Citation: Ke Guo, Wanbiao Ma. Global dynamics of an SI epidemic model with nonlinear incidence rate, feedback controls and time delays[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 643-672. doi: 10.3934/mbe.2021035

| [1] | R. M. Anderson, R. M. May, Infectious Diseases of Humans: Dynamics and Control, Oxford University Press, Oxford, 1992. |
| [2] | S. Busenberg, K. Cooke, Vertical Transmitted Diseases: Models and Dynamics, Biomathematics, Volume 23, Springer-Verlage, Berlin, 1993. |
| [3] | M. A. Nowak, R. M. May, Virus Dynamics: Mathematical Principles of Immunology and Virology, Oxford University Press, Oxford, 2000. |
| [4] | Z. Ma, Y. Zhou, W. Wang, Z. Jin, Mathematical Modeling and Research of Infectious Disease Dynamics, Science Press, Beijing, 2004. |
| [5] | L. Chen, Mathematical Ecological Models and Research Methods, Second Edition, Science Press, Beijing, 2017. |
| [6] | M. J. Keeling, P. Rohani, Modeling Infectious Diseases in Humans and Animals, Princeton University Press, New Jersey, 2008. |
| [7] | H. W. Hethcote, The mathematics of infectious disease, SIAM Rev., 42 (2000), 599–653. |
| [8] |
F. Bozkurt, A. Yousef, D. Baleanu, J. Alzabut, A mathematical model of the evolution and spread of pathogenic coronaviruses from natural host to human host, Chaos Solit. Fract., 138 (2020), 109931. doi: 10.1016/j.chaos.2020.109931

|
| [9] | M. De la Sen, R. P. Agarwal, A. Ibeas, S. Alonso-Quesada, On a generalized time-varying SEIR epidemic model with mixed point and distributed time-varying delays and combined regular and impulsive vaccination controls, Adv. Differ. Equations, 2010 (2010), 281612. |
| [10] | S. Gao, Z. Teng, D. Xie, The effects of pulse vaccination on SEIR model with two time delays, Appl. Math. Comput., 201 (2008), 282–292. |
| [11] | K. Gopalsamy, P. Weng, Feedback regulation of logistic growth, Int. J. Math. Sci., 16 (1993), 177–192. |
| [12] |
K. Gopalsamy, P. Weng, Global attractivity in a competition system with feedback controls, Comput. Math. Appl., 45 (2003), 665–676. doi: 10.1016/S0898-1221(03)00026-9
|
| [13] | H. Huo, W. Li, Positive periodic solutions of a class of delay differential system with feedback control, Appl. Math. Comput., 148 (2004), 35–46. |
| [14] |
G. Fan, Y. Li, M. Qin, The existence of positive periodic solutions for periodic feedback control systems with delays, ZAMM. Z. Angew. Math. Mech., 84 (2004), 425–430. doi: 10.1002/zamm.200310104
|
| [15] |
F. Chen, J. Yang, L. Chen, Note on the persistent property of a feedback control system with delays, Nonlinear Anal. Real World Appl., 11 (2010), 1061–1066. doi: 10.1016/j.nonrwa.2009.01.045
|
| [16] | C. Xu, P. Li, Almost periodic solutions for a competition and cooperation model of two enterprises with time-varying delays and feedback controls, J. Appl. Math. Comput., 53 (2017), 397411. |
| [17] |
L. Chen, J. Sun, Global stability of an SI epidemic model with feedback controls, Appl. Math. Lett., 28 (2014), 53–55. doi: 10.1016/j.aml.2013.09.009
|
| [18] | Y. Shang, Global stability of disease-free equilibria in a two-group SI model with feedback control, Nonlinear Anal. Model. Control, 22 (2015), 501–508. |
| [19] | H. Li, L. Zhang, Z. Teng, Y. Jiang, A. Muhammadhaji, Global stability of an SI epidemic model with feedback controls in a patchy environment, Appl. Math. Comput., 321 (2018), 372–384. |
| [20] | V. Capasso, G. Serio, A generalization of the Kermack-Mckendric deterministic epidemic model, Math. Biosci. 42 (1978), 43–61. |
| [21] |
S. Ruan, W. Wang, Dynamical behavior of an epidemic model with a nonlinear incidence rate, J. Differ. Equations, 188 (2003), 135–163. doi: 10.1016/S0022-0396(02)00089-X
|
| [22] |
D. Xiao, S. Ruan, Global analysis of an epidemic model with nonmonotone incidence rate, Math. Biosci., 208 (2007), 419–429. doi: 10.1016/j.mbs.2006.09.025
|
| [23] |
R. Xu, Z. Ma, Global stability of a SIR epidemic model with nonlinear incidence rate and time delay, Nonlinear Anal. Real World Appl., 10 (2009), 3175–3189. doi: 10.1016/j.nonrwa.2008.10.013
|
| [24] |
R. Xu, Z. Ma, Stability of a delayed SIRS epidemic model with a nonlinear incidence rate, Chaos Solit. Fract., 41 (2009), 2319–2325. doi: 10.1016/j.chaos.2008.09.007
|
| [25] | C. C. McCluskey Global stability for an SIR epidemic model with delay and nonlinear incidence, Nonlinear Anal. Real World Appl., 11 (2010), 3106–3109. |
| [26] |
Y. Chen, S. Zou, J. Yang, Global analysis of an SIR epidemic model with infection age and saturated incidence, Nonlinear Anal. Real World Appl., 30 (2016), 16–31. doi: 10.1016/j.nonrwa.2015.11.001
|
| [27] | Q. Cui, Z. Qiu, W. Liu, Z. Hu, Complex dynamics of an SIR epidemic model with nonlinear saturate incidence and recovery rate, Entropy, 19 (2017), 305. |
| [28] |
J. P. Tripathi, S. Abbas, Global dynamics of autonomous and nonautonomous SI epidemic models with nonlinear incidence rate and feedback controls, Nonlinear Dyn., 86 (2016), 337–351. doi: 10.1007/s11071-016-2892-0
|
| [29] | J. Hale, S. M. Verduyn Lunel, Introduction to Functional Differential Equations, Springer Verlag, New York, 1993. |
| [30] | Y. Kuang, Delay Differential Equations with Applications in Population Dynamics, Academic Press, Boston, 1993. |
| [31] | J. Wei, H. Wang, W. Jiang, Bifurcation Theory and Application of Delay Differential Equations, Science Press, Beijing, 2012. |
| [32] | O. Diekmann, J. A. P. Heesterbeek, J. A. J. Metz, On the definition and the computation of the basic reproduction ratio R0 in models for infectious diseases in heterogeneous populations, J. Math. Biol., 28 (1990), 365–382. |
| [33] |
P. van den Driessche, J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission, Math. Biosci., 180 (2002), 29–48. doi: 10.1016/S0025-5564(02)00108-6
|
| [34] | K. L. Cooke, Z. Grossman, Discrete delay, distributed delay and stability switches, J. Math. Anal. Appl., 86 (1982), 592–627. |
| [35] | Y. Saito, T. Hara, W. Ma, Necessary and sufficient conditions for permanence and global stability |
| [36] | K. Gopalsamy, Stability and Oscallations in Delay Differential Equations of Population Dynamics, Kluwer Academic Publishers, Netherlands, 1992. |
| [37] | I. Barbǎlat, Systemes d'equations differentielle d'oscillations nonlineaires, Rev. Roumaine Math. Pures Appl., 4 (1959), 267–270. |
| [38] |
J. Alzabut, Almost periodic solutions for an impulsive delay Nicholson's blowflies model, J. Comput. Appl. Math., 234 (2010), 233–239. doi: 10.1016/j.cam.2009.12.019
|
| [39] | H. Zhou, J. Alzabut, S. Rezapour, M. E. Samei, Uniform persistence and almost periodic solutions of a non-autonomous patch occupancy model, Adv. Differ. Equation, 2020 (2020), 143. |
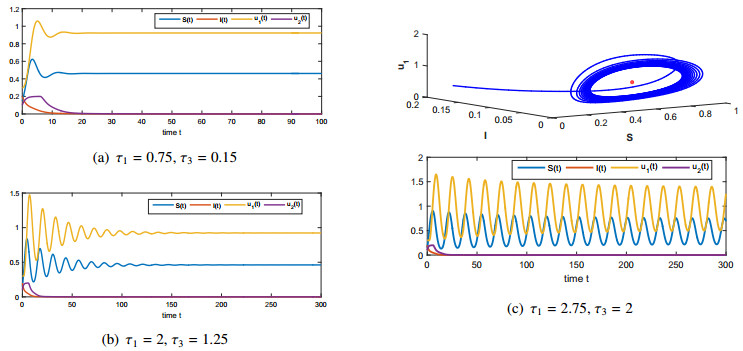
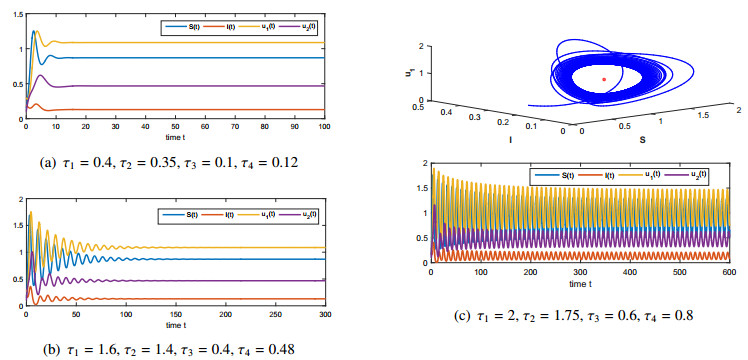
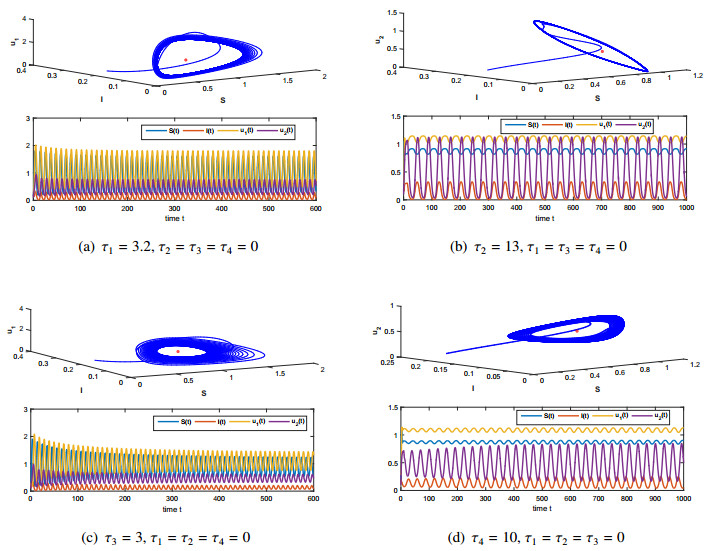
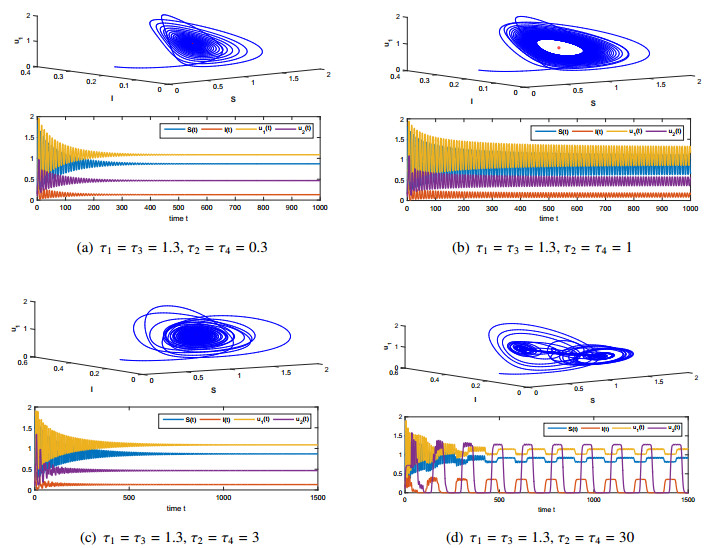
Figures(4)

Ke Guo, Wanbiao Ma. Global dynamics of an SI epidemic model with nonlinear incidence rate, feedback controls and time delays[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 643-672. doi: 10.3934/mbe.2021035







 DownLoad:
DownLoad: