Cancer remains one of the foremost causes of death worldwide. Despite advancements in pharmaceutical therapies, patients continue to experience adverse effects. Consequently, there is a considerable interest in exploring mushrooms as a supplemental cancer treatment. In Asian countries, edible and medicinal mushrooms have long been consumed in both culinary practices and herbal remedies. Their health and nutritional benefits have also garnered rising attention in Europe. Food-grade mushrooms have a variety of pharmacological properties, including soothing and immunomodulating effects, and are associated with abundant therapeutic benefits. The primary mechanisms behind their anticancer activity comprise immune system improvement, cell cycle arrest, regulation of apoptosis, prevention of metastasis, and inhibition of cancer cell growth. Here, we thoroughly review the anticancer activities of several culinary and medicinal mushrooms, as well as some endophytic fungi, with a particular focus on potential bioactive compounds and their molecular mechanisms.
Citation: Madhurima Roy, Chandana Paul, Nilasish Pal, Tanima Saha, Nirmalendu Das. Pharmacological and therapeutic inventory of fungi in cancertherapy—A comprehensive review[J]. AIMS Molecular Science, 2025, 12(1): 67-98. doi: 10.3934/molsci.2025005
Cancer remains one of the foremost causes of death worldwide. Despite advancements in pharmaceutical therapies, patients continue to experience adverse effects. Consequently, there is a considerable interest in exploring mushrooms as a supplemental cancer treatment. In Asian countries, edible and medicinal mushrooms have long been consumed in both culinary practices and herbal remedies. Their health and nutritional benefits have also garnered rising attention in Europe. Food-grade mushrooms have a variety of pharmacological properties, including soothing and immunomodulating effects, and are associated with abundant therapeutic benefits. The primary mechanisms behind their anticancer activity comprise immune system improvement, cell cycle arrest, regulation of apoptosis, prevention of metastasis, and inhibition of cancer cell growth. Here, we thoroughly review the anticancer activities of several culinary and medicinal mushrooms, as well as some endophytic fungi, with a particular focus on potential bioactive compounds and their molecular mechanisms.

| [1] | Giavasis I (2014) Bioactive fungal polysaccharides as potential functional ingredients in food and nutraceuticals. Curr Opin Biotechnol 26: 162-173. https://doi.org/10.1016/j.copbio.2014.01.010 |
| [2] | Boels D, Landreau A, Bruneau C, et al. (2014) Shiitake dermatitis recorded by French Poison Control Centers—new case series with clinical observations. Clin Toxicol 52: 625-628. https://doi.org/10.3109/15563650.2014.923905 |
| [3] | Kamalebo HM, Nshimba Seya Wa Malale H, Ndabaga CM, et al. (2018) Uses and importance of wild fungi: Traditional knowledge from the Tshopo province in the Democratic Republic of the Congo. J EthnobiolEthnomed 14: 13. https://doi.org/10.1186/s13002-017-0203-6 |
| [4] | Sánchez C (2017) Reactive oxygen species and antioxidant properties from mushrooms. Syn SystBiotechno 2: 13-22. https://doi.org/10.1016/j.synbio.2016.12.001 |
| [5] | Souilem F, Fernandes Â, Calhelha RC, et al. (2017) Wild mushrooms and their mycelia as sources of bioactive compounds: Antioxidant, anti-inflammatory and cytotoxic properties. Food Chem 230: 40-48. https://doi.org/10.1016/j.foodchem.2017.03.026 |
| [6] | Wasser SP, Sokolov D, Reshetnikov SV, et al. (2000) Dietary supplements from medicinal mushrooms: Diversity of types and variety of regulations. Int JMed Mushrooms 2: 19. https://doi.org/10.1615/IntJMedMushr.v2.i1.10 |
| [7] | Agnihotri C, Aarzoo, Agnihotri S, et al. (2024) Mushroom bioactives: Traditional resources with nutraceutical importance. Traditional resources and tools for modern drug discovery . Singapore: Springer 617-639. https://doi.org/10.1007/978-981-97-4600-2_24 |
| [8] | Araújo-Rodrigues AH, Sofia Sousa BA, Pintado CME (2022) Chapter 6: Macromolecules in fungi with pharmaceutical potential. Edible fungi: Chemical composition, nutrition and health effects . Royal society of chemistry 232-272. https://doi.org/10.1039/9781839167522-00232 |
| [9] | Bell V, Silva CRPG, Guina J, et al. (2022) Mushrooms as future generation healthy foods. Front Nutr 9: 1050099. https://doi.org/10.3389/fnut.2022.1050099 |
| [10] | Sousa AS, Araújo-Rodrigues H, Pintado ME (2023) The health-promoting potential of edible mushroom proteins. Curr Pharm Des 29: 804-823. https://doi.org/10.2174/1381612829666221223103756 |
| [11] | Chang ST, Wasser SP (2012) The role of culinary-medicinal mushrooms on human welfare with a pyramid model for human health. Int J Med Mushrooms 14: 95-134. https://doi.org/10.1615/IntJMedMushr.v14.i2.10 |
| [12] | Dan A, Swain R, Belonce S, et al. (2023) Therapeutic effects of medicinal mushrooms on gastric, breast, and colorectal cancer: A scoping review. Cureus 15: e37574. https://doi.org/10.7759/cureus.37574 |
| [13] | Bizuayehu HM, Ahmed KY, Kibret GD, et al. (2024) Global disparities of cancer and its projected burden in 2050. JAMA Netw Open 7: e2443198. https://doi.org/10.1001/jamanetworkopen.2024.43198 |
| [14] | Dizon DS, Kamal AH (2024) Cancer statistics 2024: All hands on deck. CA: A Cancer Journal for Clinicians 74: 8-9. https://doi.org/10.3322/caac.21824 |
| [15] |
De Luca MG, Roda F, Rossi P, et al. (2024) Medicinal mushrooms in metastatic breast cancer: What is their therapeutic potential as adjuvants in clinical settings?. Curr Issues Mol Biol 46: 7577-7591. https://doi.org/10.3390/cimb46070450 
|
| [16] |
De Luca F, Roda E, Ratto D, et al. (2023) Fighting secondary triple-negative breast cancer in the cerebellum: A powerful aid from a medicinal mushroom blend. Biomed Pharmacother 159: 114262. https://doi.org/10.1016/j.biopha.2023.114262
|
| [17] | Bray F, Ren JS, Masuyer E, et al. (2013) Global estimates of cancer prevalence for 27 sites in the adult population in 2008. Int J Cancer 132: 1133-1145. https://doi.org/10.1002/ijc.27711 |
| [18] | Alavi M, Farkhondeh T, Aschner M, et al. (2021) Resveratrol mediates its anti-cancer effects by Nrf2 signaling pathway activation. Cancer Cell Int 21: 579. https://doi.org/10.1186/s12935-021-02280-5 |
| [19] | Hendrix A, Yeo AE, Lejeune S, et al. (2020) Rare case of life-threatening thrombocytopenia occurring after radiotherapy in a patient treated with an immune checkpoint inhibitor. BMJ Case Reports 13: e235249. https://doi.org/10.1136/bcr-2020-235249 |
| [20] | Abravan A, Faivre-Finn C, Kennedy J, et al. (2020) Radiotherapy-related lymphopenia affects overall survival in patients with lung cancer. J Thorac Oncol 15: 1624-1635. https://doi.org/10.1016/j.jtho.2020.06.008 |
| [21] | Arnon J, Meirow D, Lewis-Roness H, et al. (2001) Genetic and teratogenic effects of cancer treatments on gametes and embryos. Hum Reprod Update 7: 394-403. https://doi.org/10.1093/humupd/7.4.394 |
| [22] | Rosangkima G, Prasad SB (2004) Antitumor activity of some plants from Meghalaya and Mizoram against murine ascites Dalton's lymphoma. Indian J Exp Biol 42: 981-988. |
| [23] | Sporn MB, Liby KT (2005) Cancer chemoprevention: Scientific promise, clinical uncertainty. Nat ClinPract Oncol 2: 518-525. https://doi.org/10.1038/ncponc0319 |
| [24] | Araújo-Rodrigues H, Sousa AS, Relvas JB, et al. (2024) An overview on mushroom polysaccharides: Health-promoting properties, prebiotic and gut microbiota modulation effects, and structure-function correlation. CarbohydPolyme 333: 121978. https://doi.org/10.1016/j.carbpol.2024.121978 |
| [25] | Buswell JA, Chang S (2024) Mushrooms: Fungi for all seasons. Acta Edulis Fungi 31: 11-30. |
| [26] | Berretta M, Dal Lago L, Tinazzi M, et al. (2022) Evaluation of concomitant use of anticancer drugs and herbal products: From interactions to synergic activity. Cancers 14: 5203. https://doi.org/10.3390/cancers14215203 |
| [27] | Chan WJJ, Adiwidjaja J, McLachlan AJ, et al. (2023) Interactions between natural products and cancer treatments: Underlying mechanisms and clinical importance. Cancer ChemotherPharmacol 91: 103-119. https://doi.org/10.1007/s00280-023-04504-z |
| [28] | Habtemariam S (2019) The chemistry, pharmacology, and therapeutic potential of the edible mushroom Dictyophoraindusiata (Vent ex.Pers.) Fischer (syn. Phallus indusiatus). Biomedicines 7: 98. https://doi.org/10.3390/biomedicines7040098 |
| [29] | Yuan S, Gopal JV, Ren S, et al. (2020) Anticancer fungal natural products: Mechanisms of action and biosynthesis. Eur J Med Chem 202: 112502. https://doi.org/10.1016/j.ejmech.2020.112502 |
| [30] | Li YX, Himaya SWA, Dewapriya P, et al. (2013) Fumigaclavine C from a marine-derived fungus Aspergillus fumigatus induces apoptosis in MCF-7 breast cancer cells. Mar Drugs 11: 5063-5086. https://doi.org/10.3390/md11125063 |
| [31] | Martirosyan A, Clendening JW, Goard CA, et al. (2010) Lovastatin induces apoptosis of ovarian cancer cells and synergizes with doxorubicin: Potential therapeutic relevance. BMC Cancer 10: 103. https://doi.org/10.1186/1471-2407-10-103 |
| [32] | Siddiqui RA, Harvey KA, Xu Z, et al. (2014) Characterization of lovastatin–docosahexaenoate anticancer properties against breast cancer cells. Bioorgan Med Chem 22: 1899-1908. https://doi.org/10.1016/j.bmc.2014.01.051 |
| [33] | Hou H, Zhou R, Li A, et al. (2014) Citreoviridin inhibits cell proliferation and enhances apoptosis of human umbilical vein endothelial cells. Environ Toxicol Phar 37: 828-836. https://doi.org/10.1016/j.etap.2014.02.016 |
| [34] | Turbyville TJ, Wijeratne EMK, Liu MX, et al. (2006) Search for Hsp90 inhibitors with potential anticancer activity: Isolation and SAR studies of radicicol and monocillin I from two plant-associated fungi of the Sonoran desert. J Nat Prod 69: 178-184. https://doi.org/10.1021/np058095b |
| [35] |
Ishii S, Fujii M, Akita H (2009) First syntheses of (-)-tauranin and antibiotic (-)-BE-40644 based on lipase-catalyzed optical resolution of albicanol. Chem Pharm Bull 57: 1103-1106. https://doi.org/10.1248/cpb.57.1103
|
| [36] | Jørgensen H (2009) Analysis of genes for the biosynthesis of polyene macrocyclic compounds in streptomycetes isolated from the Trondheimsfjord. NTNU Open . |
| [37] |
Zhang J, Guo ZY, Shao CL, et al. (2022) Nigrosporins B, a potential anti-cervical cancer agent, induces apoptosis and protective autophagy in human cervical cancer Ca Ski cells mediated by PI3K/AKT/mTOR signaling pathway. Molecules 27: 2431. https://doi.org/10.3390/molecules27082431
|
| [38] |
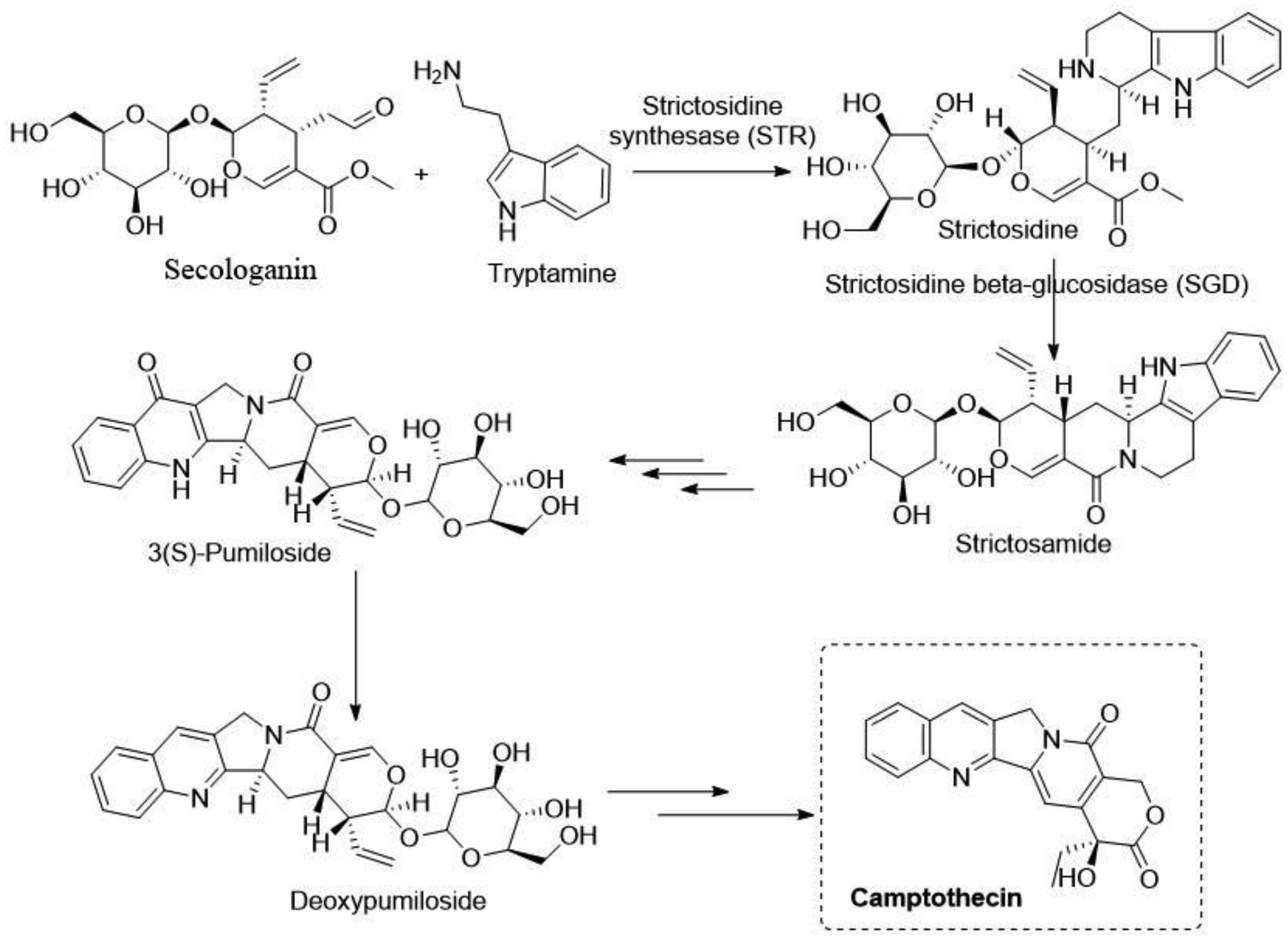
Staker BL, Hjerrild K, Feese MD, et al. (2002) The mechanism of topoisomerase I poisoning by a camptothecinanalog. Proc Natl Acad Sci USA 99: 15387-15392. https://doi.org/10.1073/pnas.242259599
|
| [39] |
Liu YQ, Li WQ, Morris-Natschke SL, et al. (2015) Perspectives on biologically active camptothecin derivatives. Med Res Rev 35: 753-789. https://doi.org/10.1002/med.21342
|
| [40] |
Nguyen DQ, Nguyen NL, Nguyen VT, et al. (2023) Isolation and identification of vincristine and vinblastine producing endophytic fungi from Catharanthus roseus (L.) G. Don. Russ J Plant Physiol 70: 188. https://doi.org/10.1134/S1021443723601507
|
| [41] |
Mulac D, Lepski S, Ebert F, et al. (2013) Cytotoxicity and fluorescence visualization of ergot alkaloids in human cell lines. J Agric Food Chem 61: 462-471. https://doi.org/10.1021/jf304569q
|
| [42] | Pal AK, Pal S (2023) Endophytic fungi as a medicinal repository of potential therapeutic compounds. J Mycopathol Res 61: 15-20. https://doi.org/10.57023/JMycR.61.1.2023.015 |
| [43] |
Kim YS, Kim SK, Park SJ (2017) Apoptotic effect of demethoxyfumitremorgin C from marine fungus Aspergillus fumigatus on PC3 human prostate cancer cells. Chem-Biol Interact 269: 18-24. https://doi.org/10.1016/j.cbi.2017.03.015
|
| [44] |
Islam F, Dehbia Z, Zehravi M, et al. (2023) Indole alkaloids from marine resources: Understandings from therapeutic point of view to treat cancers. Chem-Biol Interact 383: 110682. https://doi.org/10.1016/j.cbi.2023.110682
|
| [45] |
Paschall AV, Yang D, Lu C, et al. (2015) H3K9 trimethylation silences Fas expression to confer colon carcinoma immune escape and 5-fluorouracil chemoresistance. J Immunol 195: 1868-1882. https://doi.org/10.4049/jimmunol.1402243
|
| [46] |
Pierre HC, Amrine CSM, Doyle MG, et al. (2024) Verticillins: Fungal epipolythiodioxopiperazine alkaloids with chemotherapeutic potential. Nat Prod Rep 41: 1327-1345. https://doi.org/10.1039/D3NP00068K
|
| [47] |
Doi Y, Wakana D, Kitaoka S, et al. (2022) Secalonic acid and benzoic acid analogues exhibiting cytotoxicity against cancer cells isolated from Claviceps yanagawaensis. Adv Microbiol 12: 649-670. https://doi.org/10.4236/aim.2022.1212045
|
| [48] |
Meng Q, Li BX, Xiao X (2018) Toward developing chemical modulators of Hsp60 as potential therapeutics. Front Mol Biosci 5: 35.
|
| [49] | Kassab MM (2023) Screening and production of fungal L-asparaginase enzymes as anticancer agents from high-contrast soil environments in Egypt. Egypt Acad J Biolog Sci G Microbiolog 15: 21-41. |
| [50] |
Tiberghien F, Kurome T, Takesako K, et al. (2000) Aureobasidins: Structure−activity relationships for the inhibition of the human MDR1 P-glycoprotein ABC-transporter. J Med Chem 43: 2547-2556. https://doi.org/10.1021/jm990955w
|
| [51] |
López-Legarda X, Rostro-Alanis M, Parra-Saldivar R, et al. (2021) Submerged cultivation, characterization and in vitro antitumor activity of polysaccharides from Schizophyllumradiatum. Int J Biol Macromol 186: 919-932. https://doi.org/10.1016/j.ijbiomac.2021.07.084
|
| [52] |
Pirzadeh-Naeeni S, Mozdianfard MR, Shojaosadati SA, et al. (2020) A comparative study on schizophyllan and chitin nanoparticles for ellagic acid delivery in treating breast cancer. Int J Biol Macromol 144: 380-388. https://doi.org/10.1016/j.ijbiomac.2019.12.079
|
| [53] |
Gallego-Jara J, Lozano-Terol G, Sola-Martínez RA, et al. (2020) A comprehensive review about Taxol®: History and future challenges. Molecules 25: 5986. https://doi.org/10.3390/molecules25245986
|
| [54] |
Gond SK, Kharwar RN, White JF (2014) Will fungi be the new source of the blockbuster drug Taxol?. Fungal Biol Rev 28: 77-84. https://doi.org/10.1016/j.fbr.2014.10.001
|
| [55] |
Yang X, Wu P, Xue J, et al. (2023) Seco-pimarane diterpenoids and androstane steroids from an endophytic Nodulisporium fungus derived from Cyclosorusparasiticus. Phytochemistry 210: 113679. https://doi.org/10.1016/j.phytochem.2023.113679
|
| [56] |
Cadar E, Negreanu-Pirjol T, Pascale C, et al. (2023) Natural bio-compounds from Ganoderma lucidum and their beneficial biological actions for anticancer application: A review. Antioxidants 12: 1907. https://doi.org/10.3390/antiox12111907
|
| [57] |
Guo C, Dai H, Zhang M, et al. (2022) Molecular networking assisted discovery and combinatorial biosynthesis of new antimicrobial pleuromutilins. Eur J Med Chem 243: 114713. https://doi.org/10.1016/j.ejmech.2022.114713
|
| [58] |
Evidente A (2024) The incredible story of ophiobolin A and sphaeropsidin A: Two fungal terpenes from wilt-inducing phytotoxins to promising anticancer compounds. Nat Prod Rep 41: 434-468. https://doi.org/10.1039/D3NP00035D
|
| [59] |
Zheng Q, Sun J, Li W, et al. (2020) Cordycepin induces apoptosis in human tongue cancer cells in vitro and has antitumor effects in vivo. Arch Oral Biol 118: 104846. https://doi.org/10.1016/j.archoralbio.2020.104846
|
| [60] |
Xiang M, Kim H, Ho VT, et al. (2016) Gene expression–based discovery of atovaquone as a STAT3 inhibitor and anticancer agent. Blood 128: 1845-1853. https://doi.org/10.1182/blood-2015-07-660506
|
| [61] |
Cheng L, Yan B, Chen K, et al. (2018) Resveratrol-induced downregulation of NAF-1 enhances the sensitivity of pancreatic cancer cells to gemcitabine via the ROS/Nrf2 signaling pathways. Oxid Med Cell Longev 2018: 9482018. https://doi.org/10.1155/2018/9482018
|
| [62] |
Gangwar C, Yaseen B, Nayak R, et al. (2022) Silver nanoparticles fabricated by tannic acid for their antimicrobial and anticancerous activity. Inorg Chem Commun 141: 109532. https://doi.org/10.1016/j.inoche.2022.109532
|
| [63] |
Naidu SD, Dinkova-Kostova AT (2017) Regulation of the mammalian heat shock factor 1. FEBS J 284: 1606-1627. https://doi.org/10.1111/febs.13999
|
| [64] |
Carroll G (1988) Fungal endophytes in stems and leaves: From latent pathogen to mutualistic symbiont. Ecology 69: 2-9. https://doi.org/10.2307/1943154
|
| [65] |
Zhao J, Shan T, Mou Y, et al. (2011) Plant-derived bioactive compounds produced by endophytic fungi. Mini-Rev Med Chem 11: 159-168. https://doi.org/10.2174/138955711794519492
|
| [66] |
Monacelli B, Valletta A, Rascio N, et al. (2005) Laticifers in Camptotheca acuminate Decne: Distribution and structure. Protoplasma 226: 155-161. https://doi.org/10.1007/s00709-005-0118-2
|
| [67] |
Ran X, Zhang G, Li S, et al. (2017) Characterization and antitumor activity of camptothecin from endophytic fungus Fusarium solani isolated from Camptotheca acuminata. Afr Health Sci 17: 566-574. https://doi.org/10.4314/ahs.v17i2.34
|
| [68] | Kumar A (2016) Vincristine and vinblastine: A review. IJMPS : 23-30. |
| [69] |
Goodbody A, Endo T, Vukovic J, et al. (1988) The coupling of catharanthine and vindoline to form 3′,4′-anhydrovinblastine by haemoproteins and haemin. Planta Med 54: 210-214.
|
| [70] |
Kutchan TM (1995) Alkaloid biosynthesis—the basis for metabolic engineering of medicinal plants. Plant Cell 7: 1059-1070. https://doi.org/10.1105/tpc.7.7.1059
|
| [71] | Kalidass A, Mohan VR, Daniel C (2009) Effect of auxin and cytokinin on vincristine production by callus cultures of Catharanthus roseus L. (Apocynaceae). Trop SubtropicalAgroecosys 12: 283-288. |
| [72] |
Ramezani A, Haddad R, Sedaghati B, et al. (2018) Effects of fungal extracts on vinblastine and vincristine production and their biosynthesis pathway genes in Catharanthus roseus. S Afr J Bot 119: 163-171. https://doi.org/10.1016/j.sajb.2018.08.015
|
| [73] |
Mrusek M, Seo EJ, Greten HJ, et al. (2015) Identification of cellular and molecular factors determining the response of cancer cells to six ergot alkaloids. Invest New Drugs 33: 32-44. https://doi.org/10.1007/s10637-014-0168-4
|
| [74] |
Tudzynski P, Correia T, Keller U (2001) Biotechnology and genetics of ergot alkaloids. Appl Microbiol Biotechnol 57: 593-605. https://doi.org/10.1007/s002530100801
|
| [75] |
Coyle CM, Panaccione DG (2005) An ergot alkaloid biosynthesis gene and clustered hypothetical genes from Aspergillus fumigatus. Appl Environ Microbiol 71: 3112-3118. https://doi.org/10.1128/AEM.71.6.3112-3118.2005
|
| [76] |
Song J, Zhang B, Li M, et al. (2023) The current scenario of naturally occurring indole alkaloids with anticancer potential. Fitoterapia 165: 105430. https://doi.org/10.1016/j.fitote.2023.105430
|
| [77] |
Peng F, Hou SY, Zhang TY, et al. (2019) Cytotoxic and antimicrobial indole alkaloids from an endophytic fungus Chaetomium sp. SYP-F7950 of Panax notoginseng. RSC Adv 9: 28754-28763. https://doi.org/10.1039/C9RA04747F
|
| [78] |
Ding Y, de Wet JR, Cavalcoli J, et al. (2010) Genome-based characterization of two prenylation steps in the assembly of the stephacidin and notoamide anticancer agents in a marine-derived Aspergillus sp. J Am Chem Soc 132: 12733-12740. https://doi.org/10.1021/ja1049302
|
| [79] |
Salvi A, Amrine CSM, Austin JR, et al. (2020) Verticillin A causes apoptosis and reduces tumor burden in high-grade serous ovarian cancer by inducing DNA damage. Mol Cancer Ther 19: 89-100. https://doi.org/10.1158/1535-7163.MCT-19-0205
|
| [80] |
Strobel GA, Torczynski R, Bollon A (1997) Acremonium sp.—Aleucinostatin A producing endophyte of European yew (Taxus baccata). Plant Sci 128: 97-108. https://doi.org/10.1016/S0168-9452(97)00131-3
|
| [81] | Moharib SA (2018) Anticancer activity of L-asparaginase produced from Vigna unguiculata. World Sci Res 5: 1-12. https://doi.org/10.20448/journal.510.2018.51.1.12 |
| [82] |
Hassan SWM, Farag AM, Beltagy EA (2018) Purification, characterization, and anticancer activity of L-asparaginase produced by marine Aspergillus terreus. J Pure Appl Microbiol 12: 1845-1854. https://doi.org/10.22207/JPAM.12.4.19
|
| [83] |
Wang LG, Liu XM, Kreis W, et al. (1999) The effect of antimicrotubule agents on signal transduction pathways of apoptosis: A review. Cancer Chemother Pharmacol 44: 355-361. https://doi.org/10.1007/s002800050989
|
| [84] |
Robinson DR, Wu YM, Lonigro RJ, et al. (2017) Integrative clinical genomics of metastatic cancer. Nature 548: 297-303. https://doi.org/10.1038/nature23306
|
| [85] |
Nakamura K, Shinozuka K, Yoshikawa N (2015) Anticancer and antimetastatic effects of cordycepin, an active component of Cordyceps sinensis. J Pharmacol Sci 127: 53-56. https://doi.org/10.1016/j.jphs.2014.09.001
|
| [86] |
Tao X, Ning Y, Zhao X, et al. (2016) The effects of cordycepin on the cell proliferation, migration, and apoptosis in human lung cancer cell lines A549 and NCI-H460. J Pharm Pharmacol 68: 901-911. https://doi.org/10.1111/jphp.12544
|
| [87] |
Wong JH, Ng TB, Chan HHL, et al. (2020) Mushroom extracts and compounds with suppressive action on breast cancer: evidence from studies using cultured cancer cells, tumor-bearing animals, and clinical trials. Appl Microbiol Biotechnol 104: 4675-4703. https://doi.org/10.1007/s00253-020-10476-4
|
| [88] |
Gill BS, Kumar S, Navgeet (2018) Ganoderic acid A targeting β-catenin in Wntsignaling pathway: In silico and in vitro study. Interdiscip Sci Comput Life Sci 10: 233-243. https://doi.org/10.1007/s12539-016-0182-7
|
| [89] |
Gill BS, Navgeet, Mehra R, et al. (2018) Ganoderic acid, lanostanoid triterpene: A key player in apoptosis. Invest New Drugs 36: 136-143. https://doi.org/10.1007/s10637-017-0526-0
|
| [90] | Jiang J, Grieb B, Thyagarajan A, Sliva D (2008) Ganoderic acids suppress growth and invasive behavior of breast cancer cells by modulating AP-1 and NF-κB signaling. Int J Mol Med 21: 577-584. |
| [91] |
Yamane M, Minami A, Liu C, et al. (2017) Biosynthetic machinery of diterpene pleuromutilin isolated from basidiomycete fungi. Chem Bio Chem 18: 2317-2322. https://doi.org/10.1002/cbic.201700434
|
| [92] |
Uzma F, Mohan CD, Hashem A, et al. (2018) Endophytic fungi—alternative sources of cytotoxic compounds: A review. Front Pharmacol 9: 309.
|
| [93] | Nadeem M, Ram M, Alam P, et al. (2012) Fusarium solani, P1, a new endophyticpodophyllotoxin-producing fungus from roots of Podophyllum hexandrum. Afr J Microbiol Res 6: 2493-2499. |
| [94] |
Shi J, Zeng Q, Liu Y, et al. (2012) Alternaria sp. MG1, a resveratrol-producing fungus: isolation, identification, and optimal cultivation conditions for resveratrol production. Appl Microbiol Biotechnol 95: 369-379. https://doi.org/10.1007/s00253-012-4045-9
|
| [95] |
Guruceaga X, Perez-Cuesta U, de Cerio AAD, et al. (2019) Fumagillin, a mycotoxin of Aspergillus fumigatus: biosynthesis, biological activities, detection, and applications. Toxins 12: 7. https://doi.org/10.3390/toxins12010007
|
| [96] | National Center for Biotechnology Information (NCBI)PubChem Compound Summary for CID 6917655, Fumagillin (2025). Available from: https://pubchem.ncbi.nlm.nih.gov/compound/6917655 |
| [97] |
Khandelwal KA, Han S, Won YW, et al. (2021) Complex interactions of lovastatin with 10 chemotherapeutic drugs: A rigorous evaluation of synergism and antagonism. BMC Cancer 21: 356. https://doi.org/10.1186/s12885-021-07963-w
|
| [98] | Ma HT, Poon RYC (2017) Synchronization of HeLa cells. Cell cycle synchronization . New York: Humana Press 189-201. https://doi.org/10.1007/978-1-4939-6603-5_12 |
| [99] |
Ikuina Y, Amishiro N, Miyata M, et al. (2003) Synthesis and antitumor activity of novel O-carbamoylmethyloxime derivatives of radicicol. J Med Chem 46: 2534-2541. https://doi.org/10.1021/jm030110r
|
| [100] |
Soga S, Shiotsu Y, Akinaga S, et al. (2003) Development of radicicol analogues. Curr Cancer Drug Tar 3: 359-369. https://doi.org/10.2174/1568009033481859
|
| [101] |
Newman DJ, Cragg GM (2007) Natural products as sources of new drugs over the last 25 years. J Nat Prod 70: 461-477. https://doi.org/10.1021/np068054v
|
| [102] |
Kusari S, Hertweck C, Spiteller M (2012) Chemical ecology of endophytic fungi: Origins of secondary metabolites. Chem Biol 19: 792-798. https://doi.org/10.1016/j.chembiol.2012.06.004
|
| [103] |
Kusari S, Zühlke S, Spiteller M (2009) An endophytic fungus from Camptotheca acuminata that produces camptothecin and analogues. J Nat Prod 72: 2-7. https://doi.org/10.1021/np800455b
|
| [104] | Demain AL, Vaishnav P (2011) Natural products for cancer chemotherapy. MicrobBiotechnol 4: 687-699. https://doi.org/10.1111/j.1751-7915.2010.00221.x |
| [105] |
Xie S, Zhou J (2017) Harnessing plant biodiversity for the discovery of novel anticancer drugs targeting microtubules. Front Plant Sci 8: 720. https://doi.org/10.3389/fpls.2017.00720
|
| [106] |
Lei M, Ribeiro H, Kolodin G, et al. (2013) Establishing a high-throughput and automated cancer cell proliferation panel for oncology lead optimization. SLAS Discov 18: 1043-1053. https://doi.org/10.1177/1087057113491825
|
| [107] |
Aly AH, Edrada-Ebel R, Indriani ID, et al. (2008) Cytotoxic metabolites from the fungal endophyte Alternaria sp. and their subsequent detection in its host plant Polygonum senegalense. J Nat Prod 71: 972-980. https://doi.org/10.1021/np070447m
|
| [108] |
Salvador-Reyes LA, Luesch H (2015) Biological targets and mechanisms of action of natural products from marine cyanobacteria. Nat Prod Rep 32: 478-503. https://doi.org/10.1039/C4NP00104D
|
| [109] | Stierle AA, Stierle DB (2015) Bioactive secondary metabolites produced by the fungal endophytes of conifers. Nat Prod Commun 10: 1671-1682. |
| [110] |
Balunas MJ, Kinghorn AD (2005) Drug discovery from medicinal plants. Life Sci 78: 431-441. https://doi.org/10.1016/j.lfs.2005.09.012
|
| [111] |
Saltz L, Shimada Y, Khayat D (1996) CPT-11 (irinotecan) and 5-fluorouracil: A promising combination for therapy of colorectal cancer. Eur J Cancer 32: S24-31. https://doi.org/10.1016/0959-8049(96)00294-8
|
| [112] |
Mei C, Lei L, Tan LM, et al. (2020) The role of single strand break repair pathways in cellular responses to camptothecin induced DNA damage. Biomed Pharmacother 125: 109875. https://doi.org/10.1016/j.biopha.2020.109875
|
| [113] |
Li M, Wang L, Wei Y, et al. (2022) Anti-colorectal cancer effects of a novel camptothecin derivative PCC0208037 in vitro and in vivo. Pharmaceuticals 16: 53. https://doi.org/10.3390/ph16010053
|
| [114] |
Kaur P, Kumar V, Singh R, et al. (2020) Biotechnological strategies for production of camptothecin from fungal and bacterial endophytes. South Afr J Bot 134: 135-145. https://doi.org/10.1016/j.sajb.2020.07.001
|
| [115] |
Banadka A, Narasimha SW, Dandin VS, et al. (2024) Biotechnological approaches for the production of camptothecin. Appl Microbiol Biotechnol 108: 382. https://doi.org/10.1007/s00253-024-13187-2
|
| [116] |
Bates D, Eastman A (2017) Microtubuledestabilizing agents: Far more than just antimitotic anticancer drugs. Br J Clin Pharmacol 83: 255-268. https://doi.org/10.1111/bcp.13126
|
| [117] |
Javeed A, Ashraf M, Riaz A, et al. (2009) Paclitaxel and immune system. Eur J Pharm Sci 38: 283-290. https://doi.org/10.1016/j.ejps.2009.08.009
|
| [118] |
Lim PT, Goh BH, Lee WL (2022) Taxol: Mechanisms of action against cancer, an update with current research. Paclitaxel . Elsevier 47-71. https://doi.org/10.1016/B978-0-323-90951-8.00007-2
|
| [119] |
Kusari S, Singh S, Jayabaskaran C (2014) Rethinking production of Taxol® (paclitaxel) using endophyte biotechnology. Trends Biotechnol 32: 304-311. https://doi.org/10.1016/j.tibtech.2014.03.011
|
| [120] |
Zerbe P (2024) Plants against cancer: Towards green Taxol production through pathway discovery and metabolic engineering. aBIOTECH 5: 394-402. https://doi.org/10.1007/s42994-024-00170-8
|
| [121] |
Wong YY, Moon A, Duffin R, et al. (2010) Cordycepin inhibits protein synthesis and cell adhesion through effects on signal transduction. J Biol Chem 285: 2610-2621. https://doi.org/10.1074/jbc.M109.071159
|
| [122] |
Jin Y, Meng X, Qiu Z, et al. (2018) Anti-tumor and anti-metastatic roles of cordycepin, one bioactive compound of Cordyceps militaris. Saudi J Biol Sci 25: 991-995. https://doi.org/10.1016/j.sjbs.2018.05.016
|
| [123] |
Hwang IH, Oh SY, Jang HJ, et al. (2017) Cordycepin promotes apoptosis in renal carcinoma cells by activating the MKK7-JNK signaling pathway through inhibition of c-FLIPL expression. PLoS One 12: e0186489. https://doi.org/10.1371/journal.pone.0186489
|
| [124] |
Hsu PY, Lin YH, Yeh EL, et al. (2017) Cordycepin and a preparation from Cordyceps militaris inhibit malignant transformation and proliferation by decreasing EGFR and IL-17RA signaling in a murine oral cancer model. Oncotarget 8: 93712-93728. https://doi.org/10.18632/oncotarget.21477
|
| [125] |
Joo JC, Hwang JH, Jo E, et al. (2017) Cordycepin induces apoptosis by caveolin-1-mediated JNK regulation of Foxo3a in human lung adenocarcinoma. Oncotarget 8: 12211-12224. https://doi.org/10.18632/oncotarget.14661
|
| [126] | Wu X, Wu T, Huang A, et al. (2021) New insights into the biosynthesis of typical bioactive components in the traditional Chinese medicinal fungus Cordyceps militaris. Front Bioeng Biotechnol 9: 801721. https://doi.org/10.3389/fbioe.2021.801721 |
| [127] |
Yoo CH, Sadat MA, Kim W, et al. (2022) Comprehensive transcriptomic analysis of Cordyceps militaris cultivated on germinated soybeans. Mycobiology 50: 1-11. https://doi.org/10.1080/12298093.2022.2035906
|
| [128] |
Frottin F, Bienvenut WV, Bignon J, et al. (2016) MetAP1 and MetAP2 drive cell selectivity for a potent anti-cancer agent in synergy, by controlling glutathione redox state. Oncotarget 7: 63306-63323. https://doi.org/10.18632/oncotarget.11216
|
| [129] |
Lin HC, Chooi YH, Dhingra S, et al. (2013) The fumagillin biosynthetic gene cluster in Aspergillus fumigatus encodes a cryptic terpene cyclase involved in the formation of β-trans-Bergamotene. J Am Chem Soc 135: 4616-4619. https://doi.org/10.1021/ja312503y
|
| [130] |
Zhang Y, Yeh JR, Mara A, et al. (2006) A chemical and genetic approach to the mode of action of fumagillin. Chem Biol 13: 1001-1009. https://doi.org/10.1016/j.chembiol.2006.07.010
|
| [131] |
Yang T, Yao H, He G, et al. (2016) Effects of lovastatin on MDA-MB-231 breast cancer cells: An antibody microarray analysis. J Cancer 7: 192-199. https://doi.org/10.7150/jca.13414
|
| [132] |
Maksimova E, Yie TA, Rom WN (2008) In vitro mechanisms of lovastatin on lung cancer cell lines as a potential chemo preventive eagent. Lung 186: 45-54. https://doi.org/10.1007/s00408-007-9053-7
|
| [133] |
Ames BD, Nguyen C, Bruegger J, et al. (2012) Crystal structure and biochemical studies of the trans-acting polyketide enoyl reductase LovC from lovastatin biosynthesis. Proc Natl Acad Sci USA 109: 11144-11149. https://doi.org/10.1073/pnas.1113029109
|
| [134] |
Zhang Y, Chen Z, Wen Q, et al. (2020) An overview on the biosynthesis and metabolic regulation of monacolin K/Lovastatin. Food Funct 11: 5738-5748. https://doi.org/10.1039/D0FO00691B
|
| [135] |
Sun X, Xu Q, Zeng L, et al. (2020) Resveratrol suppresses the growth and metastatic potential of cervical cancer by inhibiting STAT3Tyr705 phosphorylation. Cancer Medicine 9: 8685-8700. https://doi.org/10.1002/cam4.3510
|
| [136] |
Brockmueller A, Girisa S, Kunnumakkara AB, et al. (2023) Resveratrol modulates chemosensitization to 5-FU via β1-Integrin/HIF-1α axis in CRC tumor microenvironment. Int J Mol Sci 24: 4988. https://doi.org/10.3390/ijms24054988
|
| [137] |
Li J, Fan Y, Zhang Y, et al. (2022) Resveratrol induces autophagy and apoptosis in non-small-cell lung cancer cells by activating the NGFR-AMPK-mTOR pathway. Nutrients 14: 2413. https://doi.org/10.3390/nu14122413
|
| [138] |
Meng T, Xiao D, Muhammed A, et al. (2021) Anti-inflammatory action and mechanisms of resveratrol. Molecules 26: 229. https://doi.org/10.3390/molecules26010229
|
| [139] | Abo-Kadoum MA, Abouelela ME, Al Mousa AA, et al. (2022) Resveratrol biosynthesis, optimization, induction, biotransformation and biodegradation in mycoendophytes. Front Microbiol 13: 010332. https://doi.org/10.3389/fmicb.2022.1010332 |
| [140] |
Schwab W, Lange BM, Wüst M (2018) Biotechnology of natural products. Springer. https://doi.org/10.1007/978-3-319-67903-7
|
| [141] |
Groth-Pedersen L, Ostenfeld MS, Høyer-Hansen M, et al. (2007) Vincristine induces dramatic lysosomal changes and sensitizes cancer cells to lysosome-destabilizing siramesine. Cancer Res 67: 2217-2225. https://doi.org/10.1158/0008-5472.CAN-06-3520
|
| [142] |
Bates D, Eastman A (2017) Microtubule destabilizing agents: Far more than just antimitotic anticancer drugs. Brit J Clini Pharmaco 8: 255-268. https://doi.org/10.1111/bcp.13126
|
| [143] |
Pandey SS, Singh S, Babu CSV, et al. (2016) Fungal endophytes of Catharanthus roseusenhance vindoline content by modulating structural and regulatory genes related to terpenoid indole alkaloid biosynthesis. Sci Rep 6: 26583. https://doi.org/10.1038/srep26583
|
| [144] | Ye L (2015) Synthetic strategies in molecular imprinting. Molecularly imprinted polymers in biotechnology . Cham: Springer 1-24. https://doi.org/10.1007/10_2015_313 |
| [145] | Gao D, Liu T, Gao J, et al. (2022) De Novobiosynthesis of vindoline and catharanthine in Saccharomyces cerevisiae. Bio Design Res 2022: 0022. https://doi.org/10.34133/bdr.0002 |
| [146] |
Jeitler M, Michalsen A, Frings D, et al. (2020) Significance of medicinal mushrooms in integrative oncology: A narrative review. Front Pharmacol 11: 580656. https://doi.org/10.3389/fphar.2020.580656
|
| [147] |
Grant SJ, Hunter J, Seely, D, et al. (2019) Integrative oncology: International perspectives. Integr Cancer Ther 18: 1-11. https://doi.org/10.1177/1534735418823266
|
| [148] |
Plácido AI, Roque F, Morgado M (2022) The promising role of mushrooms as a therapeutic adjuvant of conventional cancer therapies. Biologics 2: 58-68. https://doi.org/10.3390/biologics2010005
|
| [149] |
Tsai MY, Hung YC, Chen YH, et al. (2016) A preliminary randomised controlled study of short-term Antrodiacinnamomea treatment combined with chemotherapy for patients with advanced cancer. BMC Complement Altern Med 16: 322. https://doi.org/10.1186/s12906-016-1312-9
|
| [150] |
Tsao SM, Hsu HY (2016) Fucose-containing fraction of Ling-Zhi enhances lipid raft-dependent ubiquitination of TGFβ receptor degradation and attenuates breast cancer tumorigenesis. Sci Rep 6: 36563. https://doi.org/10.1038/srep36563
|
| [151] |
Roldan-Deamicis A, Alonso E, Brie B, et al. (2016) Maitake Pro4X has anti-cancer activity and prevents oncogenesis in BALB/c mice. Cancer Med 5: 2427-2441. https://doi.org/10.1002/cam4.744
|
| [152] | Gou Y, Zheng X, Li W, et al. (2022) Polysaccharides produced by the mushroom Trametes robiniophila Murrboost the sensitivity of hepatoma cells to oxaliplatin via the miR-224-5p/ABCB1/P-gpaxis. Integr Cancer Ther 21. https://doi.org/10.1177/15347354221090221 |
| [153] |
Xu WW, Li B, Lai ETC, et al. (2014) Water extract from Pleurotus pulmonarius with antioxidant activity exerts in vivochemoprophylaxis and chemosensitization for liver cancer. Nutr Cancer 66: 989-998. https://doi.org/10.1080/01635581.2014.936950
|
| [154] |
Cen K, Chen M, He M, et al. (2022) Sporoderm-broken spores of Ganoderma lucidum sensitize ovarian cancer to cisplatin by ROS/ERK signaling and attenuate chemotherapy-related toxicity. Front Pharmacol 13: 826716. https://doi.org/10.3389/fphar.2022.826716
|
| [155] |
De Luca F, Roda E, Ratto D, et al. (2023) Fighting secondary triple-negative breast cancer in cerebellum: A powerful aid from a medicinal mushrooms blend. Biomed Pharmacother 159: 114262. https://doi.org/10.1016/j.biopha.2023.114262
|
| [156] |
Lyons MJ, Ehrhardt C, Walsh JJ (2023) Orellanine: From fungal origin to a potential future cancer treatment. J Natural Prod 86: 1620-1631. https://doi.org/10.1021/acs.jnatprod.2c01068
|
| [157] |
Ling T, Arroyo-Cruz LV, Smither WR, et al. (2024) Early preclinical studies of ergosterol peroxide and biological evaluation of its derivatives. ACS Omega 9: 37117-37127. https://doi.org/10.1021/acsomega.4c04350
|
| [158] |
Panda SK, Sahoo G, Swain SS, et al. (2022) Anticancer activities of mushrooms: A neglected source for drug discovery. Pharmaceuticals 15: 176. https://doi.org/10.3390/ph15020176
|
| [159] | Zhao H, Zhang Q, Zhao L, et al. (2012) Spore powder of Ganoderma lucidum improves cancer-related fatigue in breast cancer patients undergoing endocrine therapy: A pilot clinical trial. Evid-Based Compl Alt Med 2012: 809614. https://doi.org/10.1155/2012/809614 |
 molsci-12-01-005-s001.pdf molsci-12-01-005-s001.pdf |
 |







Figures(8)

Madhurima Roy, Chandana Paul, Nilasish Pal, Tanima Saha, Nirmalendu Das. Pharmacological and therapeutic inventory of fungi in cancertherapy—A comprehensive review[J]. AIMS Molecular Science, 2025, 12(1): 67-98. doi: 10.3934/molsci.2025005







 DownLoad:
DownLoad: