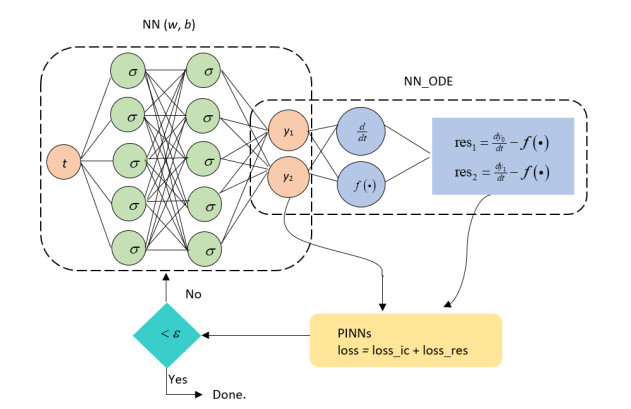
This paper adopted the alternating direction method of multipliers (ADMM) which aims to delve into data-driven differential equations. ADMM is an optimization method designed to solve convex optimization problems. This paper attempted to illustrate the conceptual ideas and parameter discovery of the linear coupled first-order ODE. The estimation of the coefficients of the underlying equation utilized a combination of algorithms between physics-informed neural networks (PINNs) and sparse optimization. Both methods underwent a sufficient amount of looping during the search for the best combinations of coefficients. The PINNs method took charge of updating weights and biases. The updated trainable variables were then fetched to the sparse optimization method. During the sparse optimization process, ADMM was used to restructure the constrained optimization problems into unconstrained optimization problems. The unconstrained optimization problem usually consists of smooth (differentiable) and non-smooth (non-differentiable) components. By using the augmented Lagrangian method, both smooth and non-smooth components of the equations can be optimized to suggest the best combinations of coefficients. ADMM has found applications in various fields, such as signal processing, machine learning, and image reconstruction, which involve decomposable structures. The proposed algorithm provides a way to discover sparse approximations of differential equations from data. This data-driven approach provides insights and a step-by-step algorithm guide to allow more research opportunities to explore the possibility of representing any physical phenomenon with differential equations.
Citation: Jye Ying Sia, Yong Kheng Goh, How Hui Liew, Yun Fah Chang. Constructing hidden differential equations using a data-driven approach with the alternating direction method of multipliers (ADMM)[J]. Electronic Research Archive, 2025, 33(2): 890-906. doi: 10.3934/era.2025040
This paper adopted the alternating direction method of multipliers (ADMM) which aims to delve into data-driven differential equations. ADMM is an optimization method designed to solve convex optimization problems. This paper attempted to illustrate the conceptual ideas and parameter discovery of the linear coupled first-order ODE. The estimation of the coefficients of the underlying equation utilized a combination of algorithms between physics-informed neural networks (PINNs) and sparse optimization. Both methods underwent a sufficient amount of looping during the search for the best combinations of coefficients. The PINNs method took charge of updating weights and biases. The updated trainable variables were then fetched to the sparse optimization method. During the sparse optimization process, ADMM was used to restructure the constrained optimization problems into unconstrained optimization problems. The unconstrained optimization problem usually consists of smooth (differentiable) and non-smooth (non-differentiable) components. By using the augmented Lagrangian method, both smooth and non-smooth components of the equations can be optimized to suggest the best combinations of coefficients. ADMM has found applications in various fields, such as signal processing, machine learning, and image reconstruction, which involve decomposable structures. The proposed algorithm provides a way to discover sparse approximations of differential equations from data. This data-driven approach provides insights and a step-by-step algorithm guide to allow more research opportunities to explore the possibility of representing any physical phenomenon with differential equations.

| [1] | L. Zheng, X. Zhang, Modelling and Analysis of Modern Fluid Problems, Elsevier INC., 2017. |
| [2] | J. Y. Sia, Y. K. Goh, H. H. Liew, Y. F. Chang, Error analysis of physics-informed neural networks (PINNs) in typical dynamical systems, J. Fiz. Malays., 44 (2023), 10044–10051. |
| [3] |
H. R. Samuel, L. B. Steven, L. P. Joshua, K. J. Nathan, Data-driven discovery of partial differential equations, Sci. Adv., 3 (2017), e1602614. https://doi.org/10.1126/sciadv.1602614 doi: 10.1126/sciadv.1602614

|
| [4] | S. Kamyab, Z. Azimifar, R. Sabzi, P. Fieguth, Survey of deep learning methods for inverse problems, preprint, arXiv: 2111.04731v2. https://doi.org/10.48550/arXiv.2111.04731 |
| [5] |
Z. Chen, Y. Liu, H. Sun, Physics-informed learning of governing equations from scarce data, Nat. Commun., 12 (2021), 1–13. https://doi.org/10.1038/s41467-021-26434-1 doi: 10.1038/s41467-021-26434-1
|
| [6] | J. F. Cai, K. S. Wei, Exploiting the structure effectively and efficiently in low rank matrix recovery, in Handbook of Numerical Analysis, 19 (2018), 21–51. https://doi.org/10.1016/bs.hna.2018.09.001 |
| [7] |
A. Haya, Deep learning-based model architecture for time-frequency images analysis, Int. J. Adv. Comput. Sci. Appl., 9 (2018). https://doi.org/10.14569/IJACSA.2018.091268 doi: 10.14569/IJACSA.2018.091268
|
| [8] |
I. E. Lagaris, A. Likas, D. I. Fotiadis, Artificial neural networks for solving ordinary and partial differential equations, IEEE Trans. Neural Networks, 9 (1998), 987–1000. https://doi.org/10.1109/72.712178 doi: 10.1109/72.712178
|
| [9] | A. Ahmad, T. M. Umadevi, J. C. Y. Ng, J. E. Toh, S. Koo, A. A. S. Zailan, A comparison review of optimizers and activation functions for convolutional neural networks, J. Appl. Technol. Innovation, 7 (2023), 37–45. |
| [10] |
Y. Shin, J. Darbon, G. E. Karniadakis, On the convergence of physics informed neural networks for linear second-order elliptic and parabolic type PDEs, Commun. Comput. Phys., 28 (2020), 2042–2074. https://doi.org/10.4208/cicp.oa-2020-0193 doi: 10.4208/cicp.oa-2020-0193
|
| [11] |
M. Raissi, P. Perdikaris, G. E. Karniadakis, Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations, J. Comput. Phys., 378 (2019), 686–707. https://doi.org/10.1016/j.jcp.2018.10.045 doi: 10.1016/j.jcp.2018.10.045
|
| [12] |
S. Mishra, R. Molinaro, Estimates on the generalization error of physics-informed neural networks for approximating a class of inverse problems for PDEs, IMA J. Numer. Anal., 42 (2021), 981–1022. https://doi.org/10.1093/imanum/drab032 doi: 10.1093/imanum/drab032
|
| [13] | J. Stiasny, S. Chevalier, S. Chatzivasileiadis, Learning without Data: Physics-Informed Neural Networks for fast time-domain simulation, in 2021 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids (SmartGridComm), (2021), 438–443. https://doi.org/10.1109/SmartGridComm51999.2021.9631995 |
| [14] |
P. H. W. Hoffmann, A Hitchhiker's guide to automatic differentiation, Numer. Algorithms, 72 (2016), 775–811. https://doi.org/10.1007/s11075-015-0067-6 doi: 10.1007/s11075-015-0067-6
|
| [15] |
H. Schaeffer, Learning partial differential equations via data discovery and sparse optimization, Proc. R. Soc. A: Math., Phys. Eng. Sci., 473 (2017). https://doi.org/10.1098/rspa.2016.0446 doi: 10.1098/rspa.2016.0446
|
| [16] |
X. Li, Y. Wang, R. Ruiz, A survey on sparse learning models for feature selection, IEEE Trans. Cybern., 52 (2022), 1642–1660. https://doi.org/10.1109/TCYB.2020.2982445 doi: 10.1109/TCYB.2020.2982445
|
| [17] |
K. Kampa, S. Mehta, C. A. Chou, W. A. Chaovalitwongse, T. J. Grabowski, Sparse optimization in feature selection: application in neuroimaging, J. Global Optim., 59 (2014), 439–457. https://doi.org/10.1007/s10898-013-0134-2 doi: 10.1007/s10898-013-0134-2
|
| [18] | K. Huang, H. Samani, C. Yang, J. Chen, Alternating direction method of multipliers for convex optimization in machine learning - interpretation and implementation, in 2022 2nd International Conference on Image Processing and Robotics (ICIPRob), (2022), 1–5. https://doi.org/10.1109/ICIPRob54042.2022.9798720 |
| [19] | J. Wang, H. Li, L. Zhao, A convergent ADMM framework for efficient neural network training, preprint, arXiv: 2112.11619. https://doi.org/10.48550/arXiv.2112.11619 |
| [20] | R. Nishihara, L. Lessard, B. Recht, A. Packard, M. Jordan, A general analysis of the convergence of ADMM, in Proceedings of the 32nd International Conference on Machine Learning, 37 (2015), 343–352. |
| [21] | G. Y. Yuan, S. Li, W. S. Zheng, A block decomposition algorithm for sparse optimization, in Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery; Data Mining, (2020), 275–285. https://doi.org/10.1145/3394486.3403070 |
| [22] |
B. Stephen, P. Neal, E. Chu, P. Borja, J. Eckstein, Distributed optimization and statistical learning via the alternating direction method of multipliers, Found. Trends Mach. Learn., 3 (2020), 1–122. https://doi.org/10.1561/2200000016 doi: 10.1561/2200000016
|
| [23] | O. Ruben, M. Michael, M. Lucas, M. Rudy, J. A. Fruzsina, B. Miguel, et al., The Well: a large-scale collection of diverse physics simulations for machine learning, preprint, arXiv: 2412.00568. https://doi.org/10.48550/arXiv.2412.00568 |








Figures(9)
Jye Ying Sia, Yong Kheng Goh, How Hui Liew, Yun Fah Chang. Constructing hidden differential equations using a data-driven approach with the alternating direction method of multipliers (ADMM)[J]. Electronic Research Archive, 2025, 33(2): 890-906. doi: 10.3934/era.2025040







 DownLoad:
DownLoad: