Citation: Sarita Bugalia, Vijay Pal Bajiya, Jai Prakash Tripathi, Ming-Tao Li, Gui-Quan Sun. Mathematical modeling of COVID-19 transmission: the roles of intervention strategies and lockdown[J]. Mathematical Biosciences and Engineering, 2020, 17(5): 5961-5986. doi: 10.3934/mbe.2020318

| [1] | L. F. Wang, Z. Shi, S. Zhang, H. Field, P. Daszak, B. Eaton, Review of bats and SARS, Emerging Infect. Dis., 12 (2006), 1834-1840. |
| [2] | Z. J. Cheng, J. Shan, 2019 Novel coronavirus: where we are and what we know, Infection, 48 (2020), 155-163. |
| [3] | L. Qun, X. Guan, P. Wu, X. Wang, L. Zhou, Y. Tong, et al., Early transmission dynamics in Wuhan, China, of novel coronavirus-infected pneumonia, N. Engl. J. Med., (2020). |
| [4] | R. Yan, Y. Zhang, Y. Li, L. Xia, Y. Guo, Q. Zhou, Structural basis for the recognition of SARSCoV-2 by full-length human ACE2, Science, 367 (2020), 1444-1448. |
| [5] | J. Shang, G. Ye, K. Shi, Y. Wan, C. Luo, H. Aihara, et al., Structural basis of receptor recognition by SARS-CoV-2, Nature, 581 (2020), 221-224. |
| [6] | R. Lu, X. Zhao, J. Liu, P. Niu, B. Yang, H. Wu, et al., Genomic characterization and epidemiology of 2019 novel coronavirus: implications for virus origins and receptor binding, Lancet, 395 (2020), 565-574. |
| [7] | L. Mousavizadeh, S. Ghasemi, Genotype and phenotype of COVID-19: Their roles in pathogenesis, J. Microbiol., Immun. Infect., (2020). |
| [8] | Y. Chen, Q. Liu, D. Guo, Emerging coronaviruses: genome structure, replication, and pathogenesis, J. Med. Virol., 92 (2020), 418-423. |
| [9] | The New York Times, available from: https://www.nytimes.com/2020/02/26/health/coronavirus-asymptomatic.html. |
| [10] | Worldometer, Coronavirus Incubation Period, available from: https://www.worldometers.info/coronavirus/coronavirus-incubation-period/. |
| [11] | Reuters, World news, available from: https://www.reuters.com/article/us-china-health-incubation/coronavirus-incubation-could-be-as-long-as-27\-days-chinese-provincial-government-says-idUSKCN20G06W. |
| [12] | CDC (Centers for Disease Control and Prevention), Symptoms of Coronavirus, available from: https://www.cdc.gov/coronavirus/2019-ncov/about/symptoms.html. |
| [13] | J. F.-W. Chan, S. Yuan, K.-H. Kok, K. K.-W. To, H. Chu, J. Yang, et al., A familial cluster of pneumonia associated with the 2019 novel coronavirus indicating person-to-person transmission: a study of a family cluster, Lancet, 395 (2020), 514-523. |
| [14] | R. M. Anderson, C. Fraser, A. C. Ghani, C. A. Donnelly, S. Riley, N. M. Ferguson, et al., Epidemiology, transmission dynamics and control of SARS: the 2002-2003 epidemic, Philos. Trans. R. Soc. Lond., B, Biol. Sci., 359 (2004), 1091-1105. |
| [15] | J. A. P. Heesterbeek, K. Dietz, The concept of R0 in epidemic theory, Stat. Neerl., 50 (1996), 89-110. |
| [16] | M. Martcheva, An introduction to mathematical epidemiology, New York: Springer, 2015. |
| [17] | H. W. Hethcote, The mathematics of infectious diseases, SIAM Rev., 42 (2000), 599-653. |
| [18] | O. Diekmann, J. A. P. Heesterbeek, J. A. Metz, On the definition and the computation of the basic reproduction ratio r 0 in models for infectious diseases in heterogeneous populations, J. Math. Biol., 28 (1990), 365-382. |
| [19] | P. Driessche, J. Watmough, Reproduction numbers and sub-threshold endemic equilibria for compartmental models of disease transmission, Math. Biosci., 180 (2002), 29-48. |
| [20] | World Health Organization, Laboratory testing for coronavirus disease 2019 (COVID- 19) in suspected human cases: interim guidance, 2 March 2020. No. WHO/COVID- 19/laboratory/2020.4. World Health Organization, 2020. |
| [21] | S. Zhao, Q. Lin, J. Ran, S. S. Musa, G. Yang, W. Wang, et al., Preliminary estimation of the basic reproduction number of novel coronavirus (2019-nCoV) in China, from 2019 to 2020: A data-driven analysis in the early phase of the outbreak, Int. J. Infect. Dis., 92 (2020), 214-217. |
| [22] | J. M. Read, Novel coronavirus 2019-nCoV: early estimation of epidemiological parameters and epidemic predictions, MedRxiv, 2020. |
| [23] | M. Majumder, D. M. Kenneth, Early transmissibility assessment of a novel coronavirus in Wuhan, China, China (January 23, 2020), (2020). |
| [24] | N. Imai, Report 3: transmissibility of 2019-nCoV, Imperial College London, 2020. |
| [25] | W.-O. Kermack, A.-G. McKendrick, A contribution to the mathematical theory of epidemics, Proc. R. Soc. London A, 115 (1927), 700-721. |
| [26] | C. Castillo-Chavez, B. Song, Dynamical models of tuberculosis and their applications, Math. Biosci. Eng., 1 (2004), 361-404. |
| [27] | R.-M. Anderson, B. Anderson, R.-M. May, Infectious diseases of humans: dynamics and control, Oxford university press, (1992). |
| [28] | B. Tang, X. Wang, Q. Li, N. L. Bragazzi, S. Y. Tang, Y. N. Xiao, et al., Estimation of the transmission risk of the 2019-nCoV and its implication for public health interventions, J. Clin. Med., 9 (2020), 462. |
| [29] | C. Yang, J. Wang, A mathematical model for the novel coronavirus epidemic in Wuhan, China, Math. Biosci. Eng., 17 (2020), 2708-2724. |
| [30] | M.-T. Li, G.-Q. Sun, J. Zhang, Y. Zhao, X. Pei, L. Li, et al., Analysis of COVID-19 transmission in Shanxi Province with discrete time imported cases, Math. Biosci. Eng., 17 (2020), 3710-3720. |
| [31] | C.-N. Ngonghala, E. lboi, S. Eikenberry, M. Scotch, C.-R. Maclntyre, M.-H. Bonds, et al., Mathematical assessment of the impact of non-pharmaceutical interventions on curtailing the 2019 novel Coronavirus, Math. Biosci., (2020), 108364. |
| [32] | S.-E. Eikenberry, M. Mancuso, E. Lboi, T. Phan, K. Eikenberry, Y. Kuang, et al., To mask or not to mask: Modeling the potential for face mask use by the general public to curtail the COVID-19 pandemic, Infect. Dis. Model., (2020). |
| [33] | F. Saldana, H. F. Arguedas, J. A. Camacho-Gutierrez, I. Barradas, Modeling the transmission dynamics and the impact of the control interventions for the COVID-19 epidemic outbreak, Math. Biosci. Eng., 17 (2020), 4165-4183. |
| [34] | S.-M. Garba, J.-M. Lubuma, B. Tsanou, Modeling the transmission dynamics of the COVID-19 Pandemic in South Africa, Math. Biosci., (2020), 108441. |
| [35] | M.-A. Acuna-Zegarra, M. Santana-Cibrian, J.-X. Velasco-Hernandez, Modeling behavioral change and COVID-19 containment in Mexico: A trade-off between lockdown and compliance, Math. Biosci., (2020), 108370. |
| [36] | C. Xinghua, M. Liu, Z. Jin, J. Wang, Studying on the impact of media coverage on the spread of COVID-19 in Hubei Province, China, Math. Biosci. Eng., 17 (2020), 3147-3159. |
| [37] | S. Khajanchi, K. Sarkar, Forecasting the daily and cumulative number of cases for the COVID-19 pandemic in India, Chaos, 30 (2020), 071101. |
| [38] | K. Sarkar, S. Khajanchi, J.-J. Nieto, Modeling and forecasting the COVID-19 pandemic in India, Chaos, Soliton. Fract., 139 (2020), 110049. |
| [39] | T. Sardar, S.-S. Nadim, S. Rana, J. Chattopadhyay, Assessment of Lockdown Effect in Some States and Overall India: A Predictive Mathematical Study on COVID-19 Outbreak, Chaos, Soliton. Fract., 139 (2020), 110078. |
| [40] | Z. Shuai, P. V. D. Driessche, Global stability of infectious disease models using Lyapunov functions, SIAM J. Appl. Math., 73 (2013), 1513-1532. |
| [41] | S. Mandal, T. Bhatnagar, N. Arinaminpathy, A. Agarwal, A. Chowdhury, M. Murhekar, et al., Prudent public health intervention strategies to control the coronavirus disease 2019 transmission in India: A mathematical model-based approach, Indian J. Med. Res., 151 (2020), 190. |
| [42] | Worldometer, Coronavirus Cases, India, available from: https://www.worldometers.info/coronavirus/country/india/. |
| [43] | J. P. LaSalle, The stability of dynamical systems, Philadelphia, Society of Industrial and Applied Mathematics, 1976. |
| [44] | J. Guckenheimer, P. Holmes, Nonlinear Oscilations, Dynamical Systems, and Bifurcations of Vector Fields, Springer, New York, 1983. |
| [45] | O. Diekmann, J. A. P. Heesterbeek, M. G. Roberts, The construction of next-generation matrices for compartmental epidemic models, J. R. Soc. Interface, 7 (2010), 873-885. |
| [46] | M. Hou, G. Duan, M. Guo, New versions of Barbalat's lemma with applications, J. Control Theory Appl., 8 (2010), 545-547. |
| [47] | S. Marino, A methodology for performing global uncertainty and sensitivity analysis in systems biology, J. Theor. Biol., 254 (2008), 178-196. |
| [48] | H. Haario, M. Laine, A. Mira, DRAM: Efficient adaptive MCMC, Stat. Comput., 16 (2006), 339- 354. |
| [49] | D. Gamerman, H. F. Lopes, Markov chain Monte Carlo: stochastic simulation for Bayesian inference, Taylor and Francis Group, London New York, 2006. |
| [50] | Z.-G. Guo, G.-Q. Sun, Z. Wang, Z. Jin, L. Li, C. Li, Spatial dynamics of an epidemic model with nonlocal infection, Appl. Math. Comput., 377 (2020), 125158. |
| [51] | G.-Q. Sun, M. Jusup, Z. Jin, Y. Wang, Z. Wang, Pattern transitions in spatial epidemics: Mechanisms and emergent properties, Phys. Life Rev., 19 (2016), 43-73. |
| [52] | S. Contreras, H. A. Villavicencio, D. Medina-Ortiz, J.P. Biron-Lattes, A. Olivera-Nappa, A multigroup SEIRA model for the spread of COVID-19 among heterogeneous populations, Chaos, Soliton. Fract., 136 (2020), 109925. |
| [53] | H. Guliyev, Determining the spatial effects of COVID-19 using the spatial panel data model, Spat. Stat., 38 (2020), 100443. |
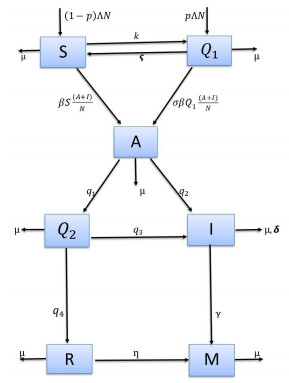
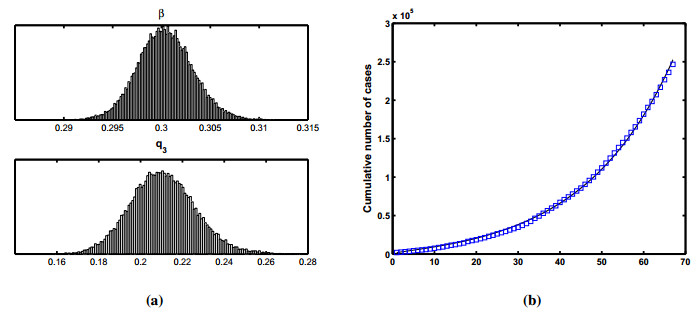
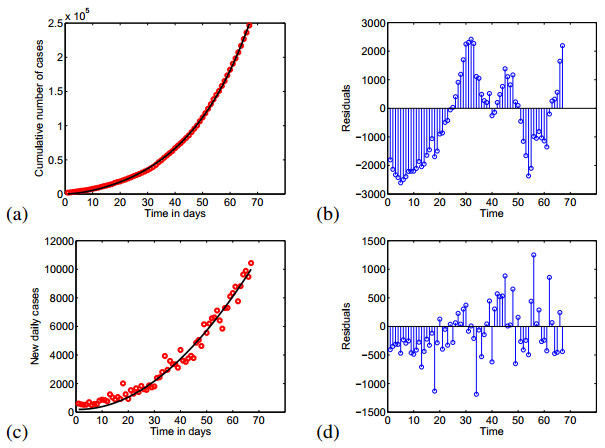
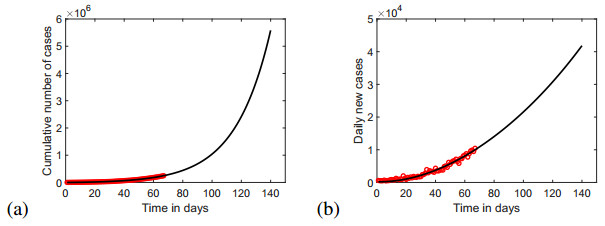


Figures(12) / Tables(4)

Sarita Bugalia, Vijay Pal Bajiya, Jai Prakash Tripathi, Ming-Tao Li, Gui-Quan Sun. Mathematical modeling of COVID-19 transmission: the roles of intervention strategies and lockdown[J]. Mathematical Biosciences and Engineering, 2020, 17(5): 5961-5986. doi: 10.3934/mbe.2020318







 DownLoad:
DownLoad: