This paper aimed to demonstrate the correlation, a hidden, intricate, interplay, between the conception of risk and the fluid nature of society during the eras of migratory relocations as portrayed in Salman Rushdie's literary masterpiece, The Satanic Verses. The general premise found in this paper was that risk is based on the following logical axiom: Risk is mathematically unpredictable, something that goes beyond the human capability of discernment or probabilistic prevision. This blank space that separates reality from its potentiality is the risk. Thus, in migratory relocation, the risk consists of the unknowability of what could happen the second after having passed a line. It is the border of what is known. Rushdie's work offers profound insights into the ways in which individuals navigate the turbulent waters of a rapidly changing world, where cultural, social, and political paradigms constantly shift. In the first part of this work, we will present the main topics related to risk. Rushdie's work underlines the central role that storytelling and narrative play in navigating the complexities of a fluid society. The characters in Rushdie's novel employ storytelling as a means of understanding and asserting their own identities, thereby confronting the inherent risk of being silenced or marginalized in a world dominated by shifting power dynamics. In conclusion, Salman Rushdie's The Satanic Verses provides a rich tapestry of narratives that not only explore the conception of risk in a fluid society but also challenge readers to contemplate the intricate interplay of identity, culture, and faith in an ever-changing world. This works serve as a testament to the power of literature to engage with contemporary issues, transcending boundaries, and sparking critical conversations. Through his vivid characters and daring narratives, Rushdie invites readers to grapple with the aims and main issues of our time: the quest for self-identity, the inevitability of risk, and the enduring need for storytelling as a means of understanding and shaping our rapidly evolving society.
Citation: Matteo Bona. Comprehending the risk throughout a literary-geocritical approach. Rushdie's The Satanic Verses as evidence and an opportunity in investigating risk scenarios[J]. AIMS Geosciences, 2024, 10(2): 419-435. doi: 10.3934/geosci.2024022
This paper aimed to demonstrate the correlation, a hidden, intricate, interplay, between the conception of risk and the fluid nature of society during the eras of migratory relocations as portrayed in Salman Rushdie's literary masterpiece, The Satanic Verses. The general premise found in this paper was that risk is based on the following logical axiom: Risk is mathematically unpredictable, something that goes beyond the human capability of discernment or probabilistic prevision. This blank space that separates reality from its potentiality is the risk. Thus, in migratory relocation, the risk consists of the unknowability of what could happen the second after having passed a line. It is the border of what is known. Rushdie's work offers profound insights into the ways in which individuals navigate the turbulent waters of a rapidly changing world, where cultural, social, and political paradigms constantly shift. In the first part of this work, we will present the main topics related to risk. Rushdie's work underlines the central role that storytelling and narrative play in navigating the complexities of a fluid society. The characters in Rushdie's novel employ storytelling as a means of understanding and asserting their own identities, thereby confronting the inherent risk of being silenced or marginalized in a world dominated by shifting power dynamics. In conclusion, Salman Rushdie's The Satanic Verses provides a rich tapestry of narratives that not only explore the conception of risk in a fluid society but also challenge readers to contemplate the intricate interplay of identity, culture, and faith in an ever-changing world. This works serve as a testament to the power of literature to engage with contemporary issues, transcending boundaries, and sparking critical conversations. Through his vivid characters and daring narratives, Rushdie invites readers to grapple with the aims and main issues of our time: the quest for self-identity, the inevitability of risk, and the enduring need for storytelling as a means of understanding and shaping our rapidly evolving society.

| [1] | Caloi P (1966) L'evento del Vajont nei suoi aspetti geodinamici. Annali di Geofisica, 19. |
| [2] |
Carley S (2022) Specialty grand challenge: energy transitions, human dimensions, and society. Front Sustain Energy Policy 1: 1063207. https://doi.org/10.3389/fsuep.2022.1063207 doi: 10.3389/fsuep.2022.1063207

|
| [3] |
Cook R (1994) Place and Displacement in Salman Rushdie's Work. World Literature Tod 68: 23–28. https://doi.org/10.2307/40149840 doi: 10.2307/40149840
|
| [4] | Morini S (2014) Il rischio. Da Pascal a Fukushima, Bollati Boringhieri srl. |
| [5] |
Ermakoff I (2015) The structure of contingency. Am J Sociol 121: 64–125. https://doi.org/10.1086/682026 doi: 10.1086/682026
|
| [6] | Rüschendorf L (2013) Mathematical risk analysis. Dependence, Risk Bounds, Optimal Allocations and Portfolios, Springer Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-33590-7 |
| [7] | Beck U, Lash S, Wynne B (1992) Risk society: Towards a new modernity, Sage. |
| [8] | Sharp JP (1994) A topology of "post" nationality: (re)mapping identity in 'The Satanic Verses'. Ecumene 1: 65–76. http://www.jstor.org/stable/44251683 |
| [9] |
McNamara DS (2011) Computational methods to extract meaning from text and advance theories of human cognition. Top Cogn Sci 3: 3–17. https://doi.org/10.1111/j.1756-8765.2010.01117.x doi: 10.1111/j.1756-8765.2010.01117.x
|
| [10] |
Wulff DU, Mata R (2022) On the semantic representation of risk. Sci Adv 8: eabm1883. https://doi.org/10.1126/sciadv.abm1883 doi: 10.1126/sciadv.abm1883
|
| [11] | Zinn JO (2006) Recent Developments in Sociology of Risk and Uncertainty. Hist Soc Res 31: 275–286. |
| [12] | Blommaert J (2013) Ethnography, superdiversity and linguistic landscapes: Chronicles of complexity, Multilingual Matters. |
| [13] | Costa MM, Máñ ez KS, Paragay SH (2013) Adaptation to Climate Change under Changing Urban Patterns: The Climatic Perspective of Migration. Climate Change: International Law and Global Governance, Nomos Verlagsgesellschaft mbH & Co. KG, 785–798. |
| [14] |
Baden C, Pipal C, Schoonvelde M, et al. (2022) Three gaps in computational text analysis methods for social sciences: A research agenda. Commun Methods Meas 16: 1–18. https://doi.org/10.1080/19312458.2021.2015574 doi: 10.1080/19312458.2021.2015574
|
| [15] | Wilkinson I (2002) Anxiety in a 'risk' society, Routledge. |
| [16] | Bazzanella C (2014) Linguistica cognitiva. Un'introduzione, Gius. Laterza & Figli Spa. |
| [17] |
Gane G (2002) Migrancy, the Cosmopolitan Intellectual, and the Global City in The Satanic Verses. MFS Mod Fict Stud 48: 18–49. https://doi.org/10.1353/mfs.2002.0007 doi: 10.1353/mfs.2002.0007
|
| [18] |
Evans V (2012) Cognitive linguistics. WIRES Cogn Sci 3: 129–141. https://doi.org/10.1002/wcs.1163 doi: 10.1002/wcs.1163
|
| [19] |
Radhakrishnan R (1993) Postcoloniality and The Boundaries of Identity. Callaloo 16: 750–771. https://doi.org/10.2307/2932208 doi: 10.2307/2932208
|
| [20] |
Mairal G (2008) Narratives of risk. J Risk Res 11: 41–54. https://doi.org/10.1080/13669870701521321 doi: 10.1080/13669870701521321
|
| [21] | Mascia R (2020) Complications of the Climate Change Narrative within the Lives of Climate Refugees: Slow Causality and Apocalyptic Themes. Consilience 22: 31–38. |
| [22] |
Mairal G (2011) The history and the narrative of risk in the media. Health Risk Soc 13: 65–79. https://doi.org/10.1080/13698575.2010.540313 doi: 10.1080/13698575.2010.540313
|
| [23] |
Sharma S (2001) Salman Rushdie: The Ambivalence of Migrancy. Twentieth Cent Lit 47: 596–618. https://doi.org/10.2307/3175995 doi: 10.2307/3175995
|
| [24] |
Liuzzo G, Bentley S, Giacometti F, et al. (2014) The Term Risk: Etymology, Legal Definition and Various Traits. Ital J Food Saf 3: 2269. https://doi.org/10.4081/ijfs.2014.2269 doi: 10.4081/ijfs.2014.2269
|
| [25] | Simandan D (2011) The wise stance in human geography. T I Brit Geogr 36: 188–192. |
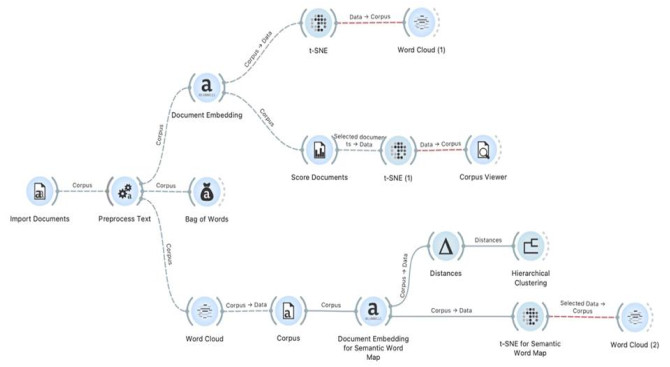
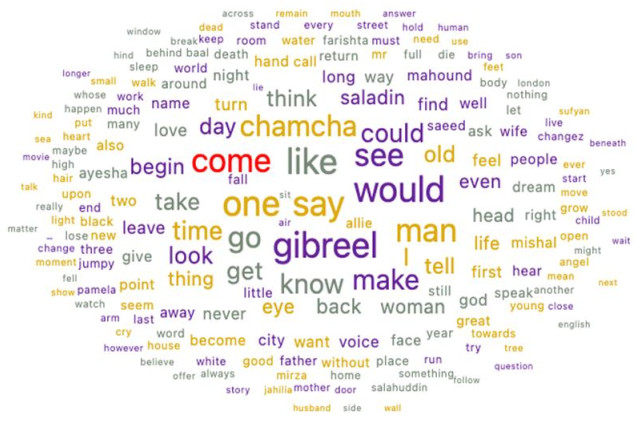
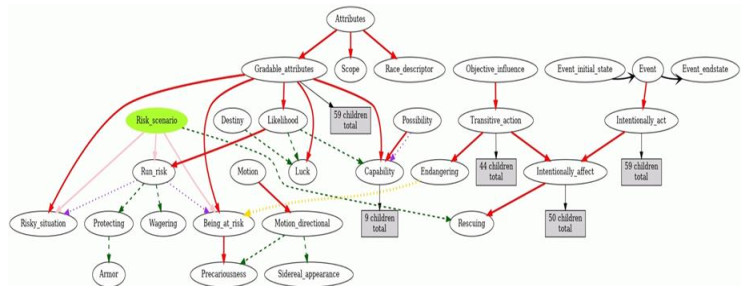
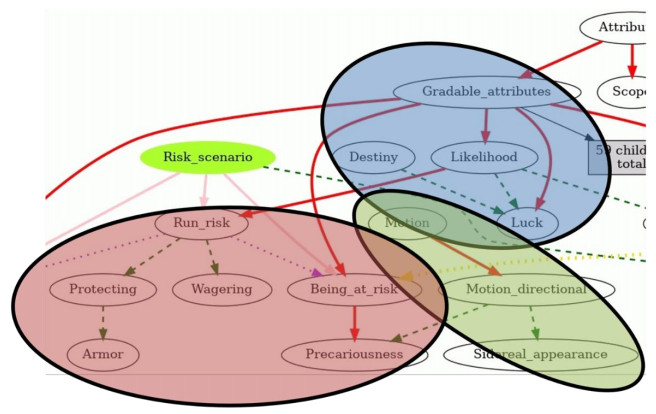
Figures(5)

Matteo Bona. Comprehending the risk throughout a literary-geocritical approach. Rushdie's The Satanic Verses as evidence and an opportunity in investigating risk scenarios[J]. AIMS Geosciences, 2024, 10(2): 419-435. doi: 10.3934/geosci.2024022







 DownLoad:
DownLoad: