{and}\quad h_2 = \frac{1-c}{1-b}, $ |
we give the following lemmas about the existence and stability of equilibriums.
Lemma 2.3. For system (1.4), the following conclusions hold.
1) System (1.4) always has two trivial equilibriums $ O(0, 0) $ and $ B(\frac{1}{b}, 0) $ which are both saddle.
2) If $ h < h_1 $ or $ h > h_2 $, then system (1.4) has a stable equilibrium $ E_{1}(u_1, v_1) $ which are separately located in $ S_0^2 $ and $ S_0^{3a} $, see Figure 1(a), (e). More precisely, the equilibrium $ E_{1}(u_1, v_1) $ is a globally stable node when $ h > h_2 $, see Figure 2(a).

Proof. The number and locations of equilibriums of system (1.4) can be obtained by the straight calculation of Eq (2.6). Next, we determine the types of equilibriums $ O(0, 0) $, $ B(\frac{1}{b}, 0) $ and $ E_{1}(u_1, v_1) $. For equilibrium $ O(0, 0) $, the eigenvalues of the Jacobian matrix $ J^{(-)} $ are $ \lambda_1 = 1 $ and $ \lambda_2 = -\epsilon c < 0 $ which implies the equilibrium $ O(0, 0) $ is a saddle point. Similarly, the eigenvalues of the Jacobian matrix $ J^{(+)} $ at $ B(\frac{1}{b}, 0) $ are $ \lambda_1 = -1 $ and $ \lambda_2 = \epsilon(1-c) > 0 $ which indicates the equilibrium $ B(\frac{1}{b}, 0) $ is a saddle point. For equilibrium $ E_{1}(u_1, v_1)\in S_0^{3a} $, the similar calculation gives the eigenvalues of the Jacobian matrix $ J^{(+)} $ as $ \lambda_1 = 1-2bu_1 < 0 $ and $ \lambda_2 = \epsilon (c-1) < 0 $, which implies $ E_{1}(u_1, v_1)\in S_0^{3a} $ is a stable node. For equilibrium $ E_{1}(u_1, v_1)\in S_0^{2} $, we calculate the determinant and trace of Jacobian matrix $ J^{(-)} $ as
|
$ Tr(J(−)(E1))=−bu1−ϵ(u1−c)<0,Det(J(−)(E1))=ϵ(h+c)(h+c+hb−hcb2)(1+hb)2>0, $
|
which implies $ E_{1}(u_1, v_1)\in S_0^{2} $ is stable.
Next, we will prove the global stability of equilibrium $ E_{1} $ when $ h > h_2 $. We construct the trapping region
|
$ Ω1={(u,v)∣12b≤u≤1b,0≤v≤14b} $
|
(2.7) |
and assert that the vector field of system (1.4) point inside at the boundary $ \partial\Omega_1 $. So the trajectories cannot leave after entering the region $ \Omega_1 $. Furthermore, we construct the same Dulac function in Lemma 2.1 as $ \varphi(u, v) = \frac{1}{uv} $ and have
|
$ ∂φf(+)∂u+ϵ∂φg(+)∂v=v−bu2u2v−ϵ1−cuv2<0,(u,v)∈Ω1. $
|
Hence, based on the Dulac's criteria, the system (1.4) has no limit cycles in the region $ \Omega_1 $, which indicate the equilibrium $ E_1 $ is globally stable in $ \Omega_1 $. Moreover, the trajectories starting in the region $ \Sigma\backslash\Omega_1 $ enter into the region $ \Omega $ in finite time because of the Fenichel theory and Lemma 2.2. Then we can assert that system (1.4) has a globally stable node $ E_1 $ when $ h > h_2 $.
Lemma 2.4. If $ h = h_1 $ or $ h = h_2 $, then system (1.4) has two positive equilibriums. More precisely,
1) If $ h = h_1 $, then system (1.4) has a stable equilibrium $ E_{1}(u_1, v_1) $ located in $ S_0^2 $ and an attracting saddle-node $ E_M(\frac{1}{2b}, \frac{1}{4b}) $ which is the vertex point in $ S_0^3 $, see Figure 1(b).
2) If $ h = h_2 $, then system (1.4) has a stable equilibrium $ E_{1}(u_1, v_1) $ located in $ S_0^2 $ and a boundary equilibrium $ E_B(1, 1-b) $ located in the switching boundary $ \Sigma $, see Figures 1(d) and 2(b).
Proof. The existence and location of two positive admissible equilibriums follows from the straight calculation of Eq (2.6). By some simple calculations, we get
|
$ Tr(J(−)(E1))=−bu1−ϵ(u1−c)<0,Det(J(−)(E1))=ϵ(h+c)(h+c+hb−hcb2)(1+hb)2>0, $
|
and the eigenvalues of equilibrium $ E_M(\frac{1}{2b}, \frac{1}{4b}) $ are $ \lambda_1 = 0 $ and $ \lambda_2 = -\epsilon(1-c) < 0 $. Hence, the equilibrium $ E_1 $ is stable and the equilibrium $ E_M $ is an attracting saddle-node which can be proven based on the conditions in [37].
Lemma 2.5. If $ h_1 < h < h_2 $, then system (1.4) has three positive equilibriums $ E_1(u_1, v_1) $, $ E_2(u_2, v_2) $ and $ E_3(u_3, v_3) $. More precisely, $ E_1(u_1, v_1) $ is a stable equilibrium in $ S_0^2 $; $ E_2(u_2, v_2) $ is a saddle in $ S_0^{3r} $ and $ E_3(u_3, v_3) $ is a stable node in $ S_0^{3a} $, see Figure 1(c).
The proof of Lemma 2.5 is similar to that given in Lemmas 2.3 and 2.4 and so is omitted.
In this section, we are keen on various possible dynamics of the slow-fast system (1.4) including relaxation oscillation, saddle-node bifurcation, boundary equilibrium bifurcation and so on.
According to Lemmas 2.3–2.5, we know that
|
$ SN={(b,c,h)∣h=h1=4b(1−c)} $
|
is a saddle-node bifurcation surface. When parameters change from one side of the surface $ SN $ to another one, the number of positive equilibriums of system (1.4) in $ \Sigma^{(+)} $ changes from zero to two. So there is a critical competition rate $ h_1 $ such that the two species coexist in the form of a positive equilibrium for suitable choices of initial values when $ h = h_1 $
In what follows, we show that system (1.4) has homoclinic orbit, heteroclinic orbit and relaxation oscillation cycles in both sides of saddle-node bifurcation surface $ SN $.
First, we investigate the relaxation oscillation cycles of system (1.4) when $ h < h_1 $. Now, we denote the function $ \hat{I}(\tilde{v}) $ as the function (2.5) with $ v_0 = \frac{1}{4e} $ and state the main theorem as follows
Theorem 3.1. When $ 0 < b < \frac{1}{4} $, $ 0 < c < 1 $ and $ 0 < h < h_1 $, system (1.4) has a positive equilibrium $ E_1(u_1, v_1) $ which is stable. Moreover, if
|
$ ˆI(1−b)=1hln4b(1−b)h+4bch+4bc+1cln4b(1−b)h+4bc4b(1−b)h+16b2(1−b)c<0, $
|
then system (1.4) has a hyperbolically stable relaxation oscillation cycle $ \Gamma^{1}_{\epsilon} $ and a hyperbolically unstable relaxation oscillation cycle $ \gamma_{\epsilon} $ which separately converges to
| $ \Gamma^{1}_0 = \overset{\LARGE\frown}{MK_1}\cup\overset{\LARGE\frown}{K_1Q_1}\cup \overset{\LARGE\frown}{Q_1D_1}\cup\overset{\LARGE\frown}{D_1M} $ |
and
| $ \gamma_0 = \overset{\LARGE\frown}{D_2K_2}\cup\overset{\LARGE\frown}{K_2Q_2}\cup \overset{\LARGE\frown}{Q_2B}\cup \overset{\LARGE\frown}{BD_2} $ |
in the Hausdorff distance as $ \epsilon\to0 $, see Figures 3(a) and 4(a).


Proof. Our first goal is to prove the existence of the stable relaxation oscillation cycle $ \Gamma^{1}_{\epsilon} $. To begin with, it is easy to see that the vertex point $ M(\frac{1}{2b}, \frac{1}{4b}) $ is a general fold and there exists $ \hat{v}^*\in(0, 1-b) $ such that $ p_0(\frac{1}{4b}) = \hat{v}^* $ based on $ \hat{I}(1-b) < 0 $ and the properties of function $ \hat{I}(\tilde{v}) $. Hence, we construct the singular slow-fast cycle $ \Gamma^{1}_0 $, see Figure 3(a), as
| $ \Gamma^{1}_0 = \overset{\LARGE\frown}{MK_1}\cup\overset{\LARGE\frown}{K_1Q_1}\cup \overset{\LARGE\frown}{Q_1D_1}\cup\overset{\LARGE\frown}{D_1M}, $ |
where $ M(\frac{1}{2b}, \frac{1}{4b}) $, $ K_{1}(0, \frac{1}{4b}) $, $ Q_1(0, \hat{v}^*) $, $ D_1(\hat{u}^*, \hat{v}^*) $ and $ \hat{u}^* $ is the larger root of equation $ H_2(u) = \hat{v}^* $.
Set
|
$ Δ0={(1,v)∣v∈(14b−δ,14b+δ)}andΔ1={(1,v)∣v∈(v∗−δ,v∗+δ)} $
|
which separately are vertical region of $ \overset{\LARGE\frown}{MK_1} $ and $ \overset{\LARGE\frown}{Q_1D_1} $ and $ \delta $ is a small positive parameter. We construct the Poincaré map $ \Pi $ as
|
$ Π=Π1∘Π0:Δ0→Δ0 $
|
which consists of two maps $ \Pi_0:\Delta_0\to\Delta_1 $ and $ \Pi_1:\Delta_1\to\Delta_0 $. For the trajectory starting in $ \Delta_0 $, it will arrive at the neighborhood of critical manifold $ S^{1a}_{0} $ and move downwards until reach the neighborhood of $ Q_1 $. The trajectory will move along the layers of system (2.3) and pass through the region $ \Delta_1 $ before reaching near the critical manifold $ S^{3a}_{0} $ because system (1.4) is continuous on the switching boundary $ \Sigma $. Then the trajectory will move along $ S^{3a}_{0} $ and jump into $ \Delta_0 $ in the neighborhood of fold point $ M $. Hence, the relaxation oscillation cycle $ \Gamma_{\epsilon}^{1} $ is equivalent to the fixed point of Poincaré map $ \Pi $ which is a contraction map with exponential contraction rate $ O(\mathrm{e}^{-\frac{1}{\epsilon}}) $ by Lemma 2.2 and Theorem 2.1 in [26]. According to the Contraction Mapping Theorem, there is an unique fixed point of $ \Pi $ corresponding to the relaxation oscillation cycle $ \Gamma_{\epsilon}^{1} $. Furthermore, it is clear that $ \Gamma_{\epsilon}^{1} $ is a hyperbolically stable limit cycle and converges to the singular slow-fast cycle $ \Gamma_{0}^{1} $ as $ \epsilon\to0 $.
Next we prove the existence of the unstable relaxation oscillation cycle $ \gamma_{\epsilon} $. Since $ E_{1}(u_1, v_1) $ is stable and the relaxation oscillation cycle $ \Gamma_{\epsilon}^{1} $ is hyperbolically stable, we can conclude that there exists at least an unstable limit cycle inside $ \Gamma_{\epsilon} $ based on Poincaré-Bendixson Theorem. According to the Geometric Singular Perturbation Theory [23], the limit cycles of slow-fast system (1.4) are usually perturbed by singular slow-fast cycles. Clearly, system (1.4) has an unique singular slow-fast cycle $ \gamma_0 $ inside the relaxation oscillation cycle $ \Gamma_{\epsilon}^1 $ for $ \epsilon\to0 $, see Figure 3(a), which are constructed as
| $ \gamma_0 = \overset{\LARGE\frown}{D_2K_2}\cup\overset{\LARGE\frown}{K_2Q_2}\cup \overset{\LARGE\frown}{Q_2B}\cup \overset{\LARGE\frown}{BD_2}, $ |
with $ Q_2(0, 1-b) $, $ B(1, 1-b) $, $ D_2(\bar{u}^*, \bar{v}^*) $ and $ K_2(0, \bar{v}^*) $. Note that $ p_0(\bar{v}^*) = 1-b $ and $ \bar{u}^* $ is the smaller root of equation $ H_2(u) = \bar{v}^* $. Hence, if the limit cycles exist, they must be in the neighborhood of $ \gamma_0 $. By the Corollary 4.3 in [38], the sign of the following integral
|
$ ∮γϵ(∂f∂u+ϵ∂g∂v)dt=∫D2A2(1−2bu)dt+O(ϵ)>0. $
|
determines the limit cycle is hyperbolically unstable if it exists. Thus, we can claim that there is an unique relaxation oscillation cycle $ \gamma_{\epsilon} $ near $ \gamma_0 $ because two adjacent limit cycles don't have the same stabilities.
Combined with the above analysis and applying numerical simulations by the "PPlane8" tool in Matlab, we give the phase portrait of system (1.4) when $ b = 0.2 $, $ c = 0.5 $ and $ h = 0.3 $, see Figure 4(a). Note that system (1.4) has a hyperbolically unstable relaxation oscillation cycle $ \gamma_{\epsilon} $ surrounded by a hyperbolically stable relaxation oscillation cycle $ \Gamma_{\epsilon}^{1} $.
Second, we investigate the existence of a homoclinic cycle of system (1.4) with $ h = h_1 $ and have the following theorem.
Theorem 3.2. When $ 0 < b < \frac{1}{4} $, $ 0 < c < 1 $ and $ h = h_1 $, system (1.4) has a stable equilibrium $ E_1(u_1, v_1) $ and a attracting saddle-node $ E_M(\frac{1}{2b}, \frac{1}{4b}) $. Moreover, if $ \hat{I}(1-b) < 0 $, then system (1.4) has a stable homoclinic cycles $ \Gamma^{2}_{\epsilon} $ and a unstable relaxation oscillation cycle $ \gamma_{\epsilon} $ which separately converge to
| $ \Gamma^{2}_0 = \overset{\LARGE\frown}{E_MK_1}\cup\overset{\LARGE\frown}{K_1Q_1}\cup \overset{\LARGE\frown}{Q_1D_1}\cup\overset{\LARGE\frown}{D_1E_M} $ |
and
| $ \gamma_0 = \overset{\LARGE\frown}{D_2K_2}\cup\overset{\LARGE\frown}{K_2Q_2}\cup \overset{\LARGE\frown}{Q_2B}\cup \overset{\LARGE\frown}{BD_2} $ |
in Hausdorff distance as $ \epsilon\to0 $, see Figures 3(b) and 4(b).
Proof. For $ \epsilon = 0 $, it is clear that there is a singular orbit $ \Gamma^2_0 $ in saddle-node $ E_M $, which can be constructed by the same way of $ \Gamma^1_0 $ in Theorem 3.1, see Figure 3(b). Furthermore, the layer of system (2.3) at $ E_M $ will be perturbed to one dimensional unstable manifold $ W^{u}_{\epsilon}(E_M) $ of system (1.4) at $ E_M $ if $ 0 < \epsilon\ll1 $. By Lemma 2.2, the unstable manifold $ W^{u}_{\epsilon}(E_M) $ will be attracted to the neighborhood of $ S_0^{1a} $ and move down until it reach near $ Q_1 $. Then $ W^{u}_{\epsilon}(E_M) $ move quickly from the neighborhood of $ S_0^{1r} $ to the neighborhood of $ S_0^{3a} $. Next, we show that the unstable manifold $ W^{u}_{\epsilon}(E_M) $ tends to saddle-node $ E_M $. We construct the trapping region $ \Omega_1 $ which is same to (2.7) in Lemma 2.4 and the orbit cannot leave if it enters the region $ \Omega_1 $. Since the unstable manifold $ W^{u}_{\epsilon}(E_M) $ enter this region $ \Omega_1 $ and the orbits is monotone increasing in $ v $, the unstable manifold $ W^{u}_{\epsilon}(E_M) $ tends to saddle-node $ E_{M} $ along its stable manifold $ W^{s}_{\epsilon}(E_M) $ which is perturbed by $ W^{s}(S^{3a}_0) $ based on the Fenichel theorem. Hence, when $ 0 < \epsilon\ll1 $, there is a homoclinic cycle $ \Gamma^{2}_{\epsilon} $ which converges to singular orbit $ \Gamma^2_0 $ as $ \epsilon\to0 $.
Based on the Theorem 5 in [37], the stability of the homoclinic cycle $ \Gamma_{\epsilon}^2 $ is determined by the sign of the following integral
|
$ ∮Γ2ϵ(∂f∂u+ϵ∂g∂v)dt=∫EMD1(1−2bu)dt<0. $
|
Hence, the homoclinic cycle $ \Gamma_{\epsilon}^2 $ is stable.
The proof of existence and stability of the relaxation oscillation cycle $ \gamma_{\epsilon} $ is omitted because it is similar to that in Theorem 3.1.
According to the analysis of Theorem 3.2 and using numerical simulation by the "PPlane8" tool in Matlab, the phase portrait of system (1.4) with $ b = 0.2 $, $ c = 0.5 $ and $ h = 0.4 $ is presented in Figure 4(b). Note that system (1.4) has a stable homoclinic cycle $ \Gamma_{\epsilon}^2 $ enclosing a hyperbolically unstable relaxation oscillation cycle $ \gamma_{\epsilon} $.
Third, we study the existence of a heterocilinic cycle of system (1.4) when $ h > h_2 $. Similarly, we denote $ \tilde{I}(\tilde{u}) $ as the function (2.5) with $ v_0 = \frac{1-c}{h} $. By applying the similar analysis methods in Theorem 3.2 and Lemma 1 in [39], we can derive the following theorem.
Theorem 3.3. When $ 0 < b < \frac{1}{4} $, $ 0 < c < 1 $ and $ h_1 < h < h_2 $, system (1.4) has a saddle point $ E_2(u_2, v_2) $ and two stable equilibirums $ E_1(u_1, v_1) $ and $ E_3(u_3, v_3) $. Moreover, if
|
$ ˜I(1−b)=1hln[h(1−b)+c]+1cln(1−c)[h(1−b)+c](1−e)h<0, $
|
(3.1) |
then system (1.4) has a heteroclinic cycle $ \Gamma^{3}_{\epsilon} $ and a unstable relaxation oscillation cycle $ \gamma_{\epsilon} $ which separately converge to
| $ \Gamma^{3}_0 = \overset{\LARGE\frown}{E_2K_3}\cup\overset{\LARGE\frown}{K_3Q_3}\cup \overset{\LARGE\frown}{Q_3D_3}\cup\overset{\LARGE\frown}{D_3E_3}\cup\overset{\LARGE\frown}{E_2E_3} $ |
and
| $ \gamma_0 = \overset{\LARGE\frown}{D_2K_2}\cup\overset{\LARGE\frown}{K_2Q_2}\cup \overset{\LARGE\frown}{Q_2B}\cup \overset{\LARGE\frown}{BD_2} $ |
in Hausdorff distance as $ \epsilon\to0 $, see Figures 3(c) and 4(c).
According to the above analysis and some numerical simulations by the "PPlane8" tool in Matlab, we give the phase portrait of system (1.4) with $ b = 0.2 $, $ c = 0.5 $ and $ h = 0.45 $, see Figure 4(c). Note that the two unstable manifolds of saddle $ E_2(u_2, v_2) $ tend to the stable node $ E_{3}(u_3, v_3) $ and form the heteroclinic cycle. From Figure 4, we know that the number of equilibriums of system (1.4) changes from one to three when parameters pass through the saddle-node bifurcation surface. Furthermore, under some conditions, system (1.4) always has a small relaxation oscillation cycle $ \gamma_{\epsilon} $ which is separately surrounded by a big relaxation oscillation cycle, homoclinic cycle and heteroclinic cycle for different values of parameter $ h $ in the neighborhood of $ h_1 $.
In this subsection, we will discuss the boundary equilibrium bifurcation of system (1.4). From Lemma 2.4, we know that the boundary equilibrium $ E_B(1, 1-b) $ is an admissible equilibrium for both systems in $ \Sigma^{(-)} $ and $ \Sigma^{(+)} $, which is a mark of boundary equilibrium bifurcation of codimension $ 1 $. Hence, incorporating Lemmas 2.3 and 2.5, we present the discontinuous saddle-node bifurcation surface as follows
|
$ DSN={(b,c,h)∣h=h2=1−c1−b}. $
|
When the parameters vary from one side of the surface to another, system (1.4) has two positive equilibriums $ E_1(u_1, v_1) $ and $ E_2(u_2, v_2) $ which are separately located in regions $ \Sigma^{(-)} $ and $ \Sigma^{(+)} $. Then the discontinuous saddle-node bifurcation gets two positive equilibriums.
In this paper, we consider the slow-fast Bazykin's predator-prey model with piecewise smooth Holling Ⅰ functional response. Our qualitative analysis on system (1.4) reveals that system has complex dynamics and bifurcations and the competition rate $ h $ plays a critical role which affects not only the number and type of equilibriums but also the type of bifurcations in this model. When the values of parameters vary, system (1.4) undergoes the saddle-node bifurcation and the discontinuous saddle-node bifurcation. For different values of parameters, it is clear that system (1.4) has a hyperbolically unstable relaxation oscillation cycle which is respectively surrounded by a hyperbolically stable relaxation oscillation cycle, a homoclinic cycle and a heteroclinic cycle. These complex dynamics cannot occur in the system (1.4) with single time scale and smooth Holling type Ⅰ functional response. In fact, the system (1.4) with $ \epsilon > 1 $ and smooth Holling type Ⅰ functional response [9] has at least one positive equilibrium which is globally stable if $ c < c_1 $, here $ c_1 $ is a threshold value. Hence, compared with our result in this paper, it is clear that the different time scale and piecewise-smooth functional response in system (1.4) can introduce more complex dynamical behaviour.
These complex dynamical phenomenons of system (1.4) show that the complexity of dynamical behaviors of the Bazykin's model. For the biological interpretations of these complex dynamical phenomenons, we interpret biological meaning of the big relaxation oscillation cycle in Theorem 3.1 as an example. By Figure 4(a), it is clear that the big relaxation oscillation cycle is hyperbolically stable, which indicates that that the prey and predator will coexist in system (1.4). The slow manifolds represent the density of prey and predator vary slowly under the influence of interactions or low prey density, and the fast movements implies the fast changes of prey density. The existence of the limit cycle suggests that the predator density increases slowly with sufficient food, and once the predator density exceeds the vertex point, the prey density decreases rapidly but not extinct due to large consumption. In the absence of food, the predator density also slowly declines until the prey density increases again quickly enough to support predator's reproduction, where the cycle begins again. Therefore, the relaxation oscillation cycle may show sudden outbreaks of pests in biology many years after extinction.
It is worth noticing that Kooij and Zegeling [40] extend the piecewise-smooth Holling type Ⅰ functional response, which replace the linear function $ p(x) = x $, $ 0 < x < 1 $ by cubic function $ p(x) = x(1+(x-1)(a_0+a_1x)) $, $ 0 < x < 1 $. Note that the new functional response is not only a non-monotonic function but also contains different cases for different values of $ a_1 $ and $ a_2 $. Furthermore, there may be more complex dynamics and bifurcations for system (1.4) with this new function response. We leave these for future consideration.
The authors declare they have not used Artificial Intelligence (AI) tools in the creation of this article.
The first author is supported by the Fundamental Research Funds for the Central Universities (No.2232023D-22, No.2232022G-13) and The third author was supported by the National Natural Science Foundation of China (12271088) and the Natural Science Foundation of Shanghai (21ZR1401000).
The authors declare there is no conflict of interest.
| [1] |
Crabtree GW, Dresselhaus MS, Buchanan MV (2004) The Hydrogen Economy. Phys Today 57: 39-44. doi: 10.1063/1.1878333

|
| [2] | Zuttel A, Borgschulte A, Schlapbach L (2008) Hydrogen as a Future Energy Carrier. Winheim: Wiley-VCH Verlag GmbH & Co. |
| [3] | Riis T, Hagen EF, Vie PJS, et al. (2006) Hydrogen Production R&D. Paris: IEA. |
| [4] |
Turner JA (2004) Sustainable Hydrogen Production. Science 305: 972-974. doi: 10.1126/science.1103197
|
| [5] |
Merle G, Wessling M, Nijmeijer K (2011) Anion exchange membranes for alkaline fuel cells: A review. J Membrane Sci 377: 1-35. doi: 10.1016/j.memsci.2011.04.043
|
| [6] |
Giddey S, Badwal SPS, Kulkarni A, et al. (2012) A comprehensive review of direct carbon fuel cell technology. Prog Energy Combust 38: 360-399. doi: 10.1016/j.pecs.2012.01.003
|
| [7] |
Antolini E, Perez J (2011) The use of rare earth-based materials in low-temperature fuel cells. Int J Hydrogen Energy 36: 15752-15765. doi: 10.1016/j.ijhydene.2011.08.104
|
| [8] |
Stambouli AB, Traversa E (2002) Solid oxide fuel cells (SOFCs): a review of an environmentally clean and efficient source of energy. Renew Sust Energy Rev 6: 433-455. doi: 10.1016/S1364-0321(02)00014-X
|
| [9] | Riis T, Sandrock G, Ulleberg O, et al. (2006) Hydrogen Storage R&D. Paris: IEA. |
| [10] |
Elam CC, Padró CEG, Sandrock G, et al. (2003) Realizing the hydrogen future: the International Energy Agency's efforts to advance hydrogen energy technologies. Int J Hydrogen Energy 28: 601-607. doi: 10.1016/S0360-3199(02)00147-7
|
| [11] | MHCoE For a description of the Metal Hydride Center of Excellence. Available from: http://www.sandia.gov/MHCoE. |
| [12] | CHCoE For a description of the Chemical Hydride Center of Excellence. Available from: http://www.hydrogen.energy.gov/annual_progress10_storage.html. |
| [13] | HSCoE For a description of the Hydrogen Sorption Center of Excellence. Available from: http://www.nrel.gov/basic_sciences/carbon_based_hydrogen_center.cfm#hsce. |
| [14] | Klebanoff L (2013) Hydrogen Storage Technology: Materials and Applications. United States of America: CRC press. |
| [15] | US-DOE (2010) Hydrogen and Fuel Cells: Current Technology of Hydrogen Storage. Available from: http://www1.eere.energy.gov/hydrogenandfuelcells/storage/current_technology.html. |
| [16] |
Felderhoff M, Weidenthaler C, von Helmolt R, et al. (2007) Hydrogen storage: the remaining scientific and technological challenges. Phys Chem Chem Phys 9: 2643-2653. doi: 10.1039/b701563c
|
| [17] |
Graetz J (2009) New approaches to hydrogen storage. Chem Soc Rev 38: 73-82. doi: 10.1039/B718842K
|
| [18] | van den Berg AWC, Arean CO (2008) Materials for hydrogen storage: current research trends and perspectives. Chem Commun 14: 668-681. |
| [19] | Klebanoff LE, Keller JO (2013) 5 Years of hydrogen storage research in the U.S. DOE Metal Hydride Center of Excellence (MHCoE). Int J Hydrogen Energ 38: 4533-4576. |
| [20] | Lu Z-H, Xu Q (2012) Recent Progress in Boron and Nitrogen based Chemical Hydrogen Storage. Functional Materials Letters 05. |
| [21] |
Michel KJ, Ozoliņš V (2013) Recent advances in the theory of hydrogen storage in complex metal hydrides. MRS Bulletin 38: 462-472. doi: 10.1557/mrs.2013.130
|
| [22] | Varin RA, Czujiko T, Wronski ZS (2009) Nanomaterials for solid state hydrogen storage. Cleveland: Springer. |
| [23] |
Grochala W, Edwards PP (2004) Thermal Decomposition of the Non-Interstitial Hydrides for the Storage and Production of Hydrogen. Chem Rev 104: 1283-1316. doi: 10.1021/cr030691s
|
| [24] |
Eremets MI, Trojan IA, Medvedev SA, et al. (2008) Superconductivity in Hydrogen Dominant Materials: Silane. Science 319: 1506-1509. doi: 10.1126/science.1153282
|
| [25] |
Scheler T, Degtyareva O, Marqués M, et al. (2011) Synthesis and properties of platinum hydride. Phys Rev B 83: 214106. doi: 10.1103/PhysRevB.83.214106
|
| [26] | Gao G, Wang H, Zhu L, et al. (2011) Pressure-Induced Formation of Noble Metal Hydrides. J Phys Chem C 116: 1995-2000. |
| [27] |
Driessen A, Sanger P, Hemmes H, et al. (1990) Metal hydride formation at pressures up to 1 Mbar. J Physics: Condensed Matter 2: 9797. doi: 10.1088/0953-8984/2/49/007
|
| [28] | Sandrock G (1999) A panoramic overview of hydrogen storage alloys from a gas reaction point of view. J Alloys Compounds 293-295: 877-888. |
| [29] | Bogdanovi B, Schwickardi M (1997) Ti-doped alkali metal aluminium hydrides as potential novel reversible hydrogen storage materials. J Alloy Compd 253-254: 1-9. |
| [30] |
Bogdanović B, Brand RA, Marjanović A, et al. (2000) Metal-doped sodium aluminium hydrides as potential new hydrogen storage materials. J Alloy Compd 302: 36-58. doi: 10.1016/S0925-8388(99)00663-5
|
| [31] |
Eberle U, Arnold G, von Helmolt R (2006) Hydrogen storage in metal-hydrogen systems and their derivatives. J Power Sources 154: 456-460. doi: 10.1016/j.jpowsour.2005.10.050
|
| [32] |
Sandrock G, Gross K, Thomas G (2002) Effect of Ti-catalyst content on the reversible hydrogen storage properties of the sodium alanates. J Alloy Compd 339: 299-308. doi: 10.1016/S0925-8388(01)02014-X
|
| [33] |
Zaluska A, Zaluski L, Ström-Olsen JO (2000) Sodium alanates for reversible hydrogen storage. J Allos Compd 298: 125-134. doi: 10.1016/S0925-8388(99)00666-0
|
| [34] | Gross KJ, Sandrock G, Thomas GJ (2002) Dynamic in situ X-ray diffraction of catalyzed alanates. J Alloy Compd 330-332: 691-695. |
| [35] | Bellosta von Colbe JM, Felderhoff M, Bogdanovic B, et al. (2005) One-step direct synthesis of a Ti-doped sodium alanate hydrogen storage material. Chem Commun 4732-4734. |
| [36] |
Li L, Xu C, Chen C, et al. (2013) Sodium alanate system for efficient hydrogen storage. Int J Hydrogen Energy 38: 8798-8812. doi: 10.1016/j.ijhydene.2013.04.109
|
| [37] | NIST. Availabe from: http://webbook.nist.gov ed. |
| [38] | Zaluska A, Zaluski L, Srom-Olsen JO, et al. (1999) Method for inducing hydrogen desorption from a metal hydride. In: 5882623, Patent. United States of America. |
| [39] |
Zaluska A, Zaluski L, Strm-Olsen JO (1999) Nanocrystalline magnesium for hydrogen storage. J Alloy Compd 288: 217-225. doi: 10.1016/S0925-8388(99)00073-0
|
| [40] |
Varin RA, Czujko T, Wronski ZS, et al. (2009) Nanomaterials for hydrogen storage produced by ball milling. Can Metall Quart 48: 11-26. doi: 10.1179/cmq.2009.48.1.11
|
| [41] |
Fichtner M (2009) Properties of nanoscale metal hydrides. Nanotechnology 20: 204009. doi: 10.1088/0957-4484/20/20/204009
|
| [42] |
Bérubé V, Radtke G, Dresselhaus M, et al. (2007) Size effects on the hydrogen storage properties of nanostructured metal hydrides: A review. Int J Energy Res 31: 637-663. doi: 10.1002/er.1284
|
| [43] |
Chen PX, Z.; Luo, J.; Lin, J.; Tan, K. L. (2002) Interaction of hydrogen with metal nitrides and imides. Nature 420: 302-304. doi: 10.1038/nature01210
|
| [44] |
Hu YH, Ruckenstein E (2003) Ultrafast Reaction between LiH and NH3 during H2 Storage in Li3N. J Phys Chem A 107: 9737-9739. doi: 10.1021/jp036257b
|
| [45] |
Ichikawa T, Hanada N, Isobe S, et al. (2004) Mechanism of Novel Reaction from LiNH2 and LiH to Li2NH and H2 as a Promising Hydrogen Storage System. J Phys Chem B 108: 7887-7892. doi: 10.1021/jp049968y
|
| [46] | Lohstroh W, Fichtner M (2007) Reaction steps in the Li-Mg-N-H hydrogen storage system. J Alloy Compd 446-447: 332-335. |
| [47] |
Hu YH, Ruckenstein E (2004) Highly Effective Li2O/Li3N with Ultrafast Kinetics for H2 Storage. Ind Eng Chem Res 43: 2464-2467. doi: 10.1021/ie049947q
|
| [48] |
Zuttel A, Wenger P, Rentsch S, et al. (2003) LiBH4 a new hydrogen storage material. J Power Sources 118: 1-7. doi: 10.1016/S0378-7753(03)00054-5
|
| [49] | Mosegaard L, Moller B, Jorgensen J-E, et al. (2008) Reactivity of LiBH4: In Situ Synchrotron Radiation Powder X-ray Diffraction Study. J Phys Chem C 112: 1299-1303. |
| [50] |
Yu XB, Grant DM, Walker GS (2009) Dehydrogenation of LiBH4 Destabilized with Various Oxides. J Phys Chem C 113: 17945-17949. doi: 10.1021/jp906519p
|
| [51] |
Maekawa H, Matsuo M, Takamura H, et al. (2009) Halide-Stabilized LiBH4, a Room-Temperature Lithium Fast-Ion Conductor. J Am Chem Soc 131: 894-895. doi: 10.1021/ja807392k
|
| [52] |
Luo C, Wang H, Sun T, et al. (2012) Enhanced dehydrogenation properties of LiBH4 compositing with hydrogenated magnesium-rare earth compounds. Int J Hydrogen Energy 37: 13446-13451. doi: 10.1016/j.ijhydene.2012.06.114
|
| [53] | Pendolino F (2011) “Boron Effect” on the Thermal Decomposition of Light Metal Borohydrides MBH4 (M = Li, Na, Ca). J Phys Chem C 116: 1390-1394. |
| [54] |
Pendolino F (2013) Thermal study on decomposition of LiBH4 at non-isothermal and non-equilibrium conditions. J Thermal Analysis Calorimetry 112: 1207-1211. doi: 10.1007/s10973-012-2662-2
|
| [55] |
Gross AF, Vajo JJ, Van Atta SL, et al. (2008) Enhanced Hydrogen Storage Kinetics of LiBH4 in Nanoporous Carbon Scaffolds. J Phys Chem C 112: 5651-5657. doi: 10.1021/jp711066t
|
| [56] | Xu J, Yu X, Ni J, et al. (2009) Enhanced catalytic dehydrogenation of LiBH4 by carbon-supported Pd nanoparticles. Dalton Transactions: 8386-8391. |
| [57] | Xu J, Yu X, Zou Z, et al. (2008) Enhanced dehydrogenation of LiBH4 catalyzed by carbon-supported Pt nanoparticles. Chem Commun 5740-5742. |
| [58] | Xu J, Qi Z, Cao J, et al. (2013) Reversible hydrogen desorption from LiBH4 catalyzed by graphene supported Pt nanoparticles. Dalton Transactions 42: 12926-12933 |
| [59] |
Luo W (2004) (LiNH2-MgH2): a viable hydrogen storage system. J Alloy Compd 381: 284-287. doi: 10.1016/j.jallcom.2004.03.119
|
| [60] |
Xiong Z, Wu G, Hu J, et al. (2004) Ternary Imides for Hydrogen Storage. Adv Mater 16: 1522-1525. doi: 10.1002/adma.200400571
|
| [61] |
Leng HY, Ichikawa T, Hino S, et al. (2004) New Metal-N-H System Composed of Mg(NH2)2 and LiH for Hydrogen Storage. J Phy Chem B 108: 8763-8765. doi: 10.1021/jp048002j
|
| [62] |
Nakamori Y, Kitahara G, Orimo S (2004) Synthesis and dehydriding studies of Mg-N-H systems. J Power Sources 138: 309-312. doi: 10.1016/j.jpowsour.2004.06.026
|
| [63] | Nakamori Y, Kitahara G, Miwa K, et al. (2005) Reversible hydrogen-storage functions for mixtures of Li3N and Mg3N2. Appl Phys A 80: 1-3. |
| [64] |
Dolci F, Weidner E, Hoelzel M, et al. (2010) In-situ neutron diffraction study of magnesium amide/lithium hydride stoichiometric mixtures with lithium hydride excess. Int J Hydrogen Energy 35: 5448-5453. doi: 10.1016/j.ijhydene.2010.03.030
|
| [65] |
Barison S, Agresti F, Lo Russo S, et al. (2008) A study of the LiNH2-MgH2 system for solid state hydrogen storage. J Alloy Compd 459: 343-347. doi: 10.1016/j.jallcom.2007.04.278
|
| [66] |
Shahi RR, Yadav TP, Shaz MA, et al. (2008) Effects of mechanical milling on desorption kinetics and phase transformation of LiNH2/MgH2 mixture. Int J Hydrogen Energy 33: 6188-6194. doi: 10.1016/j.ijhydene.2008.07.029
|
| [67] |
Liang C, Liu Y, Luo K, et al. (2010) Reaction Pathways Determined by Mechanical Milling Process for Dehydrogenation/Hydrogenation of the LiNH2/MgH2 System. Chemistry A European Journal 16: 693-702. doi: 10.1002/chem.200901967
|
| [68] |
Liu Y, Li B, Tu F, et al. (2011) Correlation between composition and hydrogen storage behaviors of the Li2NH-MgNH combination system. Dalton Transactions 40: 8179-8186. doi: 10.1039/c1dt10108k
|
| [69] |
Lu J, Choi YJ, Fang ZZ, et al. (2010) Effect of milling intensity on the formation of LiMgN from the dehydrogenation of LiNH2-MgH2 (1:1) mixture. J Power Sources 195: 1992-1997. doi: 10.1016/j.jpowsour.2009.10.032
|
| [70] | Pottmaier D, Dolci F, Orlova M, et al. (2011) Hydrogen release and structural transformations in LiNH2-MgH2 systems. J Alloy Compd 509, Supplement 2: S719-S723. |
| [71] |
Vajo JJ, Skeith SL, Mertens F (2005) Reversible Storage of Hydrogen in Destabilized LiBH4. J Phys Chem B 109: 3719-3722. doi: 10.1021/jp040769o
|
| [72] |
Bosenberg U, Doppiu S, Mosegaard L, et al. (2007) Hydrogen sorption properties of MgH2-LiBH4 composites. Acta Materialia 55: 3951-3958. doi: 10.1016/j.actamat.2007.03.010
|
| [73] | Bosenberg U, Ravnsbk DB, Hagemann H, et al. (2010) Pressure and Temperature Influence on the Desorption Pathway of the LiBH4-MgH2 Composite System. J Phys Chem C 114: 15212-15217. |
| [74] | Nakagawa T, Ichikawa T, Hanada N, et al. (2007) Thermal analysis on the Li-Mg-B-H systems. J Alloy Compd 446-447: 306-309. |
| [75] | Shim J-H, Lim J-H, Rather S-u, et al. (2009) Effect of Hydrogen Back Pressure on Dehydrogenation Behavior of LiBH4-Based Reactive Hydride Composites. J Phys Chem Lett 1: 59-63. |
| [76] |
Yang J, Sudik A, Wolverton C (2007) Destabilizing LiBH 4 with a Metal ( M ) Mg , Al , Ti , V , Cr , or Sc ) or Metal Hydride ( MH 2 ). J Phys Chem C 111: 19134-19140. doi: 10.1021/jp076434z
|
| [77] |
Pinkerton FE, Meyer MS, Meisner GP, et al. (2007) Phase Boundaries and Reversibility of LiBH 4 / MgH 2 Hydrogen Storage Material. J Phys Chem Lett C 111: 12881-12885. doi: 10.1021/jp0742867
|
| [78] |
Price TEC, Grant DM, Legrand V, et al. (2010) Enhanced kinetics for the LiBH4:MgH2 multi-component hydrogen storage system—The effects of stoichiometry and decomposition environment on cycling behaviour. Int J Hydrogen Energy 35: 4154-4161. doi: 10.1016/j.ijhydene.2010.02.082
|
| [79] |
Wan X, Markmaitree T, Osborn W, et al. (2008) Nanoengineering-Enabled Solid-State Hydrogen Uptake and Release in the LiBH4 Plus MgH2 System. J Phys Chem C 112: 18232-18243. doi: 10.1021/jp8033159
|
| [80] |
Price TEC, Grant DM, Telepeni I, et al. (2009) The decomposition pathways for LiBD4-MgD2 multicomponent systems investigated by in situ neutron diffraction. J Alloy Compd 472: 559-564. doi: 10.1016/j.jallcom.2008.05.030
|
| [81] |
Walker GS, Grant DM, Price TC, et al. (2009) High capacity multicomponent hydrogen storage materials: Investigation of the effect of stoichiometry and decomposition conditions on the cycling behaviour of LiBH4,ÄìMgH2. J Power Sources 194: 1128-1134. doi: 10.1016/j.jpowsour.2009.06.075
|
| [82] | Yu XB, Grant DM, Walker GS (2006) A new dehydrogenation mechanism for reversible multicomponent borohydride systems--The role of Li-Mg alloys. Chem commun (Cambridge, England) 1: 3906-3908. |
| [83] |
Dobbins T, NaraseGowda S, Butler LG (2012) Study of Morphological Changes in MgH2 Destabilized LiBH4 Systems Using Computed X-ray Microtomography. Materials 5: 1740-1751. doi: 10.3390/ma5101740
|
| [84] |
Barkhordarian G, Klassen T, Dornheim M, et al. (2007) Unexpected kinetic effect of MgB2 in reactive hydride composites containing complex borohydrides. J Alloy Compd 440: L18-L21. doi: 10.1016/j.jallcom.2006.09.048
|
| [85] | COSY-network Complex Solid State Reaction for Energy Efficient Hydrogen Storage. Available from: www.cosy-net.eu. |
| [86] |
Santos DMF, Sequeira CAC (2011) Sodium borohydride as a fuel for the future. Renew Sust Energy Rev 15: 3980-4001. doi: 10.1016/j.rser.2011.07.018
|
| [87] |
Dinsdale AT (1991) SGTE Data for Pure Elements. CALPHAD 15: 317-425. doi: 10.1016/0364-5916(91)90030-N
|
| [88] | Manchester FD (2000) Phase Diagrams of Binary Hydrogen Alloys. United State of America: ASM International. |
| [89] |
George L, Saxena SK (2010) Structural stability of metal hydrides, alanates and borohydrides of alkali and alkali- earth elements: A review. Int J Hydrogen Energy 35: 5454-5470. doi: 10.1016/j.ijhydene.2010.03.078
|
| [90] |
Pottmaier D, Pinatel ER, Vitillo JG, et al. (2011) Structure and Thermodynamic Properties of the NaMgH3 Perovskite: A Comprehensive Study. Chem Mater 23: 2317-2326. doi: 10.1021/cm103204p
|
| [91] |
Barrico M, Paulmbo M, Pinatel E, et al. (2010) Thermodynamic Database for Hydrogen Storage Materials. Adv Sci Tech 72: 213-218. doi: 10.4028/www.scientific.net/AST.72.213
|
| [92] | Stasinevich G, Egorenko A (1969) J Inorg Chem 13: 341-343. |
| [93] | Martelli P, Caputo R, Remhof A, et al. (2010) Stability and Decomposition of NaBH 4. The J Phys Chem C 114: 7173-7177. |
| [94] |
Urgnani J, Torres F, Palumbo M, et al. (2008) Hydrogen release from solid state NaBH4. Int J Hydrogen Energy 33: 3111-3115. doi: 10.1016/j.ijhydene.2008.03.031
|
| [95] |
Mao JF, Yu XB, Guo ZP, et al. (2009) Enhanced hydrogen storage performances of NaBH4-MgH2 system. J Alloy Compd 479: 619-623. doi: 10.1016/j.jallcom.2009.01.012
|
| [96] |
Humphries TD, Kalantzopoulos GN, Llamas-Jansa I, et al. (2013) Reversible Hydrogenation Studies of NaBH4 Milled with Ni-Containing Additives. J Phys Chem C 117: 6060-6065. doi: 10.1021/jp312105w
|
| [97] |
Pendolino F, Mauron P, Borgschulte A, et al. (2009) Effect of Boron on the Activation Energy of the Decomposition of LiBH4. J Phys Chem C 113: 17231-17234. doi: 10.1021/jp902384v
|
| [98] |
Caputo R, Garroni S, Olid D, et al. (2010) Can Na2[B12H12] be a decomposition product of NaBH4? Phys Chem Chem Phys 12: 15093-15100.99. Her J-H, Zhou W, Stavila V, et al. (2009) Role of Cation Size on the Structural Behavior of the Alkali-Metal Dodecahydro-closo-Dodecaborates. J Phys Chem Lett C 113: 11187-11189. doi: 10.1021/jp904980m
|
| [99] |
100. Friedrichs O, Remhof A, Hwang K-J, et al. (2010) Role of Li2B12H12 for the formation and decomposition of LiBH4. Chem Mater 22: 3265-3268. doi: 10.1021/cm100536a
|
| [100] |
101. Her JH, Yousufuddin M, Zhou W, et al. (2008) Crystal structure of Li2B12H12: a possible intermediate species in the decomposition of LiBH4. Inorg Chem 47: 9757-9759. doi: 10.1021/ic801345h
|
| [101] | 102. Hwang SJ, Bowman RC, Reiter JW, et al. (2008) NMR Confirmation for Formation of [B12H12]2- Complexes during Hydrogen Desorption from Metal Borohydrides. J Phys Chem C 112: 3164-3169. |
| [102] |
103. Minella CB, Pistidda C, Garroni S, et al. (2013) Ca(BH4)2 + MgH2: Desorption Reaction and Role of Mg on Its Reversibility. J Phys Chem C 117: 3846-3852. doi: 10.1021/jp312271s
|
| [103] |
104. Yan Y, Remhof A, Rentsch D, et al. (2013) Is Y2(B12H12)3 the main intermediate in the decomposition process of Y(BH4)3? Chem Commun 49: 5234-5236. doi: 10.1039/c3cc41184b
|
| [104] |
105. Mao J, Guo Z, Yu X, et al. (2013) Combined effects of hydrogen back-pressure and NbF5 addition on the dehydrogenation and rehydrogenation kinetics of the LiBH4-MgH2 composite system. Int J Hydrogen Energy 38: 3650-3660. doi: 10.1016/j.ijhydene.2012.12.106
|
| [105] |
106. Yan Y, Li H-W, Maekawa H, et al. (2011) Formation of Intermediate Compound Li2B12H12 during the Dehydrogenation Process of the LiBH4-MgH2 System. J Phys Chem C 115: 19419-19423. doi: 10.1021/jp205450c
|
| [106] |
107. Garroni S, Milanese C, Pottmaier D, et al. (2011) Experimental Evidence of Na2[B12H12] and Na Formation in the Desorption Pathway of the 2NaBH4 + MgH2 System. J Phys Chem C 115: 16664-16671. doi: 10.1021/jp202341j
|
| [107] |
108. Pottmaier D, Pistidda C, Groppo E, et al. (2011) Dehydrogenation reactions of 2NaBH4 + MgH2 system. Int J Hydrogen Energy 36: 7891-7896. doi: 10.1016/j.ijhydene.2011.01.059
|
| [108] |
109. Pistidda C, Garroni S, Minella CB, et al. (2010) Pressure Effect on the 2NaH + MgB2 Hydrogen Absorption Reaction. J Phys Chem C 114: 21816-21823. doi: 10.1021/jp107363q
|
| [109] |
110. Garroni S, Milanese C, Girella A, et al. (2010) Sorption properties of NaBH4/MH2 (M = Mg, Ti) powder systems. Int J Hydrogen Energy 35: 5434-5441. doi: 10.1016/j.ijhydene.2010.03.004
|
| [110] |
111. Shi L, Gi Y, Qian T, et al. (2004) Synthesis of ultrafine superconducting MgB2 by a convenient solid-state reaction route. Physica C 405: 271-274. doi: 10.1016/j.physc.2004.02.013
|
| [111] |
112. Varin RA, Chiu C, Wronski ZS (2008) Mechano-chemical activation synthesis (MCAS) of disordered Mg(BH4)2 using NaBH 4. J Alloy Compd 462: 201-208. doi: 10.1016/j.jallcom.2007.07.110
|
| [112] |
113. Varin Ra, Czujko T, Chiu C, et al. (2009) Synthesis of nanocomposite hydrides for solid-state hydrogen storage by controlled mechanical milling techniques. J Alloy Compd 483: 252-255. doi: 10.1016/j.jallcom.2008.07.207
|
| [113] |
114. Czujko T, Varin R, Wronski Z, et al. (2007) Synthesis and hydrogen desorption properties of nanocomposite magnesium hydride with sodium borohydride (MgH2+NaBH4). J Alloy Compd 427: 291-299. doi: 10.1016/j.jallcom.2006.03.020
|
| [114] | 115. Czujiko T, Varin R, Zaranski Z, et al. (2010) The dehydrogenation process of destabilized NaBH4-MgH2 solid state hydride composites. Arch Metall Mater 55: 539-552. |
| [115] |
116. Garroni S, Pistidda C, Brunelli M, et al. (2009) Hydrogen desorption mechanism of 2NaBH4+MgH2 composite prepared by high-energy ball milling. Scripta Materialia 60: 1129-1132. doi: 10.1016/j.scriptamat.2009.02.059
|
| [116] |
117. Caputo R, Garroni S, Olid D, et al. (2010) Can Na2[B12H12] be a decomposition product of NaBH4? Phys Chem Chem Phys 12: 15093-15100. doi: 10.1039/c0cp00877j
|
| [117] |
118. Garroni S, Milanese C, Girella A, et al. (2010) Sorption properties of NaBH4/MH2 (M=Mg, Ti) powder systems. Int J Hydrogen Energy 35: 5434-5441. doi: 10.1016/j.ijhydene.2010.03.004
|
| [118] |
119. Pottmaier D, Garroni S, Barò MD, et al. (2010) Hydrogen Desorption Reactions of the Na-Mg-B-H System. Adv Sci Tech72: 164-169. doi: 10.4028/www.scientific.net/AST.72.164
|
| [119] | 120.Pottmaier D, Garroni S, Brunelli M, et al. (2010) NaBX4-MgX2 Composites (X= D,H) Investigated by In situ Neutron Diffraction. Mater Res Soc Symp Proc 1262: W03-04. |
| [120] |
121. Nwakwuo CC, Pistidda C, Dornheim M, et al. (2012) Microstructural study of hydrogen desorption in 2NaBH4 + MgH2 reactive hydride composite. Int J Hydrogen Energy 37: 2382-2387. doi: 10.1016/j.ijhydene.2011.10.070
|
| [121] |
122. Mao J, Guo Z, Yu X, et al. (2011) Improved Hydrogen Storage Properties of NaBH4 Destabilized by CaH2 and Ca(BH4)2. J Phys Chem C 115: 9283-9290. doi: 10.1021/jp2020319
|
| [122] |
123. Franco F, Baricco M, Chierotti MR, et al. (2013) Coupling Solid-State NMR with GIPAW ab Initio Calculations in Metal Hydrides and Borohydrides. J Phys Chem C 117: 9991-9998. doi: 10.1021/jp3126895
|
| [123] |
124. Shane DT, Corey RL, Bowman Jr RC, et al. (2009) NMR studies of the hydrogen storage compound NaMgH3. J Phys Chem C 113: 18414-18419. doi: 10.1021/jp906414q
|
| [124] |
125. Huang Z, Eagles M, Porter S, et al. (2013) Thermolysis and solid state NMR studies of NaB3H8, NH3B3H7, and NH4B3H8. Dalton Transactions 42: 701-708. doi: 10.1039/C2DT31365K
|
| [125] |
126. Çakır D, de Wijs GA, Brocks G (2011) Native Defects and the Dehydrogenation of NaBH4. J Phys Chem C 115: 24429-24434. doi: 10.1021/jp208642g
|
| [126] |
127. Pistidda C, Barkhordarian G, Rzeszutek A, et al. (2011) Activation of the reactive hydride composite 2NaBH4+MgH2. Scripta Materialia 64: 1035-1038. doi: 10.1016/j.scriptamat.2011.02.017
|
| [127] |
128. Kato S, Borgschulte A, Bielmann M, et al. (2012) Interface reactions and stability of a hydride composite (NaBH4 + MgH2). Phys Chem Chem Phys 14: 8360-8368. doi: 10.1039/c2cp23491b
|
| [128] |
129. Pistidda C, Napolitano E, Pottmaier D, et al. (2013) Structural study of a new B-rich phase obtained by partial hydrogenation of 2NaH + MgB2. Int J Hydrogen Energy 38: 10479-10484. doi: 10.1016/j.ijhydene.2013.06.025
|
| [129] |
130. Milanese C, Garroni S, Girella A, et al. (2011) Thermodynamic and Kinetic Investigations on Pure and Doped NaBH4-MgH2 System. J Phys Chem C 115: 3151-3162. doi: 10.1021/jp109392e
|
| [130] |
131. Saldan I, Gosalawit-Utke R, Pistidda C, et al. (2012) Influence of Stoichiometry on the Hydrogen Sorption Behavior in the LiF-MgB2 System. J Phys Chem C 116: 7010-7015. doi: 10.1021/jp212322u
|
| [131] |
132. Christian M, Aguey-Zinsou K-F (2013) Synthesis of core-shell NaBH4@M (M = Co, Cu, Fe, Ni, Sn) nanoparticles leading to various morphologies and hydrogen storage properties. Chem Commun 49: 6794-6796. doi: 10.1039/c3cc42815j
|
| [132] | 133. Mulas G, Campesi R, Garroni S, et al. (2012) Hydrogen storage in 2NaBH4+MgH2 mixtures: Destabilization by additives and nanoconfinement. J Alloy Compd 536, Supplement 1: S236-S240. |
| [133] | 134. Peru F, Garroni S, Campesi R, et al. (2013) Ammonia-free infiltration of NaBH4 into highly-ordered mesoporous silica and carbon matrices for hydrogen storage. J Alloy Compd 580, Supplement 1: S309-S312. |
| [134] | 135. Bardhan R, Hedges LO, Pint CL, et al. (2013) Uncovering the intrinsic size dependence of hydriding phase transformations in nanocrystals. Nat Mater advance online publication. |
| [135] | 136. Schlesinger HI, Sanderson RT, Burg AB (1940) Metallo Borohydrides. I. Aluminum Borohydride. J Am Chem Soc 62: 3421-3425. |
| [136] |
137. Schlesinger HI, Brown HC (1940) Metallo Borohydrides. III. Lithium Borohydride. J Am Chem Soc 62: 3429-3435. doi: 10.1021/ja01869a039
|
| [137] | 138. Schlesinger HI, Brown HC, Hoekstra HR, et al. (1953) Reactions of Diborane with Alkali Metal Hydrides and Their Addition Compounds. New Syntheses of Borohydrides. Sodium and Potassium Borohydrides1. J Am Chem Soc 75: 199-204. |
| [138] | 139. Schlesinger HI, Brown HC, Abraham B, et al. (1953) New Developments in the Chemistry of Diborane and the Borohydrides. I. General Summary1. J Am Chem Soc 75: 186-190. |
| [139] |
140. Miwa K, Aoki M, Noritake T, et al. (2006) Correlation between thermodynamic staibilties of metal borohydrides and cation electronegavities: First principles calculations and experiments. Phys Rev B 74: 075110. doi: 10.1103/PhysRevB.74.075110
|
| [140] | 141. Nakamori Y, Li H, Kikuchi K, et al. (2007) Thermodynamical stabilities of metal-borohydrides. J Alloy Compd 447: 296-300. |
| [141] |
142. Hu J, Kwak JH, Zhenguo Y, et al. (2009) Direct observation of ion exchange in mechanism activated LiH+MgB2 system using ultrahigh field nuclear magnetic resonance spectroscopy. Appl Phys Lett 94: 05. doi: 10.1063/1.3110966
|
| [142] |
143. Li H-W, Matsunaga T, Yan Y, et al. (2010) Nanostructure-induced hydrogenation of layered compound MgB2. J Alloy Compd 505: 654-656. doi: 10.1016/j.jallcom.2010.06.101
|
| [143] |
144. Pistidda C, Garroni S, Dolci F, et al. (2010) Synthesis of amorphous Mg(BH4)2 from MgB2 and H2 at room temperature. J Alloy Compd 508: 212-215. doi: 10.1016/j.jallcom.2010.07.226
|
| [144] | 145. Barkhordarian G, Jensen TR, Doppiu S, et al. (2008) Formation of Ca(BH4)2 from Hydrogenation of CaH2+MgB2 Composite. J Phys Chem C 112: 2743-2749. |
| [145] |
146. Nwakwuo CC, Pistidda C, Dornheim M, et al. (2011) Microstructural analysis of hydrogen absorption in 2NaH+MgB2. Scripta Materialia 64: 351-354. doi: 10.1016/j.scriptamat.2010.10.034
|
| [146] |
147. Garroni S, Minella CB, Pottmaier D, et al. (2013) Mechanochemical synthesis of NaBH4 starting from NaH-MgB2 reactive hydride composite system. Int J Hydrogen Energy 38: 2363-2369. doi: 10.1016/j.ijhydene.2012.11.136
|
| [147] |
148. Nwakwuo CC, Hutchison JL, Sykes JM (2012) Hydrogen sorption in 3NaH+MgB2/2NaBH4+NaMgH3 composite. Scripta Materialia 66: 175-177. doi: 10.1016/j.scriptamat.2011.10.035
|
| [148] | 149. Wang H, Zhang J, Liu JW, et al. (2013) Catalysis and hydrolysis properties of perovskite hydride NaMgH3. J Alloy Compd 580, Supplement 1: S197-S201. |
| [149] |
150. Rafi ud d, Xuanhui Q, Zahid GH, et al. (2014) Improved hydrogen storage performances of MgH2-NaAlH4 system catalyzed by TiO2 nanoparticles. J Alloy Compd 604: 317-324. doi: 10.1016/j.jallcom.2014.03.150
|
| [150] |
151. Milošević S, Milanović I, Mamula BP, et al. (2013) Hydrogen desorption properties of MgH2 catalysed with NaNH2. Int J Hydrogen Energy 38: 12223-12229. doi: 10.1016/j.ijhydene.2013.06.083
|
| [151] |
152. Li Y, Fang F, Song Y, et al. (2013) Hydrogen storage of a novel combined system of LiNH2-NaMgH3: synergistic effects of in situ formed alkali and alkaline-earth metal hydrides. Dalton Transactions 42: 1810-1819. doi: 10.1039/C2DT31923C
|
| 1. | Jiyao Liu, Lang He, Haifeng Chen, Dongmei Jiang, Directional Spatial and Spectral Attention Network (DSSA Net) for EEG-based emotion recognition, 2025, 18, 1662-5218, 10.3389/fnbot.2024.1481746 |
Figures(2) / Tables(3)

Daphiny Pottmaier, Marcello Baricco. Materials for hydrogen storage and the Na-Mg-B-H system[J]. AIMS Energy, 2015, 3(1): 75-100. doi: 10.3934/energy.2015.1.75

| Holling type | Definition | Generalized form |
| Ⅱ | $ p(u)=\frac{mu}{u+k} $ | |
| Ⅲ | $ p(u)=\frac{mu^2}{u^2+k} $ | $ p(u)=\frac{mu^2}{k_1u^2+k_2u+1}(k_2>-2\sqrt{k_1}) $ |
| Ⅳ | $ p(u)=\frac{mu}{u^2+k} $ | $ p(u)=\frac{mu}{k_1u^2+k_2u+1}(k_2>-2\sqrt{k_1}) $ |
DownLoad:
CSV
