Citation: Emil Kowalewski, Małgorzata Zienkiewicz-Machnik, Dmytro Lisovytskiy, Kostiantyn Nikiforov, Krzysztof Matus, Anna Śrębowata, Jacinto Sá. Turbostratic carbon supported palladium as an efficient catalyst for reductive purification of water from trichloroethylene[J]. AIMS Materials Science, 2017, 4(6): 1276-1288. doi: 10.3934/matersci.2017.6.1276

| [1] |
Goszewska I, Giziński D, Zienkiewicz-Machnik M, et al. (2017) A novel nano-palladium catalyst for continuous-flow chemoselective hydrogenation reactions. Catal Commun 94: 65–68. doi: 10.1016/j.catcom.2017.02.014

|
| [2] |
McCue AJ, Guerrero-Ruiz A, Rodríguez-Ramos I, et al. (2016) Palladium sulphide-A highly selective catalyst for the gas phase hydrogenation of alkynes to alkenes. J Catal 340: 10–16. doi: 10.1016/j.jcat.2016.05.002
|
| [3] | Munoz M, Kolb V, Lamolda A, et al. (2017) Polymer-based spherical activated carbon as catalytic support for hydrodechlorination reactions. Appl Catal B-Environ 218: 498–505. |
| [4] |
Kamińska I, Lisovytskiy D, Casale S, et al. (2017) Influence of preparation procedure on catalytic activity of PdBEA zeolites in aqueous phase hydrodechlorination of 1,1,2-trichloroethene. Micropor Mesopor Mat 237: 65–73. doi: 10.1016/j.micromeso.2016.09.023
|
| [5] | Sohn H, Celik G, Gunduz S, et al. (2017) Hydrodechlorination of trichloroethylene over Pd supported on swellable organically-modified silica (SOMS). Appl Catal B-Environ 203: 641–653. |
| [6] |
Sahu RS, Li D, Doong R (2018) Unveiling the hydrodechlorination of trichloroethylene by reduced graphene oxide supported bimetallic Fe/Ni nanoparticles. Chem Eng J 334: 30–40. doi: 10.1016/j.cej.2017.10.019
|
| [7] |
Sahu RS, Bindumadhavan K, Doong R (2017) Boron-doped reduced graphene oxide-based bimetallic Ni/Fe nanohybrids for the rapid dechlorination of trichloroethylene. Environ Sci-Nano 4: 565–576. doi: 10.1039/C6EN00575F
|
| [8] |
Yu X, Wu T, Yang XJ, et al. (2016) Degradation of trichloroethylene by hydrodechlorination using formic acid as hydrogen source over supported Pd catalysts. J Hazard Mater 305: 178–189. doi: 10.1016/j.jhazmat.2015.11.025
|
| [9] |
Juszczyk W, Malinowski A, Karpiński Z (1998) Hydrodechlorination of CCl2F2 (CFC-12) over γ-alumina supported palladium catalysts. Appl Catal A-Gen 166: 311–319. doi: 10.1016/S0926-860X(97)00265-2
|
| [10] |
Aramendıá MA, Boráu V, Garcıá IM, et al. (1999) Influence of the Reaction Conditions and Catalytic Properties on the Liquid-Phase Hydrodechlorination of Chlorobenzene over Palladium-Supported Catalysts: Activity and Deactivation. J Catal 187: 392–399. doi: 10.1006/jcat.1999.2632
|
| [11] |
Baeza JA, Calvo L, Gilarranz MA, et al. (2012) Catalytic behavior of size-controlled palladium nanoparticles in the hydrodechlorination of 4-chlorophenol in aqueous phase. J Catal 293: 85–93. doi: 10.1016/j.jcat.2012.06.009
|
| [12] | Díaz E, Faba L, Ordóñez S (2011) Effect of carbonaceous supports on the Pd-catalyzed aqueous-phase trichloroethylene hydrodechlorination. Appl Catal B-Environ 104: 415–417. |
| [13] |
Ren Y, Fan G, Wang C (2014) Aqueous hydrodechlorination of 4-chlorophenol over an Rh/reduced graphene oxide synthesized by a facile one-pot solvothermal process under mild conditions. J Hazard Mater 274: 32–40. doi: 10.1016/j.jhazmat.2014.04.005
|
| [14] |
Śrębowata A, Kamińska II, Giziński D, et al. (2015) Remarkable effect of soft-templating synthesis procedure on catalytic properties of mesoporous carbon supported Ni in hydrodechlorination of trichloroethylene in liquid phase. Catal Today 251: 60–65. doi: 10.1016/j.cattod.2014.11.005
|
| [15] |
Letellier F, Blanchard J, Fajerwerg K, et al. (2006) Search for confinement effects in mesoporous supports: hydrogenation of o-xylene on Pt/MCM-41. Catal Lett 110: 115–124. doi: 10.1007/s10562-006-0093-z
|
| [16] |
Bonarowska M, Raróg-Pilecka W, Karpiński Z (2011) The use of active carbon pretreated at 2173 K as a support for palladium catalysts for hydrodechlorination reactions. Catal Today 169: 223–231. doi: 10.1016/j.cattod.2010.12.039
|
| [17] |
Guha N, Loomis D, Grosse Y, et al. (2012) International Agency for Research on Cancer Monograph Working Group, Carcinogenicity of trichloroethylene, tetrachloroethylene, some other chlorinated solvents, and their metabolites. Lancet Oncol 13: 1192–1193. doi: 10.1016/S1470-2045(12)70485-0
|
| [18] |
Lash LH, Chiu WA, Guyton KZ, et al. (2014) Trichloroethylene biotransformation and its role in mutagenicity, carcinogenicity and target organ toxicity. Mutat Res-Rev Mutat 762: 22–36. doi: 10.1016/j.mrrev.2014.04.003
|
| [19] |
Rouhou MC, Haddad S (2014) Modulation of trichloroethylene in vitro metabolism by different drugs in human. Toxicol In Vitro 28: 732–741. doi: 10.1016/j.tiv.2014.03.004
|
| [20] |
Bonarowska M, Pielaszek J, Semikolenov VA, et al. (2002) Pd–Au/Sibunit Carbon Catalysts: Characterization and Catalytic Activity in Hydrodechlorination of Dichlorodifluoromethane (CFC-12). J Catal 209: 528–538. doi: 10.1006/jcat.2002.3650
|
| [21] |
Amorim C, Keane MA (2008) Palladium supported on structured and nonstructured carbon: A consideration of Pd particle size and the nature of reactive hydrogen. J Colloid Interf Sci 322: 196–208. doi: 10.1016/j.jcis.2008.02.021
|
| [22] |
Śrębowata A, Tarach K, Girman V, et al. (2016) Catalytic removal of trichloroethylene from water over palladium loaded microporous and hierarchical zeolites. Appl Catal B-Environ 181: 550–560. doi: 10.1016/j.apcatb.2015.08.025
|
| [23] |
Munoz M, Kaspereit M, Etzold BJM (2016) Deducing kinetic constants for the hydrodechlorination of 4-chlorophenol using high adsorption capacity catalysts. Chem Eng J 285: 228–235. doi: 10.1016/j.cej.2015.10.002
|
| [24] |
Munoz M, Zhang GR, Etzold BJM (2017) Exploring the role of the catalytic support sorption capacity on the hydrodechlorination kinetics by the use of carbide-derived carbons. Appl Catal B-Environ 203: 591–598. doi: 10.1016/j.apcatb.2016.10.062
|
| [25] | Molina CB, Pizarro AH, Casas JA, et al. (2014) Aqueous-phase hydrodechlorination of chlorophenols with pillared clays-supported Pt, Pd and Rh catalysts. Appl Catal B-Environ 148–149: 330–338. |
| [26] |
Ordóñez S, Dı́ez F, Sastre H (2001) Characterisation of the deactivation of platinum and palladium supported on activated carbon used as hydrodechlorination catalysts. Appl Catal B-Environ 31: 113–122. doi: 10.1016/S0926-3373(00)00270-8
|
| [27] |
Álvarez-Montero MA, Gómez-Sainero LM, Mayoral A, et al. (2011) Hydrodechlorination of chloromethanes with a highly stable Pt on activated carbon catalyst. J Catal 279: 389–396. doi: 10.1016/j.jcat.2011.02.009
|
| [28] |
Bertolini JC, Delichere P, Khanra BC, et al. (1990) Electronic properties of supported Pd aggregates in relation with their reactivity for 1,3-butadiene hydrogenation. Catal Lett 6: 215–223. doi: 10.1007/BF00774723
|
| [29] |
Ilinicha OM, Gribov EN, Simonov PA (2003) Water denitrification over catalytic membranes: hydrogen spillover and catalytic activity of macroporous membranes loaded with Pd and Cu. Catal Today 82: 49–56. doi: 10.1016/S0920-5861(03)00201-3
|

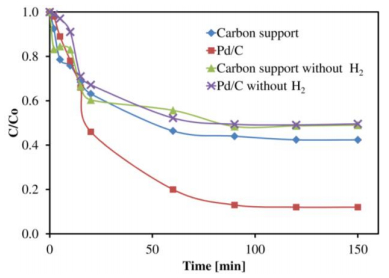
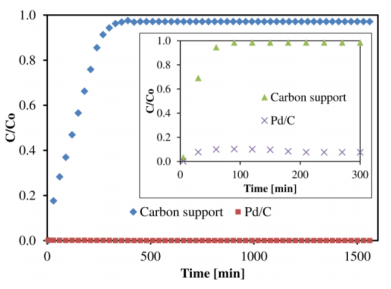
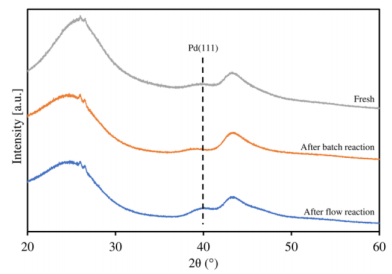

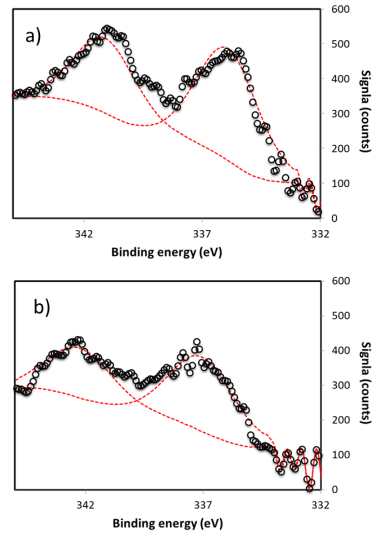
Figures(10) / Tables(1)

Emil Kowalewski, Małgorzata Zienkiewicz-Machnik, Dmytro Lisovytskiy, Kostiantyn Nikiforov, Krzysztof Matus, Anna Śrębowata, Jacinto Sá. Turbostratic carbon supported palladium as an efficient catalyst for reductive purification of water from trichloroethylene[J]. AIMS Materials Science, 2017, 4(6): 1276-1288. doi: 10.3934/matersci.2017.6.1276







 DownLoad:
DownLoad: