Citation: Martin Do Pham. Fractal approximation of chaos game representations using recurrent iterated function systems[J]. AIMS Mathematics, 2019, 5(6): 1824-1840. doi: 10.3934/math.2019.6.1824

| [1] |
J. S. Almeida, J. A. Carrico, A. Maretzek, et al. Analysis of genomic sequences by Chaos Game Representation, Bioinformatics, 17 (2001), 429-437. doi: 10.1093/bioinformatics/17.5.429

|
| [2] | M. F. Barnsley, Superfractals, 1st edition, Cambridge University Press, Cambridge, 2006. |
| [3] |
M. F. Barnsley, J. H. Elton and D. P. Hardin, Recurrent iterated function systems, Constr. Approx., 5 (1989), 3-31. doi: 10.1007/BF01889596
|
| [4] |
M. F. Barnsley and S. Demko, Iterated function systems and the global construction of fractals, Proceedings of the Royal Society of London A, 399 (1985), 243-275. doi: 10.1098/rspa.1985.0057
|
| [5] |
P. J. Deschavanne, A. Giron, J. Vilain, et al. Genomic signature: characterization and classification of species assessed by chaos game representation of sequences, Mol. Biol. Evol., 16 (1999), 1391-1399. doi: 10.1093/oxfordjournals.molbev.a026048
|
| [6] |
A. Fiser, G. E. Tusnady, I. Simon, Chaos game representation of protein structures, J. Mol. Graph. Model., 12 (1994), 302-304. doi: 10.1016/0263-7855(94)80109-6
|
| [7] |
J. M. Gutierrez, M. A. Rodriguez, G. Abramson, Multifractal analysis of DNA sequences using a novel chaos-game representation, Physica A: Statistical Mechanics and its Applications, 300 (2001), 271-284. doi: 10.1016/S0378-4371(01)00333-8
|
| [8] |
J. C. Hart, Fractal Image Compression and Recurrent Iterated Function Systems, IEEE Comput. Graph., 16 (1996), 25-33. doi: 10.1109/38.511849
|
| [9] |
H. J. Jeffrey, Chaos game representation of gene structure, Nucleic Acids Research, 18 (1990), 2163-2170. doi: 10.1093/nar/18.8.2163
|
| [10] | H. Jia-Jing and F. Wei-Juan, Wavelet-based multifractal analysis of DNA sequences by using chaosgame representation, Chinese Phys. B, 19 (2010), 10205. |
| [11] | L. Kari, K. A. Hill, A. S. Sayem, et al. Mapping the space of genomic signatures, PLOS ONE, 10 (2015), 119815. |
| [12] |
S. G. Mallat, A theory for multiresolution signal decomposition: the wavelet representation, IEEE transactions on pattern analysis and machine intelligence, 11 (1989), 674-693. doi: 10.1109/34.192463
|
| [13] |
P. Mayukha, B. Satish, K. Srinivas, et al. Multifractal detrended cross-correlation analysis of coding and non-coding DNA sequences through chaos-game representation, Physica A: Statistical Mechanics and its Applications, 436 (2015), 596-603. doi: 10.1016/j.physa.2015.05.018
|
| [14] | H. Oh, B. Seo, S. Lee, et al. Two complete chloroplast genome sequences of Cannabis sativa varieties, Mitochondrial DNA Part A: DNA mapping, sequencing, and analysis, 27 (2016), 2835-2837. |
| [15] | D. Vergara, K. H. White, K. G. Keepers, et al. The complete chloroplast genomes of Cannabis sativa and Humulus lupulus, Mitochondrial DNA Part A: DNA mapping, sequencing, and analysis, 27 (2016), 3793-3794. |
| [16] |
Y. Wang, K. Hill, S. Singh, et al. The spectrum of genomic signatures: from dinucleotides to chaos game representation, Gene, 346 (2005), 173-185. doi: 10.1016/j.gene.2004.10.021
|
| [17] |
J-Y. Yang, Z-L. Peng, Y. Zu-Guo, et al. Prediction of protein structural classes by recurrence quantification analysis based on chaos game representation, J. Theor. Biol., 257 (2009), 618-626. doi: 10.1016/j.jtbi.2008.12.027
|
| [18] |
Y. Zu-Guo, V. Anh, K-S. Lau, Chaos game representation of protein sequences based on the detailed HP model and their multifractal and correlation analyses, J. Theor. Biol., 226 (2004), 341-348. doi: 10.1016/j.jtbi.2003.09.009
|
| [19] | Y. Zu-Guo, X. Qian-Jun, S. Long, et al. Chaos game representation of functional protein sequences, and simulation and multifractal analysis of induced measures, Chinese Phys. B, 19 (2010), 68701. |
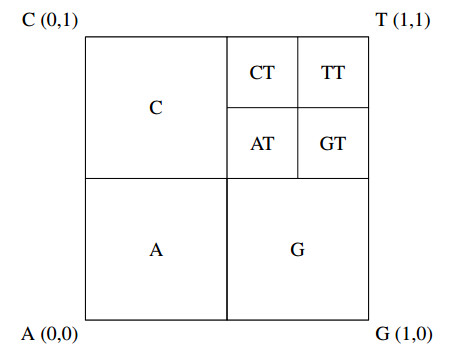
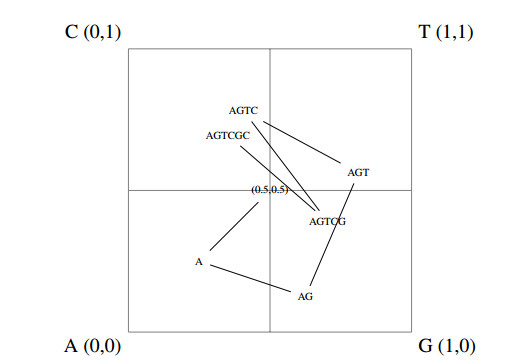

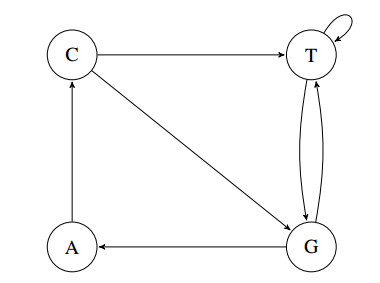
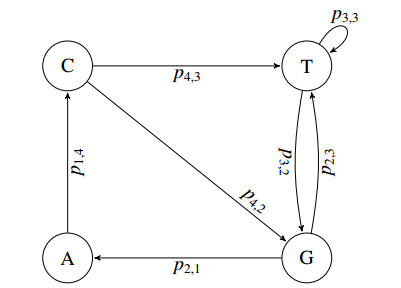






Figures(12) / Tables(1)

Martin Do Pham. Fractal approximation of chaos game representations using recurrent iterated function systems[J]. AIMS Mathematics, 2019, 5(6): 1824-1840. doi: 10.3934/math.2019.6.1824







 DownLoad:
DownLoad: