Citation: Ayu Azera Izad, Rosimah Nulit, Che Azurahanim Che Abdullah, A'fifah Abdul Razak, Teh Huey Fang, Mohd Hafiz Ibrahim. Growth, leaf gas exchange and biochemical changes of oil palm (Elaeis guineensis Jacq.) seedlings as affected by iron oxide nanoparticles[J]. AIMS Materials Science, 2019, 6(6): 960-984. doi: 10.3934/matersci.2019.6.960

| [1] |
Rastogi A, Zivcak M, Sytar O, et al. (2017) Impact of metal and metal oxide nanoparticles on plant: a critical review. Front Chem 5: 78. doi: 10.3389/fchem.2017.00078

|
| [2] |
Etheridge ML, Campbell SA, Erdman AG, et al. (2013) The big picture on nanomedicine: the state of investigational and approved nanomedicine products. Nanomed: Nanotechnol, Biol Med 9: 1-14. doi: 10.1016/j.nano.2012.05.013
|
| [3] |
Roco MC (2005) International perspective on government nanotechnology funding in 2005. J Nanopart Res 7: 707-712. doi: 10.1007/s11051-005-3141-5
|
| [4] |
Maynard AD, Aitken RJ, Butz T, et al. (2006) Safe handling of nanotechnology. Nature 444: 267-269. doi: 10.1038/444267a
|
| [5] |
Faraji M, Yamini Y, Rezaee M (2010) Magnetic nanoparticles: synthesis, stabilization, functionalization, characterization, and applications. J Iran Chem Soc 7: 1-37. doi: 10.1007/BF03245856
|
| [6] | Nidhin M, Indumathy R, Sreeram KJ, et al. (2008) Synthesis of iron oxide nanoparticles of narrow size distribution on polysaccharide templates. Bull Mater Sci 31: 93-96. |
| [7] |
Xu Y, Qin Y, Palchoudhury S, et al. (2011) Water-soluble iron oxide nanoparticles with high stability and selective surface functionality. Langmuir 27: 8990-8997. doi: 10.1021/la201652h
|
| [8] | Scott N, Chen H (2012) Nanoscale science and engineering for agriculture and food systems. Ind Biotechnol 8: 340-343. |
| [9] |
Rizwan M, Ali S, Ali B, et al. (2019) Zinc and iron oxide nanoparticles improved the plant growth and reduced the oxidative stress and cadmium concentration in wheat. Chemosphere 214: 269-277. doi: 10.1016/j.chemosphere.2018.09.120
|
| [10] | Zareii FD, Roozbahani A, Hosnamidi A (2014) Evaluation the effect of water stress and foliar application of Fe nanoparticles on yield, yield components and oil percentage of safflower (Carthamus tinctorious L.). Int J Adv Biol Biom Res 2: 1150-1159. |
| [11] |
Vasconcelos MW, Grusak MA (2014) Morpho-physiological parameters affecting iron deficiency chlorosis in soybean (Glycine max L.). Plant Soil 374: 161-172. doi: 10.1007/s11104-013-1842-6
|
| [12] | Rui M, Ma C, Hao Y, et al. (2016) Iron oxide nanoparticles as a potential iron fertilizer for peanut (Arachis hypogaea). Front Plant Sci 7: 815. |
| [13] | Kavian B. Negahdar, Ghaziani MVF (2014) The effect of iron nano-chelate and cycocel on some morphological and physiological characteristics, proliferation and enhancing the quality of Euphorbia pulcherrima Willd. Sci Pap Ser B Hortic 58: 337-342. |
| [14] |
Bombin S, LeFebvre M, Sherwood J, et al. (2015) Developmental and reproductive effects of iron oxide nanoparticles in Arabidopsis thaliana. Int J Mol Sci 16: 24174-24193. doi: 10.3390/ijms161024174
|
| [15] |
Antisari LV, Carbone S, Gatti A, et al. (2015) Uptake and translocation of metals and nutrients in tomato grown in soil polluted with metal oxide (CeO2, Fe3O4, SnO2, TiO2) or metallic (Ag, Co, Ni) engineered nanoparticles. Environ Sci Pollut Res 22: 1841-1853. doi: 10.1007/s11356-014-3509-0
|
| [16] |
El-Temsah YS, Joner EJ (2012) Impact of Fe and Ag nanoparticles on seed germination and differences in bioavailability during exposure in aqueous suspension and soil. Environ Toxicol 27: 42-49. doi: 10.1002/tox.20610
|
| [17] |
Ren HX, Liu L, Liu C, et al. (2011) Physiological investigation of magnetic iron oxide nanoparticles towards Chinese mung bean. J Biomed Nanotechnol 7: 677-684. doi: 10.1166/jbn.2011.1338
|
| [18] |
Kim JH, Lee Y, Kim EJ. et al. (2014). Exposure of iron nanoparticles to Arabidopsis thaliana enhances root elongation by triggering cell wall loosening. Environ Sci Technol 48: 3477-3485. doi: 10.1021/es4043462
|
| [19] |
García A, Espinosa R, Delgado L, et al. (2011) Acute toxicity of cerium oxide, titanium oxide and iron oxide nanoparticles using standardized tests. Desalination 269: 136-141. doi: 10.1016/j.desal.2010.10.052
|
| [20] | Trujillo-Reyes J, Majumdar S, Botez CE, et al. (2014) Exposure studies of core-shell Fe/Fe3O4 and Cu/CuO NPs to lettuce (Lactuca sativa) plants: are they a potential physiological and nutritional hazard? J Hazard Mater 267: 255-263. |
| [21] | Popova LV, Popkova EG, Dubova YI, et al. (2016) Financial mechanisms of nanotechnology development in developing countries. J Appl Econ Sci 11: 584-590. |
| [22] | Bottero JY, Auffan M, Borschnek D, et al. (2015) Nanotechnology, global development in the frame of environmental risk forecasting. A necessity of interdisciplinary researches. C R Geosci 347: 35-42. |
| [23] |
Ma X, Geisler-Lee J, Deng Y, et al. (2010) Interactions between engineered nanoparticles (ENPs) and plants: phytotoxicity, uptake and accumulation. Sci Total Environ 408: 3053-3061. doi: 10.1016/j.scitotenv.2010.03.031
|
| [24] |
Maxwell K, Johnson GN (2000) Chlorophyll fluorescence-a practical guide. J Exp Bot 51: 659-668. doi: 10.1093/jexbot/51.345.659
|
| [25] |
Hayat S, Hayat Q, Alyemeni MN, et al. (2012) Role of proline under changing environments: a review. Plant Signaling Behav 7: 1456-1466. doi: 10.4161/psb.21949
|
| [26] |
Zain N, Ismail M, Mahmood M, et al. (2014) Alleviation of water stress effects on MR220 rice by application of periodical water stress and potassium fertilization. Molecules 19: 1795-1819. doi: 10.3390/molecules19021795
|
| [27] |
Kong W, Liu F, Zhang C, et al. (2016) Non-destructive determination of Malondialdehyde (MDA) distribution in oilseed rape leaves by laboratory scale NIR hyperspectral imaging. Sci Rep 6: 35393. doi: 10.1038/srep35393
|
| [28] |
Ibrahim MH, Jaafar HZE (2012) Reduced photoinhibition under low irradiance enhanced Kacip fatimah (Labisia pumila Benth) secondary metabolites, phenyl alanine lyase and antioxidant activity. Int J Mol Sci 13: 5290-5306. doi: 10.3390/ijms13055290
|
| [29] | Ibrahim MH, Jaafar HZE, Rahmat A, et al. (2011) The relationship between phenolics and flavonoids production with total non-structural carbohydrate and photosynthetic rate in Labisia pumila Benth. Under high CO2 and nitrogen fertilization. Molecules 16: 162-174. |
| [30] | Baskar V, Venkatesh R, Ramalingam S (2018) Flavonoids (antioxidants systems) in higher plants and their response to stresses, In: Gupta DK, Palma JM, Corpas FJ, Antioxidants and antioxidant enzymes in higher plants, New York: Springer, 253-268. |
| [31] | Ibrahim MH, Jaafar HZE (2012) Primary, secondary metabolites, H2O2, malondialdehyde and photosynthetic responses of Orthosiphon stamineus Benth. To different irradiance levels. Molecules 17:1159-1176. |
| [32] |
Bienfait HF, van den Briel W. Mesland-Mul NT (1985) Free space iron pools in roots: generation and mobilization. Plant Physiol 78: 596-600. doi: 10.1104/pp.78.3.596
|
| [33] | Corley RHV, Tinker PBH (2003) Mineral nutrition of oil palms, In: The Oil Palm, 4 Eds., Blackwell Science, 327-354. |
| [34] | Iannone MF, Groppa MD, de Sousa ME, et al. (2016) Impact of magnetite iron oxide nanoparticles on wheat (Triticum aestivum L.) development: evaluation of oxidative damage. Environ Exp Bot 131: 77-88. |
| [35] | Ghafariyan MH, Malakouti MJ, Dadpour MR, et al. (2013) Effects of magnetite nanoparticles on soybean chlorophyll. Environ Sci Technol 47: 10645-10652. |
| [36] | Vasconcelos MW, Grusak MA (2014) Morpho-physiological parameters affecting iron deficiency chlorosis in soybean (Glycine max L.). Plant Soil 374 : 161-172. |
| [37] | Mukherjee A, Peralta-Videa JR. Bandyopadhyay S, et al. (2014) Physiological effects of nanoparticulate ZnO in green peas (Pisum sativum L.) cultivated in soil. Metallomics 6: 132-138. |
| [38] |
Ma J, Stiller J, Berkman PJ, et al. (2013) Sequence-based analysis of translocations and inversions in bread wheat (Triticum aestivum L.). PloS one 8: e79329. doi: 10.1371/journal.pone.0079329
|
| [39] |
Nair PMG, Chung IM (2014) Impact of copper oxide nanoparticles exposure on Arabidopsis thaliana growth, root system development, root lignificaion, and molecular level changes. Environ Sci Pollut Res 21: 12709-12722. doi: 10.1007/s11356-014-3210-3
|
| [40] |
Servin AD, Morales MI, Castillo-Michel H, et al. (2013) Synchrotron verification of TiO2 accumulation in cucumber fruit: a possible pathway of TiO2 nanoparticle transfer from soil into the food chain. Environ Sci Technol 47: 11592-11598. doi: 10.1021/es403368j
|
| [41] |
Jacob DL, Borchardt JD, Navaratnam L, et al. (2013) Uptake and translocation of Ti from nanoparticles in crops and wetland plants. Int J Phytorem 15: 142-153. doi: 10.1080/15226514.2012.683209
|
| [42] |
Ainsworth EA, Rogers A (2007) The response of photosynthesis and stomatal conductance to rising [CO2]: mechanisms and environmental interactions. Plant, Cell Environ 30: 258-270. doi: 10.1111/j.1365-3040.2007.01641.x
|
| [43] |
Schlüter U, Muschak M, Berger D, et al. (2003) Photosynthetic performance of an Arabidopsis mutant with elevated stomatal density (sdd1-1) under different light regimes. J Exp Bot 54: 867-874. doi: 10.1093/jxb/erg087
|
| [44] |
Xu Z, Zhou G (2008) Responses of leaf stomatal density to water status and its relationship with photosynthesis in a grass. J Exp Bot 59: 3317-3325. doi: 10.1093/jxb/ern185
|
| [45] |
Khan MIR, Iqbal N, Masood A, et al. (2013) Salicylic acid alleviates adverse effects of heat stress on photosynthesis through changes in proline production and ethylene formation. Plant Signaling Behav 8: e26374. doi: 10.4161/psb.26374
|
| [46] |
Urrego-Pereira YF, Martínez-Cob A, Fernández V, et al. (2013) Daytime sprinkler irrigation effects on net photosynthesis of maize and alfalfa. Agron J 105: 1515-1528. doi: 10.2134/agronj2013.0119
|
| [47] | Izad AI, Ibrahim MH, Abdullah CAC, et al. (2018) Growth, leaf gas exchange and secondary metabolites of Orthosiphon stamineus as affected by multiwall carbon nanotubes application. Annu Res Rev Biol 23: 1-13. |
| [48] |
Hanson DT, Stutz SS, Boyer JS (2016) Why small fluxes matter: the case and approaches for improving measurements of photosynthesis and (photo) respiration. J Exp Bot 67: 3027-3039. doi: 10.1093/jxb/erw139
|
| [49] |
Farquhar GD, von Caemmerer S, Berry JA (1980) A biochemical model of photosynthetic CO2 assimilation in leaves of C3 species. Planta 149: 78-90. doi: 10.1007/BF00386231
|
| [50] | Sikuku PA, Netondo GW, Onyango JC, et al. (2010) Chlorophyll fluorescence, protein and chlorophyll content of three rainfed rice varieties under varying irrigation regimes. J Agric Biol Sci 5: 19-25. |
| [51] |
Strasser RJ, Stirbet AD (1998) Heterogeneity of photosystem Ⅱ probed by the numerically simulated chlorophyll a fluorescence rise (O-J-I-P). Math Comput Simulat 48: 3-9. doi: 10.1016/S0378-4754(98)00150-5
|
| [52] |
Peterson RB, Havir EA (2003) Contrasting modes of regulation of PS Ⅱ light utilization with changing irradiance in normal and psbS mutant leaves of Arabidopsis thaliana. Photosynth Res 75: 57-70. doi: 10.1023/A:1022458719949
|
| [53] |
Tezera W, Mitchell V, Driscoll SP, et al. (2002) Effects of water deficit and its interaction with CO2 supply on the biochemistry and physiology of photosynthesis in sunflower. J Exp Bot 53: 1781-1791. doi: 10.1093/jxb/erf021
|
| [54] |
Kalaji HM, Oukarroum A, Alexandrov V, et al. (2014) Identification of nutrient deficiency in maize and tomato plants by in vivo chlorophyll a fluorescence measurements. Plant Physiol Biochem 81: 16-25. doi: 10.1016/j.plaphy.2014.03.029
|
| [55] |
Msilini N, Zaghdoudi M, Govindachary S, et al. (2011) Inhibition of photosynthetic oxygen evolution and electron transfer from the quinone acceptor QA to QB by iron deficiency. Photosynth Res 107: 247-256. doi: 10.1007/s11120-011-9628-2
|
| [56] |
Yadavalli V, Neelam S, Rao ASVC, et al. (2012) Differential degradation of photosystem I subunits under iron deficiency in rice. J Plant Physiol 169: 753-759. doi: 10.1016/j.jplph.2012.02.008
|
| [57] |
Barhoumi N, Labiadh L, Oturan MA, et al. (2015) Electrochemical mineralization of the antibiotic levofloxacin by electro-Fenton-pyrite process. Chemosphere 141: 250-257. doi: 10.1016/j.chemosphere.2015.08.003
|
| [58] | Kobayashi T, Nishizawa NK (2012) Iron uptake, translocation, and regulation in higher plants. Annu Rev Plant Biol 63: 131-152. |
| [59] | Briat JF, Ravet K, Arnaud N, et al. (2009) New insights into ferritin synthesis and function highlight a link between iron homeostasis and oxidative stress in plants. Ann Bot 105: 811-822. |
| [60] |
Soliman AS, El-feky SA, Darwish E (2015) Alleviation of salt stress on Moringa peregrina using foliar application of nanofertilizers. J Hort For 7: 36-47. doi: 10.5897/JHF2014.0379
|
| [61] |
Yoshida Y, Kioyoshue T, Katagiri T. et al. (1995) Correlation between the induction of a gene for Δ1-pyrroline-5-carboxylate synthase and the accumulation of proline in Arabidopsis thaliana under osmotic stress. Plant J 7: 751-760. doi: 10.1046/j.1365-313X.1995.07050751.x
|
| [62] |
Hayat S, Hayat Q, Alyemeni MN, et al. (2012) Role of proline under changing environments: a review. Plant Signaling Behav 7: 1456-1466. doi: 10.4161/psb.21949
|
| [63] |
Jaafar HZ, Ibrahim MH, Fakri M, et al. (2012) Impact of soil field water capacity on secondary metabolites, phenylalanine ammonia-lyase (PAL), maliondialdehyde (MDA) and photosynthetic responses of Malaysian Kacip Fatimah (Labisia pumila Benth). Molecules 17: 7305-7322. doi: 10.3390/molecules17067305
|
| [64] |
Jones CG, Hartley SE (1999) A protein competition model of phenolic allocation. Oikos 86: 27-44. doi: 10.2307/3546567
|
| [65] |
Bharti AK, Khurana JP (2003) Molecular characterization of transparent testa (tt) mutants of Arabidopsis thaliana (ecoype Estland) impaired in flavonoid biosynthesic pathway. Plant Sci 165: 1321-1332. doi: 10.1016/S0168-9452(03)00344-3
|
| [66] |
Palmqvis NGM, Seisenbaeva GA, Svedlindh P, et al. (2017) Maghemite nanoparticles acts as nanozymes, improving growth and abiotic stress tolerance in Brassica napus. Nanoscale Res Lett 12: 631. doi: 10.1186/s11671-017-2404-2
|
| [67] | Rui M, Ma C, Hao Y, et al. (2016) Iron oxide nanoparticles as a potential iron fertilizer for peanut (Arachis hypogaea). Front Plant Sci 7: 815. |
| [68] |
Ghasemzadeh A, Jaafar HZE, Rahmat A (2010) Antioxidant activities, total phenolics and flavonoids content in two varieties of malaysia young ginger (Zingiber officinale Roscoe). Molecules 15: 4324-4333. doi: 10.3390/molecules15064324
|
| [69] |
Guo R, Yuan G, Wang Q (2011) Effect of sucrose and mannitol on the accumulation of health-promoting compounds and the activity of metabolic enzymes in broccoli sprouts. Sci Hort 128: 159-165. doi: 10.1016/j.scienta.2011.01.014
|
| [70] |
Nguyen GN, Hailstones DL, Wilkes M, et al. (2010) Drought stress: role of carbohydrate metabolism in drought-induced male sterility in rice anthers. J Agron Crop Sci 196: 346-357. doi: 10.1111/j.1439-037X.2010.00423.x
|
| [71] |
Akula R, Ravishanka GA (2011) Influence of abiotic stress signals on secondary metabolites in plants. Plant Signaling Behav 6: 1720-1731. doi: 10.4161/psb.6.11.17613
|
| [72] | Kubalt K (2016) The role of phenolic compounds in plant resistance. Biotechnol Food Sci 80: 97-108. |
| [73] | Lattanzio V, Lattanzio VMT, Cardinali A (2006) Role of phenolics in the resistance mechanisms of plants against fungal pathogens and insects. Phytochem: Adv in Res 661: 23-67. |
| [74] |
Ghorbanpour M, Hadian J (2015) Multi-walled carbon nanotubes stimulate callus induction, secondary metabolites biosynthesis and antioxidant capacity in medicinal plant Satureja khuzestanica grown in vitro. Carbon 94: 749-759. doi: 10.1016/j.carbon.2015.07.056
|
| [75] |
Moore MN (2006) Do nanoparticles present ecotoxicological risks for the health of the aquatic environment? Environ Int 32: 967-976. doi: 10.1016/j.envint.2006.06.014
|
| [76] | Chinnamuthu CR, Boopathi PM (2009) Nanotechnology and agroecosystem. Madras Agric J 96: 17-31. |
| [77] |
Kanazawa K, Hashimoto T, Yoshida S, et al. (2012) Short photoirradiation induces flavonoid synthesis and increases its production in postharvest vegetables. J Agri Food Chem 60: 4359-4368. doi: 10.1021/jf300107s
|
| [78] | Xie Y, Xu D, Cui W, et al. (2012) Mutation of Arabidopsis HY1 causes UV-C hypersensitivity by impairing carotenoid and flavonoid biosynthesis and the down-regulation of antioxidant defence. J ExpBotany 63: 3869-3883. |
| [79] | Kefeli VI, Kalevitch MV, Borsari B (2003) Phenolic cycle in plants and environment. J Cell Mol Biol 2: 13-18. |
| [80] | Adamski JM, Peters JA, Danieloski R, et al. (2011) Excess iron-induced changes in the photosynthetic characteristics of sweet potato. J Plant Physiol 168: 2056-2062. |
| [81] |
Hänsch R, Mendel RR (2009) Physiological functions of mineral micronutrients (Cu, Zn, Mn, Fe, Ni, Mo, B, Cl). Curr Opin Plant Biol 12: 259-266. doi: 10.1016/j.pbi.2009.05.006
|
| [82] |
Briat JF, Curie C, Gaymard F (2007) Iron utilization and metabolism in plants. Curr Opin Plant Biol 10: 276-282. doi: 10.1016/j.pbi.2007.04.003
|
| [83] |
Kobayashi T, Nozoye T, Nishizawa NK (2019) Iron transport and its regulation in plants. Free Radical Biol Med 133: 11-20. doi: 10.1016/j.freeradbiomed.2018.10.439
|
| [84] |
Nenova VR (2009) Growth and photosynthesis of pea plants under different iron supply. Acta Physiol Plant 31: 385. doi: 10.1007/s11738-008-0247-2
|
| [85] | Chatterjee C, Gopal R, Dube BK (2006) Impact of iron stress on biomass, yield, metabolism and quality of potato (Solanum tuberosum L.). Sci Hortic 108: 1-6. |
| [86] | Xing W, Huang WM, Liu GH (2010) Effect of excess iron and copper on physiology of aquatic plant Spirodela polyrrhiza (L.) Schleid. Environ Toxicol 25: 103-112. |
| [87] | Prasad MNV, Strzalka K (1999) Impact of heavy metals on photosynthesis. In: Prasad MNV, Hagemeyer J, Heavy Metal stress in Plants: from Molecules to Ecosystems. Berlin-Heidelberg: Springer Verlag, 117-138. |
| [88] |
Robello E, Galatro A, Puntarulo S (2007) Iron role in oxidative metabolism of soybean axes upon growth: effect of iron overload. Plant Sci 172: 939-947. doi: 10.1016/j.plantsci.2007.01.003
|
| [89] |
Fang WC, Wang JW, Lin CC, et al. (2001) Iron induction of lipid peroxidation and effects on antioxidative enzyme activities in rice leaves. Plant Growth Regul 35: 75-80. doi: 10.1023/A:1013879019368
|
| [90] | Yin XL, Wang JX, Duan ZQ, et al. (2006) Study on the stomatal density and daily change rule of the wheat. Chin Agric Sci Bull 22: 237-242. |
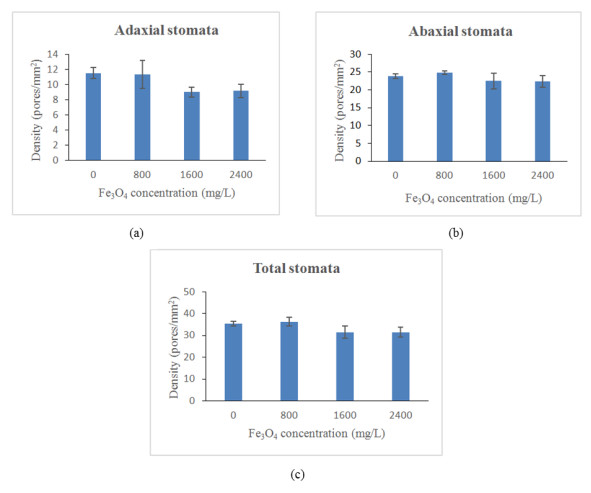
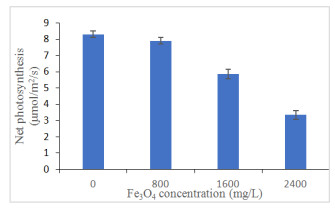
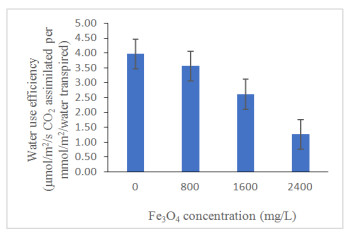


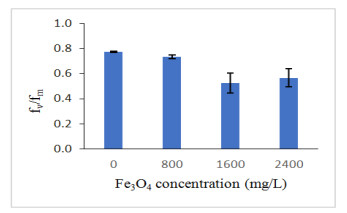
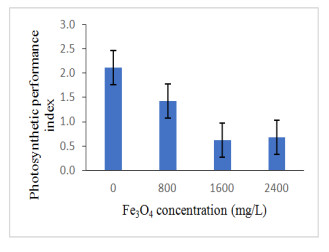

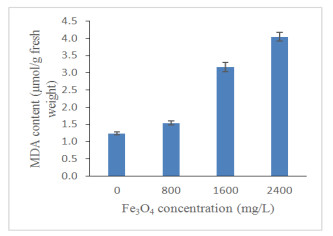

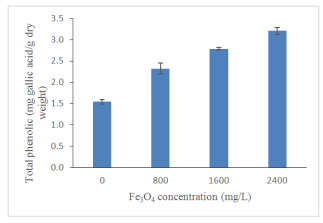
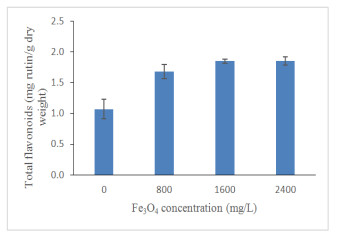
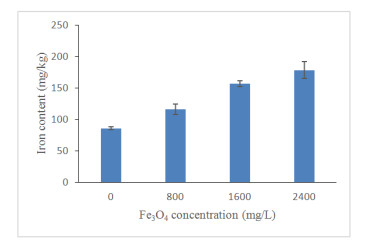
Figures(13) / Tables(4)

Ayu Azera Izad, Rosimah Nulit, Che Azurahanim Che Abdullah, A'fifah Abdul Razak, Teh Huey Fang, Mohd Hafiz Ibrahim. Growth, leaf gas exchange and biochemical changes of oil palm (Elaeis guineensis Jacq.) seedlings as affected by iron oxide nanoparticles[J]. AIMS Materials Science, 2019, 6(6): 960-984. doi: 10.3934/matersci.2019.6.960







 DownLoad:
DownLoad: