Citation: Christina L. Ekegren, Rachel E. Climie, William G. Veitch, Neville Owen, David W. Dunstan, Lara A. Kimmel, Belinda J. Gabbe. Sedentary behaviour and physical activity patterns in adults with traumatic limb fracture[J]. AIMS Medical Science, 2019, 6(1): 1-12. doi: 10.3934/medsci.2019.1.1

| [1] | Bradley C, Harrison J (2004) Descriptive epidemiology of traumatic fractures in Australia. INJCAT 57 ed. Adelaide: AIHW. |
| [2] | Henley G, Harrison JE (2017) Work-related hospitalised injury, Australia, 2006-07 to 2013-14. INJCAT 180 ed. Canberra: AIHW. |
| [3] | Bradley C, Harrison JE (2008) Hospital separations due to injury and poisoning, Australia 2004-05. INJCAT 117 ed. Canberra: AIHW. |
| [4] | Kreisfeld R, Harrison JE, Pointer S (2014) Australian sports injury hospitalisations 2011-12. INJCAT 168 ed. Canberra: AIHW. |
| [5] | Brinker MR, O'Connor DP (2004) The incidence of fractures and dislocations referred for orthopaedic services in a capitated population. J Bone Joint Surg Am 86-a: 290–297. |
| [6] |
Faergemann C, Frandsen PA, Rock ND (1998) Residual impairment after lower extremity fracture. J Trauma 45: 123–126. doi: 10.1097/00005373-199807000-00026

|
| [7] |
Pape HC, Probst C, Lohse R, et al. (2010) Predictors of late clinical outcome following orthopedic injuries after multiple trauma. J Trauma 69:1243–1251. doi: 10.1097/TA.0b013e3181ce1fa1
|
| [8] |
Bonafede M, Espindle D, Bower AG (2013) The direct and indirect costs of long bone fractures in a working age US population. J Med Econ 16:169–178. doi: 10.3111/13696998.2012.737391
|
| [9] | Caspersen CJ, Powell KE, Christenson GM (1985) Physical activity, exercise, and physical fitness: definitions and distinctions for health-related research. Public Health Rep 100:126–131. |
| [10] |
Tremblay MS, Aubert S, Barnes JD, et al. (2017) Sedentary Behavior Research Network (SBRN)-Terminology Consensus Project process and outcome. Int J Behav Nutr Phys Act 14: 75. doi: 10.1186/s12966-017-0525-8
|
| [11] |
Ekegren CL, Beck B, Climie RE, et al. (2018) Physical Activity and Sedentary Behavior Subsequent to Serious Orthopedic Injury: A Systematic Review. Arch Phys Med Rehabil 99: 164–177. doi: 10.1016/j.apmr.2017.05.014
|
| [12] |
Zusman EZ, Dawes MG, Edwards N, et al. (2018) A systematic review of evidence for older adults' sedentary behavior and physical activity after hip fracture. Clin Rehabil 32: 679–691. doi: 10.1177/0269215517741665
|
| [13] |
Owen N, Healy GN, Matthews CE, et al. (2010) Too Much Sitting: The Population-Health Science of Sedentary Behavior. Exerc Sport Sci Rev 38: 105–113. doi: 10.1097/JES.0b013e3181e373a2
|
| [14] |
Hamilton MT, Hamilton DG, Zderic TW (2007) Role of low energy expenditure and sitting in obesity, metabolic syndrome, type 2 diabetes, and cardiovascular disease. Diabetes 56: 2655–2667. doi: 10.2337/db07-0882
|
| [15] | Ferrando AA, Lane HW, Stuart CA, et al. (1996) Prolonged bed rest decreases skeletal muscle and whole body protein synthesis. Am J Physiol 270: E627–633. |
| [16] | Convertino VA (1997) Cardiovascular consequences of bed rest: effect on maximal oxygen uptake. Med Sci Sports Exerc 29: 191–196. |
| [17] |
Van der Wiel HE, Lips P, Nauta J, et al. (1994) Loss of bone in the proximal part of the femur following unstable fractures of the leg. J Bone Joint Surg Am 76: 230–236. doi: 10.2106/00004623-199402000-00009
|
| [18] |
van der Sluis CK, Eisma WH, Groothoff JW, et al. (1998) Long-term physical, psychological and social consequences of severe injuries. Injury 29: 281–285. doi: 10.1016/S0020-1383(98)80206-4
|
| [19] |
Beckenkamp PR, Lin CW, Engelen L, et al. (2016) Reduced Physical Activity in People Following Ankle Fractures: A Longitudinal Study. J Orthop Sports Phys Ther 46: 235–242. doi: 10.2519/jospt.2016.6297
|
| [20] |
Biswas A, Oh PI, Faulkner GE, et al. (2015) Sedentary Time and Its Association With Risk for Disease Incidence, Mortality, and Hospitalization in Adults: A Systematic Review and Meta-analysis. Ann Intern Med 162: 123–132. doi: 10.7326/M14-1651
|
| [21] | Ekelund U, Steene-Johannessen J, Brown WJ, et al. (2016) Does physical activity attenuate, or even eliminate, the detrimental association of sitting time with mortality? A harmonised meta-analysis of data from more than 1 million men and women. Lancet 388: 1302–1310. |
| [22] |
Stewart IJ, Sosnov JA, Howard JT, et al. (2015) Retrospective Analysis of Long Term Outcomes After Combat Injury: A Hidden Cost of War. Circulation 132: 2126–2133. doi: 10.1161/CIRCULATIONAHA.115.016950
|
| [23] |
Gabbe BJ, Simpson PM, Harrison JE, et al. (2016) Return to work and functional outcomes after major trauma: who recovers, when and how well? Ann Surg 263: 623–632. doi: 10.1097/SLA.0000000000001564
|
| [24] |
Hekler EB, Buman MP, Haskell WL, et al. (2012) Reliability and validity of CHAMPS self-reported sedentary-to-vigorous intensity physical activity in older adults. J Phys Act Health 9: 225–36. doi: 10.1123/jpah.9.2.225
|
| [25] | Veitch WG, Climie RED, Gabbe BJ, et al. (2018) Validation Of Two Physical Activity And Sedentary Behavior Questionnaires In Orthopedic Trauma Patients. Med Sci Sports Exerc 50: 711. |
| [26] | IPAQ Group, International Physical Activity Questionnaire. Secondary International Physical Activity Questionnaire, 2016. Available from: www.ipaq.ki.se |
| [27] |
Lyden K, Kozey Keadle SL, Staudenmayer JW, et al. (2012) Validity of two wearable monitors to estimate breaks from sedentary time. Med Sci Sports Exerc 44: 2243–2252. doi: 10.1249/MSS.0b013e318260c477
|
| [28] |
Harrington DM, Welk GJ, Donnelly AE (2011) Validation of MET estimates and step measurement using the ActivPAL physical activity logger. J Sports Sci 29: 627–633. doi: 10.1080/02640414.2010.549499
|
| [29] |
Treacy D, Hassett L, Schurr K, et al. (2017) Validity of Different Activity Monitors to Count Steps in an Inpatient Rehabilitation Setting. Phys Ther 97: 581–588. doi: 10.1093/ptj/pzx010
|
| [30] |
Ryan CG, Grant PM, Tigbe WW, et al. (2006) The validity and reliability of a novel activity monitor as a measure of walking. Br J Sports Med 40: 779–784. doi: 10.1136/bjsm.2006.027276
|
| [31] |
Sasaki JE, John D, Freedson PS (2011) Validation and comparison of ActiGraph activity monitors. J Sci Med Sport 14: 411–416. doi: 10.1016/j.jsams.2011.04.003
|
| [32] |
Winkler EA, Bodicoat DH, Healy GN, et al. (2016) Identifying adults' valid waking wear time by automated estimation in activPAL data collected with a 24 h wear protocol. Physiol Meas 37: 1653–1668. doi: 10.1088/0967-3334/37/10/1653
|
| [33] | Choi L, Liu Z, Matthews CE, et al. (2011) Validation of accelerometer wear and nonwear time classification algorithm. Med Sci Sports Exerc 43: 357–364. |
| [34] |
Edwardson CL, Winkler EAH, Bodicoat DH, et al. (2017) Considerations when using the activPAL monitor in field-based research with adult populations. J Sport Health Sci 6: 162–178. doi: 10.1016/j.jshs.2016.02.002
|
| [35] |
Ward DS, Evenson KR, Vaughn A, et al. (2005) Accelerometer use in physical activity: best practices and research recommendations. Med Sci Sports Exerc 37: S582–588. doi: 10.1249/01.mss.0000185292.71933.91
|
| [36] |
Freedson PS, Melanson E, Sirard J (1998) Calibration of the Computer Science and Applications, Inc. accelerometer. Med Sci Sports Exerc 30: 777–781. doi: 10.1097/00005768-199805000-00021
|
| [37] | WHO (1995) Physical status: the use and interpretation of anthropometry. Report of a WHO Expert Committee. World Health Organ Tech Rep Ser, 854, Geneva: World Health Organization, 1–452. |
| [38] |
Fleig L, McAllister MM, Brasher P, et al. (2016) Sedentary Behavior and Physical Activity Patterns in Older Adults After Hip Fracture: A Call to Action. J Aging Phys Act 24: 79–84. doi: 10.1123/japa.2015-0013
|
| [39] |
Ceroni D, Martin X, Lamah L, et al. (2012) Recovery of physical activity levels in adolescents after lower limb fractures: a longitudinal, accelerometry-based activity monitor study. BMC Musculoskel Dis 13: 131. doi: 10.1186/1471-2474-13-131
|
| [40] |
Resnick B, Galik E, Boltz M, et al. (2011) Physical Activity in the Post-Hip-Fracture Period. J Aging Phys Act 19: 373–387. doi: 10.1123/japa.19.4.373
|
| [41] | Hosmer JDW, Lemeshow S, Sturdivant RX (2013) Model-Building Strategies and Methods for Logistic Regression. Applied Logistic Regression: John Wiley & Sons, Inc., 89–151. |
| [42] | Portney LG, Watkins MP (2000) Foundations of Clinical Research: Applications to Practice. New Jersey: Prentice Hall Health. |
| [43] |
Friedrich JO, Adhikari NK, Beyene J (2012) Ratio of geometric means to analyze continuous outcomes in meta-analysis: comparison to mean differences and ratio of arithmetic means using empiric data and simulation. Stat Med 31: 1857–1886. doi: 10.1002/sim.4501
|
| [44] |
Austin PC, Steyerberg EW (2015) The number of subjects per variable required in linear regression analyses. J Clin Epidemiol 68: 627–636. doi: 10.1016/j.jclinepi.2014.12.014
|
| [45] |
Matthews CE, Chen KY, Freedson PS, et al. (2008) Amount of Time Spent in Sedentary Behaviors in the United States, 2003–2004. Am J Epidemiol 167: 875–881. doi: 10.1093/aje/kwm390
|
| [46] |
Dwyer T, Pezic A, Sun C, et al. (2015) Objectively Measured Daily Steps and Subsequent Long Term All-Cause Mortality: The Tasped Prospective Cohort Study. PLoS ONE 10: e0141274. doi: 10.1371/journal.pone.0141274
|
| [47] |
Troiano RP, Berrigan D, Dodd KW, et al. (2008) Physical Activity in the United States Measured by Accelerometer. Med Sci Sports Exerc 40: 181–188. doi: 10.1249/mss.0b013e31815a51b3
|
| [48] |
Davenport SJ, Arnold M, Hua C, et al. (2015) Physical Activity Levels During Acute Inpatient Admission After Hip Fracture are Very Low. Physiother Res Int 20: 174–181. doi: 10.1002/pri.1616
|
| [49] |
Bellettiere J, Winkler EAH, Chastin SFM, et al. (2017) Associations of sitting accumulation patterns with cardio-metabolic risk biomarkers in Australian adults. PLoS ONE 12: e0180119. doi: 10.1371/journal.pone.0180119
|
| [50] |
Dempsey PC, Larsen RN, Sethi P, et al. (2016) Benefits for Type 2 Diabetes of Interrupting Prolonged Sitting With Brief Bouts of Light Walking or Simple Resistance Activities. Diabetes Care 39: 964–972. doi: 10.2337/dc15-2336
|
| [51] |
Dunstan DW, Kingwell BA, Larsen R, et al. (2012) Breaking up prolonged sitting reduces postprandial glucose and insulin responses. Diabetes Care 35: 976–983. doi: 10.2337/dc11-1931
|
| [52] |
Harris TJ, Victor CR, Carey IM, et al. (2008) Less healthy, but more active: Opposing selection biases when recruiting older people to a physical activity study through primary care. BMC Public Health 8: 182. doi: 10.1186/1471-2458-8-182
|
 medsci-06-01-001-s001.pdf medsci-06-01-001-s001.pdf |
 |
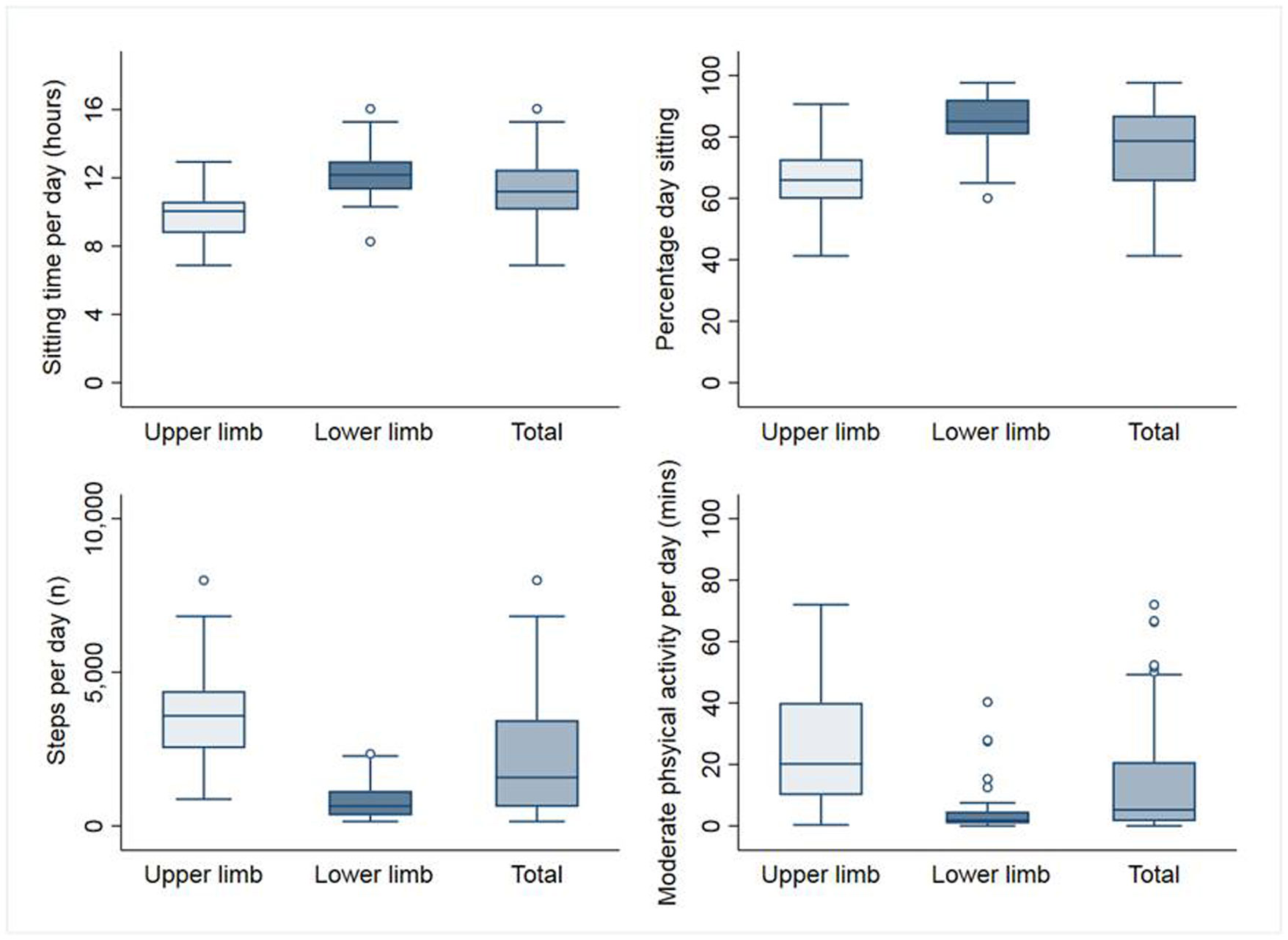
Figures(1) / Tables(2)

Christina L. Ekegren, Rachel E. Climie, William G. Veitch, Neville Owen, David W. Dunstan, Lara A. Kimmel, Belinda J. Gabbe. Sedentary behaviour and physical activity patterns in adults with traumatic limb fracture[J]. AIMS Medical Science, 2019, 6(1): 1-12. doi: 10.3934/medsci.2019.1.1







 DownLoad:
DownLoad: