Citation: Carey Caginalp, Gunduz Caginalp. Establishing cryptocurrency equilibria through game theory[J]. AIMS Mathematics, 2019, 4(3): 420-436. doi: 10.3934/math.2019.3.420

| [1] | Z. Bernard, Everything you need to know about Bitcoin, its mysterious origins, and the many alleged identities of its creator, 2017. Available from: http://www.businessinsider.com/bitcoin-history-cyptocurrency-satoshi-nakamoto-2017-12. |
| [2] |
R. J. Barro, Rational expectations and the role of monetary policy, Journal of Monetary economics, 2 (1976), 1-32. doi: 10.1016/0304-3932(76)90002-7

|
| [3] |
R. J. Barro and D. B. Gordon, A Positive Theory of Monetary Policy in a Natural Rate Model, Journal of Political Economy, 91 (1983), 589-610. doi: 10.1086/261167
|
| [4] | Z. Bodie, A. Kane and A. J. Marcus, Essentials of Investments 9th Edition. McGraw-Hill, 2012. |
| [5] | R. M. Bratspies, Cryptocurrency and the Myth of the Trustless Transaction, 2018. Available from: https://ssrn.com/abstract=3141605 or http://dx.doi.org/10.2139/ssrn.3141605. |
| [6] |
C. Brunetti, B. Büyükşahin and J. H. Harris, Speculators, Prices, and Market Volatility, Journal of Financial and Quantitative Analysis, 51 (2016), 1545-1574. doi: 10.1017/S0022109016000569
|
| [7] | C. Caginalp, A Dynamical Systems Approach to Cryptocurrency Stability, arXiv preprint: 1805.03143, 2018. |
| [8] |
G. Caginalp and D. Balenovich, Asset flow and momentum: deterministic and stochastic equations, Philosophical Transactions of the Royal Society of London A: Mathematical, Physical and Engineering Sciences, 357 (1999), 2119-2133. doi: 10.1098/rsta.1999.0421
|
| [9] |
C. Caginalp and G. Caginalp, Opinion: Valuation, liquidity price, and stability of cryptocurrencies, Proceedings of the National Academy of Sciences, 115 (2018), 1131-1134. doi: 10.1073/pnas.1722031115
|
| [10] |
G. Caginalp, D. Porter and V. Smith, Initial cash/asset ratio and asset prices: An experimental study, Proceedings of the National Academy of Sciences, 95 (1998), 756-761. doi: 10.1073/pnas.95.2.756
|
| [11] |
G. Caginalp, D. Porter and V. Smith, Financial bubbles: Excess cash, momentum, and incomplete information, The Journal of Psychology and Financial Markets, 2 (2001), 80-99. doi: 10.1207/S15327760JPFM0202_03
|
| [12] | G. Camera, A Perspective on Electronic Alternatives to Traditional Currencies, Sveriges Riksbank Economic Review, 1 (2017), 126-148. Available from: https://ssrn.com/abstract=2902721. |
| [13] | C. F. Camerer, Behavioral game theory: Experiments in strategic interaction, Princeton University Press, 2011. |
| [14] | G. Camera and M. Casari, The Coordination Value of Monetary Exchange: Experimental Evidence, American Economic Journals: Microeconomics (Forthcoming), 2013. Available from: https://ssrn.com/abstract=1463350. |
| [15] | R. Clements, Assessing the Evolution of Cryptocurrency: Demand Factors, Latent Value and Regulatory Developments, Michigan Business and Entrepreneurial Law Review, 2018. Available from: https://ssrn.com/abstract=3117635 or http://dx.doi.org/10.2139/ssrn.3117635. |
| [16] | U. W. Chohan, The Problems of Cryptocurrency Thefts and Exchange Shutdowns, 2018. Available from: https://ssrn.com/abstract=3131702 or http://dx.doi.org/10.2139/ssrn.3131702. |
| [17] | R. Curran, Why Bitcoin's bubble matters, The Wall Street Journal, 2017. Available from: https://www.wsj.com/articles/why-bitcoins-bubble-matters-1507515361. |
| [18] | D. Fudenberg and J. Tirole, Game theory, MIT Press, Cambridge, Massachusetts, 1991. |
| [19] |
R. Garratt and N. Wallace, Bitcoin 1, Bitcoin 2 ....: An experiment in privately issued outside monies, Economic Inquiry, 56 (2018), 1887-1897. doi: 10.1111/ecin.12569
|
| [20] | P. Gillespie, 'Death spiral:' 4,000% inflation in Venezuela, CNN, 2017. Available from: http://money.cnn.com/2017/11/22/ news/economy/venezuela-currency-crash/index.html. |
| [21] | B. Graham, The intelligent investor: A book of practical counsel, 1965. |
| [22] | B. Graham and B. McGowan, The intelligent investor, Harper Collins, 2005. |
| [23] | M. Iwamura, Y. Kitamura, T. Matsumoto, et al. Can We Stabilize the Price of a Cryptocurrency?: Understanding the Design of Bitcoin and Its Potential to Compete with Central Bank Money, Understanding the Design of Bitcoin and Its Potential to Compete with Central Bank Money (October 25, 2014), 2014. |
| [24] | S. Jafari, T. Vo-Huu, B. Jabiyev, et al. Cryptocurrency: A Challenge to Legal System, 2018. |
| [25] | A. M. Kane, An eco-friendly Ecash with recycled banknotes, arXiv preprint arXiv:1806.05711, 2018. |
| [26] | Y. Liu and A. Tsyvinski, Risks and Returns of Cryptocurrency No. w24877, National Bureau of Economic Research, 2018. Available from: https://ssrn.com/abstract=3226952 or http://dx.doi.org/10.2139/ssrn.3226952. |
| [27] | D. G. Luenberger, Investment science, OUP Catalogue, 2013. |
| [28] | V. Mazalov, Mathematical game theory and applications, John Wiley and Sons, 2014. |
| [29] | P. Milgrom and J. Roberts, Rationalizability, learning, and equilibrium in games with strategic complementarities, Econometrica: Journal of the Econometric Society, (1990), 1255-1277. |
| [30] | M. Okur, Ö. Çatıkkaş and P. Kaya, Long Memory in the Volatility of Selected Cryptocurrencies: Bitcoin, Ethereum and Ripple, Preprint, 2018. |
| [31] |
D. P. Porter and V. L. Smith, Stock market bubbles in the laboratory, Applied mathematical finance, 1 (1994), 111-128. doi: 10.1080/13504869400000008
|
| [32] | R. Price, Someone in 2010 bought 2 pizzas with 10,000 bitcoins - which today would be worth $100 million, 2017. Available from: http://www.businessinsider.com/bitcoin-pizza-10000-100-million-2017-11}. |
| [33] | K. Rapoza, Struggling nations think cryptocurrencies will save them, Forbes, 2018. Available from: https://www.forbes.com/sites/kenrapoza/2018/02/26/struggling-nations-think-cryptocurrencies-will-save-them/#3b4605a47da6. |
| [34] | O. Romanchenko, O. Shemetkova, V. Piatanova, et al. Approach of Estimation of the Fair Value of Assets on a Cryptocurrency Market, The 2018 International Conference on Digital Science (pp. 245-253), Springer, Cham, 2018. |
| [35] | V. Smith, Bargaining and market behavior: essays in experimental economics, Cambridge University Press, 2005. |
| [36] | V. L. Smith, G. L. Suchanek and A. W. Williams, Bubbles, crashes, and endogenous expectations in experimental spot asset markets, Econometrica: Journal of the Econometric Society, (1988), 1119-1151. |
| [37] | O. Schlotmann, S. Ulreich and I. Zippe, Bitcoin: Quo Vadis? a Forecast Based on Estimated Production Costs and Investor Preferences, 2018. Available from: https://ssrn.com/abstract=3291543 or http://dx.doi.org/10.2139/ssrn.3291543. |
| [38] | G. White, The millions of Americans without bank accounts, The Atlantic, 2017. Available from: https://www.theatlantic.com/business/archive/2016/10/fdic-underbanked-cfpb/504881/. |
| [39] | D. H. Wolpert, M. Harre, E. Olbrich, et al. Hysteresis effects of changing the parameters of noncooperative games, Phys. Rev. E, 85 (2012), 036102. |
| [40] | K. Wu, S. Wheatley and D. Sornette, Classification of cryptocurrency coins and tokens by the dynamics of their market capitalizations, Roy. Soc. Open Sci., 5 (2018), 180381. |
| [41] | K. Wu, Financial Markets in Natural Experiments, Field Experiments, Lab Experiments and Real Life, Doctoral dissertation, ETH Zurich, 2018. |
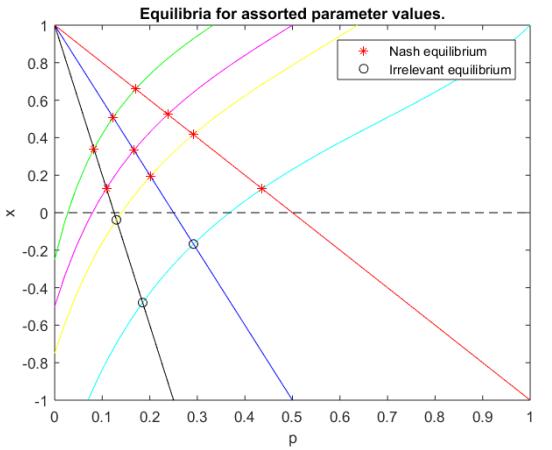
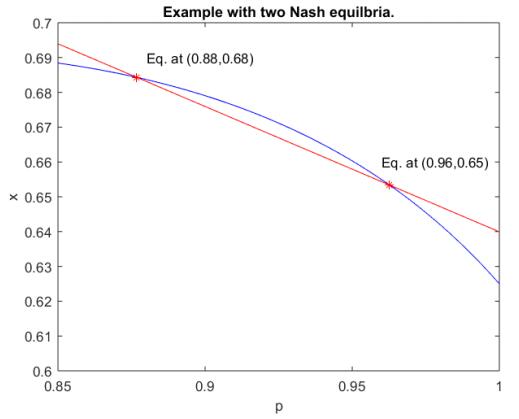
Figures(2)

Carey Caginalp, Gunduz Caginalp. Establishing cryptocurrency equilibria through game theory[J]. AIMS Mathematics, 2019, 4(3): 420-436. doi: 10.3934/math.2019.3.420







 DownLoad:
DownLoad: