Intertemporal decision-making, which involves making choices between outcomes at different time points, is a fundamental aspect of human behavior. Understanding the underlying mental processes is vital for comprehending the complexities of human decision-making and choice behavior.
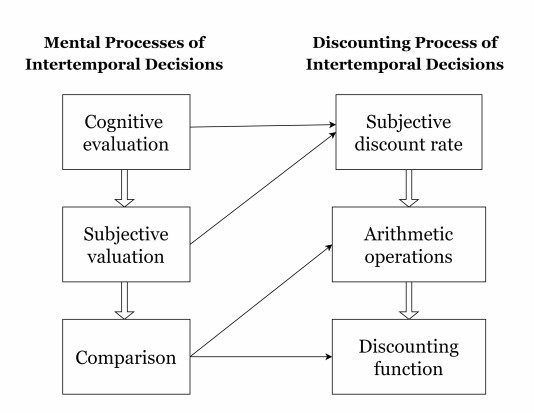
The main objective of this study is to investigate the interplay of mental processes, specifically cognitive evaluation, subjective valuation, and comparison, in the context of intertemporal decision-making, with a specific focus on understanding the discounting process.
Development of a mathematical representation of the discounting process that incorporates the mental processes associated with intertemporal decision-making.
Our findings indicate that hyperbolic discounting aligns well with the cognitive processes underlying intertemporal decision-making. Subsequent research will employ qualitative questionnaires to establish the discount function relevant to specific groups, thereby enhancing our comprehension of the discounting process within intertemporal decision-making.
Citation: Salvador Cruz Rambaud, Jorge Hernandez-Perez. A naive justification of hyperbolic discounting from mental algebraic operations and functional analysis[J]. Quantitative Finance and Economics, 2023, 7(3): 463-474. doi: 10.3934/QFE.2023023
Intertemporal decision-making, which involves making choices between outcomes at different time points, is a fundamental aspect of human behavior. Understanding the underlying mental processes is vital for comprehending the complexities of human decision-making and choice behavior.
The main objective of this study is to investigate the interplay of mental processes, specifically cognitive evaluation, subjective valuation, and comparison, in the context of intertemporal decision-making, with a specific focus on understanding the discounting process.
Development of a mathematical representation of the discounting process that incorporates the mental processes associated with intertemporal decision-making.
Our findings indicate that hyperbolic discounting aligns well with the cognitive processes underlying intertemporal decision-making. Subsequent research will employ qualitative questionnaires to establish the discount function relevant to specific groups, thereby enhancing our comprehension of the discounting process within intertemporal decision-making.

| [1] | Aczél J (1987) A Short Course on Functional Equations, Dordrecht: D. Reidel. |
| [2] |
Ainslie G (1975) Specious reward: A behavioral theory of impulsiveness and impulse control. Psychol Bull 82: 463–496. https://doi.org/10.1037/h0076860 doi: 10.1037/h0076860

|
| [3] |
Backes-Gellner U, Herz H, Kosfeld M, et al. (2018) Do preferences and biases predict life outcomes? Evidence from education and labor market entry decisions. Eur Econ Rev 134: 103709. https://doi.org/10.1016/j.euroecorev.2021.103709 doi: 10.1016/j.euroecorev.2021.103709
|
| [4] |
Berns GS, Laibson D, Loewenstein G (2007) Intertemporal choice - toward an integrative framework. Trends Cogn Sci 11: 482–488. https://doi.org/10.1016/j.tics.2007.08.011 doi: 10.1016/j.tics.2007.08.011
|
| [5] |
Bickel WK, Yi R, Kowal BP, et al. (2008) Cigarette smokers discount past and future rewards symmetrically and more than controls: Is discounting a measure of impulsivity? Drug Alcohol Depen 96: 256–262. https://doi.org/10.1016/j.drugalcdep.2008.03.009 doi: 10.1016/j.drugalcdep.2008.03.009
|
| [6] |
Cadena BC, Keys BJ (2015) Human capital and the lifetime costs of impatience. Am Econ J Econ Policy 7: 126–153. https://doi.org/10.1257/pol.20130081 doi: 10.1257/pol.20130081
|
| [7] |
Chapman GB, Weber BJ (2006) Decision biases in intertemporal choice and choice under uncertainty: Testing a common account. Mem Cognition 34: 589–602. https://doi.org/10.3758/BF03193582 doi: 10.3758/BF03193582
|
| [8] |
Cheung SL, Tymula A, Wang X (2022) Present bias for monetary and dietary rewards. Exp Econ 25: 1202–1233. https://doi.org/10.1007/s10683-022-09749-8 doi: 10.1007/s10683-022-09749-8
|
| [9] |
Cruz Rambaud S (2014) A new argument in favor of hyperbolic discounting in very long term project appraisal. Int J Theor Appl Financ 17: 1–17. https://doi.org/10.1142/S0219024914500496 doi: 10.1142/S0219024914500496
|
| [10] |
Cruz Rambaud S, Muñoz Torrecillas MJ (2016) Measuring impatience in intertemporal choice. PLoS ONE 11: e0149256. https://doi.org/10.1371/journal.pone.0149256 doi: 10.1371/journal.pone.0149256
|
| [11] | Doyle J, Chen CH (2010) Time is money: Arithmetic discounting outperforms hyperbolic and exponential discounting. Available from: SSRN: https://ssrn.com/abstract = 1609594 or http://dx.doi.org/10.2139/ssrn.1609594. |
| [12] |
Dyer JS, Sarin RK (1982) Relative risk aversion. Manage Sci 28: 875–886. https://doi.org/10.1287/mnsc.28.8.875 doi: 10.1287/mnsc.28.8.875
|
| [13] |
Franco-Watkins AM, Mattson RE, Jackson MD (2016) Now or later? Attentional processing and intertemporal choice. J Behav Decis Making 29: 206–217. https://doi.org/10.1002/bdm.1895 doi: 10.1002/bdm.1895
|
| [14] |
Frederick S, Loewenstein G, O'Donoghue T (2002) Time discounting and time preference: A critical review. J Econ Lit 40: 351–401. https://doi.org/10.1257/002205102320161311 doi: 10.1257/002205102320161311
|
| [15] |
Friedel JE, DeHart WB, Madden GJ, et al. (2014) Impulsivity and cigarette smoking: Discounting of monetary and consumable outcomes in current and non-smokers. Psychopharmacology 231: 4517–4526. https://doi.org/10.1007/s00213-014-3597-z doi: 10.1007/s00213-014-3597-z
|
| [16] |
Green L, Myerson J (2004) A discounting framework for choice with delayed and probabilistic rewards. Psychol Bull 130: 769–792. https://doi.org/10.1037/0033-2909.130.5.769 doi: 10.1037/0033-2909.130.5.769
|
| [17] | Golsteyn BHH, Grönqvist H, Lindahl L (2013) Time preferences and lifetime outcomes. IZA Discussion Papers 7165, Institute for the Study of Labor (IZA), Bonn. http://dx.doi.org/10.2139/ssrn.2210825 |
| [18] |
Harris CR (2012) Feelings of dread and intertemporal choice. J Behav Decis Making 25: 13–28. https://doi.org/10.1002/bdm.709 doi: 10.1002/bdm.709
|
| [19] |
Harvey CM (1986) Value functions for infinite-period planning. Manage Sci 32: 1123–1139. https://doi.org/10.1287/mnsc.32.9.1123 doi: 10.1287/mnsc.32.9.1123
|
| [20] |
Harvey CM (1994) The reasonableness of non-constant discounting. J Public Econ 53: 31–51. https://doi.org/10.1016/0047-2727(94)90012-4 doi: 10.1016/0047-2727(94)90012-4
|
| [21] |
Herz H, Huber M, Maillard-Bjedov T, et al. (2021) Time preferences across language groups: Evidence on intertemporal choices from the Swiss language border. Econ J 131: 2920–2954. https://doi.org/10.1093/ej/ueab025 doi: 10.1093/ej/ueab025
|
| [22] |
Kable JW, Glimcher PW (2007) The neural correlates of subjective value during intertemporal choice. Nat Neurosci 10: 1625–1633. https://doi.org/10.1038/nn2007 doi: 10.1038/nn2007
|
| [23] |
Keidel K, Rramani Q, Weber B, et al. (2021) Individual differences in intertemporal choice. Front Psychol 12: 643670. https://doi.org/10.3389/fpsyg.2021.643670 doi: 10.3389/fpsyg.2021.643670
|
| [24] |
Killeen PR (2009) An additive-utility model of delay discounting. Psychol Rev 116: 602–619. https://doi.org/10.1037/a0016414 doi: 10.1037/a0016414
|
| [25] |
Kim BK, Zauberman G (2009) Perception of anticipatory time in temporal discounting. J Neurosci Psychol E 2: 91–101. https://doi.org/10.1037/a0017686 doi: 10.1037/a0017686
|
| [26] |
Laibson D (1997) Golden eggs and hyperbolic discounting. Q J Econ 112: 443–478. https://doi.org/10.1162/003355397555253 doi: 10.1162/003355397555253
|
| [27] |
Lempert KM, Johnson E, Phelps EA (2016) Emotional arousal predicts intertemporal choice. Emotion 16: 647–656. https://doi.org/10.1037/emo0000168 doi: 10.1037/emo0000168
|
| [28] |
Liu X, Turel O, Xiao Z, et al. (2022) Impulsivity and neural mechanisms that mediate preference for immediate food rewards in people with vs without excess weight. Appetite 169: 105798. https://doi.org/10.1016/j.appet.2021.105798 doi: 10.1016/j.appet.2021.105798
|
| [29] |
Loewenstein G (1988) Frames of mind in intertemporal choice. Manage Sci 34: 200–214. https://doi.org/10.1287/mnsc.34.2.200 doi: 10.1287/mnsc.34.2.200
|
| [30] |
Loewenstein G (1996) Out of control: Visceral influences on behavior. Organ Behav Hu Dec 65: 272–292. https://doi.org/10.1006/obhd.1996.0028 doi: 10.1006/obhd.1996.0028
|
| [31] |
Loewenstein G, Prelec D (1992) Anomalies in intertemporal choice: Evidence and an interpretation. Q J Econ 107: 573–597. https://doi.org/10.2307/2118482 doi: 10.2307/2118482
|
| [32] | Malkoc SA, Zauberman G (2006) Deferring versus expediting consumption: The effect of outcome concreteness on sensitivity to time horizon J Marketing Res XLIII: 618–627. https://doi.org/10.1509/jmkr.43.4.618 |
| [33] |
Malkoc SA, Zauberman G (2019) Psychological analysis of consumer intertemporal decisions. Consum Psychol Rev 2: 97–113. https://doi.org/10.1002/arcp.1048 doi: 10.1002/arcp.1048
|
| [34] |
Malkoc SA, Zauberman G, Bettman JR (2010) Unstuck from the concrete! Carryover effect of abstract mindsets in intertemporal preferences. Organ Behav Hu Dec 113: 112–126. https://doi.org/10.1016/j.obhdp.2010.07.003 doi: 10.1016/j.obhdp.2010.07.003
|
| [35] | Mazur JE (1987) An adjusting procedure for studying delayed reinforcement, In: Commons ML, Mazur JE, Nevin JA, Rachlin H (Eds.) Quantitative Analyses of Behavior, The effect of delay and of intervening events on reinforcement value, Lawrence Erlbaum Associates: Hillsdale, NJ, 5: 55–73. |
| [36] |
Moreira D, Barbosa F (2019) Delay Discounting in Impulsive Behavior: A systematic review. Eur Psychol 24: 312–-321. https://doi.org/10.1027/1016-9040/a000360 doi: 10.1027/1016-9040/a000360
|
| [37] |
Muñoz Torrecillas MJ, Takahashi T, Gil Roales-Nieto J, et al. (2018) Impatience and inconsistency in intertemporal choice: An experimental analysis. J Behav Financ 19: 190–198. https://doi.org/10.1080/15427560.2017.1374274 doi: 10.1080/15427560.2017.1374274
|
| [38] |
Scharff RL (2009) Obesity and hyperbolic discounting: Evidence and implications. J Consumer Policy 32: 3–21. https://doi.org/10.1007/s10603-009-9090-0 doi: 10.1007/s10603-009-9090-0
|
| [39] | Stevens JR, Stephens DW (2010) The adaptive nature of impulsivity. In: Madden GJ, Bickel WK (Eds.), Impulsivity: The behavioral and neurological science of discounting, American Psychological Association, 361—387. https://doi.org/10.1037/12069-013 |
| [40] |
Steward T, Mestre-Bach G, Fernández-Aranda F, et al. (2017) Delay discounting and impulsivity traits in young and older gambling disorder patients. Addict Behav 71: 96–103. https://doi.org/10.1016/j.addbeh.2017.03.001 doi: 10.1016/j.addbeh.2017.03.001
|
| [41] | Sutter M, Angerer S, Glätzle-Rützler D, et al.(2015) The effect of language on economic behavior: Experimental evidence from children's intertemporal choices. CESifo Working Paper Series, 5532. http://dx.doi.org/10.2139/ssrn.2681024 |
| [42] |
Sutter M, Angerer S, Glätzle-Rützler D, et al. (2018) Language group differences in time preferences: Evidence from primary school children in a bilingual city. Eur Econ Rev 106: 21–34. https://doi.org/10.1016/j.euroecorev.2018.04.003 doi: 10.1016/j.euroecorev.2018.04.003
|
| [43] |
Tversky A, Kahneman D (1991) Loss aversion in riskless choice: A reference-dependent model. Q J Econ 106: 1039–1061. https://doi.org/10.2307/2937956 doi: 10.2307/2937956
|
| [44] |
Zauberman G, Kim BK, Malkoc SA, et al. (2009) Discounting time and time discounting: Subjective time perception and intertemporal preferences. J Marketing Res 46: 543–556. https://doi.org/10.1509/jmkr.46.4.543 doi: 10.1509/jmkr.46.4.543
|
| [45] |
Zauberman G, Ratner RK, Kim BK (2009) Memories as assets: Strategic memory protection in choice over time. J Consumer Res 35: 715–728. https://doi.org/10.1086/592943 doi: 10.1086/592943
|
Figures(1) / Tables(1)

Salvador Cruz Rambaud, Jorge Hernandez-Perez. A naive justification of hyperbolic discounting from mental algebraic operations and functional analysis[J]. Quantitative Finance and Economics, 2023, 7(3): 463-474. doi: 10.3934/QFE.2023023







 DownLoad:
DownLoad: