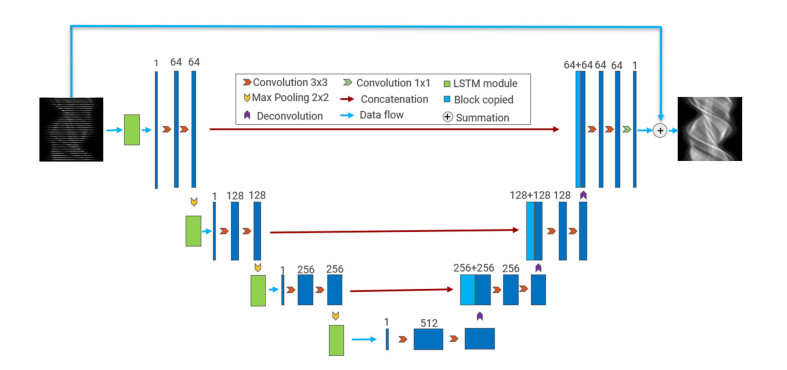
Lowering the dose in single-photon emission computed tomography (SPECT) imaging to reduce the radiation damage to patients has become very significant. In SPECT imaging, lower radiation dose can be achieved by reducing the activity of administered radiotracer, which will lead to projection data with either sparse projection views or reduced photon counts per view. Direct reconstruction of sparse-view projection data may lead to severe ray artifacts in the reconstructed image. Many existing works use neural networks to synthesize the projection data of sparse-view to address the issue of ray artifacts. However, these methods rarely consider the sequence feature of projection data along projection view. This work is dedicated to developing a neural network architecture that accounts for the sequence feature of projection data at adjacent view angles. In this study, we propose a network architecture combining Long Short-Term Memory network (LSTM) and U-Net, dubbed LU-Net, to learn the mapping from sparse-view projection data to full-view data. In particular, the LSTM module in the proposed network architecture can learn the sequence feature of projection data at adjacent angles to synthesize the missing views in the sinogram. All projection data used in the numerical experiment are generated by the Monte Carlo simulation software SIMIND. We evenly sample the full-view sinogram and obtain the 1/2-, 1/3- and 1/4-view projection data, respectively, representing three different levels of view sparsity. We explore the performance of the proposed network architecture at the three simulated view levels. Finally, we employ the preconditioned alternating projection algorithm (PAPA) to reconstruct the synthesized projection data. Compared with U-Net and traditional iterative reconstruction method with total variation regularization as well as PAPA solver (TV-PAPA), the proposed network achieves significant improvement in both global and local quality metrics.
Citation: Si Li, Wenquan Ye, Fenghuan Li. LU-Net: combining LSTM and U-Net for sinogram synthesis in sparse-view SPECT reconstruction[J]. Mathematical Biosciences and Engineering, 2022, 19(4): 4320-4340. doi: 10.3934/mbe.2022200
Lowering the dose in single-photon emission computed tomography (SPECT) imaging to reduce the radiation damage to patients has become very significant. In SPECT imaging, lower radiation dose can be achieved by reducing the activity of administered radiotracer, which will lead to projection data with either sparse projection views or reduced photon counts per view. Direct reconstruction of sparse-view projection data may lead to severe ray artifacts in the reconstructed image. Many existing works use neural networks to synthesize the projection data of sparse-view to address the issue of ray artifacts. However, these methods rarely consider the sequence feature of projection data along projection view. This work is dedicated to developing a neural network architecture that accounts for the sequence feature of projection data at adjacent view angles. In this study, we propose a network architecture combining Long Short-Term Memory network (LSTM) and U-Net, dubbed LU-Net, to learn the mapping from sparse-view projection data to full-view data. In particular, the LSTM module in the proposed network architecture can learn the sequence feature of projection data at adjacent angles to synthesize the missing views in the sinogram. All projection data used in the numerical experiment are generated by the Monte Carlo simulation software SIMIND. We evenly sample the full-view sinogram and obtain the 1/2-, 1/3- and 1/4-view projection data, respectively, representing three different levels of view sparsity. We explore the performance of the proposed network architecture at the three simulated view levels. Finally, we employ the preconditioned alternating projection algorithm (PAPA) to reconstruct the synthesized projection data. Compared with U-Net and traditional iterative reconstruction method with total variation regularization as well as PAPA solver (TV-PAPA), the proposed network achieves significant improvement in both global and local quality metrics.

| [1] | H. A. Ziessman, J. P. O'Malley, J. H. Thrall, Nuclear Medicine: The Requisites, Mosby, 2006. |
| [2] |
R. G. Wells, Dose reduction is good but it is image quality that matters, J. Nucl. Cardiol., 27 (2020), 238–240. https://doi.org/10.1007/s12350-018-1378-5 doi: 10.1007/s12350-018-1378-5

|
| [3] |
J. Zhang, S. Li, A. Krol, C. R. Schmidtlein, E. Lipson, D. Feiglin, et al., Infimal convolution-based regularization for SPECT reconstruction, Med. Phys., 45 (2018), 5397–5410. https://doi.org/10.1002/mp.13226 doi: 10.1002/mp.13226
|
| [4] |
A. Krol, S. Li, L. Shen, Y. Xu, Preconditioned alternating projection algorithms for maximum a posteriori ECT reconstruction, Inverse Probl., 28 (2012). https://doi.org/10.1088/0266-5611/28/11/115005 doi: 10.1088/0266-5611/28/11/115005
|
| [5] |
Y. Jiang, S. Li, S. X. Xu, A higher-order polynomial method for SPECT reconstruction, IEEE Trans. Med. Imaging, 38 (2019), 1271–1283. https://doi.org/10.1109/TMI.2018.2881919 doi: 10.1109/TMI.2018.2881919
|
| [6] |
M. H. Zhang, B. Dong, A review on deep learning in medical image reconstruction, J. Oper. Res. Soc. China, 8 (2020), 311–340. https://doi.org/10.1007/s40305-019-00287-4 doi: 10.1007/s40305-019-00287-4
|
| [7] |
A. J. Ramon, Y. Yang, P. H. Pretorius, K. L. Johnson, M. A. King, M. N. Wernick, Improving diagnostic accuracy in low-dose SPECT myocardial perfusion imaging with convolutional denoising networks, IEEE Trans. Med. Imaging, 39 (2020), 2893–2903. https://doi.org/10.1109/TMI.2020.2979940 doi: 10.1109/TMI.2020.2979940
|
| [8] |
H. Chen, Y. Zhang, M. K. Kalra, F. Lin, Y. Chen, P. Liao, et al., Low-dose CT with a residual encoder-decoder convolutional neural network, IEEE Trans. Med. Imaging, 36 (2017), 2524–2535. https://doi.org/10.1109/TMI.2017.2715284 doi: 10.1109/TMI.2017.2715284
|
| [9] |
C. Z. Zhang, K. X. Liang, X. Dong, Y. Q. Xie, G. H. Cao, A sparse-view CT reconstruction method based on combination of DenseNet and deconvolution, IEEE Trans. Med. Imaging, 37 (2018), 1407–1477. https://doi.org/10.1109/TMI.2018.2823338 doi: 10.1109/TMI.2018.2823338
|
| [10] |
Q. Yang, P. Yan, Y. Zhang, H. Yu, Y. Shi, X. Mou, et al., Low-dose CT image denoising using a generative adversarial network with Wasserstein distance and perceptual loss, IEEE Trans. Med. Imaging, 37 (2018), 1348–1357. https://doi.org/10.1109/TMI.2018.2827462 doi: 10.1109/TMI.2018.2827462
|
| [11] |
N. Basty, V. Grau, Super resolution of cardiac cine MRI sequences using deep learning, Image Analys. Moving Org. Breast Thorac. Images, 2018 (2018), 23–31. https://doi.org/10.1007/978-3-030-00946-5_3 doi: 10.1007/978-3-030-00946-5_3
|
| [12] | J. Sun, H. Li, Z. Xu, Deep ADMM-Net for compressive sensing MRI, Adv. Neural Inf. Process. Syst., 2016 (2016), 29. |
| [13] |
Y. Yang, J. Sun, H. Li, Z. Xu, ADMM-CSNet: a deep learning approach for image compressive sensing, IEEE Trans. Pattern Anal. Mach. Intell., 42 (2018), 521–538. https://doi.org/10.1109/TPAMI.2018.2883941 doi: 10.1109/TPAMI.2018.2883941
|
| [14] |
J. Adler, O. Öktem, Learned primal-dual reconstruction, IEEE Trans. Med. Imaging, 37 (2018), 1322–1332. https://doi.org/10.1109/TMI.2018.2799231 doi: 10.1109/TMI.2018.2799231
|
| [15] | M. H. Zhang, B. Dong, D. B. Liu, JSR-Net: a deep network for Joint Spatial-Radon domain CT reconstruction from incomplete data, in IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (2019), 3657–3661. https://doi.org/10.1109/ICASSP.2019.8682178 |
| [16] |
I. Haeggstroem, C. R. Schmidtlein, G. Campanella, T. J. Fuchs, DeepPET: a deep encoder-decoder network for directly solving the PET reconstruction inverse problem, Med. Image Anal., 54 (2018), 253–262. https://doi.org/10.1016/j.media.2019.03.013 doi: 10.1016/j.media.2019.03.013
|
| [17] | X. Dong, S. Vekhande, G. Cao, Sinogram interpolation for sparse-view micro-CT with deep learning neural network, in Medical Imaging 2019: Physics of Medical Imaging, SPIE, (2019), 692–698. https://doi.org/10.1117/12.2512979 |
| [18] | H. Yuan, J. Jia, Z. Zhu, SIPID: a deep learning framework for sinogram interpolation and image denoising in low-dose CT reconstruction, in 2018 IEEE 15th International Symposium on Biomedical Imaging, (2018), 1521–1524. https://doi.org/10.1109/ISBI.2018.8363862 |
| [19] |
H. Lee, J. Lee, H. Kin, B. Cho, S. Cho, Deep-neural-network based sinogram synthesis for sparse-view CT image reconstruction, IEEE Trans. Radiat. Plasma Med. Sci., 3 (2019), 109–119. https://doi.org/10.1109/TRPMS.2018.2867611 doi: 10.1109/TRPMS.2018.2867611
|
| [20] | I. Shiri, P. Sheikhzadeh, M. R. Ay, Deep-fill: deep learning based sinogram domain gap filling in positron emission tomography, preprint, arXiv: 1906.07168. |
| [21] | C. Tang, W. Zhang, L. Wang, A. Cai, N. Liang, B. Yang, Generative adversarial network-based sinogram super-resolution for computed tomography imaging, Phys. Med. Biol., 65 (2020), 235006. |
| [22] | Z. Li, W. Zhang, L. Wang, A. Cai, N. Liang, B. Yang, et al., A sinogram inpainting method based on generative adversarial network for limited-angle computed tomography, in 15th International Meeting on Fully Three-Dimensional Image Reconstruction in Radiology and Nuclear Medicine. International Society for Optics and Photonics, (2019), 11072. https://doi.org/10.1117/12.2533757 |
| [23] |
Y. Wang, W. Zhang, A. Cai, L. Wang, C. Tang, Z. Feng, et al., An effective sinogram inpainting for complementary limited-angle dual-energy computed tomography imaging using generative adversarial networks, J. X-Ray Sci. Technol., 29 (2020), 1–25. https://doi.org/10.3233/XST-200736 doi: 10.3233/XST-200736
|
| [24] | C. Chrysostomou, L. Koutsantonis, C. Lemesios, C. N. Papanicolas, SPECT angle interpolation based on deep learning methodologies, in 2020 IEEE Nuclear Science Symposium and Medical Imaging Conference (NSS/MIC), (2021), 1–4. https://doi.org/10.1109/NSS/MIC42677.2020.9507966 |
| [25] | O. Ronneberger, P. Fischer, T. Brox, U-net: convolutional networks for biomedical image segmentation, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4_28 |
| [26] |
M. T. McCann, K. H. Jin, M. Unser, Deep convolutional neural network for inverse problems in imaging, IEEE Trans. Image Process., 34 (2017), 85–95. https://doi.org/10.1109/MSP.2017.2739299 doi: 10.1109/MSP.2017.2739299
|
| [27] | Y. S. Han, J. Yoo, J. C. Ye, Deep residual learning for compressed sensing CT reconstruction via persistent homology analysis, preprint, arXiv: 1611.06391. |
| [28] |
S. Hochreiter, J. Schmidhuber, Long short-term memory, Neural Comput., 9 (1997), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735 doi: 10.1162/neco.1997.9.8.1735
|
| [29] |
L. A. Shepp, Y. Vardi, Maximum likelihood reconstruction for emission tomography, IEEE Trans. Med. Imaging, 1 (1982), 113–122. https://doi.org/10.1109/TMI.1982.4307558 doi: 10.1109/TMI.1982.4307558
|
| [30] | C. A. Micchelli, X. L. Shen, S. Y. Xu, Proximity algorithms for imagemodels: denoising, Inverse Probl., 27 (2011), 045009. |
| [31] | S. Tong, A. M. Alessio, P. E. Kinahan, Noise and signal properties in PSF-based fully 3D PET image reconstruction: an experimental evaluation, Phys. Med. Biol., 55 (2016), 1453–1473. |










Figures(11) / Tables(7)

Si Li, Wenquan Ye, Fenghuan Li. LU-Net: combining LSTM and U-Net for sinogram synthesis in sparse-view SPECT reconstruction[J]. Mathematical Biosciences and Engineering, 2022, 19(4): 4320-4340. doi: 10.3934/mbe.2022200







 DownLoad:
DownLoad: