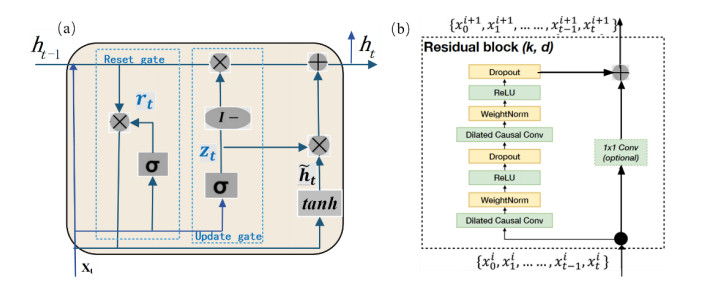
Flood time series forecasting stands a critical challenge in precise predictive models and reliable error estimation methods. A novel approach utilizing a hybrid deep learning model for both point and interval flood prediction is presented, enhanced by improved kernel density estimation (KDE) for prediction comparison and error simulation. Firstly, an optimized gated recurrent unit-time convolutional network (GRU-TCN) is constructed by tuning the internal structure of the TCN, the activation function, the L2 regularization, and the optimizer. Then, Pearson Correlation is used for feature selection, and the hyperparameters of the improved GRU-TCN are optimized by the subtraction-average-based optimizer (SABO). To further assess the prediction uncertainty, interval predictions are provided via Non-parametric KDE, with an optimized bandwidth setting for accurate error distribution simulation. Experimental comparisons are made on 5-year hydro-meteorological daily data from two stations along the Yangtze River. The proposed model surpasses long short-term memory network (LSTM), TCN, GRU, TCN-LSTM, and GRU-TCN, with a reduction of more than 13% in root mean square error (RMSE) and approximately 15% in mean absolute error (MAE), resulting in better interval estimation and error control. The improved kernel density estimation curves for the errors are closer to the mean value of the confidence intervals, better reflecting the trend of the error distribution. This research enhances the accuracy and reliability of flood predictions and improves the capacity of humans to cope with climate and environmental changes.
Citation: Chenmin Ni, Muhammad Fadhil Marsani, Fam Pei Shan, Xiaopeng Zou. Flood prediction with optimized gated recurrent unit-temporal convolutional network and improved KDE error estimation[J]. AIMS Mathematics, 2024, 9(6): 14681-14696. doi: 10.3934/math.2024714
Flood time series forecasting stands a critical challenge in precise predictive models and reliable error estimation methods. A novel approach utilizing a hybrid deep learning model for both point and interval flood prediction is presented, enhanced by improved kernel density estimation (KDE) for prediction comparison and error simulation. Firstly, an optimized gated recurrent unit-time convolutional network (GRU-TCN) is constructed by tuning the internal structure of the TCN, the activation function, the L2 regularization, and the optimizer. Then, Pearson Correlation is used for feature selection, and the hyperparameters of the improved GRU-TCN are optimized by the subtraction-average-based optimizer (SABO). To further assess the prediction uncertainty, interval predictions are provided via Non-parametric KDE, with an optimized bandwidth setting for accurate error distribution simulation. Experimental comparisons are made on 5-year hydro-meteorological daily data from two stations along the Yangtze River. The proposed model surpasses long short-term memory network (LSTM), TCN, GRU, TCN-LSTM, and GRU-TCN, with a reduction of more than 13% in root mean square error (RMSE) and approximately 15% in mean absolute error (MAE), resulting in better interval estimation and error control. The improved kernel density estimation curves for the errors are closer to the mean value of the confidence intervals, better reflecting the trend of the error distribution. This research enhances the accuracy and reliability of flood predictions and improves the capacity of humans to cope with climate and environmental changes.

| [1] | J. Douris, G. Kim, The Atlas of mortality and economic losses from weather, climate and water extremes (1970–2019), World Meteorological Organization, 2021. |
| [2] |
J. B. Liu, X. Y. Yuan, Prediction of the air quality index of Hefei based on an improved ARIMA model, AIMS Math., 8 (2023), 18717–18733. https://doi.org/10.3934/math.2023953 doi: 10.3934/math.2023953

|
| [3] |
B. Yan, R. Mu, J. Guo, Y. Liu, J. Tang, H. Wang, Flood risk analysis of reservoirs based on full-series ARIMA model under climate change, J. Hydrol., 610 (2022), 127979. https://doi.org/10.1016/j.jhydrol.2022.127979 doi: 10.1016/j.jhydrol.2022.127979
|
| [4] |
B. Jiang, S. Chen, B. Wang, B. Luo, MGLNN: semi-supervised learning via multiple graph cooperative learning neural networks, Neural Networks, 153 (2022), 204–214. https://doi.org/10.1016/j.neunet.2022.05.024 doi: 10.1016/j.neunet.2022.05.024
|
| [5] | D. K. Hakim, R. Gernowo, A. W. Nirwansyah, Flood prediction with time series data mining: systematic review, Nat. Hazards Res., in press, 2023. https://doi.org/10.1016/j.nhres.2023.10.001 |
| [6] |
A. M. Roy, J. Bhaduri, DenseSPH-YOLOv5: an automated damage detection model based on DenseNet and Swin-Transformer prediction head-enabled YOLOv5 with attention mechanism, Adv. Eng. Inf., 56 (2023), 102007. https://doi.org/10.1016/j.aei.2023.102007 doi: 10.1016/j.aei.2023.102007
|
| [7] |
L. Zhang, H. Qin, J. Mao, X. Cao, G. Fu, High temporal resolution urban flood prediction using attention-based LSTM models, J. Hydrol., 620 (2023), 129499. https://doi.org/10.1016/j.jhydrol.2023.129499 doi: 10.1016/j.jhydrol.2023.129499
|
| [8] |
Z. Vizi, B. Batki, L. Rátki, S. Szalánczi, I. Fehérváry, P. Kozák, et al., Water level prediction using long short-term memory neural network model for a lowland river: a case study on the Tisza River, Central Europe, Environ. Sci. Eur., 35 (2023), 92. https://doi.org/10.1186/s12302-023-00796-3 doi: 10.1186/s12302-023-00796-3
|
| [9] |
C. Ni, P. S. Fam, M. F. Marsani, A data-driven method and hybrid deep learning model for flood risk prediction, Int. J. Intell. Syst., 2024 (2024), 3562709. https://doi.org/10.1155/2024/3562709 doi: 10.1155/2024/3562709
|
| [10] |
J. Chung, Ç. Gülçehre, K. Cho, Y. Bengio, Empirical evaluation of gated recurrent neural networks on sequence modeling, arXiv, 2014. https://doi.org/10.48550/arXiv.1412.3555 doi: 10.48550/arXiv.1412.3555
|
| [11] |
F. Abid, M. Alam, F. S. Alamri, I. Siddique, Multi-directional gated recurrent unit and convolutional neural network for load and energy forecasting: a novel hybridization, AIMS Math., 8 (2023), 19993–20017. https://doi.org/10.3934/math.20231019 doi: 10.3934/math.20231019
|
| [12] |
C. Ji, T. Peng, C. Zhang, L. Hua, W. Sun, An integrated framework of GRU based on improved whale optimization algorithm for flood prediction, Res. Square, 2021. https://doi.org/10.21203/rs.3.rs-947198/v1 doi: 10.21203/rs.3.rs-947198/v1
|
| [13] |
S. Bai, J. Z. Kolter, V. Koltun, An empirical evaluation of generic convolutional and recurrent networks for sequence modeling, arXiv, 2018. https://doi.org/10.48550/arXiv.1803.01271 doi: 10.48550/arXiv.1803.01271
|
| [14] |
H. Xue, X. Gui, G. Wang, X. Yang, H. Gong, Prediction of gas drainage changes from nitrogen replacement: a study of a TCN deep learning model with integrated attention mechanism, Fuel, 357 (2024), 129797. https://doi.org/10.1016/j.fuel.2023.129797 doi: 10.1016/j.fuel.2023.129797
|
| [15] |
R. Gong, J. Li, C. Wang, Remaining useful life prediction based on multisensor fusion and attention TCN-BiGRU model, IEEE Sensors J., 22 (2022), 21101–21110. https://doi.org/10.1109/jsen.2022.3208753 doi: 10.1109/jsen.2022.3208753
|
| [16] |
Y. Xu, C. Hu, Q. Wu, Z. Li, S. Jian, Y. Chen, Application of temporal convolutional network for flood forecasting, Hydrol. Res., 52 (2021), 1455–1468. https://doi.org/10.2166/nh.2021.021 doi: 10.2166/nh.2021.021
|
| [17] |
X. Zhang, F. Dong, G. Chen, Z. Dai, Advance prediction of coastal groundwater levels with temporal convolutional and long short-term memory networks, Hydrol. Earth Syst. Sci., 27 (2023), 83–96. https://doi.org/10.5194/hess-27-83-2023 doi: 10.5194/hess-27-83-2023
|
| [18] |
G. Li, Z. Liu, J. Zhang, H. Han, Z. Shu, Bayesian model averaging by combining deep learning models to improve lake water level prediction, Sci. Total Environ., 906 (2024), 167718. https://doi.org/10.1016/j.scitotenv.2023.167718 doi: 10.1016/j.scitotenv.2023.167718
|
| [19] |
M. A. Khanesar, D. T. Branson, Prediction interval identification using interval type-2 fuzzy logic systems: lake water level prediction using remote sensing data, IEEE Sensors J., 21 (2021), 13815–13827. https://doi.org/10.1109/jsen.2021.3067841 doi: 10.1109/jsen.2021.3067841
|
| [20] |
J. Wang, Z. Li, Wind speed interval prediction based on multidimensional time series of convolutional neural networks, Eng. Appl. Artif. Intell., 121 (2023), 105987. https://doi.org/10.1016/j.engappai.2023.105987 doi: 10.1016/j.engappai.2023.105987
|
| [21] |
C. Pan, J. Tan, D. Feng, Prediction intervals estimation of solar generation based on gated recurrent unit and kernel density estimation, Neurocomputing, 453 (2021), 552–562. https://doi.org/10.1016/j.neucom.2020.10.027 doi: 10.1016/j.neucom.2020.10.027
|
| [22] |
B. Badyalina, N. A. Mokhtar, N. A. M. Jan, M. F. Marsani, M. F. Ramli, M. Majid, et al., Hydroclimatic data prediction using a new ensemble group method of data handling coupled with artificial bee colony algorithm, Sains Malays., 51 (2022), 2655–2668. https://doi.org/10.17576/jsm-2022-5108-24 doi: 10.17576/jsm-2022-5108-24
|
| [23] |
M. Zhou, Y. Zhang, S. Wu, L. Kong, Z. Wang, Interval prediction of remaining life of a bearing based on CNN, J. Mech. Electr. Eng., 40 (2023), 1225–1230. https://doi.org/10.3969/j.issn.1001-4551.2023.08.011 doi: 10.3969/j.issn.1001-4551.2023.08.011
|
| [24] |
X. Zhangsun, C. D, Research on equipment reliability of nuclear power plant by interval estimation of exponential distribution life test, Nuclear Saf., 22 (2023), 90–94. https://doi.org/10.16432/j.cnki.1672-5360.2023.05.010 doi: 10.16432/j.cnki.1672-5360.2023.05.010
|
| [25] |
W. Liao, S. Wang, B. Bak-Jensen, J. R. Pillai, Z. Yang, K. Liu, Ultra-short-term interval prediction of wind power based on graph neural network and improved bootstrap technique, J. Mod. Power Syst. Clean Energy, 11 (2023), 1100–1114. https://doi.org/10.35833/mpce.2022.000632 doi: 10.35833/mpce.2022.000632
|
| [26] |
H. Xu, Y. Chang, Y. Zhao, F. Wang, A novel hybrid wind speed interval prediction model based on mode decomposition and gated recursive neural network, Environ. Sci. Pollut. Res., 29 (2022), 87097–87113. https://doi.org/10.1007/s11356-022-21904-5 doi: 10.1007/s11356-022-21904-5
|
| [27] |
L. Wu, Q. Tai, Y. Bian, Y. Li, Point and interval forecasting of ultra-short-term carbon price in China, Carbon Manag., 14 (2023), 2275576. https://doi.org/10.1080/17583004.2023.2275576 doi: 10.1080/17583004.2023.2275576
|
| [28] |
M. Wang, F. Ying, Point and interval prediction for significant wave height based on LSTM-GRU and KDE, Ocean Eng., 289 (2023), 116247. https://doi.org/10.1016/j.oceaneng.2023.116247 doi: 10.1016/j.oceaneng.2023.116247
|
| [29] |
D. Li, F. Jiang, M. Chen, T. Qian, Multi-step-ahead wind speed forecasting based on a hybrid decomposition method and temporal convolutional networks, Energy, 238 (2022), 121981. https://doi.org/10.1016/j.energy.2021.121981 doi: 10.1016/j.energy.2021.121981
|
| [30] |
P. Trojovský, M. Dehghani, Subtraction-average-based optimizer: a new swarm-inspired metaheuristic algorithm for solving optimization problems, Biomimetics, 8 (2023), 149. https://doi.org/10.3390/biomimetics8020149 doi: 10.3390/biomimetics8020149
|
| [31] |
N. Jiang, X. Yu, M. Alam, A hybrid carbon price prediction model based-combinational estimation strategies of quantile regression and long short-term memory, J. Clean. Prod., 429 (2023), 139508. https://doi.org/10.1016/j.jclepro.2023.139508 doi: 10.1016/j.jclepro.2023.139508
|
| [32] |
V. Paquianadin, K. N. Sam, G. Koperundevi, M. M. R. Singaravel, Current sensor-based single MPPT controller using sequential golden section search algorithm for hybrid solar PV generator-TEG in isolated DC microgrid, Solar Energy, 266 (2023), 112147. https://doi.org/10.1016/j.solener.2023.112147 doi: 10.1016/j.solener.2023.112147
|
| [33] |
J. F. Ruma, M. S. G. Adnan, A. Dewan, R. M. Rahman, Particle swarm optimization based LSTM networks for water level forecasting: a case study on Bangladesh river network, Result Eng., 17 (2023), 100951. https://doi.org/10.1016/j.rineng.2023.100951 doi: 10.1016/j.rineng.2023.100951
|
| [34] |
L. Li, Y. Li, R. Mao, L. Li, W. Hua, J. Zhang, Remaining useful life prediction for lithium-ion batteries with a hybrid model based on TCN-GRU-DNN and dual attention mechanism, IEEE Trans. Transp. Electrific., 9 (2023), 4726–4740. https://doi.org/10.1109/tte.2023.3247614 doi: 10.1109/tte.2023.3247614
|







Figures(8) / Tables(3)

Chenmin Ni, Muhammad Fadhil Marsani, Fam Pei Shan, Xiaopeng Zou. Flood prediction with optimized gated recurrent unit-temporal convolutional network and improved KDE error estimation[J]. AIMS Mathematics, 2024, 9(6): 14681-14696. doi: 10.3934/math.2024714







 DownLoad:
DownLoad: