Citation: David Melkuev, Danqiao Guo, Tony S. Wirjanto. Applications of random-matrix theory and nonparametric change-point analysis to three notable systemic crises[J]. Quantitative Finance and Economics, 2018, 2(2): 413-467. doi: 10.3934/QFE.2018.2.413

| [1] | lez R, Bouchaud JP (2011) Individual and collective stock dynamics: intraday seasonalities. New J Phys 13: 345–349. |
| [2] |
Anderson TW (1963) Asymptotic theory for principal component analysis. Ann Math Stat 34: 122– 148. doi: 10.1214/aoms/1177704248

|
| [3] | Andersson E, Bock D, Fris´en M (2004) Detection of turning points in business cycles. J Bus Cycle Manage Anal 1: 93–108. |
| [4] |
Andersson E, Bock D, Fris´en M (2006) Some statistical aspects of methods for detection of turning points in business cycles. J Appl Stat 33: 257–278. doi: 10.1080/02664760500445517
|
| [5] |
Andrews DWK, Lee I, Ploberger W (1996) Optimal changepoint tests for normal linear regression. J Econometrics 70: 9–38. doi: 10.1016/0304-4076(94)01682-8
|
| [6] |
Ang A, Chen J (2002) Asymmetric correlations of equity portfolios. J Financ Econ 63: 443–494. doi: 10.1016/S0304-405X(02)00068-5
|
| [7] | Bai Z, Zhou W (2008) Large sample covariance matrices without independence structures in columns. Stat Sinica 18: 425–442. |
| [8] | Bai ZD, Silverstein JW (2010) Spectral Analysis of Large Dimensional Random Matrices, Second Edition, Springer, New York. |
| [9] | Basserville M, Nikiforov I (1993) Detection of Abrupt Changes: Theory and Applications. Prentice- Hall, Englewood Cli_s, NJ. |
| [10] | Beibel M, Lerche HR (2000) A new look at optimal stopping problems related to mathematical finance. Stat Sinica 7: 93–108. |
| [11] | Bejan A (2005) Largest eigenvalues and sample covariance matrices. M.Sc. dissertation, Department of Statistics, The University of Warwick. |
| [12] | Berkes I, Gombay E, Horv´ath L, et al. (2004) Sequential change-point detection in GARCH(p,q) models. Economet Theor 20: 1140–1167. |
| [13] |
Biely C, Thurner S (2008) Random matrix ensembles of time-lagged correlation matrices: derivation of eigenvalue spectra and analysis of financial time-series. Quant Financ 8: 705–722. doi: 10.1080/14697680701691477
|
| [14] | Bijlsma M, Klomp J, Duineveld S (2010) Systemic risk in the financial sector: A review and synthesis. CPB Netherland Bureau of Economic Policy Analysis Paper 210. |
| [15] |
Billio M, Getmansky M, Lo AW, et al. (2012) Econometric measures of connectedness and systemic risk in the finance and insurance sectors. J Financ Economet 104: 535–559. doi: 10.1016/j.jfineco.2011.12.010
|
| [16] |
Bouchaud JP, Potters M (2001) More stylized facts of financial markets: leverage effect and downside correlations. Physica A 299: 60–70. doi: 10.1016/S0378-4371(01)00282-5
|
| [17] | Broemling LD, Tsurumi H (1987) Econometrics and Structural Change, Marcel Dekker, New York. |
| [18] | Capuano C (2008) The option-iPoD. The probability of default implied by option prices based on entropy. IMF. |
| [19] |
Chen J, Gupta AK (1997) Testing and locating variance change-points with application to stock prices. J Am Stat Assoc 92: 739–747. doi: 10.1080/01621459.1997.10474026
|
| [20] |
Chordia T, Swaminathan B (2000) Trading volume and cross-autocorrelations in stock returns. J Financ 55: 913–935. doi: 10.1111/0022-1082.00231
|
| [21] |
Cizeau P, Potters M, Bouchaud JP (2001) Correlation structure of extreme stock returns. Quant Financ 1: 217–222. doi: 10.1080/713665669
|
| [22] |
Conlon T, Ruskin HJ, Crane M (2009) Cross-correlations dynamics in financial time series. Physica A 388: 705–714. doi: 10.1016/j.physa.2008.10.047
|
| [23] |
Constantine AG (1963) Some non-central distribution problems in multivariate analysis. Ann Math Stat 34: 1270–1285. doi: 10.1214/aoms/1177703863
|
| [24] |
Daniel K, Moskowitz T (2016) Momentum crashes. J Financ Econ 122: 221–247. doi: 10.1016/j.jfineco.2015.12.002
|
| [25] |
Davis RA, Pfa_el O, Stelzer R (2014) Limit theory for the largest eigenvalue of sample covariance matrices with heavy-tails. Stoch Proc Appl 124: 18–50. doi: 10.1016/j.spa.2013.07.005
|
| [26] | De Brandt O, Hartmann P (2000) Systemic risk: A survey. European Central Bank. |
| [27] | Dickey DA, Fuller WA (1979) Distribution of the estimators for autoregressive time series with a unit root. J Am Stat Assoc 74: 427–431. |
| [28] |
Dimson E (1979) Risk measurement when shares are subject to infrequent trading. J Financ Econ 7: 197–226. doi: 10.1016/0304-405X(79)90013-8
|
| [29] | Doris D (2014) Modeling Systemic Risk in the Options Market. Ph.D. Thesis, Department of Mathematics, New York University, New York, NY. |
| [30] |
Drożdż S, Grumer F, Ruf F, et al. (2000) Dynamics of competition between collectivity and noise in the stock market. Physica A 287: 440–449. doi: 10.1016/S0378-4371(00)00383-6
|
| [31] | Edelman A, Persson PO (2005) Numerical methods for eigenvalue distributions of random matrices. Math . |
| [32] |
Edelman A, Rao NR (2005) Random matrix theory. Acta Numer 14: 233–297. doi: 10.1017/S0962492904000236
|
| [33] | Franses PH, van Dijk D (2000) Non-Linear Time Series Models in Empirical Finance. Cambridge University Press, New York, NY. |
| [34] |
Geman S (1980) A limit theorem for the norm of random matrices. Ann Probab 8: 252–261. doi: 10.1214/aop/1176994775
|
| [35] |
Gopikrishnan P, Rosenov B, Plerou V, et al. (2001) Quantifying and interpreting collective behavior in fnancial markets. Physi Rev E 64: 035106. doi: 10.1103/PhysRevE.64.035106
|
| [36] |
Granger CWJ (1969) Investigating causal relations by econometric models and cross-spectral methods. Econometrica 37: 424–438. doi: 10.2307/1912791
|
| [37] | International Monetary Fund (2009). Global Financial Stability Report; Responding to the Financial Crisis and Measuring Systemic Risks. Washington, D.C. |
| [38] | James AT (1960) The distribution of the latent roots of the covariance matrix. Ann Math Stati 32: 874–882. |
| [39] |
Jin B, Wang C, Miao B, et al. (2009) Limiting spectral distribution of large-dimensional sample covariance matrices generated by VARMA. J Multivariate Anal 100: 2112–2125. doi: 10.1016/j.jmva.2009.06.011
|
| [40] |
Jobst AA (2013) Multivariate dependence of implied volatilities from equity options as measure of systemic risk. International Review of Financial Analysis 28: 112–129. doi: 10.1016/j.irfa.2013.01.005
|
| [41] | Johnstone IM (2001) On the distribution of the largest eigenvalue in principal component analysis. Ann Stat 29: 295–327. |
| [42] | Kawahara Y, Yairi T, Machida K (2007) Change-point detection in time-series data based on subspace identification. Proceedings of the 7th IEEE International Conference on Data Mining, 559–564. |
| [43] |
Kritzman M, Li Y, Page S, et al. (2011) Principal components as a measure of systemic risk. J Portf Manage 37: 112–126. doi: 10.3905/jpm.2011.37.4.112
|
| [44] |
Kwiatkowski D, Phillips P, Schmidt P, et al. (1992) Testing the null hypothesis of stationarity against the alternative of a unit root: How sure are we that economic time series has a unit root? J Econometrics 54: 159–178. doi: 10.1016/0304-4076(92)90104-Y
|
| [45] |
Laloux L, Cizeau P, Bouchaud JP (1999) Noise Dressing of Financial Correlation Matrices. Phys Rev Lett 83: 1467–1469. doi: 10.1103/PhysRevLett.83.1467
|
| [46] |
Laloux L, Cizeau P, Potters M, et al. (2000) Random matrix theory and financial correlations. Int J Theor Appl Financ 3: 391–397. doi: 10.1142/S0219024900000255
|
| [47] |
Lequeux P, Menon M (2010) An eigenvalue approach to risk regimes in currency markets. J Deriv Hedge Funds 16: 123–135. doi: 10.1057/jdhf.2010.10
|
| [48] | Lewis M (2010) The Big Short: Inside the Doomsday Machine. W. W. Norton & Company Inc., New York, NY. |
| [49] |
Liu H, Aue A, Debashis P (2015) On the Marˇcenko-Pastur law for linear time series. Ann Stat 43: 675–712. doi: 10.1214/14-AOS1294
|
| [50] |
Liu S, Yamada M, Collier N, et al. (2013) Change-point detection in time-series data by relative densityratio estimation. Neural Networks 43: 72–83. doi: 10.1016/j.neunet.2013.01.012
|
| [51] | Longin F, Solnik B (2001) Extreme correlation of international equity markets. J Financ 5: 649–676. |
| [52] | Lorden G (1971) Procedures for reacting to a change in distribution, Ann Math Stat 42: 1897–1908. |
| [53] |
Marčenko VA, Pastur LA (1967) Distribution for some sets of random matrices. Math USSR-Sbornik 1: 457–483. doi: 10.1070/SM1967v001n04ABEH001994
|
| [54] | Mayya KBK, Amritkar RE (2006) Analysis of delay correlation matrices. Quant Financ. |
| [55] | Meng H, Xie WJ, Jiang ZQ, et al. (2014) Systemic risk and spatiotemporal dynamics of the US housing market. Sci Rep-UK 4: 3655. |
| [56] | Meric I, Kim S, Kim JH, et al. (2001) Co-movements of U.S., U.K., and Asian stock markets before and after September 11, 2001. J Money Invest Bank 3: 47–57. |
| [57] |
Moustakides GV (1986) Optimal stopping times for detecting changes in distributions. Ann Stat 14: 1379–1387. doi: 10.1214/aos/1176350164
|
| [58] | Muirhead RJ (1982) Aspects of Multivariate Statistical Theory, Wiley, New York. |
| [59] | Murphy KM, Topel RH (1985) Estimation and inference in two-step econometric models. J Bus Econ Stat 34: 370–379. |
| [60] |
Newey WK,West KD (1987) A Simple, Positive Semi-definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix. Econometrica 55: 703–708. doi: 10.2307/1913610
|
| [61] | NYSE Financial Index (2014) NYSE Euronex. Available from: http://www.nyse.com/about/listed/nykid.shtml. |
| [62] |
Page ES (1954) Continuous inspection schemes. Biometrika 41: 100–115. doi: 10.1093/biomet/41.1-2.100
|
| [63] | Pan RK, Sinha S (2007) Collective behavior of stock price movements in an emerging market. Phys Rev E 76: 1–9. |
| [64] |
Petterson M (1998) Monitoring a freshwater fish population: Statistical surveillance of biodiversity. Environmetrics 9: 139–150. doi: 10.1002/(SICI)1099-095X(199803/04)9:2<139::AID-ENV291>3.0.CO;2-3
|
| [65] |
Petzold M, Sonesson C, Bergman E, et al. (2004) Surveillance in longitudinal models: Detection of intrauterine growth restriction. Biometrics 60: 1025–1033. doi: 10.1111/j.0006-341X.2004.00258.x
|
| [66] |
Phillips P, Perron P (1988) Time series regression with a unit root. Biometrika 75: 335–346. doi: 10.1093/biomet/75.2.335
|
| [67] | Pillai KCS (1976a) Distribution of characteristic roots in multivariate analysis. Part I: Null distributions. Can J Stat 4: 157–184. |
| [68] | Pillai KCS (1976b) Distribution of characteristic roots in multivariate analysis. Part II: Non-null distributions. Can J Stat 5: 1–62. |
| [69] |
Plerou V, Gopikrishnan P, Rosenow B, et al. (2002) Random matrix approach to cross correlations in financial data. Phy Rev E 65: 066126. doi: 10.1103/PhysRevE.65.066126
|
| [70] | Poor V, Hadjiliadis O (2009) Quickest Detection, Cambridge University Press, New York, NY. |
| [71] | Preisendorfer RW (1988) Principal component analysis in meteorology and oceanography. North Holland, Amsterdam. |
| [72] |
Pukthuanthong K, Roll R (2009) Global market integration: An alternative measure and its application. J Financ Econ 94: 214–232. doi: 10.1016/j.jfineco.2008.12.004
|
| [73] |
Pukthuanthong K, Berger D (2012) Market Fragility and International Market Crashes. J Financ Econ 105: 565–580. doi: 10.1016/j.jfineco.2012.03.009
|
| [74] | Reinhart C, Rogoff K (2011) This Time Is Di_erent: Eight Centuries of Financial Folly. Princeton University Press, Princeton, New Jersey. |
| [75] | Fitch cuts Greece's issuer default ratings to 'RD'. (2012, March 9). Reuters. Available from: http://www.reuters.com/article/2012/03/09/idUSL2E8E97FN20120309. |
| [76] | Shiryaev AN (1978) Optimal Stopping Rules. Springer-Werlag, New York. |
| [77] | Shiryaev AN (2002) Quickest detection problems in the technical analysis of financial data. Mathematical Finance - Bachelier Congress, 2000 (Paris). Springer, Berlin, 487–521. |
| [78] |
Silverstein JW (1985) The smallest eigenvalue of large dimensional Wishart matrix. Ann Probab 13: 1364–1368. doi: 10.1214/aop/1176992819
|
| [79] |
Silverstein JW (1995) Strong convergence of the empirical distribution of eigenvalues of largedimensional random matrices. J Multivariate Anal 55: 331–339. doi: 10.1006/jmva.1995.1083
|
| [80] | Smith R, Sidel R (2010). Banks keep failing, no end in sight. Wall Street J. Available from: http://online.wsj.com/news/articles/SB20001424052748704760704575516272337762044. |
| [81] |
Solnik B, Boucrelle C, Le Fu Y (1996) International market correlation and volatility. Financ Anal J 52: 17–34. doi: 10.2469/faj.v52.n5.2021
|
| [82] | Sugiyama M, Suzuki T, Nakajima S, et al. (2008) Direct density ratio estimation in high-dimensional spaces, Ann I Stat Math 60: 699–746. |
| [83] |
Tartakovsky AG, Rozovskii BL, Blazek RB, et al. (2006) A novel approach to detection of intrusions in computer networks via adaptive sequential and batch-sequential change-point detection methods. IEEE T Signal Proces 54: 3372–3382. doi: 10.1109/TSP.2006.879308
|
| [84] | Thottan M, Ji C (2003) Anomaly detection in IP networks. IEEE T Signal Proces 15: 2191–2204. |
| [85] | Thurner S, Biely C (2007) The eigenvalue spectrum of lagged correlation matrices. Acta Phys Pol B 38: 4111–4122. |
| [86] |
Tracy CA, Widom H (1996) On orthogonal and symplectic matrix ensembles. Commun Math Phys 177: 727–754. doi: 10.1007/BF02099545
|
| [87] |
Trivedi R, Chandramouli R (2005) Secret key estimation in sequential steganography, IEEE T Signal Proces 53: 746–757. bibitemTulino2004 Tulino AM, Verd S (2004) Random Matrix Theory and Wireless Communications. Found Trend Commun Inf Theory 1: 1–182. doi: 10.1561/0100000001
|
| [88] | Wetherhill GB, Brown DW (1991) Statistical Process Control. Chapman and Hall, London. |
| [89] |
White H (1980) A heteroskedasticity-consistent covariance matrix estimator and a direct test for heteroskedasticity. Econometrica 48: 817–838. doi: 10.2307/1912934
|
| [90] |
Wigner EP (1955) Characteristic vectors of bordered matrices with infinite dimensions. Ann Math 62: 548–564. doi: 10.2307/1970079
|
| [91] | Wishart J (1928) The generalized product moment distribution in samples from a normal multivariate population. Biometrika 20: 32–52. |
| [92] | Yamada M, Kimura A, Naya F, et al. (2013) Change-point detection with feature selection in highdimensional time-series data. Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence 171: 1827–1833. |
| [93] | Yao JF (2012) A note on a Marˇcenko-Pastur type theorem for time series. Stat Probab Letter 82: 20–28. |
| [94] | Zhang M, Kolkiewicz AW,Wirjanto TS, et al. (2015) The impacts of financial crisis on sovereign credit risk analysis in Asia and Europe. Int J Financ Eng 2: 143–152. |
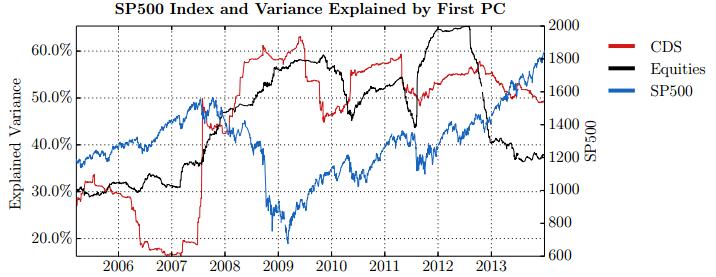
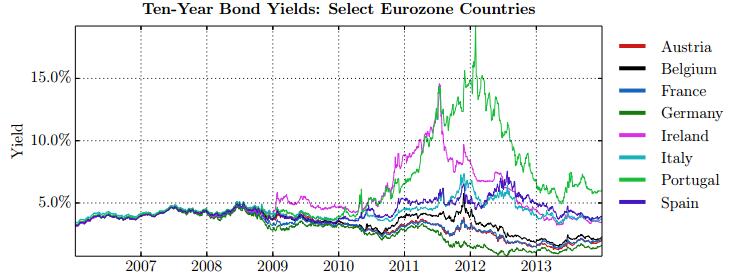
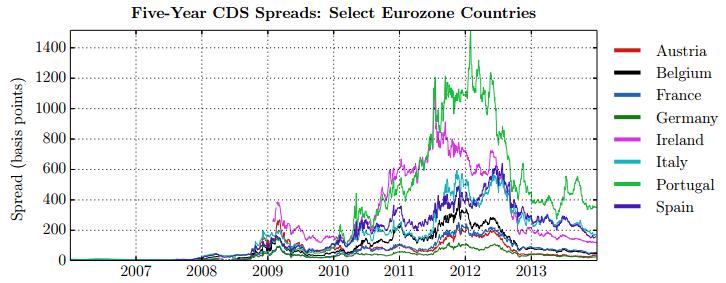
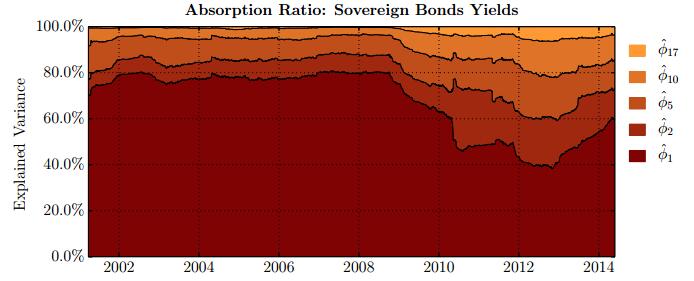
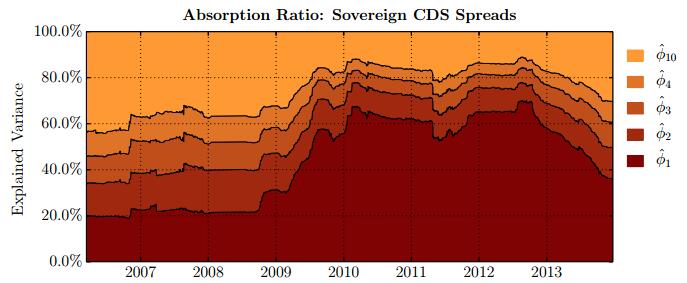
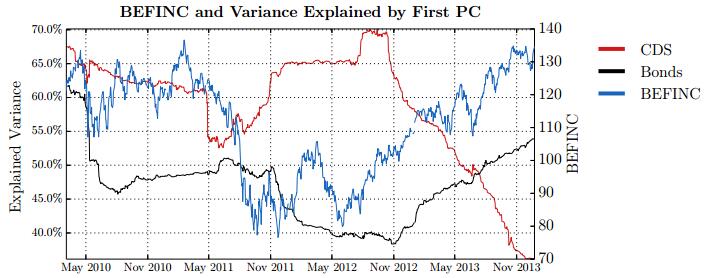
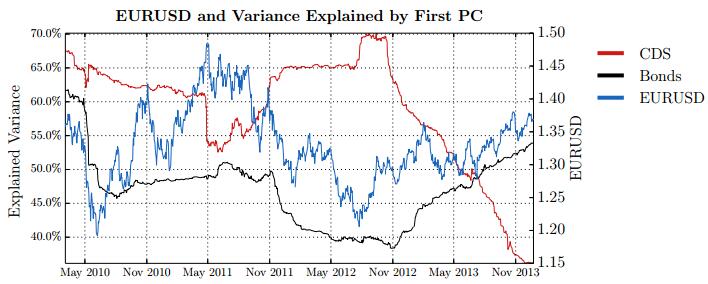
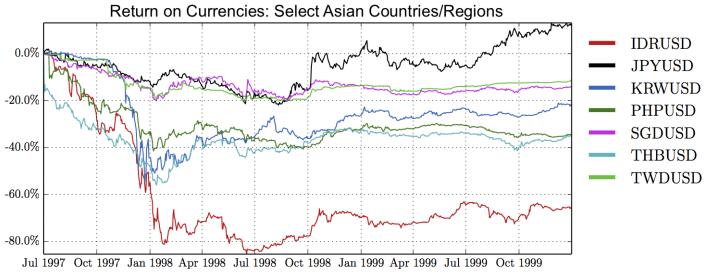
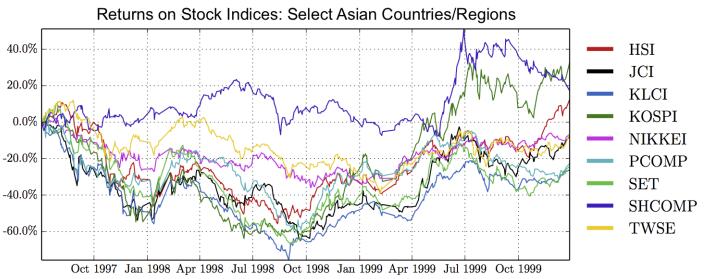
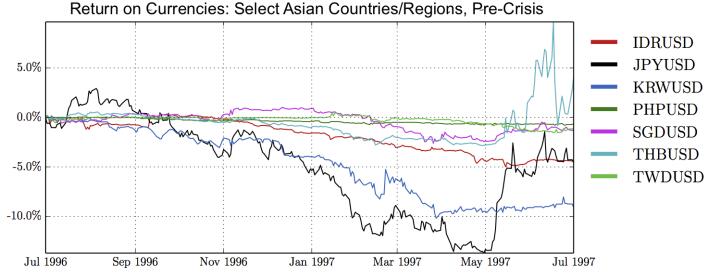
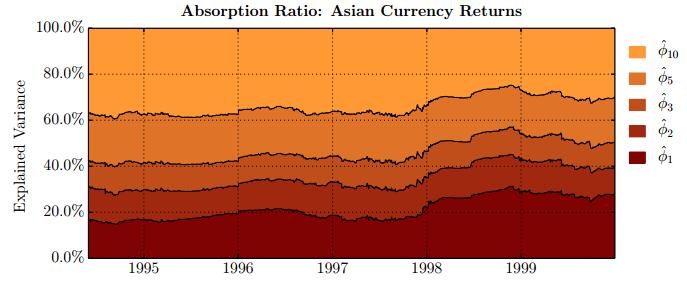
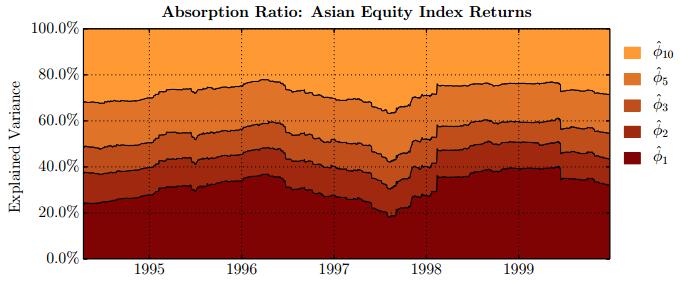
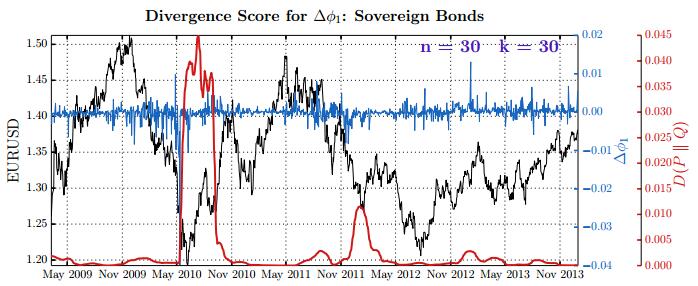
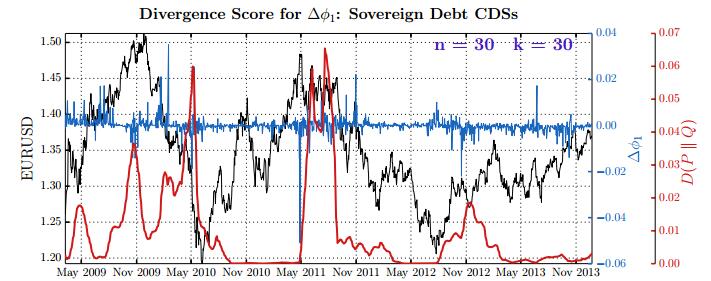
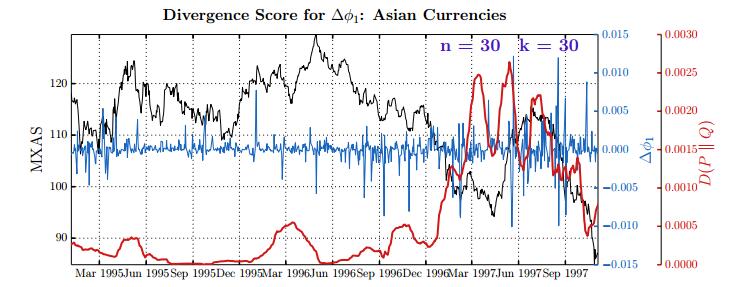
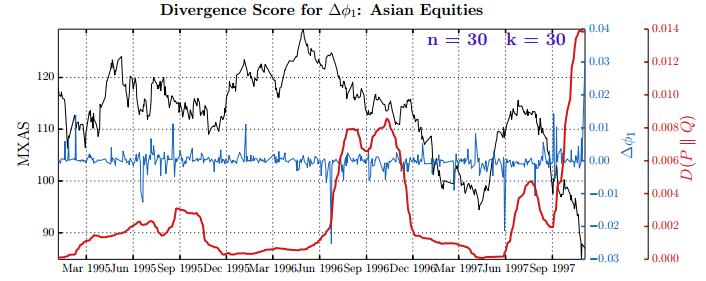
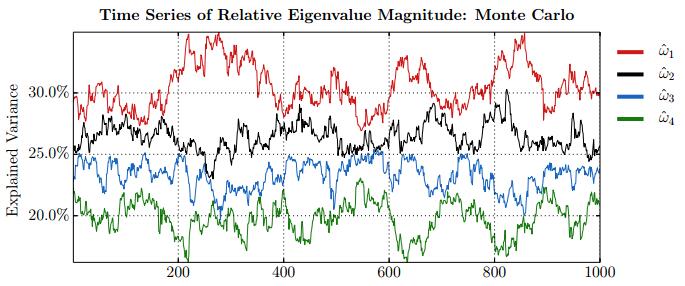
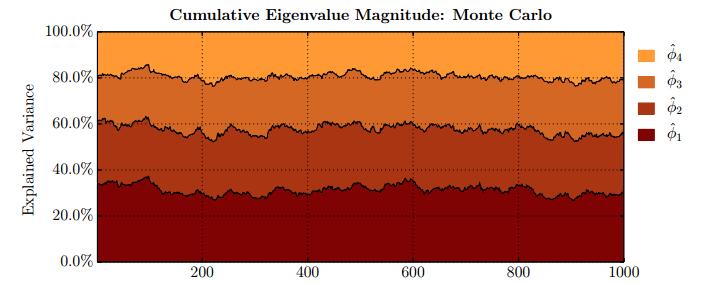
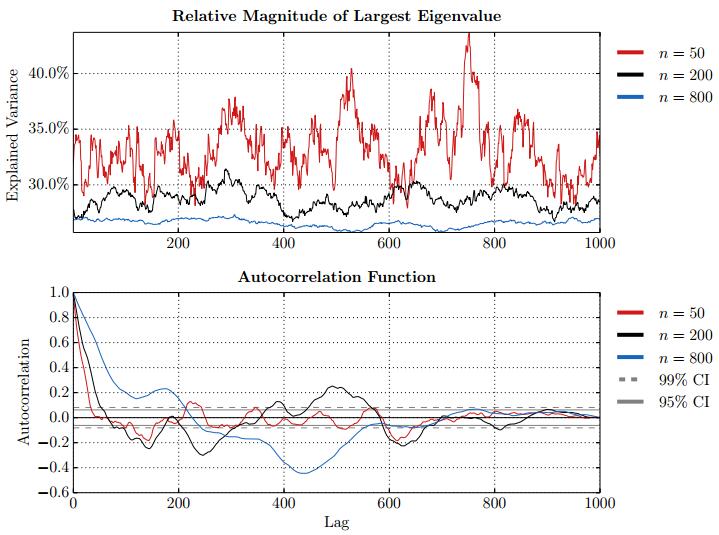
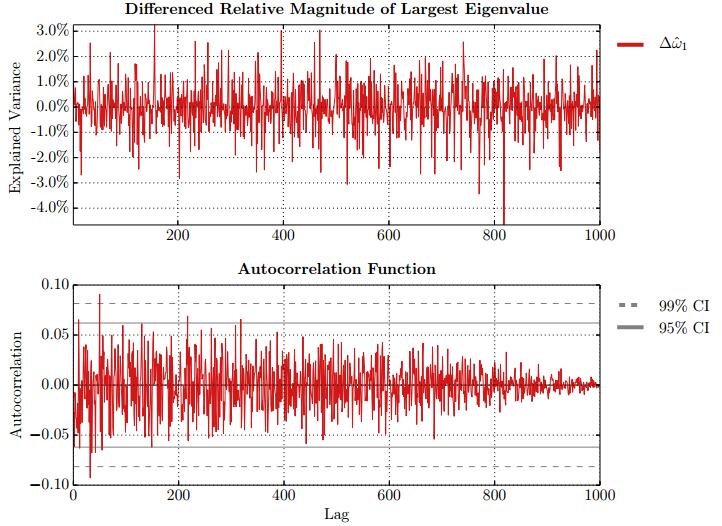
Figures(28) / Tables(15)

David Melkuev, Danqiao Guo, Tony S. Wirjanto. Applications of random-matrix theory and nonparametric change-point analysis to three notable systemic crises[J]. Quantitative Finance and Economics, 2018, 2(2): 413-467. doi: 10.3934/QFE.2018.2.413







 DownLoad:
DownLoad: