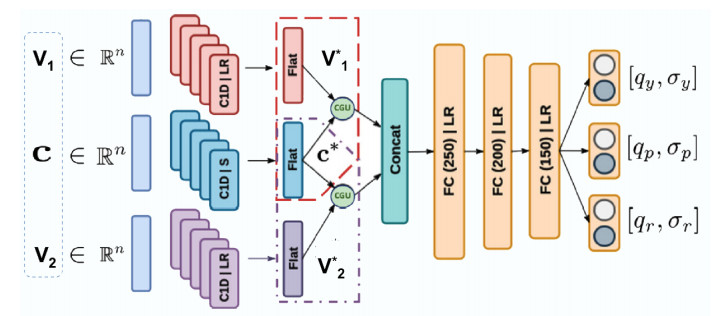
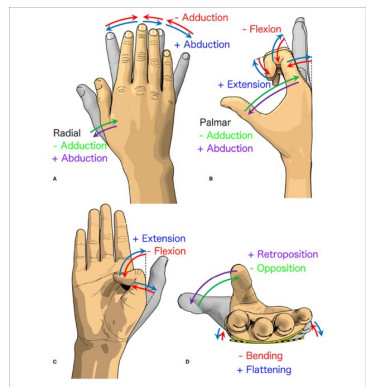
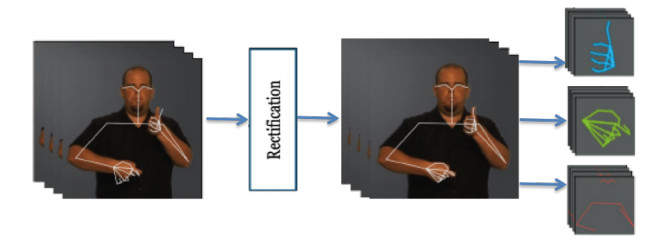
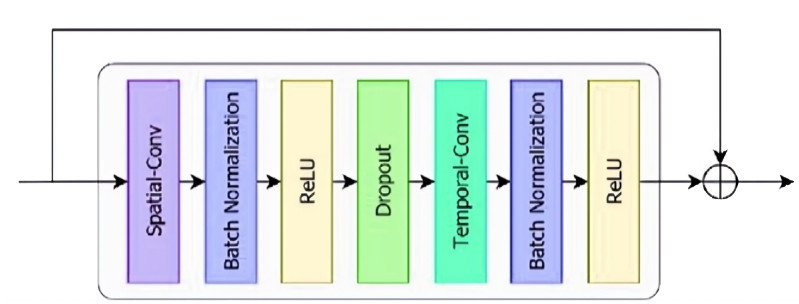
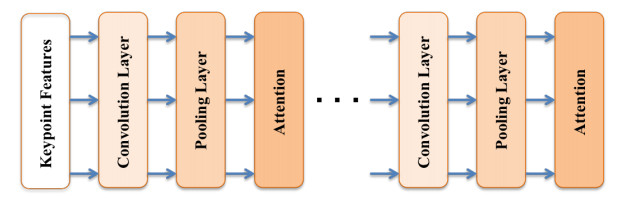
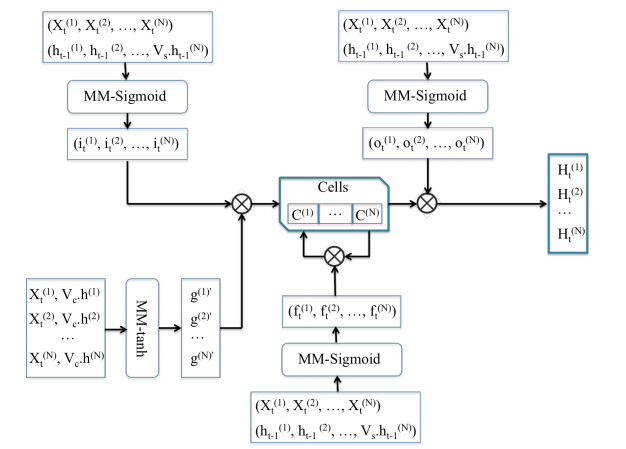
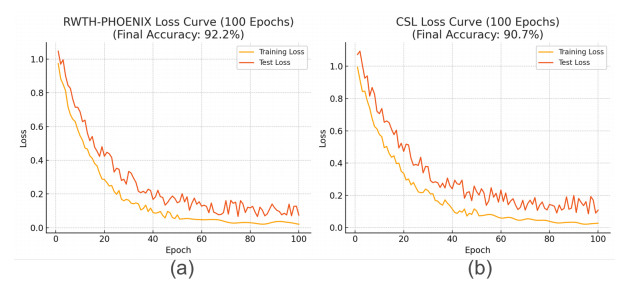
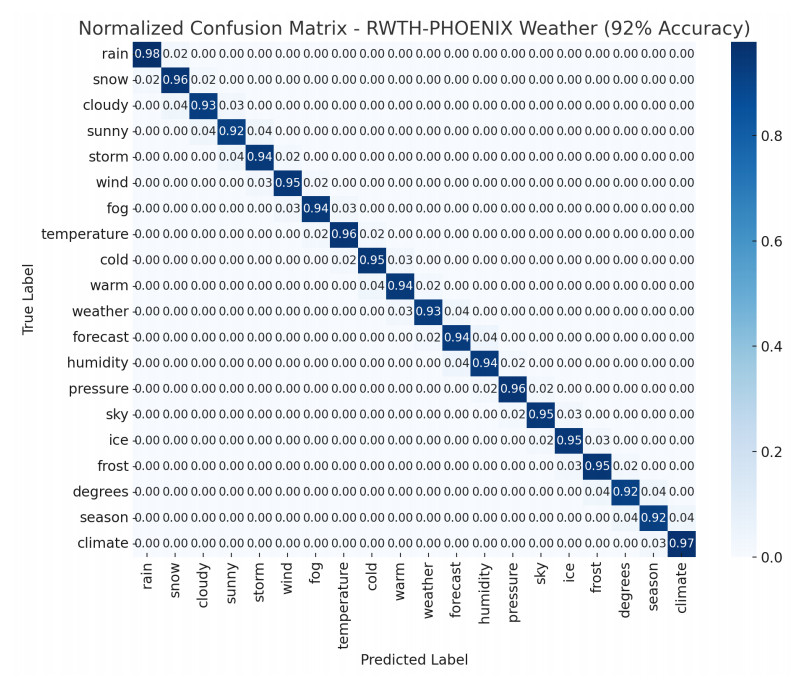
The quality of recognition systems for sign language utterances has significantly improved in recent years for the benefit of hearing-impaired people. Nevertheless, research initiatives frequently overlook particular linguistic characteristics of sign languages, such as nonmanual utterances. Nonmanual articulations are an essential element of all sign languages. They encompass not only many elements of facial expression but also ocular gaze, as well as the position of the head and the upper body movements. This study assessed the efficacy of a recognition system utilizing a single video camera about nonmanual features. We presented a two-stage pipeline utilizing 2D body joint locations derived from red, green, blue (RGB) camera data. The initial pipeline examined heteroscedastic head pose network (HHP-net), a technique for calculating head direction from individual frames utilizing a HHP-net to ascertain an individual's head position from a limited number of head keypoints. In the second pipeline, we presented a kinematic hand pose rectification method for enforcing constraints to enhance the realism of hand skeletal representations. Next, we examined spatial-temporal graph convolutional networks and multi-modal long short-term memory to use multi-articulatory information (e.g., body, right hand, and left hand) for the recognition of sign glosses. We trained an spatiotemporal graph convolutional network (ST-GCN) model to learn representations from the upper body and hands. The suggested method was subsequently assessed using two publicly available datasets, the RWTH-PHOENIX-Weather and the Chinese sign language (CSL), featuring a range of nonmanual utterances. By examining several data forms and network characteristics, we identified word segments with 92.8% accuracy from the underlying body joint movement data. The research showed a 17.8% word error rate for whole sentence predictions, a significant improvement from ground truth scores based on labeling that ignored nonmanual content.
Citation: Maher Jebali, Lamia Trabelsi, Haifa Harrouch, Rabab Triki, Shawky Mohamed. Development of deep learning-based models highlighting the significance of non-manual features in sign language recognition[J]. AIMS Mathematics, 2025, 10(9): 20084-20112. doi: 10.3934/math.2025898
The quality of recognition systems for sign language utterances has significantly improved in recent years for the benefit of hearing-impaired people. Nevertheless, research initiatives frequently overlook particular linguistic characteristics of sign languages, such as nonmanual utterances. Nonmanual articulations are an essential element of all sign languages. They encompass not only many elements of facial expression but also ocular gaze, as well as the position of the head and the upper body movements. This study assessed the efficacy of a recognition system utilizing a single video camera about nonmanual features. We presented a two-stage pipeline utilizing 2D body joint locations derived from red, green, blue (RGB) camera data. The initial pipeline examined heteroscedastic head pose network (HHP-net), a technique for calculating head direction from individual frames utilizing a HHP-net to ascertain an individual's head position from a limited number of head keypoints. In the second pipeline, we presented a kinematic hand pose rectification method for enforcing constraints to enhance the realism of hand skeletal representations. Next, we examined spatial-temporal graph convolutional networks and multi-modal long short-term memory to use multi-articulatory information (e.g., body, right hand, and left hand) for the recognition of sign glosses. We trained an spatiotemporal graph convolutional network (ST-GCN) model to learn representations from the upper body and hands. The suggested method was subsequently assessed using two publicly available datasets, the RWTH-PHOENIX-Weather and the Chinese sign language (CSL), featuring a range of nonmanual utterances. By examining several data forms and network characteristics, we identified word segments with 92.8% accuracy from the underlying body joint movement data. The research showed a 17.8% word error rate for whole sentence predictions, a significant improvement from ground truth scores based on labeling that ignored nonmanual content.

| [1] |
I. Alam, A. Hameed, R. A. Ziar, Exploring sign language detection on smartphones: A systematic review of machine and deep learning approaches, Adv. Hum. Comput. Interact., 2024 (2024). https://doi.org/10.1155/2024/1487500 doi: 10.1155/2024/1487500

|
| [2] | J. Dodandeniya, G. Dayananda, S. Hewagama, W. Dela, W. Dinuka, K. Sanvitha, Visual kids: Interactive learning application for hearing-impaired primary school kids in Sri Lanka, In: 2023 5th International conference on advancements in computing (ICAC), 2023,846–851. https://doi.org/10.1109/ICAC60630.2023.10417450 |
| [3] | S. Aswathi, G. Nagappan, A deep learning driven flask level enhanced web application for efficient communication system, In: 2024 IEEE International conference on computing, power and communication technologies (IC2PCT), 2024, 1207–1210. |
| [4] |
M. Jebali, A. Dakhli, W. Bakari, Deep learning-based sign language recognition system using both manual and nonmanual components fusion, AIMS Mathematics, 9 (2023), 2105–2122. http://dx.doi.org/10.3934/math.2024105 doi: 10.3934/math.2024105
|
| [5] | M. Marais, D. Brown, J. Connan, A. Boby, Spatiotemporal convolutions and video vision transformers for signer-independent sign language recognition, In: 2023 International conference on artificial intelligence, big data, computing and data communication systems (icABCD), 2023, 1–6. https://doi.org/10.1109/icABCD59051.2023.10220534 |
| [6] | H. Fu, L. Zhang, B. Fu, R. Zhao, J. Su, X. Shi, et al., Signer diversity-driven data augmentation for signer-independent sign language translation, In: Findings of the association for computational linguistics: NAACL 2024, 2024, 2182–2193. https://doi.org/10.18653/v1/2024.findings-naacl.140 |
| [7] | A. Moryossef, Z. Jiang, M. Müller, S. Ebling, Y. Goldberg, Linguistically motivated sign language segmentation, In: Findings of the association for computational linguistics: EMNLP 2023, 2023, 12703–12724. https://doi.org/10.18653/v1/2023.findings-emnlp.846 |
| [8] |
S. Siddique, S. Islam, E. E. Neon, T. Sabbir, I. T. Naheen, R. Khan, Deep learning-based Bangla sign language detection with an edge device, Intell. Syst. Appl., 18 (2023), 200224. https://doi.org/10.1016/j.iswa.2023.200224 doi: 10.1016/j.iswa.2023.200224
|
| [9] | R. Sivaraman, S Santiago, K. Chinnathambi, S. Sarkar, S. SN, S. Srimathi, Sign language recognition using improved Seagull optimization algorithm with deep learning model, In: 2024 Second international conference on intelligent cyber physical systems and internet of things (ICoICI), 2024, 1566–1571. https://doi.org/10.1109/ICoICI62503.2024.10696047 |
| [10] |
Pranav, R. Katarya, Effi-CNN: real-time vision-based system for interpretation of sign language using CNN and transfer learning, Multimed. Tools Appl., 84 (2025), 3137–3159. https://doi.org/10.1007/s11042-024-20585-1 doi: 10.1007/s11042-024-20585-1
|
| [11] |
Y. Nakamura, L. Jing, Skeleton-based data augmentation for sign language recognition using adversarial learning, IEEE Access, 13 (2024), 15290–15300. https://doi.org/10.1109/ACCESS.2024.3481254 doi: 10.1109/ACCESS.2024.3481254
|
| [12] | S. Liu, Q. Xiao, A signer-independent sign language recognition system based on the weighted KNN/HMM, In: 2015 7th International conference on intelligent human-machine systems and cybernetics, 2025,186–189. https://doi.org/10.1109/IHMSC.2015.71 |
| [13] | B. P. Kumar, M. Manjunatha, Performance analysis of KNN, SVM and ANN techniques for gesture recognition system, Indian J. Sci. Technol., 9 (2016), 1–8. |
| [14] | I. Sandjaja, A. Alsharoa, D. Wunsch, J. Liu, Survey of hidden Markov models (HMMs) for sign language recognition (SLR), In: 2024 IEEE 7th International conference on industrial cber-physical systems (ICPS), 2024, 1–6. https://doi.org/10.1109/ICPS59941.2024.10640040 |
| [15] | N. A. Sarhan, Y. El-Sonbaty, S. M. Youssef, HMM-based Arabic sign language recognition using Kinect, In: 2015 Tenth international conference on digital information management (ICDIM), 2015,169–174. https://doi.org/10.1109/ICDIM.2015.7381873 |
| [16] |
M. Jebali, A. Dakhli, M. Jemni, Vision-based continuous sign language recognition using multimodal sensor fusion, Evol. Syst., 12 (2021), 1031–1044. https://doi.org/10.1007/s12530-020-09365-y doi: 10.1007/s12530-020-09365-y
|
| [17] |
R. Rastgoo, K. Kiani, S. Escalera, Hand sign language recognition using multi-view hand skeleton, Expert Syst. Appl., 150 (2020), 11336. https://doi.org/10.1016/j.eswa.2020.113336 doi: 10.1016/j.eswa.2020.113336
|
| [18] | J. Pu, W. Zhou, H. Li, Iterative alignment network for continuous sign language recognition, In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), 2019, 4165–4174. |
| [19] |
O. Koller, S. Zargaran, H. Ney, R. Bowden, Deep sign: Enabling robust statistical continuous sign language recognition via hybrid CNN-HMMs, Int. J. Comput. Vis., 126 (2018), 1311–1325. https://doi.org/10.1007/s11263-018-1121-3 doi: 10.1007/s11263-018-1121-3
|
| [20] |
R. Cui, H. Liu, C. Zhang, A deep neural framework for continuous sign language recognition by iterative training, IEEE Trans. Multimed., 21 (2019), 1880–1891. https://doi.org/10.1109/TMM.2018.2889563 doi: 10.1109/TMM.2018.2889563
|
| [21] | D. Guo, W. Zhou, H. Li, M. Wang, Hierarchical LSTM for sign language translation, In: Proceedings of the AAAI conference on artificial intelligence, 32 (2018). |
| [22] | J. Cai, N. Jiang, X. Han, K. Jia, J. Lu, JOLO-GCN: Mining joint-centered light-weight information for skeleton-based action recognition, In: Proceedings of the IEEE/CVF winter conference on applications of computer vision (WACV), 2021, 2735–2744. |
| [23] |
J. Shin, A. Matsuoka, Md. Al M. Hasan, A. Y. Srizon, American sign language alphabet recognition by extracting feature from hand pose estimation, Sensors, 21 (2021), 5856. https://doi.org/10.3390/s21175856 doi: 10.3390/s21175856
|
| [24] | O. Yusuf, M. Habib, M. Moustafa, Real-time hand gesture recognition: Integrating skeleton-based data fusion and multi-stream CNN, arXiv: 2406.15003, 2024. https://doi.org/10.48550/arXiv.2406.15003 |
| [25] |
S. Narayan, A. P. Mazumdar, S. K. Vipparthi, SBI-DHGR: Skeleton-based intelligent dynamic hand gestures recognition, Expert Syst. Appl., 232 (2023), 120735. https://doi.org/10.1016/j.eswa.2023.120735 doi: 10.1016/j.eswa.2023.120735
|
| [26] | G. Mei, Z. Cao, G. Wang, End-to-End mmWave-based human pose estimation from raw signal, In: Proceedings of 2024 Chinese intelligent systems conference, 2024,132–140. https://doi.org/10.1007/978-981-97-8654-1_15 |
| [27] | S. Yan, Y. Xiong, D. Lin, Spatial temporal graph convolutional networks for Skeleton-Based Action Recognition, In: Proceedings of the AAAI conference on artificial intelligence, 32 (2018). |
| [28] | B. Tang, K. Zhang, W. Luo, W. Liu, H. Li, Prompting future driven diffusion model for hand motion prediction, In: Computer vision – ECCV 2024, 2024,169–186. https://doi.org/10.1007/978-3-031-72667-5_10 |
| [29] | A. Desai, L. Berger, F. O. Minakov, V. Milan, C. Singh, K. Pumphre, ASL citizen: A community-sourced dataset for advancing isolated sign language recognition, In: 37th Conference on neural information processing systems (NeurIPS 2023), 2023. |
| [30] |
W. Zhao, H. Hu, W. Zhou, Y. Mao, M. Wang, H. Li, MASA: Motion-aware masked autoencoder with semantic alignment for sign language recognition, IEEE Trans. Circuits Syst. Video Technol., 34 (2024), 10793–10804. https://doi.org/10.1109/TCSVT.2024.3409728 doi: 10.1109/TCSVT.2024.3409728
|
| [31] | Y. Yang, Y. Min, X. Chen, S2Net: Skeleton-aware slowFast network for efficient sign language recognition, In: Proceedings of the Asian conference on computer vision (ACCV), 2024,319–336. |
| [32] | K. Cheng, Y. Zhang, C. Cao, L. Shi, J. Cheng, H. Lu, Decoupling GCN with DropGraph module for skeleton-based action recognition, In: Computer vision – ECCV 2020, Cham: Springer, 2020,536–553. https://doi.org/10.1007/978-3-030-58586-0_32 |
| [33] | Y. Song, Z. Zhang, C. Shan, L. Wang, Stronger, faster and more explainable: A graph convolutional baseline for skeleton-based action recognition, In: Proceedings of the 28th ACM international conference on multimedia, 2020, 1625–1633. https://doi.org/10.1145/3394171.3413802 |
| [34] |
M. Al-Hammadi, M. A. Bencherif, M. Alsulaiman, G. Muhammad, M. A. Mekhtiche, W. Abdul, et al., Spatial attention-based 3D graph convolutional neural network for sign language recognition, Sensors, 22 (2022), 4558. https://doi.org/10.3390/s22124558 doi: 10.3390/s22124558
|
| [35] | C. Lugaresi, J. Tang, H. Nash, C. McClanahan, E. Uboweja, M. Hays, et al., MediaPipe: A framework for building perception pipelines, arXiv: 1906.08172, 2019. https://doi.org/10.48550/arXiv.1906.08172 |
| [36] |
M. Geetha, N. Aloysius, D. A. Somasundaran, A. Raghunath, P. Nedungadi, Towards real-time recognition of continuous Indian sign language: A multi-modal approach using RGB and pose, IEEE Access, 13 (2025), 60270–60283. https://doi.org/10.1109/ACCESS.2025.3554618 doi: 10.1109/ACCESS.2025.3554618
|
| [37] |
M. Guan, Y. Wang, G. Ma, J. Liu, M. Sun, MSKA: Multi-stream keypoint attention network for sign language recognition and translation, Pattern Recognit., 165 (2025), 11602. https://doi.org/10.1016/j.patcog.2025.111602 doi: 10.1016/j.patcog.2025.111602
|
| [38] | Y. Yu, S. Liu, Y. Feng, M. Xu, Z. Jin, X. Yang, Improving continuous sign language recognition via cross-frame interactions in expanded contextual spaces, In: ICASSP 2025–2025 IEEE International conference on acoustics, speech and signal processing (ICASSP), Hyderabad: IEEE, 2025, 1–5. https://doi.org/10.1109/ICASSP49660.2025.10890162 |
| [39] | G. Cantarini, F. F. Tomenotti, N. Noceti, F. Odone, HHP-Net: A light heteroscedastic neural network for head pose estimation with uncertainty, In: Proceedings of the IEEE/CVF winter conference on applications of computer vision (WACV), 2022, 3521–3530. |
| [40] | P. A. Dias, D. Malafronte, H. Medeiros, F. Odone, Gaze estimation for assisted living environments, In: Proceedings of the IEEE/CVF winter conference on applications of computer vision (WACV), 2020,290–299. |
| [41] | D. A. Nix, A. S. Weigend, Estimating the mean and variance of the target probability distribution, In: Proceedings of 1994 IEEE international conference on neural networks (ICNN'94), 1994, 55–60. https://doi.org/10.1109/ICNN.1994.374138 |
| [42] | A. Kendall, Y. Gal, What uncertainties do we need in bayesian deep learning for computer vision?, In: Advances in neural information processing systems 30 (NIPS 2017), 2017. |
| [43] |
J. H. R. Isaac, M. Manivannan, B. Ravindran, Single shot corrective CNN for anatomically correct 3D hand pose estimation, Front. Artif. Intell., 5 (2022), 759255. https://doi.org/10.3389/frai.2022.759255 doi: 10.3389/frai.2022.759255
|
| [44] |
J. Cabibihan, F. Alkhatib, M. Mudassir, L. A. Lambert, O. S. Al-Kwifi, K. Diab, et al., Suitability of the openly accessible 3D printed prosthetic hands for war-wounded children, Front. Robot. AI, 7 (2020), 594196. https://doi.org/10.3389/frobt.2020.594196 doi: 10.3389/frobt.2020.594196
|
| [45] |
O. Koller, J. Forster, H. Ney, Continuous sign language recognition: Towards large vocabulary statistical recognition systems handling multiple signers, Comput. Vis. Image Underst., 141 (2015), 108–125. https://doi.org/10.1016/j.cviu.2015.09.013 doi: 10.1016/j.cviu.2015.09.013
|
| [46] | O. Koller, S. Zargaran, H. Ney, Re-Sign: Re-aligned end-to-end sequence modelling with deep recurrent CNN-HMMs, In: Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), 2017, 4297–4305 |
| [47] | S. Kumar, B. Deepa, T. Kavitha, M. Tamilselvi, V. Sathiyapriya, B. Natarajan, A novel approach for sign language video generation using deep networks, In: 2024 International conference on data science and network security (ICDSNS), Tiptur: IEEE, 2024, 1–6. https://doi.org/10.1109/ICDSNS62112.2024.10691162 |
| [48] | D. Uthus, G. Tanzer, M. Georg, YouTube-ASL: A large-scale, open-domain american sign language-english parallel corpus, In: Advances in neural information processing systems 36 (NeurIPS 2023), 2023. |
| [49] | Y. Gao, J. Feng, T. Wang, C. Deng, S. Zhang, A CTC triggered siamese network with spatial-temporal dropout for speech recognition, arXiv: 2206.08031, 2022. https://doi.org/10.48550/arXiv.2206.08031 |
| [50] | Ş. Öztürk, H. Y. Keles, E-TSL: A continuous educational Turkish sign language dataset with baseline methods, In: 2024 International congress on human-computer interaction, optimization and robotic applications (HORA), Istanbul: IEEE, 2024, 1–7. https://doi.org/10.1109/HORA61326.2024.10550648 |
| [51] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Attention is all you need, In: Advances in neural information processing systems, 2017. |
| [52] | S. S. Rajagopalan, L. Morency, T. Baltrusaitis, R. Goecke, Extending long short-term memory for multi-view structured learning, In: Computer vision – ECCV 2016, Cham: Springer, 2016,338–353. https://doi.org/10.1007/978-3-319-46478-7_21 |
| [53] | Y. Chen, R. Zuo, F. Wei, Y. Wu, S. Liu, B. Mak, Two-stream network for sign language recognition and translation, In: Advances in neural information processing systems, 2022. |
| [54] |
H. Hu, W. Zhao, W. Zhou, H. Li, SignBERT+: Hand-model-aware self-supervised pre-training for sign language understanding, IEEE Trans. Pattern Anal. Mach. Intell., 45 (2023), 11221–11239. https://doi.org/10.1109/TPAMI.2023.3269220 doi: 10.1109/TPAMI.2023.3269220
|
| [55] | Q. Zhu, J. Li, F. Yuan, J. Fan, Q. Gan, A chinese continuous sign language dataset based on complex environments, arXiv: 2409.11960, 2024. https://doi.org/10.48550/arXiv.2409.11960 |
| [56] |
Q. Zhu, J. Li, F. Yuan, Q. Gan, Temporal superimposed crossover module for effective continuous sign language, Mach. Vis. Appl., 35 (2024), 116. https://doi.org/10.1007/s00138-024-01595-3 doi: 10.1007/s00138-024-01595-3
|

Figures(10) / Tables(13)

Maher Jebali, Lamia Trabelsi, Haifa Harrouch, Rabab Triki, Shawky Mohamed. Development of deep learning-based models highlighting the significance of non-manual features in sign language recognition[J]. AIMS Mathematics, 2025, 10(9): 20084-20112. doi: 10.3934/math.2025898







 DownLoad:
DownLoad: