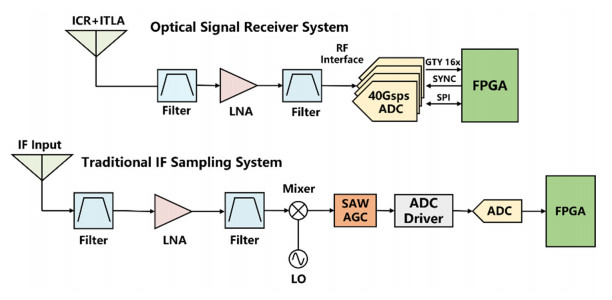
This article presents a method to calibrate a 16-channel 40 GS/s time-interleaved analog-to-digital converter (TI-ADC) based on channel equalization and Monte Carlo method. First, the channel mismatch is estimated by the Monte Carlo method, and equalize each channel to meet the calibration requirement. This method does not require additional hardware circuits, every channel can be compensated. The calibration structure is simple and the convergence speed is fast, besides, the ADC is worked in background mode, which does not affect the conversion. The prototype, implemented in 28 nm CMOS, reaches a 41 dB SFDR with an input signal of 1.2 GHz and 5 dBm after the proposed background offset and gain mismatch calibration. Compared with previous works, the spurious-free dynamic range (SFDR) and the effective number of bits (ENOB) are better, the estimation accuracy is higher, the error is smaller and the faster speed of convergence improves the efficiency of signal processing.
Citation: Yongjie Zhao, Sida Li, Zhiping Huang. TI-ADC multi-channel mismatch estimation and calibration in ultra-high-speed optical signal acquisition system[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 9050-9075. doi: 10.3934/mbe.2021446
This article presents a method to calibrate a 16-channel 40 GS/s time-interleaved analog-to-digital converter (TI-ADC) based on channel equalization and Monte Carlo method. First, the channel mismatch is estimated by the Monte Carlo method, and equalize each channel to meet the calibration requirement. This method does not require additional hardware circuits, every channel can be compensated. The calibration structure is simple and the convergence speed is fast, besides, the ADC is worked in background mode, which does not affect the conversion. The prototype, implemented in 28 nm CMOS, reaches a 41 dB SFDR with an input signal of 1.2 GHz and 5 dBm after the proposed background offset and gain mismatch calibration. Compared with previous works, the spurious-free dynamic range (SFDR) and the effective number of bits (ENOB) are better, the estimation accuracy is higher, the error is smaller and the faster speed of convergence improves the efficiency of signal processing.

| [1] |
M. I. Zahoor, Z. Dou, S. B. H. Shah, I. U. Khan, S. Ayub, T. R. Gadekallu, Pilot decontamination using asynchronous fractional pilot scheduling in massive MIMO systems, Sensors, 20 (2020), 6213. doi: 10.3390/s20216213

|
| [2] |
M. H. Abidi, H. Alkhalefah, K. Moiduddin, M. Alazab, M. K. Mohammed, W. Ameen, et al., Optimal 5G network slicing using machine learning and deep learning concepts, Comput. Stand. Interfaces, 76 (2021), 103518. doi: 10.1016/j.csi.2021.103518
|
| [3] | N. Ning, Z. Sui, J. Li, S. Wu, H. Chen, S. Xu, et al., Multi scaling coefficients technique for noisy signal based gain error background calibration, in 2012 IEEE International Conference on Electron Devices and Solid State Circuit (EDSSC), (2012), 1–2. |
| [4] |
N. Ning, Z. Sui, J. Li, S. Wu, H. Chen, S. Xu, et al., Multiscaling coefficients technique for gain error background calibration in pipelined ADC, J. Circuits Syst. Comput., 23 (2014), 1450034. doi: 10.1142/S0218126614500340
|
| [5] | C. C. Hsu, F. C. Huang, C. Y. Shih, C. C. Huang, Y. H. Lin, C. C. Lee, et al., An 11b 800MS/s time-interleaved ADC with digital background calibration, in 2007 IEEE International Solid-State Circuits Conference, (2017), 464–615. |
| [6] | D. Wang, J. P. Keane, P. J. Hurst, B. C. Levy, S. H. Lewis, Convergence analysis of a background interstage gain calibration technique for pipelined ADCs, in 2005 IEEE International Symposium on Circuits and Systems, (2005), 4058–4061. |
| [7] |
L. Guo, S. Tian, Z. Wang, Estimation and correction of gain mismatch and timing error in time-interleaved ADCs based on DFT, Metrol. Meas. Syst., 21 (2014), 535–544. doi: 10.2478/mms-2014-0045
|
| [8] | S. Liu, N. Lyu, J. Cui, Y. Zou, Improved blind timing skew estimation based on spectrum sparsity and ApFFT in time-interleaved ADCs, IEEE Trans. Instrum. Meas., 68 (2018), 73–86. |
| [9] |
S. M. Jamal, D. Fu, N. C. J. Chang, P. J. Hurst, S. H. Lewis, A 10-b 120-Msample/s time-interleaved analog-to-digital converter with digital background calibration, IEEE J. Solid State Circuits, 37 (2002), 1618–1627. doi: 10.1109/JSSC.2002.804327
|
| [10] | M. Guo, J. Mao, S. W. Sin, H. Wei, R. P. Martins, A 5 GS/s 29 mW interleaved SAR ADC with 48.5 dB SNDR using digital-mixing background timing-skew calibration for direct sampling applications, IEEE Access, 8 (2002), 138944–138954. |
| [11] | D. Xing, Y. Zhu, C. H. Chan, S. W. Sin, F. Ye, J. Ren, et al., Seven-bit 700-MS/s four-way time-interleaved SAR ADC with partial Vcm-based switching, IEEE Trans. VLSI Syst., 25 (2016), 1168–1172. |
| [12] | N. Le Dortz, J. P. Blanc, T. Simon, S. Verhaeren, E. Rouat, P. Urard, et al., A 1.62GS/s time-interleaved SAR ADC with fully digital background mismatch calibration achieving interleaving spurs below 70dBFS, in Proceedings of the 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers, (2014), 386–388. |
| [13] |
S. W. Sin, U. F. Chio, U. Seng-Pan, R. P. Martins, Statistical spectra and distortion analysis of time-interleaved sampling bandwidth mismatch, IEEE Trans. Circuits Syst. Ⅱ Express Briefs, 55 (2008), 648–652. doi: 10.1109/TCSII.2008.921600
|
| [14] |
K. C. Dyer, J. P. Keane, S. H. Lewis, Calibration and dynamic matching in data converters: part 1: linearity calibration and dynamic-matching techniques, IEEE Solid State Circuits Mag., 10 (2018, ), 46–55. doi: 10.1109/MSSC.2017.2771106
|
| [15] |
D. Dermit, M. Shrivas, K. Bunsen, J. L. Benites, J. Craninckx, E. Martens, A 1.67-GSps TI 10-Bit Ping-Pong SAR ADC With 51-dB SNDR in 16-nm FinFET, IEEE Solid State Circuits Lett., 3 (2020), 150–153. doi: 10.1109/LSSC.2020.3008264
|
| [16] | B. Razavi, Problem of timing mismatch in interleaved ADCs, Proc. Cust. Integr. Circuits Conf., 2012 (2012), 1–8. |
| [17] |
B. Razavi, Design considerations for interleaved ADCs, IEEE J. Solid State Circuits, 48 (2013), 1806–1817. doi: 10.1109/JSSC.2013.2258814
|
| [18] |
D. Wang, X. Zhu, X. Guo, J. Luan, L. Zhou, D. Wu, et al., A 2.6 GS/s 8-Bit time-interleaved SAR ADC in 55 nm CMOS technology, Electronics, 8 (2019), 305. doi: 10.3390/electronics8020161
|
| [19] |
C. C. Huang, C. Y. Wang, J. T. Wu, A CMOS 6-bit 16-GS/s time-interleaved ADC using digital background calibration techniques, IEEE J. Solid State Circuits, 46 (2011), 848–858. doi: 10.1109/JSSC.2011.2109511
|
| [20] | H. Le Duc, D. M. Nguyen, C. Jabbour, T. Graba, P. Desgreys, O. Jamin, Hardware implementation of all digital calibration for undersampling TIADCs, in 2015 IEEE International Symposium on Circuits and Systems (ISCAS), (2015), 2181–2184. |
| [21] |
M. Bagheri, F. Schembari, H. Zare-Hoseini, R. B. Staszewski, A. Nathan, Interchannel mismatch calibration techniques for time-interleaved SAR ADCs, IEEE Open J. Circuits Syst., 2 (2021), 420–433. doi: 10.1109/OJCAS.2021.3083680
|
| [22] |
K. Seong, D. K. Jung, D. H. Yoon, J. S. Han, J. E. Kim, T. T. H. Kim, Time-interleaved SAR ADC with background timing-skew calibration for UWB wireless communication in IoT systems, Sensors, 20 (2020), 2430. doi: 10.3390/s20082430
|
| [23] |
S. R. Khan, A. A. Hashmi, G. S. Choi, A fully digital background calibration technique for M-channel time-interleaved ADCs, Circuits Syst. Signal Process., 36 (2017), 3303–3319. doi: 10.1007/s00034-016-0456-7
|
| [24] |
Y. Qiu, Y. J. Liu, J. Zhou, G. Zhang, D. Chen, N. Du, All-digital blind background calibration technique for any channel time-interleaved ADC, IEEE Trans. Circuits Syst. Ⅰ Regul. Pap., 65 (2018), 2503–2514. doi: 10.1109/TCSI.2018.2794529
|
| [25] |
H. Niu, J. Yuan, An efficient spur-aliasing-free spectral calibration technique in time-interleaved ADCs, IEEE Trans. Circuits Syst. Ⅰ Regul. Pap., 67 (2020), 2229–2238. doi: 10.1109/TCSI.2020.2975304
|
| [26] | Waveform Measurement and Analysis Technical Committee, IEEE Standard for Terminology and Test Methods for Analog-to-Digital Converters, 2011. Available from: http://www2.imse-cnm.csic.es/elec_esi/asignat/LME/pdf/temas/IEEE_ADC.pdf. |
| [27] | S. Singh, L. Anttila, M. Epp, W. Schlecker, M. Valkama, Analysis, blind identification, and correction of frequency response mismatch in two-channel time-interleaved ADCs, IEEE Trans. Microw. Theory Tech. 63 (2015), 1721–1734. |
| [28] |
W. K. Hastings, Monte Carlo sampling methods using Markov chains and their applications. Biometrika, 57 (1970), 97–109. doi: 10.1093/biomet/57.1.97
|
| [29] | J. Lemley, F. Jagodzinski, R. Andonie, Big holes in big data: A monte carlo algorithm for detecting large hyper-rectangles in high dimensional data, in 2016 IEEE 40th Annual Computer Software and Applications Conference (COMPSAC), (2016), 563–571. |
| [30] | A. Dubey, A. Lohiya, V. Narwal, A. K. Jha, P. Agarwal, G. Schaefer, Natural image interpolation using extreme learning machine, in International Conference on Soft Computing and Pattern Recognition, (2016), 340–350. |
| [31] | T. Saramaki, R. Bregovic, Multirate Systems and Filterbanks, in Multirate systems: design and applications, IGI Global, (2002), 27–85. |
| [32] | Y. Yin, G. Yang, H. Chen, A novel gain error background calibration algorithm for time-interleaved ADCs, in 2014 International Conference on Anti-Counterfeiting, Security and Identification (ASID), (2014), 1–4. |
| [33] | S. Saleem, C. Vogel, LMS-based identification and compensation of timing mismatches in a two-channel time-interleaved analog-to-digital converter, Norchip 2007, (2007), 7–10. |
| [34] | J. Wu, J. Wu, Background calibration of capacitor mismatch and gain error in pipelined-SAR ADC using partially split structure, in 2021 IEEE 5th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), (2021), 1882–1885. |




















Figures(21) / Tables(8)

Yongjie Zhao, Sida Li, Zhiping Huang. TI-ADC multi-channel mismatch estimation and calibration in ultra-high-speed optical signal acquisition system[J]. Mathematical Biosciences and Engineering, 2021, 18(6): 9050-9075. doi: 10.3934/mbe.2021446







 DownLoad:
DownLoad: