Citation: Zhong-Min Wang. Sulfur dioxide removal by sol-gel sorbent derived CuO/Alumina sorbents in fixed bed adsorber[J]. AIMS Environmental Science, 2017, 4(1): 134-144. doi: 10.3934/environsci.2017.1.134

| [1] | Livengood CD, Markussen JM (1994) FG Technologies for Combined Control of SO2 and NOx. Power Eng 98: 38-42. |
| [2] | Yeh JT, Demski RJ, Strakey JP, et al. (1985) Combined SO2/NOx Removal from Flue Gas. Detailed Discussion of a New Regenerative Fluidized-Bed Process Developed by the Pittsburgh Energy Technology Center. Environ Prog 4: 223-228. |
| [3] |
Wang ZM, Lin YS (1998) Sol-Gel Synthesis of Pure and Copper Oxide Coated Mesoporous Alumina Granular Particles. J Catal 174: 43-51. doi: 10.1006/jcat.1997.1913

|
| [4] | Deng SG, Lin YS (1997) Granulation of Sol-Gel-Derived Nanostructured Alumina. IChE J 43: 505-514. |
| [5] | Wang ZM, Sahle-Demessie E, Hassan AA (2011) Selective Oxidation Using Flame Aerosol Synthesized Iron and Vanadium-Doped Nano-TiO2. J Nanotechnology 2011: 209150. |
| [6] | Wang ZM, Sahle-Demessie E, Hassan AA, et al. (2012) Surface Structure and Photocatalytic Activity of Nano-TiO2 Thin Film for Selective Oxidation. J Environ Eng 138: 923-931 |
| [7] |
Wang ZM, Yang G, Biswas P, et al. (2001) Processing of iron-doped titania powders in flame aerosol reactors. Powder Technol 114: 197-204. doi: 10.1016/S0032-5910(00)00321-1
|
| [8] |
Wang ZM, Lin YS (1998) Sol-gel-derived Alumina-Supported Copper Oxide Sorbent for Flue Gas Desulfurization. Ind Eng Chem Res 37: 4675-4681. doi: 10.1021/ie980343u
|
| [9] |
Sahle-Demessie E, Gonzalez M, Wang ZM, et al. (1999) Synthesizing Alcohols and Ketones by Photoinduced Catalytic Partial Oxidation of Hydrocarbons in TiO2 Film Reactors Prepared by Three Different Methods. Ind Eng Chem Res 38: 3276-3284. doi: 10.1021/ie990054l
|
| [10] | van Heldon HJA, Nabor JE, Zuiderweg J, et al. (1970) Removal of sulfur oxides from gas mixture, U.S. Pat. 3.501,897. |
| [11] |
McCrea DH, Forney AJ, Myers JG (1970) Recovery of sulfur from flue gases using a copper oxide absorbent. J Air Pollut Contr Assoc 20: 819-824. doi: 10.1080/00022470.1970.10469479
|
| [12] | Dautzenberg FM, Nader JE, van Ginneken AJJ (1971) The Shell Flue Gas Desulphurization Process. Chem Eng Prog 67: 86-91. |
| [13] |
Friedman RM, Freeman JJ, Lytle FW (1978) Characterization of Cu/Al2O3 Catalysts. J Catal 55: 10-28. doi: 10.1016/0021-9517(78)90181-1
|
| [14] |
Strohmeier BR, Leyden DE, Field RS, et al. (1985) Surface Spectroscopic Characterization of Cu/Al2O3 Catalysts. J Catal 94: 514-530. doi: 10.1016/0021-9517(85)90216-7
|
| [15] |
Centi G, Riva A, Passarini N, et al. (1990) Simultaneous Removal of SO2/NOx from Flue-Gases Sorbent-Catalyst Design and Performances. Chem Eng Sci 45: 2679-2686. doi: 10.1016/0009-2509(90)80158-B
|
| [16] |
Yoo KS, Kim SD, Park SB (1994) Sulfation of Al2O3 in Flue Gas Desulfurization by CuO/g-Al2O3 Sorbent. Ind Eng Chem Res 33: 1786-1791. doi: 10.1021/ie00031a018
|
| [17] |
Centi G, Hodnett BK, Jaeger P, et al. (1995) Development of Copper-on-alumina Catalytic Materials for the Cleanup of Flue Gas and the Disposal of Diluted Ammonium Sulfate Solutions. J Mater Res 10: 553-561. doi: 10.1557/JMR.1995.0553
|
| [18] | Kiel JHA, Edelaar ACS, Prins W, et al. (1992) Performance of Silica Supported Copper-Oxide Sorbents for SOx/NOx Removal from Flue-Gas. 1. Sulfur-Dioxide Absorption and Regeneration Kinetics. Appl Catal B: Environ 1: 13-39. |
| [19] |
Yeh JT, Drummond CJ, Joubert JI (1987) Process Simulation of the Fluidized-Bed Copper-Oxide Process Sulfation Reaction. Environ Prog 6: 44-50. doi: 10.1002/ep.670060123
|
| [20] |
Sun X, Tang X, Yi H, et al. (2015) Simultaneous adsorption of SO2 and NO from flue gas over mesoporous alumina. Environ Technol 36: 588-594. doi: 10.1080/09593330.2014.953600
|
| [21] | Wu CM, Baltrusaitis J, Gillanand EG, et al. (2011) Sulfur Dioxide Adsorption on ZnO Nanoparticles and Nanorods. J Phys Chem C 115: 10164-10172. |
| [22] |
Lo Jacono M, Cimino A, Inversi M (1982) Oxidation States of Copper on Alumina Studied by Redox Cycles. J Catal 76: 320-332. doi: 10.1016/0021-9517(82)90263-9
|
| [23] |
Habashi F, Mikhail SA, Vo Van K (1976) Reduction of sulfates by hydrogen. Can J Chem 54: 3646-3650. doi: 10.1139/v76-524
|
| [24] | Sacks MD, Tseng TY, Lee SY (1984) Thermal Decomposition of Spherical Hydrated Basic Aluminum Suffate. Ceramic Bulletin 63: 301. |
| [25] |
Yoo JS, Bhattacharyya AA, Radlowski CA, et al. (1992) Advanced De-SOx catalysts: mixed solid solution spinels with cerium oxide. Appl Catal B 1: 169-189. doi: 10.1016/0926-3373(92)80022-R
|
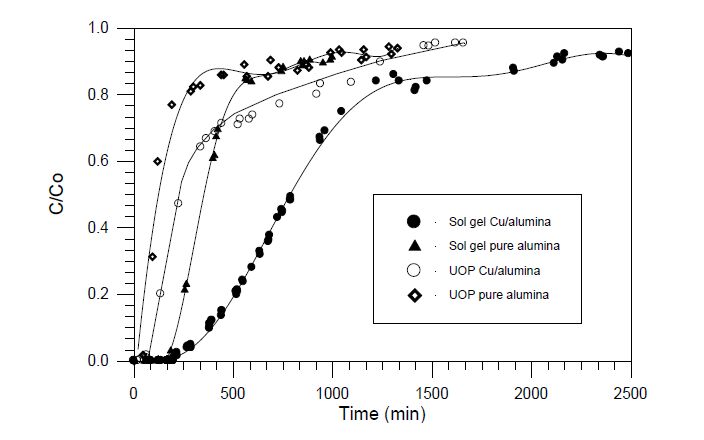

Figures(6) / Tables(3)

Zhong-Min Wang. Sulfur dioxide removal by sol-gel sorbent derived CuO/Alumina sorbents in fixed bed adsorber[J]. AIMS Environmental Science, 2017, 4(1): 134-144. doi: 10.3934/environsci.2017.1.134







 DownLoad:
DownLoad: