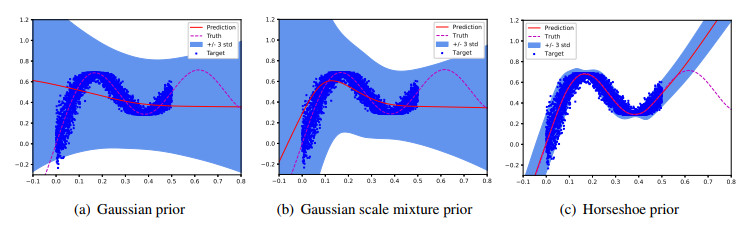
Choosing an appropriate prior distribution for the weights of Bayesian neural networks (BNNs) remains an open challenge. In most cases, a Gaussian prior is adopted, but its typically high variance can lead to overestimation of the predictive uncertainty. Recently, horseshoe priors have been proposed for model selection and compression, as they effectively deactivate units that do not contribute to explaining the data and yield well-calibrated structural weight uncertainty estimates. However, the horseshoe prior has been found to underestimate predictive uncertainty, especially in regions lacking data. In this paper, we proposed an efficient variational sparse BNN that integrates both a regularized horseshoe prior and a Gaussian scale mixture prior. Both priors can induce sparsity, thereby mitigating overfitting and improving the model's generalization ability. Our approach enables computationally efficient optimization via variational inference while providing more reliable predictive uncertainty. Experimental results demonstrate that the proposed model delivers competitive predictive performance and reasonable posterior weight uncertainty estimates in non-linear regression, image classification, and anomaly detection tasks compared with recent methods.
Citation: Xu Chen, Lilong Sima, Zhen Wei, Xingde Duan, Ping Feng, Fuhong Song. Variational sparse Bayesian neural networks with regularized horseshoe priors and scale mixture priors[J]. AIMS Mathematics, 2025, 10(9): 21929-21952. doi: 10.3934/math.2025977
Choosing an appropriate prior distribution for the weights of Bayesian neural networks (BNNs) remains an open challenge. In most cases, a Gaussian prior is adopted, but its typically high variance can lead to overestimation of the predictive uncertainty. Recently, horseshoe priors have been proposed for model selection and compression, as they effectively deactivate units that do not contribute to explaining the data and yield well-calibrated structural weight uncertainty estimates. However, the horseshoe prior has been found to underestimate predictive uncertainty, especially in regions lacking data. In this paper, we proposed an efficient variational sparse BNN that integrates both a regularized horseshoe prior and a Gaussian scale mixture prior. Both priors can induce sparsity, thereby mitigating overfitting and improving the model's generalization ability. Our approach enables computationally efficient optimization via variational inference while providing more reliable predictive uncertainty. Experimental results demonstrate that the proposed model delivers competitive predictive performance and reasonable posterior weight uncertainty estimates in non-linear regression, image classification, and anomaly detection tasks compared with recent methods.

| [1] |
I. Abdullayev, E. Akhmetshin, I. Kosorukova, E. Klochko, W. Cho, G. P. Joshi, Modeling of extended osprey optimization algorithm with Bayesian neural network: An application on Fintech to predict financial crisis, AIMS Mathematics, 9 (2024), 17555–17577. https://doi.org/10.3934/math.2024853 doi: 10.3934/math.2024853

|
| [2] | J. C. Bai, Q. F. Song, G. Cheng, Efficient variational inference for sparse deep learning with theoretical guarantee, In: Proceedings of the 34th International Conference on Neural Information Processing Systems, Red Hook: Curran Associates Inc., 2020,466–476. |
| [3] | F. Bergamin, Pablo. Moreno-Muñoz, S. Hauberg, G. Arvanitidis, Riemannian Laplace approximations for Bayesian neural networks, 37th Annual Conference on Neural Information Processing Systems, New Orleans, US, 2023. |
| [4] | C. Blundell, J. Cornebise, K. Kavukcuoglu, D. Wierstra, Weight uncertainty in neural networks, In: Proceedings of the 32nd International Conference on Machine Learning, New York: PMLR, 2015, 1613–1622. |
| [5] | C. M. Carvalho, N. G. Polson, J. G. Scott, Handling sparsity via the horseshoe, In: Proceedings of the Twelfth International Conference on Artificial Intelligence and Statistics, New York: PMLR, 2009, 73–80. |
| [6] |
Y. Cao, Y. G. Kao, Z. Wang, X. S. Yang, J. H. Park, W. Xie, Sliding mode control for uncertain fractional-order reaction-diffusion memristor neural networks with time delays, Neural Networks, 178 (2024), 106402. https://doi.org/10.1016/j.neunet.2024.106402 doi: 10.1016/j.neunet.2024.106402
|
| [7] |
X. Chen, C. C. Liu, Y. Zhao, Z. Y. Jia, G. Jin, Improving adversarial robustness of Bayesian neural networks via multi-task adversarial training, Inform. Sciences, 592 (2022), 156–173. https://doi.org/10.1016/j.ins.2022.01.051 doi: 10.1016/j.ins.2022.01.051
|
| [8] |
X. Chen, Y. Zhao, C. C. Liu, Medical image segmentation using scalable functional variational Bayesian neural networks with Gaussian processes, Neurocomputing, 500 (2022), 58–72. https://doi.org/10.1016/j.neucom.2022.05.055 doi: 10.1016/j.neucom.2022.05.055
|
| [9] | N. Dabiran, B. Robinson, R. Sandhu, Mo. Khalil, D. Poirel, A. Sarkar, Sparse Bayesian neural networks for regression: Tackling overfitting and computational challenges in uncertainty quantification, arXiv: 2310.15614, (2023). |
| [10] | E. Daxberger, E. Nalisnick, J. U. Allingham, J. Antorán, J. Hernández-Lobato, Bayesian deep learning via subnetwork inference, In: Proceedings of the 38th International Conference on Machine Learning, New York: PMLR, 2021, 2510–2521. |
| [11] |
G. Franchi, A. Bursuc, E. Aldea, S. Dubuisson, I. Bloch, Encoding the latent posterior of Bayesian neural networks for uncertainty quantification, IEEE T. Pattern Anal., 46 (2024), 2027–2040. https://doi.org/10.1109/TPAMI.2023.3328829 doi: 10.1109/TPAMI.2023.3328829
|
| [12] |
B. Ghoshal, A. Tucker, B. Sanghera, W. L. Wong, Estimating uncertainty in deep learning for reporting confidence to clinicians in medical image segmentation and disease detection, Comput. Intell., 37 (2021), 701–734. https://doi.org/10.1111/coin.12411 doi: 10.1111/coin.12411
|
| [13] | Y. Gal, R. Islam, Z. Ghahramani, Deep Bayesian active learning with image data, In: Proceedings of the 34th International Conference on Machine Learning, New York: PMLR, 2017, 1183–1192. |
| [14] | S. Ghosh, Y. Yao, F. Doshi-Velez, Model selection in Bayesian neural networks via horseshoe priors, J. Mach. Learn. Res., 20 (2019), 1–46. |
| [15] | S. Ghosh, Y. Yao, F. Doshi-Velez, Structured variational learning of Bayesian neural networks with horseshoe priors, In: Proceedings of the 35th International Conference on Machine Learning, New York: PMLR, 2018, 1739–1748. |
| [16] | D. Hendrycks, K. Gimpel, A baseline for detecting misclassified and out-of-distribution examples in neural networks, In: International Conference on Learning Representations, 2017, 1–12. |
| [17] |
J. M. Hernández-Lobato, D. Hernández-Lobato, A. Suárez, Expectation propagation in linear regression models with spike-and-slab priors, Machine Learning, 99 (2015), 437–487. https://doi.org/10.1007/s10994-014-5475-7 doi: 10.1007/s10994-014-5475-7
|
| [18] | J. M. Hernández-Lobato, Y. Z. Li, M. Rowland, T. Bui, D. Hernández-Lobato, R. Turner, Black-box alpha-divergence minimization, In: Proceedings of the 33rd International Conference on Machine Learning, New York: PMLR, 2016, 1511–1520. |
| [19] | A. Hubin, G. Storvik, Variational inference for Bayesian neural networks under model and parameter uncertainty, arXiv: 2305.00934, (2023). |
| [20] | J. Ingraham, D. S. Marks, Variational inference for sparse and undirected models, In: Proceedings of the 34th International Conference on Machine Learning, New York: PMLR, 2017, 1607–1616. |
| [21] |
D. R. Insua, R. Naveiro, V. Gallego, J. Poulos, Adversarial machine learning: Bayesian perspectives, J. Am. Stat. Assoc., 118 (2023), 2195–2206. https://doi.org/10.1080/01621459.2023.2183129 doi: 10.1080/01621459.2023.2183129
|
| [22] |
S. Jantre, S. Bhattacharya, T. Maiti, Layer adaptive node selection in Bayesian neural networks: Statistical guarantees and implementation details, Neural Networks, 167 (2023), 309–330. https://doi.org/10.1016/j.neunet.2023.08.029 doi: 10.1016/j.neunet.2023.08.029
|
| [23] |
S. Jantre, S. Bhattacharya, T. Maiti, Spike-and-slab shrinkage priors for structurally sparse Bayesian neural networks, IEEE T. Neur. Net. Lear., 36 (2025), 11176–11188. https://doi.org/10.1109/TNNLS.2024.3485529 doi: 10.1109/TNNLS.2024.3485529
|
| [24] | A. Kendall, Y. Gal, What uncertainties do we need in Bayesian deep learning for computer vision?, In: Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook: Curran Associates Inc., 2017, 5580–5590. |
| [25] | D. P. Kingma, M. Welling, Auto-encoding variational Bayes, International Conference on Learning Representations, Banff, Canada, 2014. |
| [26] | D. Krueger, C.-W. Huang, R. Islam, R. Turner, A. Lacoste, A. Courville, Bayesian hypernetworks, Second workshop on Bayesian Deep Learning (NIPS 2017), Long Beach, USA, 2017. |
| [27] | Y. Z. Li, Y. Gal, Dropout inference in Bayesian neural networks with alpha-divergences, In: Proceedings of the 34th International Conference on Machine Learning, New York: PMLR, 2017, 2052–2061. |
| [28] |
Z. Li, L. Bin, On weighted residual varextropy: characterization, estimation and application, AIMS Mathematics, 10 (2025), 11234–11259. https://doi.org/10.3934/math.2025509 doi: 10.3934/math.2025509
|
| [29] | C. Louizos, K. Ullrich, M. Welling, Bayesian compression for deep learning, In: Proceedings of the 31st International Conference on Neural Information Processing Systems, Red Hook: Curran Associates Inc., 2017, 3290–3300. |
| [30] |
H. Li, Y. G. Kao, H. B. Bao, Y. Q. Chen, Uniform stability of complex-valued neural networks of fractional order with linear impulses and fixed time delays, IEEE T. Neur. Net. Lear., 33 (2022), 5321–5331. https://doi.org/10.1109/TNNLS.2021.3070136 doi: 10.1109/TNNLS.2021.3070136
|
| [31] |
P. F. Li, Q. H. Hu, X. F. Wang, Federated learning meets Bayesian neural network: Robust and uncertainty-aware distributed variational inference, Neural Networks, 185 (2025), 107135. https://doi.org/10.1016/j.neunet.2025.107135 doi: 10.1016/j.neunet.2025.107135
|
| [32] |
Y. D. Lin, Q. T. Zhang, B. Gao, J. S. Tang, P. Yao, C. X. Li, et al., Uncertainty quantification via a memristor Bayesian deep neural network for risk-sensitive reinforcement learning, Nat. Mach. Intell., 5 (2023), 714–723. https://doi.org/10.1038/s42256-023-00680-y doi: 10.1038/s42256-023-00680-y
|
| [33] |
M. Magris, A. Iosifidis, Bayesian learning for neural networks: An algorithmic survey, Artif. Intell. Rev., 56 (2023), 11773–11823. https://doi.org/10.1007/s10462-023-10443-1 doi: 10.1007/s10462-023-10443-1
|
| [34] | A. Malinin, M. Gales, Predictive uncertainty estimation via prior networks, In: Proceedings of the 32nd International Conference on Neural Information Processing Systems, Red Hook: Curran Associates Inc., 2018, 7047–7058. |
| [35] | J. Mitros, A. Pakrashi, B. M. Namee, Ramifications of approximate posterior inference for Bayesian deep learning in adversarial and out-of-distribution settings, In: Computer Vision–ECCV 2020 Workshops, Cham: Springer, 2020, 71–87. https://doi.org/10.1007/978-3-030-66415-2_5 |
| [36] | E. T. Nalisnick, On prior for Bayesian neural networks, PhD Thesis, UC Irvine, 2018. |
| [37] | E. T. Nalisnick, J. M. Hernandez-Lobato, P. Smyth, Dropout as a structured shrinkage prior, In: Proceedings of the 36th International Conference on Machine Learning, New York: PMLR, 2019, 4712–4722. |
| [38] | S. W. Ober, L. Aitchison, Global inducing point variational posteriors for Bayesian neural networks and deep Gaussian processes, In: Proceedings of the 38th International Conference on Machine Learning, New York: PMLR, 2021, 8248–8259. |
| [39] | H. Overweg, A.-L. Popkes, A. Ercole, Y. Z. Li, J. M. Hernández-Lobato, Y. Zaykov, et al., Interpretable outcome prediction with sparse Bayesian neural networks in intensive care, arXiv: 1905.02599, (2019). |
| [40] | J. Piironen, A. Vehtari, On the hyperprior choice for the global shrinkage parameter in the horseshoe prior, In: Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, New York: PMLR, 2017,905–913. |
| [41] |
I. Qureshi, J. H. Yan, Q. Abbas, K. Shaheed, A. B. Riaz, A. Wahid, et al., Medical image segmentation using deep semantic-based methods: A review of techniques, applications and emerging trends, Inform. Fusion, 90 (2023), 316–352. https://doi.org/10.1016/j.inffus.2022.09.031 doi: 10.1016/j.inffus.2022.09.031
|
| [42] |
S. Rodríguez-Santana, D. Hernández-Lobato, Adversarial $\alpha$-divergence minimization for Bayesian approximate inference, Neurocomputing, 471 (2022), 260–274. https://doi.org/10.1016/j.neucom.2020.09.076 doi: 10.1016/j.neucom.2020.09.076
|
| [43] | S. Y. Sun, G. D. Zhang, J. X. Shi, Functional variational Bayesian neural networks, Bayesian Deep Learning (NeurIPS 2018), Montréal, Canada, 2019. |
| [44] | M. Sarıyıldız, K. Alahari, D. Larlus, Y. Kalantidis, Fake it till you make it: Learning transferable representations from synthetic imagenet clones, 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, Canada, 2023, 8011–8021. https://doi.org/10.1109/CVPR52729.2023.00774 |
| [45] | L. Skaaret-Lund, G. Storvik, A. Hubin, Sparsifying Bayesian neural networks with latent binary variables and normalizing flows, arXiv: 2305.03395, (2023). |
| [46] | F. B. Smith, A. Kirsch, S. Farquhar, Y. Gal, A. Foster, T. Rainforth, Prediction-oriented Bayesian active learning, In: Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, New York: PMLR, 2023, 7331–7348. |
| [47] |
Y. Sun, Q. F. Song, F. M. Liang, Consistent sparse deep learning: theory and computation, J. Am. Stat. Assoc., 117 (2022), 1981–1995. https://doi.org/10.1080/01621459.2021.1895175 doi: 10.1080/01621459.2021.1895175
|
| [48] |
Y. Yang, D. D. Guo, B. Chen, D. X. Hu, Continual learning with Bayesian compression for shared and private latent representations, Neural Networks, 185 (2025), 107167. https://doi.org/10.1016/j.neunet.2025.107167 doi: 10.1016/j.neunet.2025.107167
|
| [49] |
C. Zhang, J. Butepage, H. Kjellstrom, S. Mandt, Advances in variational inference, IEEE T. Pattern Anal., 41 (2019), 2008–2026. https://doi.org/10.1109/TPAMI.2018.2889774 doi: 10.1109/TPAMI.2018.2889774
|
| [50] |
Z. D. Zhu, K. X. Lin, A. K. Jain, J. Y. Zhou, Transfer learning in deep reinforcement learning: A survey, IEEE T. Pattern Anal., 45 (2023), 13344–13362. https://doi.org/10.1109/TPAMI.2023.3292075 doi: 10.1109/TPAMI.2023.3292075
|







Figures(8) / Tables(7)

Xu Chen, Lilong Sima, Zhen Wei, Xingde Duan, Ping Feng, Fuhong Song. Variational sparse Bayesian neural networks with regularized horseshoe priors and scale mixture priors[J]. AIMS Mathematics, 2025, 10(9): 21929-21952. doi: 10.3934/math.2025977







 DownLoad:
DownLoad: