Influence maximization (IM), a central issue in optimizing information diffusion on social platforms, aims to spread posts or comments more widely, rapidly, and efficiently. Existing studies primarily focus on the positive effects of incorporating heuristic calculations in IM approaches. However, heuristic models fail to consider the potential enhancements that can be achieved through network representation learning techniques. Some recent work is keen to use representation learning to deal with IM issues. However, few in-depth studies have explored the existing challenges in IM representation learning, specifically regarding the role characteristics and role representations. This paper highlights the potential advantages of combining heuristic computing and role embedding to solve IM problems. First, the method introduces role granularity classification to effectively categorize users into three distinct roles: opinion leaders, structural holes and normal nodes. This classification enables a deeper understanding of the dynamics of users within the network. Second, a novel role-based network embedding (RbNE) algorithm is proposed. By leveraging the concept of node roles, RbNE captures the similarity between nodes, allowing for a more accurate representation of the network structure. Finally, a superior IM approach, named RbneIM, is recommended. RbneIM combines heuristic computing and role embedding to establish a fusion-enhanced IM solution, resulting in an improved influence analysis process. Exploratory outcomes on six social network datasets indicate that the proposed approach outperforms state-of-the-art seeding algorithms in terms of maximizing influence. This finding highlights the effectiveness and efficacy of the proposed method in achieving higher levels of influence within social networks. The code is available at https://github.com/baiyazi/IM2.
Citation: Xu Gu, Zhibin Wang, Xiaoliang Chen, Peng Lu, Yajun Du, Mingwei Tang. Influence maximization in social networks using role-based embedding[J]. Networks and Heterogeneous Media, 2023, 18(4): 1539-1574. doi: 10.3934/nhm.2023068
Influence maximization (IM), a central issue in optimizing information diffusion on social platforms, aims to spread posts or comments more widely, rapidly, and efficiently. Existing studies primarily focus on the positive effects of incorporating heuristic calculations in IM approaches. However, heuristic models fail to consider the potential enhancements that can be achieved through network representation learning techniques. Some recent work is keen to use representation learning to deal with IM issues. However, few in-depth studies have explored the existing challenges in IM representation learning, specifically regarding the role characteristics and role representations. This paper highlights the potential advantages of combining heuristic computing and role embedding to solve IM problems. First, the method introduces role granularity classification to effectively categorize users into three distinct roles: opinion leaders, structural holes and normal nodes. This classification enables a deeper understanding of the dynamics of users within the network. Second, a novel role-based network embedding (RbNE) algorithm is proposed. By leveraging the concept of node roles, RbNE captures the similarity between nodes, allowing for a more accurate representation of the network structure. Finally, a superior IM approach, named RbneIM, is recommended. RbneIM combines heuristic computing and role embedding to establish a fusion-enhanced IM solution, resulting in an improved influence analysis process. Exploratory outcomes on six social network datasets indicate that the proposed approach outperforms state-of-the-art seeding algorithms in terms of maximizing influence. This finding highlights the effectiveness and efficacy of the proposed method in achieving higher levels of influence within social networks. The code is available at https://github.com/baiyazi/IM2.

| [1] |
J. Gu, G. Li, N. D. Vo, J. J. Jung, Contextual Word2Vec model for understanding chinese out of vocabularies on online social media, Int. J. Semant. Web. Inf. Syst., 18 (2022), 1–14. https://doi.org/10.4018/ijswis.309428 doi: 10.4018/ijswis.309428

|
| [2] | G. Manal, Social media data for the conservation of historic urban landscapes: Prospects and challenges, in Culture and Computing. Design Thinking and Cultural Computing (eds. M. Rauterberg), Springer, (2021), 209–223. https://doi.org/10.1007/978-3-030-77431-8_13 |
| [3] | J. Zhao, L. Yang, X. Yang, Maximum profit of viral marketing: An optimal control approach, in Proceedings of the 2019 4th International Conference on Mathematics and Artificial Intelligence, Association for Computing Machinery, (2019), 209–214. https://doi.org/10.1145/3325730.3325767 |
| [4] | D. Pedro, R. Matt, Mining the network value of customers, in Proceedings of the seventh ACM SIGKDD international conference on Knowledge discovery and data mining, Association for Computing Machinery, (2001), 57–66. https://doi.org/10.1145/502512.502525 |
| [5] | X. Song, B. L. Tseng, C. Lin, M. Sun, Personalized recommendation driven by information flow, in Proceedings of the 29th annual international ACM SIGIR conference on Research and development in information retrieval, Association for Computing Machinery, (2006), 509–516. https://doi.org/10.1145/1148170.1148258 |
| [6] |
Y. Li, D. Zhang, K. Tan, Real-time targeted influence maximization for online advertisements, Proc. VLDB Endow., 8 (2015), 1070–1081. https://doi.org/10.14778/2794367.2794376 doi: 10.14778/2794367.2794376
|
| [7] | L. Simone, M. Diego, R. Giuseppe, M. Maurizio, Mining micro-influencers from social media posts, in Proceedings of the 35th Annual ACM Symposium on Applied Computing, Association for Computing Machinery, (2020), 867–874. https://doi.org/10.1145/3341105.3373954 |
| [8] |
X. Zhou, S. Li, Z. Li, W. Li, Information diffusion across cyber-physical-social systems in smart city: a survey, Neurocomputing, 444 (2021), 203–213. https://doi.org/10.1016/j.neucom.2020.08.089 doi: 10.1016/j.neucom.2020.08.089
|
| [9] |
V. Soroush, M. Mostafa, R. Deb, Rumor gauge: predicting the veracity of rumors on Twitter, ACM Trans. Knowl. Discov. Data, 11 (2017), 1–36. https://doi.org/10.1145/3070644 doi: 10.1145/3070644
|
| [10] |
S. R. Sahoo, B. B. Gupta, Multiple features based approach for automatic fake news detection on social networks using deep learning, Appl. Soft Comput., 100 (2021), 106983. https://doi.org/10.1016/j.asoc.2020.106983 doi: 10.1016/j.asoc.2020.106983
|
| [11] | D. Kempe, J. Kleinberg, E. Tardos, Maximizing the spread of influence through a social network, in Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Association for Computing Machinery, (2003), 137–146. https://doi.org/10.1145/956750.956769 |
| [12] |
A. G. Cecilia, B. Manuel, T. M. Valentina, An agent-based social simulation for citizenship competences and conflict resolution styles, Int. J. Semant. Web Inf. Syst., 18 (2022), 1–23. https://doi.org/10.4018/IJSWIS.306749 doi: 10.4018/IJSWIS.306749
|
| [13] | Y. Rong, Q. Zhu, H. Cheng, A model-free approach to infer the diffusion network from event cascade, in Proceedings of the 25th ACM International on Conference on Information and Knowledge Management, Association for Computing Machinery, (2016), 1653–1662. https://doi.org/10.1145/2983323.2983718 |
| [14] | S. Galhotra, A. Arora, S. Virinchi, S. Roy, Asim: A scalable algorithm for influence maximization under the independent cascade model, in Proceedings of the 24th International Conference on World Wide Web, Association for Computing Machinery, (2015), 35–36. https://doi.org/10.1145/2740908.2742725 |
| [15] |
A. Cetto, M. Klier, A. Richter, J. F. Zolitschka, "Thanks for sharing"—Identifying users' roles based on knowledge contribution in Enterprise Social Networks, Comput. Net., 135 (2018), 275–288. https://doi.org/10.1016/j.comnet.2018.02.012 doi: 10.1016/j.comnet.2018.02.012
|
| [16] |
L. Sopjani, J. J. Stier, S. Ritzén, M. Hesselgren, P. Georén, Involving users and user roles in the transition to sustainable mobility systems: The case of light electric vehicle sharing in Sweden, Transp. Res. Part D: Transp. Environ., 71 (2019), 207–221. https://doi.org/10.1016/j.trd.2018.12.011 doi: 10.1016/j.trd.2018.12.011
|
| [17] |
L. B. Jeppesen, K. Laursen, The role of lead users in knowledge sharing, Res. Policy, 38 (2009), 1582–1589. https://doi.org/10.1016/j.respol.2009.09.002 doi: 10.1016/j.respol.2009.09.002
|
| [18] |
I. Singh, N. Kumar, S. K. G., T. Sharma, V. Kumar, S. Singhal, Database intrusion detection using role and user behavior based risk assessment, J. Inf. Secur. Appl., 55 (2020), 102654. https://doi.org/10.1016/j.jisa.2020.102654 doi: 10.1016/j.jisa.2020.102654
|
| [19] | D. Kempe, J. M. Kleinberg, E. Tardos, Maximizing the spread of influence through a social network, in Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, Association for Computing Machinery, (2003), 137–146. https://doi.org/10.1145/956750.956769 |
| [20] | P. Shakarian, A. Bhatnagar, A. Aleali, E. Shaabani, R. Guo, The independent cascade and linear threshold models, in Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Association for Computing Machinery, (2015), 177–184. https://doi.org/10.1007/978-3-319-23105-1_4 |
| [21] | M. Richardson, P. Domingos, Mining knowledge-sharing sites for viral marketing, in Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining, Association for Computing Machinery, (2002), 61–70. https://doi.org/10.1145/775047.775057 |
| [22] | D. Oriedi, C. de Runz, Z. Guessoum, A. A. Nyongesa, Influence maximization through user interaction modeling, in Proceedings of the 35th Annual ACM Symposium on Applied Computing, Association for Computing Machinery, (2020), 1888–1890. https://doi.org/10.1145/3386901.3388999 |
| [23] | L. Sun, A. Chen, P. S. Yu, W. Chen, Influence maximization with spontaneous user adoption, in Proceedings of the 13th International Conference on Web Search and Data Mining, Association for Computing Machinery, (2020), 573–581. https://doi.org/10.1145/3336191.3371785 |
| [24] |
J. Guo, W. Wu, Adaptive influence maximization: if influential node unwilling to be the seed, ACM Trans. Knowl. Discov. Data, 15 (2021), 1–23. https://doi.org/10.1145/3447396 doi: 10.1145/3447396
|
| [25] | J. Luo, X. Liu, X. Kong, Competitive opinion maximization in social networks, in Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Association for Computing Machinery, (2019), 250–257. https://doi.org/10.1145/3341161.3342899 |
| [26] | Y. Zhang, Y. Zhang, Top-K influential nodes in social networks: A game perspective, in Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Association for Computing Machinery, (2017), 1029–1032. https://doi.org/10.1145/3077136.3080709 |
| [27] | X. Liu, X. Kong, P. S. Yu, Active ppinion maximization in social networks, Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Association for Computing Machinery, (2018), 1840–1849. https://doi.org/10.1145/3219819.3220061 |
| [28] | P. Banerjee, W. Chen, L. V.S. Lakshmanan, Maximizing welfare in social networks under a utility driven influence diffusion model, in Proceedings of the 2019 International Conference on Management of Data, Association for Computing Machinery, (2019), 1078–1095. https://doi.org/10.1145/3299869.3319879 |
| [29] |
M. M. Keikha, M. Rahgozar, M. Asadpour, M. F. Abdollahi, Influence maximization across heterogeneous interconnected networks based on deep learning, Expert Syst. Appl., 140 (2020). https://doi.org/10.1016/j.eswa.2019.112905 doi: 10.1016/j.eswa.2019.112905
|
| [30] |
Q. Zhan, W. Zhuo, Y. Liu, Social influence maximization for public health campaigns, IEEE Access, 7 (2019), 151252–151260. https://doi.org/10.1109/ACCESS.2019.2946391 doi: 10.1109/ACCESS.2019.2946391
|
| [31] |
S. Tian, S. Mo, L. Wang, Z. Peng, Deep reinforcement learning-based approach to tackle topic-aware influence maximization, Data Sci. Engineer., 5 (2020), 1–11. https://doi.org/10.1007/s41019-020-00117-1 doi: 10.1007/s41019-020-00117-1
|
| [32] | D. Li, J. Liu, J. Jeon, S. Hong, T. Le, D. Lee, et al., Large-scale data-rriven airline market influence maximization, in Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery & Data Mining, Association for Computing Machinery, (2021), 914–924. https://doi.org/10.1145/3447548.3467365 |
| [33] |
C. Zhang, W. Li, D. Wei, Y. Liu, Z. Li, Network dynamic GCN influence maximization algorithm with leader fake labeling mechanism, IEEE Trans. Comput. Soc. Syst., (2022), 1–9. https://doi.org/10.1109/TCSS.2022.3193583 doi: 10.1109/TCSS.2022.3193583
|
| [34] |
W. Li, Z. Li, A. M. Luvembe, C. Yang, Influence maximization algorithm based on Gaussian propagation model, Inf. Sci., 568 (2021), 386–402. https://doi.org/10.1016/j.ins.2021.04.061 doi: 10.1016/j.ins.2021.04.061
|
| [35] |
W. Li, Y. Li, W. Liu, C. Wang, An influence maximization method based on crowd emotion under an emotion-based attribute social network, Inf. Process. Manage., 59 (2022), 102818. https://doi.org/10.1016/j.ipm.2021.102818 doi: 10.1016/j.ipm.2021.102818
|
| [36] |
W. Li, Y. Hu, C. Jiang, S. Wu, Q. Bai, E. M. K. Lai, ABEM: an adaptive agent-based evolutionary approach for influence maximization in dynamic social networks, Appl. Soft Comput., 136 (2023), 110062. https://doi.org/10.1016/j.asoc.2023.110062 doi: 10.1016/j.asoc.2023.110062
|
| [37] |
H. Cai, V. W. Zheng, K. C. Chang, A comprehensive survey of graph embedding: Problems, techniques, and applications, IEEE Trans. Knowl. Data Engineer., 30 (2018), 1616–1637. https://doi.org/10.1109/TKDE.2018.2807452 doi: 10.1109/TKDE.2018.2807452
|
| [38] | B. Perozzi, R. Al-Rfou, S. Skiena, Deepwalk: online learning of social representations, in Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining, Association for Computing Machinery, (2014), 701–710. https://doi.org/10.1145/2623330.2623732 |
| [39] | J. Tang, M. Qu, M. Wang, M. Zhang, J. Yan, Q. Mei, Line: large-scale information network embedding, in Proceedings of the 24th international conference on World Wide Web, Association for Computing Machinery, (2015), 1067–1077. https://doi.org/10.1145/2736277.2741093 |
| [40] | A. Grover, J. Leskovec, node2vec: scalable feature learning for networks, in Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, Association for Computing Machinery, (2016), 855–864. https://doi.org/10.1145/2939672.2939754 |
| [41] | C. McCormick, Word2vec tutorial-the skip-gram model, 2016. Available from: http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model. |
| [42] |
M. M. Keikha, M. Rahgozar, M. Asadpour, Community aware random walk for network embedding, Knowledge-Based Syst., 148 (2018), 47–54. https://doi.org/10.1016/j.knosys.2018.02.028 doi: 10.1016/j.knosys.2018.02.028
|
| [43] | T. Lou, J. Tang, Mining structural hole spanners through information diffusion in social networks, in Proceedings of the 22nd international conference on World Wide Web, Association for Computing Machinery, (2013), 825–836. https://doi.org/10.1145/2488388.2488461 |
| [44] |
R. S. Burt, Structural holes and good ideas, Am. J. Soc., 110 (2004), 349–399. https://doi.org/10.1086/421787 doi: 10.1086/421787
|
| [45] | S. Wu, J. M. Hofman, W. A. Mason, D. J. Watts, Who says what to whom on Twitter, in Proceedings of the 20th International Conference on World Wide Web, WWW 2011, Association for Computing Machinery, (2011). https://doi.org/10.1145/1963405.1963504 |
| [46] | T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space, 2013. Available from: http://arXiv.org/abs/1301.3781. |
| [47] |
D. Lusseau, K. Schneider, O. J. Boisseau, P. Haase, E. Slooten, S. M. Dawson, The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations, Behav. Ecol. Soc., 54 (2003), 396–405. https://doi.org/10.1007/s00265-003-0651-y doi: 10.1007/s00265-003-0651-y
|
| [48] | A. L. Traud, P. J. Mucha, M. A. Porter, Social structure of Facebook networks, Phys. A, 391 (2012), 4165–4180. https://arXiv.org/1102.2166 |
| [49] | M. J. Newman, Finding community structure in networks using the eigenvectors of matrices, Phys. Rev. E, 74 (2006), 036104. https://arXiv.org/abs/physics/0605087v3 |
| [50] |
J. Leskovec, J. Kleinberg, C. Faloutsos, Graph evolution: Densification and shrinking diameters, ACM Trans. Knowl. Discovery Data, 1 (2007). https://doi.org/10.1145/1217299.1217301 doi: 10.1145/1217299.1217301
|
| [51] | B. Rozemberczki, R. Davies, R. Sarkar, C. Sutton, Gemsec: graph embedding with self clustering, in Proceedings of the 2019 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining 2019, Association for Computing Machinery, (2019), 65–72. https://doi.org/10.1145/3341161.3342890 |
| [52] | J. Zhang, Y. Luo, Degree centrality, betweenness centrality, and closeness centrality in social network, in Proceedings of the 2017 2nd International Conference on Modelling, Simulation and Applied Mathematics (MSAM2017), 132 (2017), 300–303. https://doi.org/10.2991/msam-17.2017.68 |
| [53] |
M. E. J. Newman, A measure of betweenness centrality based on random walks, Soc. Net., 27 (2005), 39–54. https://doi.org/10.1016/j.socnet.2004.11.009 doi: 10.1016/j.socnet.2004.11.009
|
| [54] |
D. F. Gleich, PageRank beyond the Web, SIAM Rev., 57 (2015), 321–363. https://doi.org/10.1137/140976649 doi: 10.1137/140976649
|
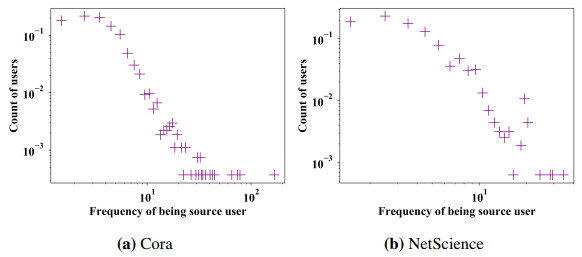
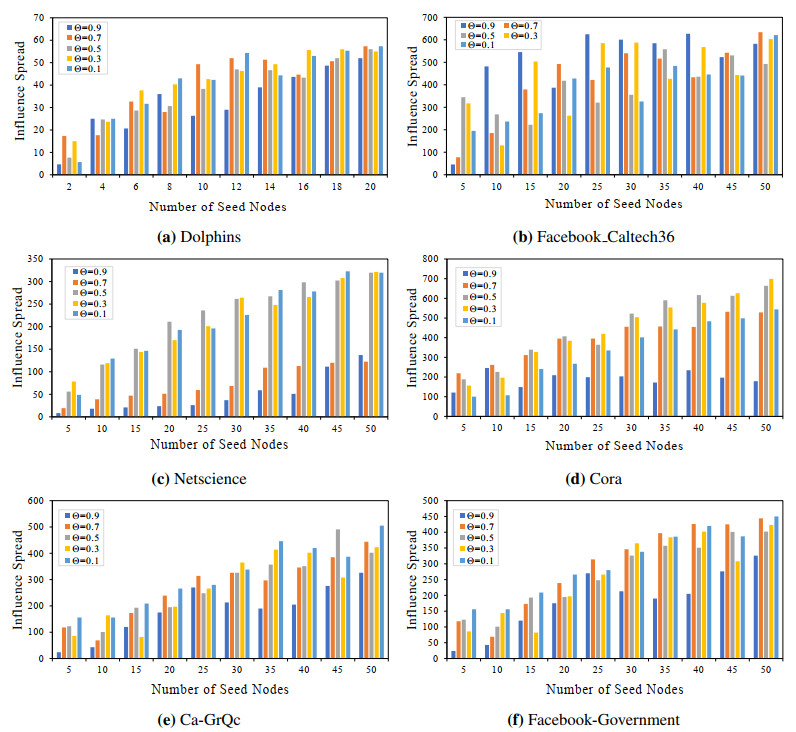
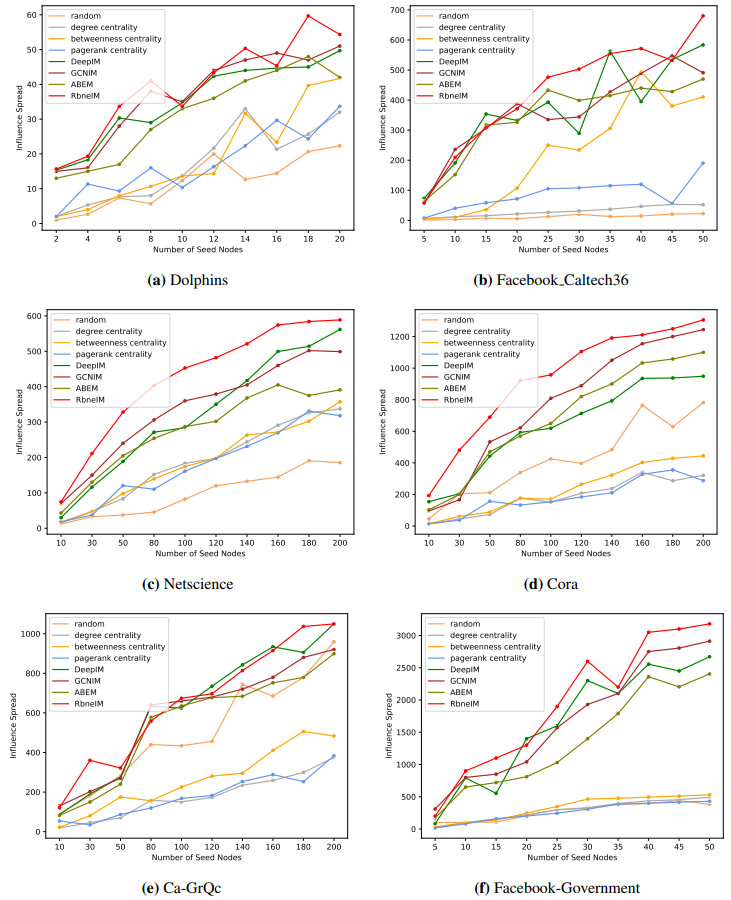
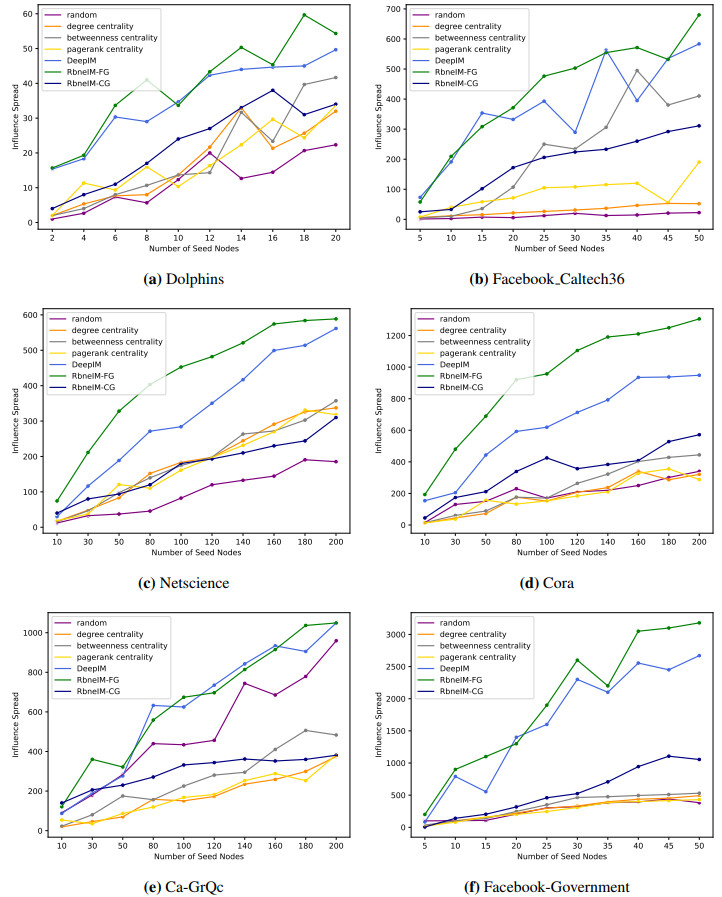
Figures(8) / Tables(8)
Xu Gu, Zhibin Wang, Xiaoliang Chen, Peng Lu, Yajun Du, Mingwei Tang. Influence maximization in social networks using role-based embedding[J]. Networks and Heterogeneous Media, 2023, 18(4): 1539-1574. doi: 10.3934/nhm.2023068







 DownLoad:
DownLoad: