Citation: Zhenjun Tang, Yongzheng Yu, Hanyun Zhang, Mengzhu Yu, Chunqiang Yu, Xianquan Zhang. Robust image hashing via visual attention model and ring partition[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 6103-6120. doi: 10.3934/mbe.2019305

| [1] | Z. Tang, Z. Huang, X. Q. Zhang, et al., Robust image hashing with multidimensional scaling, Signal Process., 137(2017), 240–250. |
| [2] | C. Qin, X. Chen, D. Ye, et al., A novel image hashing scheme with perceptual robustness using block truncation coding, Inform. Sci., 361(2016), 84–99. |
| [3] | Z. Tang, L. Chen, X. Q. Zhang, et al., Robust image hashing with tensor decomposition, IEEE Trans. Knowl. Data En., 31(2019), 549–560. |
| [4] | Z. Tang, S. Wang, X. P. Zhang, et al., Lexicographical framework for image hashing with implementation based on DCT and NMF, Multimed. Tools Appl., 52(2011), 325–345. |
| [5] | F. Lefebvre, B. Macq and J. D. Legat, RASH: Radon soft hash algorithm, In: Proc. of European Signal Processing Conference, Toulouse, France, Sep. 3−6, 2002, pp.299–302. |
| [6] | A. Swaminathan, Y. Mao and M. Wu, Robust and secure image hashing, IEEE Trans. Inf. Foren. Secur., 1(2006), 215–230. |
| [7] | V. Monga and B. L. Evans, Perceptual image hashing via feature points: performance evaluation and trade-offs, IEEE Trans. Image Process., 15(2006), 3453–3466. |
| [8] | Y. Ou and K. H. Rhee, A key-dependent secure image hashing scheme by using Radon transform, In: Proc. of the IEEE International Symposium on Intelligent Signal Processing and Communication Systems, pp.595–598, 2009. |
| [9] | Z. Tang, S. Wang, X. P. Zhang, et al., Structural feature-based image hashing and similarity metric for tampering detection, Fundam. Inf., 106(2011), 75–91. |
| [10] | C. Qin, C. C. Chang and P. L. Tsou, Robust image hashing using non-uniform sampling in discrete Fourier domain, Digit. Signal Process., 23(2013), 578–585. |
| [11] | Z. Tang, X. Q. Zhang, L. Huang, et al., Robust image hashing using ring-based entropies, Signal Process., 93(2013), 2061–2069. |
| [12] | Z. Tang, Y. Dai, X. Q. Zhang, et al., Robust image hashing via colour vector angles and discrete wavelet transform, IET Image Process., 8(2014), 142–149. |
| [13] | L. Ghouti, Robust perceptual color image hashing using quaternion singular value decomposition, In: Proc. of IEEE International Conference on Acoustic, Speech and Signal Processing (ICASSP 2014), pp.3794–3798, 2014. |
| [14] | C. Yan, C. Pun and X. Yuan, Quaternion-based image hashing for adaptive tampering localization, IEEE Trans. Inf. Foren. Secur., 11(2016), 2664–2677. |
| [15] | C. Qin, X. Chen, J. Dong, et al., Perceptual image hashing with selective sampling for salient structure features, Displays, 45(2016), 26–37. |
| [16] | Z. Tang, X. Q. Zhang, X. Li, et al., Robust image hashing with ring partition and invariant vector distance, IEEE Trans. Inf. Foren. Secur., 11(2016), 200–214. |
| [17] | R. K. Karsh, R. H. Laskar and B. B. Richhariya, Robust image hashing using ring partition-PGNMF and local features, SpringerPlus, 5(2016), 1–20. |
| [18] | R. K. Karsh, R. H. Laskar and Aditi, Robust image hashing through DWT-SVD and spectral residual method, EURASIP J. Image Vide., 2017(2017), 1–17. |
| [19] | R. Davarzani, S. Mozaffariand and K. Yaghmaie, Perceptual image hashing using center-symmetric local binary patterns, Multimed. Tools Appl., 75(2016), 4639–4667. |
| [20] | X. Huang, X. Liu, G. Wang, et al., A robust image hashing with enhanced randomness by using random walk on zigzag blocking, In: Proc. IEEE Trustcom/BigDataSE/ISPA, pp.23–26, 2016. |
| [21] | R. K. Karsh, A. Saikia and R. H. Laskar, Image authentication based on robust image hashing with geometric correction, Multimed. Tools Appl., 77(2018), 25409–25429. |
| [22] | C. Qin, M. Sun and C.-C. Chang, Perceptual hashing for color images based on hybrid extraction of structural features, Signal Process., 142(2018), 194–205. |
| [23] | Z. Tang, Z. Huang, H. Yao, et al., Perceptual image hashing with weighted DWT features for reduced-reference image quality assessment, Comput. J., 61 (2018), 1695–1709. |
| [24] | L. Itti, C. Koch and E. Niebur, A model of saliency based visual attention for rapid scene analysis, IEEE Trans. Patt. Anal. Mac. Intell., 20(1998), 1254–1259. |
| [25] | D. Walther and C. Koch, Modeling attention to salient proto-objects, Neural Networks, 19(2006), 1395–1407. |
| [26] | X. Hou and L. Zhang, Saliency detection: A spectral residual approach, In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp.1–8, 2007. |
| [27] | C. Guo, Q. Ma and L. Zhang, Spatio-temporal saliency detection using phase spectrum of quaternion Fourier transform, In: Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp.1–8, 2008. |
| [28] | Z. Tang, X. Q. Zhang and S. Zhang, Robust perceptual image hashing based on ring partition and NMF, IEEE Trans. Knowl. Data En., 26(2014), 711–724. |
| [29] | Z. Tang, L. Huang, X. Q. Zhang, et al., Robust image hashing based on color vector angle and canny operator, AEÜ-Int. J. Electron. Commun., 70(2016), 833–841. |
| [30] | Kodak Lossless True Color Image Suite. Available online: http://r0k.us/graphics/kodak/. |
| [31] | F. A. P. Petitcolas, Watermarking schemes evaluation, IEEE Signal Process. Mag., 17(2000), 58–64. |
| [32] | Z. Wang, A. C. Bovik, H. R. Sheikh, et al., Image quality assessment: from error visibility to structural similarity, IEEE Trans. Image Process., 13(2004), 600–612. |
| [33] | Ground Truth Database. Available online: http://www.cs.washington.edu/research/imagedatabase/groundtruth/. |
| [34] | T. Fawcett, An introduction to ROC analysis, Patt. Recog. Lett., 27(2006), 861–874. |
| [35] | IEEE Std754–2008, IEEE Standard for Floating-Point Arithmetic, pp.1–70, 2008. |
| [36] | G. Schaefer and M. Stich, UCID-an uncompressed color image database, Proc. SPIE, Storage and Retrieval Methods and Applications for Multimedia, pp.472–480, 2004. |


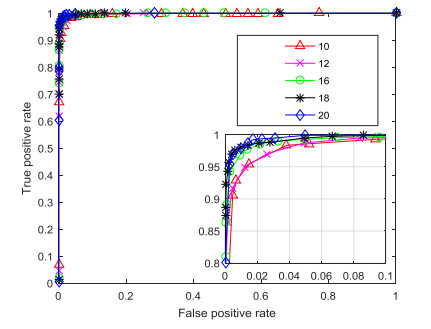
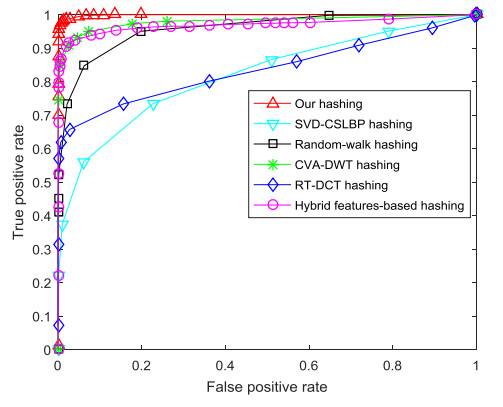


Figures(10) / Tables(4)

Zhenjun Tang, Yongzheng Yu, Hanyun Zhang, Mengzhu Yu, Chunqiang Yu, Xianquan Zhang. Robust image hashing via visual attention model and ring partition[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 6103-6120. doi: 10.3934/mbe.2019305







 DownLoad:
DownLoad: