Citation: Peng-Yeng Yin, Chih-Chun Tsai, Rong-Fuh Day, Ching-Ying Tung, Bir Bhanu. Ensemble learning of model hyperparameters and spatiotemporal data for calibration of low-cost PM2.5 sensors[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6858-6873. doi: 10.3934/mbe.2019343

| [1] | C. Song, J. He, L. Wu, et al., Health burden attributable to ambient PM2.5 in China, Environ. Pollut., 223 (2017), 575–586. |
| [2] | IPCC, Climate Change 2007: the Scientific Basis, Contribution of Working Group I, in Third Assessment Report of the Intergovernmental Panel on Climate Change (eds. J. T. Houghton, Y. Ding, D. J. Griggs, et al.), Cambridge University, New York (2007). |
| [3] | Y. J. Liu, T. T. Zhang, Q. Y. Liu, et al., Seasonal variation of physical and chemical properties in TSP, PM10 and PM2.5 at a roadside site in Beijing and their influence on atmospheric visibility, Aerosol Air Qual. Res., 14 (2014), 954–969. |
| [4] | L. Mo, Z. Ma, Y. Xu, et al., Assessing the capacity of plant species to accumulate particulate matter in Beijing, China, PLoS One, 10 (2015), 0140664. |
| [5] | K. Hu, A. Rahman, H. Bhrugubanda, et al., HazeEst machine learning based metropolitan air pollution estimation from fixed and mobile sensors, IEEE Sens. J., 17 (2017), 3517–3525. |
| [6] | M. Miksys, Predictions of PM2.5 and PM10 concentrations using static and mobile sensors, Technical Report, School of Informatics, University of Edinburgh, (2016). |
| [7] | L. J. Chen, Y. H. Ho, H. C. Lee, et al., An open framework for participatory PM2.5 monitoring in smart cities, IEEE Access, 5 (2017), 14441–14454. |
| [8] | S. Ausati and J. Amanollahi, Assessing the accuracy of ANFIS, EEMD-GRNN, PCR, and MLR models in predicting PM2.5, Atmos. Environ., 142 (2016), 465–474. |
| [9] | H. W. Barker, Isolating the industrial contribution of PM2.5 in Hamilton and Burlington, Ontario J. Appl. Meteorol. Climatol., 52 (2013), 660–667. |
| [10] | M. Jerrett, R.T. Burnett, R. Ma, et al., Spatial analysis of air pollution and mortality in Los Angeles, Epidemiology, 16 (2005), 727–736. |
| [11] | A. Di Antonio, O. Popoola, B. Ouyang, et al., Developing a relative humidity correction for low-cost sensors measuring ambient particulate matter, Sensors, 18 (2018), 2790. |
| [12] | G. J. Hwang and S. S. Tseng, A heuristic task-assignment algorithm to maximize reliability of a distributed system, IEEE T. Reliab., 42 (1993), 408–416. |
| [13] | I. Eekhout and R. M. de Boer, Missing data: a systematic review of how they are reported and handled, Epidemiology, 23 (2012), 729–732. |
| [14] | H. Shen, X. Li and Q. Cheng, Missing information reconstruction of remote sensing data: A technical review, IEEE Geosc. Rem. Sen. M., 3 (2015), 61–85. |
| [15] | S. A. Dudani, The distance-weighted k-nearest-neighbor rule, IEEE T. Syst. Man. Cy., 4 (1976), 325–327. |
| [16] | M. J. Azur, E. A. Stuart, C. Frangakis, et al., Multiple imputation by chained equations: what is it and how does it work? Int. J. Meth. Psych. Res., 20 (2011), 40–49,. |
| [17] | R. Mazumder, T. Hastie and R. Tibshirani, Spectral regularization algorithms for learning large incomplete matrices, J. Mach. Learn. Res., (2010), 2287–2322. |
| [18] | P. F. Pai, K. P. Lin, C. S. Lin, et al., Time series forecasting by a seasonal support vector regression model, Expert Syst. Appl., 37 (2010), 4261–4265. |
| [19] | J. Friedman, Greedy function approximation: a gradient boosting machine. Ann. Stat., 29 (2001), 1189–1232. |
| [20] | T. Chen and C. Guestrin, XGBoost: A scalable tree boosting system, in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD2016), San Francisco, USA, (2016). |
| [21] | R. Bekkerman, The present and the future of the KDD cup competition: an outsider's perspective. Available from: https://www.linkedin.com/pulse/present-future-kdd-cup-competition-outsiders-ron-bekkerman . Commentary from Linkedin at on Aug. 25, 2015. |
| [22] | J. Bergstra and Y. Bengio, Random search for hyper-parameter optimization, J. Mach. Learn. Res., (2012), 281–305. |
| [23] | H. Wang, Q. Geng and Z. Qiao, Parameter tuning of particle swarm optimization by using Taguchi method and its application to motor design, in Proceedings of the 4th IEEE International Conference on Information Science and Technology, (2014). |
| [24] | J. Safarik, J. Jalowiczor, E. Gresak, et al., Genetic algorithm for automatic tuning of neural network hyperparameters, in Proceedings of SPIE Autonomous Systems: Sensors, Vehicles, Security, and the Internet of Everything, (2018). |
| [25] | J. Derrac, S. García and F. Herrera, A Survey on Evolutionary Instance Selection and Generation, Int. J. Appl. Metaheuristic Comput., 1 (2010), 60–92. |
| [26] | J. Kennedy and R. C. Eberhart, Particle swarm optimization, in Proceedings IEEE International Conference on Neural Networks IV, (1995), 1942–1948. |
| [27] | S. Joe and F. Y. Kuo, Remark on algorithm 659: Implementing Sobol's quasirandom sequence generator, ACM T. Math. Software, 1 (2003), 49–57. |
| [28] | J. C. Lagarias, J. A. Reeds, M. H. Wright, et al., Convergence properties of the Nelder-Mead simplex method in low dimensions, SIAM J. Optimiz., 9 (1998), 112–147. |
| [29] | B. K. Tan, Laboratory evaluation of low to medium cost particle sensors, Master's Thesis, University of Waterloo (2017). |
| [30] | K. E. Kelly, J. Whitaker, A. Petty, et al., Ambient and laboratory evaluation of a low-cost particulate matter sensor, Environ. Pollut., 221 (2017), 491–500. |
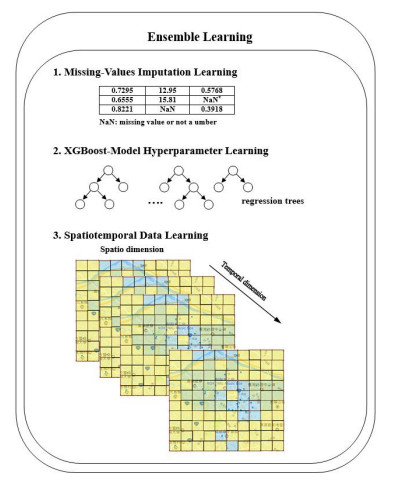

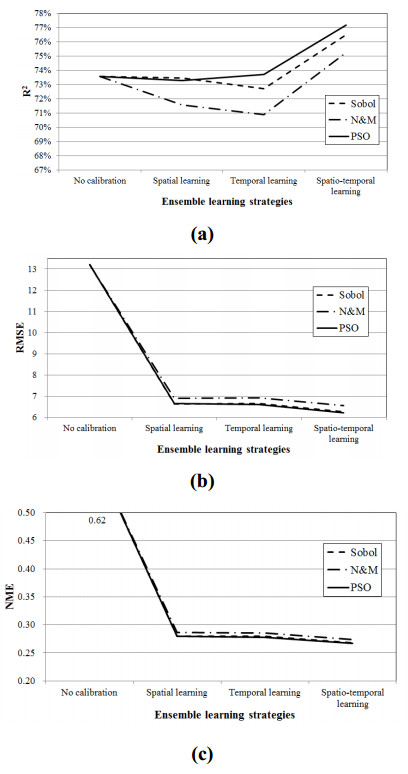
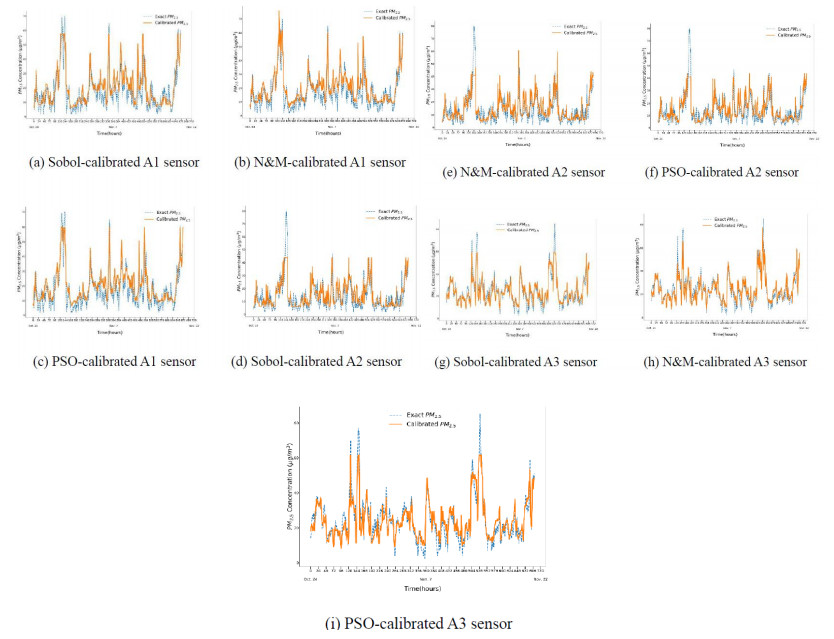
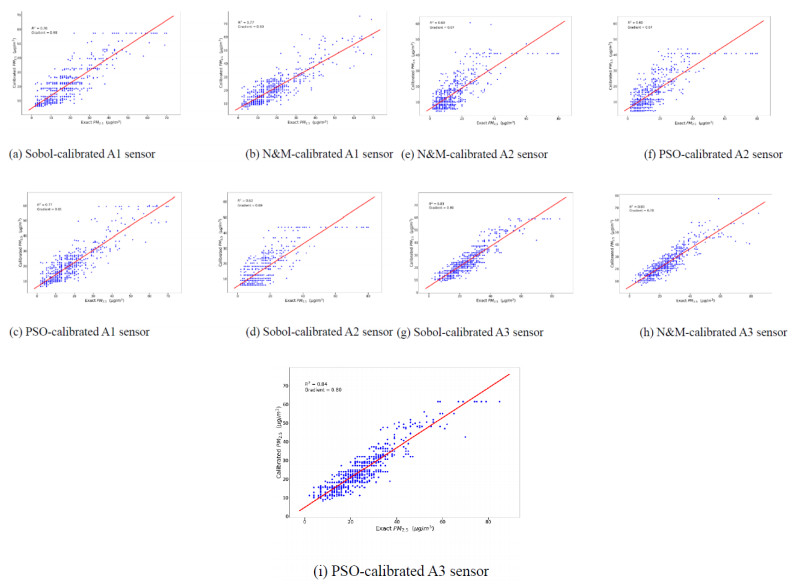
Figures(5) / Tables(5)

Peng-Yeng Yin, Chih-Chun Tsai, Rong-Fuh Day, Ching-Ying Tung, Bir Bhanu. Ensemble learning of model hyperparameters and spatiotemporal data for calibration of low-cost PM2.5 sensors[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 6858-6873. doi: 10.3934/mbe.2019343







 DownLoad:
DownLoad: