Citation: Karent Zorogastua, Pathu Sriphanlop, Alyssa Reich, Sarah Aly, Aminata Cisse, Lina Jandorf. Breast and Cervical Cancer Screening among US and non US Born African American Muslim Women in New York City[J]. AIMS Public Health, 2017, 4(1): 78-93. doi: 10.3934/publichealth.2017.1.78

| [1] | US Cancer Statistics Working Group. (2014) United States cancer statistics: 1999-2010 incidence and mortality web-based report, In: Anonymous, Atlanta (GA): Department of Health and Human Services, Centers for Disease Control and Prevention, and National Cancer Institute. |
| [2] |
Berry DA, Cronin KA, Plevritis SK, et al. (2005) Effect of screening and adjuvant therapy on mortality from breast cancer. N Engl J Med 353: 1784-1792. doi: 10.1056/NEJMoa050518

|
| [3] |
Brawley OW (2012) Risk-based mammography screening: an effort to maximize the benefits and minimize the harms. Ann Intern Med 156: 662-663. doi: 10.7326/0003-4819-156-9-201205010-00012
|
| [4] | Gøtzsche PC, Nielsen M (2009) Screening for breast cancer with mammography. The cochrane library. |
| [5] |
Humphrey LL, Helfand M, Chan BK, et al. (2002) Breast cancer screening: a summary of the evidence for the US Preventive Services Task Force. Ann Intern Med 137: 347-360. doi: 10.7326/0003-4819-137-5_Part_1-200209030-00012
|
| [6] | Cancer prevention & early detection facts & figures 2012, 2012. Available from: http://www.cancer.org/acs/groups/content/@epidemiologysurveilance/documents/document/acspc-033423.pdf. |
| [7] |
Press R, Carrasquillo O, Sciacca RR, et al. (2008) Racial/ethnic disparities in time to follow-up after an abnormal mammogram. J Women's Health 17: 923-930. doi: 10.1089/jwh.2007.0402
|
| [8] |
Stuver SO, Zhu J, Simchowitz B, et al. (2011) Identifying women at risk of delayed breast cancer diagnosis. Jt Comm J Qual Patient Saf 37: 568-568. doi: 10.1016/S1553-7250(11)37073-0
|
| [9] | Fact sheet-cervical cancer, 2010. Available from: http://report.nih.gov/nihfactsheets/viewfactsheet.aspx?csid=76. |
| [10] | National Institutes of Health Consensus Development Panel. (1996) National institutes of health consensus development conference statement: Cervical cancer. J Natl Cancer Inst Monogr 21. |
| [11] | SEER stat fact sheets: Cervix uteri cancer, 2015. Available from: http://seer.cancer.gov/statfacts/html/cervix.html. |
| [12] | Agency for Healthcare Research and Quality. (2008) Cancer screening and treatment in women: Recent findings. |
| [13] |
Gauss JW, Mabiso A, Williams KP (2013) Pap screening goals and perceptions of pain among black, Latina, and Arab women: steps toward breaking down psychological barriers. J Cancer Educ 28: 367-374. doi: 10.1007/s13187-012-0441-1
|
| [14] | International Agency for Research on Cancer. (2005) IARC handbooks of cancer prevention: IARC. |
| [15] |
Hasnain M, Connell KJ, Menon U, et al. (2011) Patient-centered care for Muslim women: provider and patient perspectives. J Women's Health 20: 73-83. doi: 10.1089/jwh.2010.2197
|
| [16] | Matin M, LeBaron S (2004) Attitudes toward cervical cancer screening among Muslim women: a pilot study. Women Health 39: 63-77. |
| [17] |
O'Malley MS, Earp JA, Hawley ST, et al. (2001) The association of race/ethnicity, socioeconomic status, and physician recommendation for mammography: who gets the message about breast cancer screening? Am J Public Health 91: 49-54. doi: 10.2105/AJPH.91.1.49
|
| [18] |
Rajaram SS, Rashidi A (1999) Asian-Islamic women and breast cancer screening: a socio-cultural analysis. Women Health 28: 45-58. doi: 10.1300/J013v28n03_04
|
| [19] |
Rashidi A, Rajaram SS (2000) Middle Eastern Asian Islamic women and breast self-examination: needs assessment. Cancer Nurs 23: 64-70. doi: 10.1097/00002820-200002000-00010
|
| [20] | Shaheen M, Galal O (2005) Practices for early detection of breast camcer among Muslim women in Southern California. Ann Epidemiol 15: 649. |
| [21] | FastStats: Mammography/breast cancer, 2015. Available from: http://www.cdc.gov/nchs/fastats/mammography.htm. |
| [22] | Increase the proportion of women who receive a breast cancer screening based on the most recent guidelines, 2015. Available from: http://www.healthypeople.gov/node/4055/data_details. |
| [23] | Cancer Prevention & Early Detection Facts & Figures 2013, 2013. Available from: http://www.cancer.org/acs/groups/content/@epidemiologysurveilance/documents/document/acspc-037535.pdf. |
| [24] | Padela AI, Murrar S, Adviento B, et al. (2016) Associations between religion-related factors and breast cancer screening among American Muslims. |
| [25] |
Padela AI, Murrar S, Adviento B, et al. (2015) Associations between religion-related factors and breast cancer screening among American Muslims. J Immigr Minor Health 17: 660-669. doi: 10.1007/s10903-014-0014-y
|
| [26] |
Schwartz K, Fakhouri M, Bartoces M, et al. (2008) Mammography screening among Arab American women in metropolitan Detroit. J Immigr Minor Health 10: 541-549. doi: 10.1007/s10903-008-9140-8
|
| [27] | FastStats: Pap tests and cervical cancer, 2015. Available from: http://www.cdc.gov/nchs/fastats/pap-tests.htm. |
| [28] | Women receiving Pap test within past 3 years (age adjusted, percent, 21-65 years), 2015. Available from: https://www.healthypeople.gov/2020/data/Chart/4053?category=2717&by=Total. |
| [29] |
Salman KF (2012) Health beliefs and practices related to cancer screening among Arab Muslim women in an urban community. Health Care Women Int 33: 45-74. doi: 10.1080/07399332.2011.610536
|
| [30] |
Padela AI, Peek M, Johnson-Agbakwu CE, et al. (2014) Associations between religion-related factors and cervical cancer screening among Muslims in greater Chicago. J Low Genit Tract Dis 18: 326-332. doi: 10.1097/LGT.0000000000000026
|
| [31] |
Austin LT, Ahmad F, McNally M, et al. (2002) Breast and cervical cancer screening in Hispanic women: a literature review using the health belief model. Womens Health Issues 12: 122-128. doi: 10.1016/S1049-3867(02)00132-9
|
| [32] |
Behbakht K, Lynch A, Teal S, et al. (2004) Social and cultural barriers to Papanicolaou test screening in an urban population. Obstet Gynecol 104: 1355-1361. doi: 10.1097/01.AOG.0000143881.53058.81
|
| [33] | Chavez LR, Hubbell FA, Mishra SI, et al. (1997) The influence of fatalism on self-reported use of Papanicolaou smears. Am J Prev Med 13: 418-424. |
| [34] |
Nelson K, Geiger AM, Mangione CM (2002) Effect of Health Beliefs on Delays in Care for Abnormal Cervical Cytology in a Multi‐ethnic Population. J Gen Intern Med 17: 709-716. doi: 10.1046/j.1525-1497.2002.11231.x
|
| [35] | Schleicher E (2007) Immigrant women and cervical cancer prevention in the United States. Baltimore: Women's and Children's Health Policy Center, Johns Hopkins Bloomberg School of Public Health. |
| [36] | Suarez L, Roche RA, Nichols D, et al. (1997) Knowledge, behavior, and fears concerning breast and cervical cancer among older low-income Mexican-American women. Am J Prev Med 13: 137-142. |
| [37] | Aroian KJ (2001) Immigrant women and their health. Annu Rev Nurs Res 19: 179-226. |
| [38] | Tannenbaum Center for Interreligious Understanding. (2011) Muslim and Islam in the United States. |
| [39] |
Saslow D, Boetes C, Burke W, et al. (2007) American Cancer Society guidelines for breast screening with MRI as an adjunct to mammography. Ca-Cancer J Clin 57: 75-89. doi: 10.3322/canjclin.57.2.75
|
| [40] |
Saslow D, Solomon D, Lawson HW, et al. (2012) American Cancer Society, American Society for Colposcopy and Cervical Pathology, and American Society for Clinical Pathology screening guidelines for the prevention and early detection of cervical cancer. Ca-Cancer J Clin 62: 147-172. doi: 10.3322/caac.21139
|
| [41] |
Smith RA, Manassaram-Baptiste D, Brooks D, et al. (2014) Cancer screening in the United States, 2014: A review of current American Cancer Society guidelines and current issues in cancer screening. Ca-Cancer J Clin 64: 30-51. doi: 10.3322/caac.21212
|
| [42] |
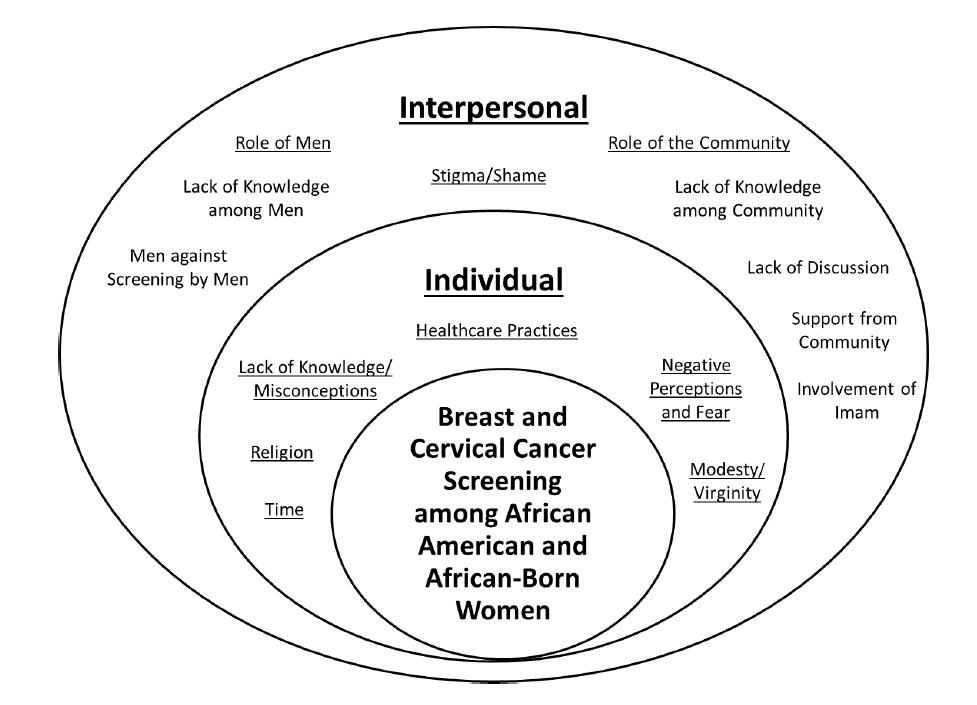
McLeroy KR, Bibeau D, Steckler A, et al. (1988) An ecological perspective on health promotion programs. Health Educ Behav 15: 351-377. doi: 10.1177/109019818801500401
|
| [43] |
Paskett ED, McLaughlin JM, Lehman AM, et al. (2011) Evaluating the efficacy of lay health advisors for increasing risk-appropriate pap test screening: A randomized controlled trial among Ohio Appalachian women. Cancer Epidemiol, Biomarkers Prev 20: 835-843. doi: 10.1158/1055-9965.EPI-10-0880
|
| [44] | Donnelly TT, Al Khater A, Al-Bader SB, et al. (2012) Breast cancer screening among Arabic women living in the State of Qatar: Awareness, knowledge, and participation in screening activities. Bader 2. |
| [45] |
Guimond ME, Salman K (2013) Modesty matters: cultural sensitivity and cervical cancer prevention in Muslim women in the United States. Nurs Women's Health 17: 210-217. doi: 10.1111/1751-486X.12034
|
| [46] |
Winslow WW, Honein G, Elzubeir MA (2002) Seeking Emirati women's voices: the use of focus groups with an Arab population. Qual Health Res 12: 566-575. doi: 10.1177/104973202129119991
|
Figures(1) / Tables(3)

Karent Zorogastua, Pathu Sriphanlop, Alyssa Reich, Sarah Aly, Aminata Cisse, Lina Jandorf. Breast and Cervical Cancer Screening among US and non US Born African American Muslim Women in New York City[J]. AIMS Public Health, 2017, 4(1): 78-93. doi: 10.3934/publichealth.2017.1.78







 DownLoad:
DownLoad: