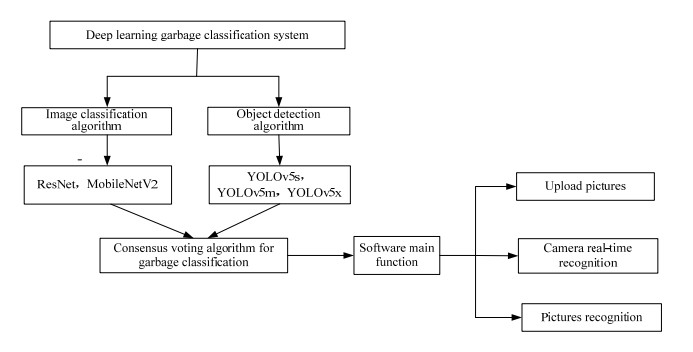
With the development of national economy, the output of waste is also increasing. People's living standards are constantly improving, and the problem of garbage pollution is increasingly serious, which has a great impact on the environment. Garbage classification and processing has become the focus of today. This topic studies the garbage classification system based on deep learning convolutional neural network, which integrates the garbage classification and recognition methods of image classification and object detection. First, the data sets and data labels used are made, and then the garbage classification data are trained and tested through ResNet and MobileNetV2 algorithms, Three algorithms of YOLOv5 family are used to train and test garbage object data. Finally, five research results of garbage classification are merged. Through consensus voting algorithm, the recognition rate of image classification is improved to 2%. Practice has proved that the recognition rate of garbage image classification has been increased to about 98%, and it has been transplanted to the raspberry pie microcomputer to achieve ideal results.
Citation: Zhongxue Yang, Yiqin Bao, Yuan Liu, Qiang Zhao, Hao Zheng, YuLu Bao. Research on deep learning garbage classification system based on fusion of image classification and object detection classification[J]. Mathematical Biosciences and Engineering, 2023, 20(3): 4741-4759. doi: 10.3934/mbe.2023219
With the development of national economy, the output of waste is also increasing. People's living standards are constantly improving, and the problem of garbage pollution is increasingly serious, which has a great impact on the environment. Garbage classification and processing has become the focus of today. This topic studies the garbage classification system based on deep learning convolutional neural network, which integrates the garbage classification and recognition methods of image classification and object detection. First, the data sets and data labels used are made, and then the garbage classification data are trained and tested through ResNet and MobileNetV2 algorithms, Three algorithms of YOLOv5 family are used to train and test garbage object data. Finally, five research results of garbage classification are merged. Through consensus voting algorithm, the recognition rate of image classification is improved to 2%. Practice has proved that the recognition rate of garbage image classification has been increased to about 98%, and it has been transplanted to the raspberry pie microcomputer to achieve ideal results.

| [1] | H. Hu, X. Jiang, X. Liu, R. Ding, S. Ma, B. Wang, Summary of domestic garbage classification and detection based on deep learning, in 2021 7th International Conference on Computer and Communications (ICCC), 7 (2021), 858–862. https://doi.org/10.1109/ICCC54389.2021.9674502 |
| [2] | Y. Deng, Y. Xu, Design of waste classification and recycling system based on tensorflow, Comput. Knowl. Technol., 23 (2021), 50–52. |
| [3] |
D. O. Melinte, A. M. Travediu, D. N. Dumitriu, Deep convolutional neural networks object detector for real-time waste identification, Appl. Sci. 10 (2020), 7301. https://doi.org/10.3390/app10207301 doi: 10.3390/app10207301

|
| [4] | S. Li, M. Yan, J. Xu, Garbage object recognition and classification based on mask scoring RCNN, in 2020 International Conference on Culture-oriented Science & Technology (ICCST), 6 (2020), 54–58. https://doi.org/10.1109/ICCST50977.2020.00016 |
| [5] | D. Lin, Z. Chen, M. Wang, J. Zhang, X. Zhou, Design and implementation of intelligent garbage classification system based on artificial intelligence technology, in 2021 13th International Conference on Computational Intelligence and Communication Networks (CICN), 13 (2021), 128–134. https://doi.org/10.1109/CICN51697.2021.9574675 |
| [6] | Z. Wu, D. Zhang, Y. Shao, X. Q. Zhang, X. P. Zhang, Y. Feng, et al., Using YOLOv5 for garbage classification, in 2021 4th International Conference on Pattern Recognition and Artificial Intelligence (PRAI), 4 (2021), 35–38. https://doi.org/10.1109/PRAI53619.2021.9550790 |
| [7] | W. Liu, G. F. Ren, R. S. Yu, S. Guo, J. K. Zhu, L. Zhang, Image-adaptive YOLO for object detection in adverse weather conditions, arXiv preprint, (2021), arXiv: 2112.08088v1. |
| [8] | J. M. Feng, M. X. Chu, Y. H. Yang, R. F. Gong, Vehicle information detection based on improved YOLOv3 algorithm, J. Chongqing Univ., 12 (2021), 71–79. |
| [9] | G. Yang, Garbage classification system with YOLOV5 based on image recognition, in 2021 IEEE 6th International Conference on Signal and Image Processing (ICSIP), 6 (2021), 11–18. https://doi.org/10.1109/ICSIP52628.2021.9688725 |
| [10] | Q. Guo, Y. Shi, S. Wang, Research on deep learning image recognition technology in garbage classification, in 2021 Asia-Pacific Conference on Communications Technology and Computer Science (ACCTCS), 10 (2021), 92–96. https://doi.org/10.1109/ACCTCS52002.2021.00027 |
| [11] |
Z. Kang, J. Yang, G. Li, Z. Zhang, An automatic garbage classification system based on deep learning, IEEE Access, 8 (2020), 140019–140029. https://doi.org/10.1109/ACCESS.2020.3010496 doi: 10.1109/ACCESS.2020.3010496
|
| [12] |
G. E. Hinton, S. Osindero, Y. W. Teh, A fast learning algorithm for deep belief nets, Neural Comput., 18 (2006), 1527–1554. https://doi.org/10.1162/neco.2006.18.7.1527 doi: 10.1162/neco.2006.18.7.1527
|
| [13] |
D. N. Su, G. T. Cao, Y. N. Wang, H. Wang, H. Ren, Survey of deep learning for radar emitter identification based on small sample, Comput. Sci., 49 (2022), 226–235. https://doi.org/10.11896/jsjkx.210600138 doi: 10.11896/jsjkx.210600138
|
| [14] | A. Krueangsai, S. Supratid, Effects of shortcut-level amount in lightweight ResNet of ResNet on object recognition with distinct number of categories, in 2022 International Electrical Engineering Congress (iEECON), (2022), 1–4. https://doi.org/10.1109/iEECON53204.2022.9741665 |
| [15] |
Z. Zhu, W. Zhai, H. Liu, J. Geng, M. Zhou, C. Ji, et al., Juggler-ResNet: A flexible and high-speed ResNet optimization method for intrusion detection system in software-defined industrial networks, IEEE Trans. Ind. Inf., 18 (2022), 4224–4233. https://doi.org/10.1109/TII.2021.3121783 doi: 10.1109/TII.2021.3121783
|
| [16] |
M. Hu, Y. Wei, M. Li, H. Yao, W. Deng, M. Tong, et al., Bimodal learning engagement recognition from videos in the classroom, Sensors, 22 (2022), 5932–5942. https://doi.org/10.3390/s22165932 doi: 10.3390/s22165932
|
| [17] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 770–778. |
| [18] |
C. Zhang, T. Yang, J. Yang, Image recognition of wind turbine blade defects using attention-based mobileNetv1-YOLOv4 and transfer learning, Sensors, 22 (2022), 6009–6019. https://doi.org/10.3390/s22166009 doi: 10.3390/s22166009
|
| [19] | M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L. C. Chen, Mobilenetv2: Inverted residuals and linear bottlenecks, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 4510–4520. https://doi.org/10.1109/CVPR.2018.00474 |
| [20] |
Q. Luo, J. Wang, M. Gao, Z. He, Y. Yang, H. Zhou, Multiple mechanisms to strengthen the ability of YOLOv5s for real-time identification of vehicle type, Electronics, 11 (2022), 2586–2597. https://doi.org/10.3390/electronics11162586 doi: 10.3390/electronics11162586
|
| [21] | L. W. Ye, Z. P. Song, Real time detection method of classroom behavior based on YOLO-v5 improved model, Changjiang Inf. Commun., 7 (2021), 41–45. |
| [22] |
Z. Li, A. Namiki, S. Suzuki, Q. Wang, T. Zhang, W. Wang, Application of low-altitude UAV remote sensing image object detection based on improved YOLOv5, Appl. Sci., 12 (2022), 8314–8325. https://doi.org/10.3390/app12168314 doi: 10.3390/app12168314
|
| [23] | Q. Fu, J. Chen, W. Yang, S. Zheng, Nearshore ship detection on SAR image based on YOLOv5, in 2021 2nd China International SAR Symposium (CISS), (2021), 1–4. https://doi.org/10.23919/CISS51089.2021.9652233 |
| [24] | J. Ieamsaard, S. N. Charoensook, S. Yammen, Deep learning-based face mask detection using YOLOV5, in 2021 9th International Electrical Engineering Congress (iEECON), (2021), 428–431. https://doi.org/10.1109/iEECON51072.2021.9440346 |
| [25] |
Z. M. Bao, S. R. Gong, S. Zhong, R. Yan, X. H. Dai, Person re-identification algorithm based on bidirectional KNN ranking optimization, Comput. Sci., 46 (2019), 267–271. https://doi.org/10.11896/jsjkx.181001861 doi: 10.11896/jsjkx.181001861
|
| [26] |
X. Liu, Y. Wang, Y. Li, F. Liu, J. Shen, L. Ou, et al., Comparing eight computing algorithms and four consensus methods to analyze relationship between land use pattern and driving forces, Int. J. Geosci., 10 (2019), 12–28. https://doi.org/10.4236/ijg.2019.101002 doi: 10.4236/ijg.2019.101002
|










Figures(11) / Tables(11)

Zhongxue Yang, Yiqin Bao, Yuan Liu, Qiang Zhao, Hao Zheng, YuLu Bao. Research on deep learning garbage classification system based on fusion of image classification and object detection classification[J]. Mathematical Biosciences and Engineering, 2023, 20(3): 4741-4759. doi: 10.3934/mbe.2023219







 DownLoad:
DownLoad: