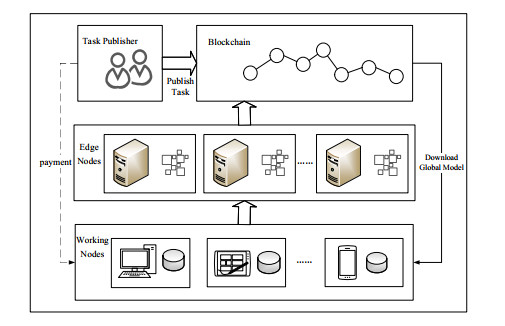
An optimization algorithm for federated learning, equipped with an incentive mechanism, is introduced to tackle the challenges of excessive iterations, prolonged training durations, and suboptimal efficiency encountered during model training within the federated learning framework. Initially, the algorithm establishes reputation values that are tied to both time and model loss metrics. This foundation enables the creation of incentive mechanisms aimed at rewarding honest nodes while penalizing malicious ones. Subsequently, a bidirectional selection mechanism anchored in blockchain technology is developed, allowing smart contracts to enroll nodes with high reputations in training sessions, thus filtering out malicious clients and enhancing local training efficiency. Furthermore, the integration of the Earth Mover's Distance (EMD) mechanism serves to lessen the impact of non-IID (non-Independent and Identically Distributed) data on the global model, leading to a reduction in the frequency of model training cycles and an improvement in model accuracy. Experimental results confirm that this approach maintains high model accuracy in non-IID data settings, outperforming traditional federated learning algorithms.
Citation: Xiaoyu Jiang, Ruichun Gu, Huan Zhan. Research on incentive mechanisms for anti-heterogeneous federated learning based on reputation and contribution[J]. Electronic Research Archive, 2024, 32(3): 1731-1748. doi: 10.3934/era.2024079
An optimization algorithm for federated learning, equipped with an incentive mechanism, is introduced to tackle the challenges of excessive iterations, prolonged training durations, and suboptimal efficiency encountered during model training within the federated learning framework. Initially, the algorithm establishes reputation values that are tied to both time and model loss metrics. This foundation enables the creation of incentive mechanisms aimed at rewarding honest nodes while penalizing malicious ones. Subsequently, a bidirectional selection mechanism anchored in blockchain technology is developed, allowing smart contracts to enroll nodes with high reputations in training sessions, thus filtering out malicious clients and enhancing local training efficiency. Furthermore, the integration of the Earth Mover's Distance (EMD) mechanism serves to lessen the impact of non-IID (non-Independent and Identically Distributed) data on the global model, leading to a reduction in the frequency of model training cycles and an improvement in model accuracy. Experimental results confirm that this approach maintains high model accuracy in non-IID data settings, outperforming traditional federated learning algorithms.

| [1] | I. S. Candanedo, E. H. Nieves, S. R. González, M. T. S. Martín, A. G. Briones, Machine learning predictive model for industry 4.0, in Knowledge Management in Organizations: 13th International Conference, Springer International Publishing, Žilina, Slovakia, (2018), 501–510. https://doi.org/10.1007/978-3-319-95204-8_42 |
| [2] |
M. A. Khan, H. El Sayed, S. Malik, M. T. Zia, N. Alkaabi, J. Khan, A journey towards fully autonomous driving-fueled by a smart communication system, Veh. Commun., 36 (2022), 100476. https://doi.org/10.1016/j.vehcom.2022.100476 doi: 10.1016/j.vehcom.2022.100476

|
| [3] |
C. J. Haug, J. M. Drazen, Artificial intelligence and machine learning in clinical medicine, N. Engl. J. Med., 388 (2023), 1201–1208. https://doi.org/10.1056/NEJMra2302038 doi: 10.1056/NEJMra2302038
|
| [4] |
A. A. Shaikh, K. S. Lakshmi, K. Tongkachok, J. Alanya-Beltran, E. Ramirez-Asis, J. Perez-Falcon, Empirical analysis in analysing the major factors of machine learning in enhancing the e-business through structural equation modelling (SEM) approach, Int. J. Syst. Assur. Eng. Manage., 13 (2022), 681–689. https://doi.org/10.1007/s13198-021-01590-1 doi: 10.1007/s13198-021-01590-1
|
| [5] | J. Konečný, H. B. McMahan, F. X. Yu, P. Richtárik, A. T. Suresh, D. Bacon, Federated learning: strategies for improving communication efficiency, preprint, arXiv: 1610.05492. https://doi.org/10.48550/arXiv.1610.05492 |
| [6] | Q. Li, Y. Diao, Q. Chen, B. He, Federated learning on non-iid data silos: an experimental study, in 2022 IEEE 38th International Conference on Data Engineering (ICDE), (2022), 965–978. https://doi.org/10.1109/ICDE53745.2022.00077 |
| [7] |
E. T. M. Beltrán, M. Q. Pérez, P. M. S. Sánchez, S. L. Bernal, G. Bovet, M. G. Pérez, et al., Decentralized federated learning: fundamentals, state of the art, frameworks, trends, and challenges, IEEE Commun. Surv. Tutorials, 2023. https://doi.org/10.1109/COMST.2023.3315746 doi: 10.1109/COMST.2023.3315746
|
| [8] | Y. Huang, L. Chu, Z. Zhou, L. Wang, J. Liu, J. Pei, et al., Personalized cross-silo federated learning on non-iid data, in Proceedings of the AAAI Conference on Artificial Intelligence, 35 (2021), 7865–7873. https://doi.org/10.1609/aaai.v35i9.16960 |
| [9] | V. Mugunthan, R. Rahman, L. Kagal, Blockflow: An accountable and privacy-preserving solution for federated learning, preprint, arXiv: 2007.03856. https://doi.org/10.48550/arXiv.2007.03856 |
| [10] |
Q. Wang, Y. Guo, L. Yu, P. Li, Earthquake prediction based on spatio-temporal data mining: an LSTM network approach, IEEE Trans. Emerging Top. Comput., 8 (2017), 148–158. https://doi.org/10.1109/TETC.2017.2699169 doi: 10.1109/TETC.2017.2699169
|
| [11] |
J. Li, Y. Shao, K. Wei, M. Ding, C. Ma, L. Shi, et al., Blockchain assisted decentralized federated learning (BLADE-FL): Performance analysis and resource allocation, IEEE Trans. Parallel Distrib. Syst., 33 (2021), 2401–2415. https://doi.org/10.1109/TPDS.2021.3138848 doi: 10.1109/TPDS.2021.3138848
|
| [12] | X. Wu, Z. Wang, J. Zhao, Y. Zhang, Y. Wu, FedBC: blockchain-based decentralized federated learning, in IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), (2020), 217–221. https://doi.org/10.1109/ICAICA50127.2020.9182705 |
| [13] |
W. Zhang, Y. Zhao, F. Li, H. Zhu, A hierarchical federated learning algorithm based on time aggregation in edge computing environment, Appl. Sci., 13 (2023), 5821. https://doi.org/10.3390/app13095821 doi: 10.3390/app13095821
|
| [14] |
J. Guo, Z. Liu, S. Tian, F. Huang, J. Li, X. Li, et al., TFL-DT: a trust evaluation scheme for federated learning in digital twin for mobile networks, IEEE J. Sel. Areas Commun., 41 (2023), 3548–3560. https://doi.org/10.1109/JSAC.2023.3310094 doi: 10.1109/JSAC.2023.3310094
|
| [15] | I. Martinez, S. Francis, A. S. Hafid, Record and reward federated learning contributions with blockchain, in 2019 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), (2019), 50–57. https://doi.org/10.1109/CyberC.2019.00018 |
| [16] | Y. Liu, Z. Ai, S. Sun, S. Zhang, Z. Liu, H. Yu, Fedcoin: a peer-to-peer payment system for federated learning, in Federated Learning: Privacy and Incentive, Cham: Springer International Publishing, (2020), 125–138. https://doi.org/10.1007/978-3-030-63076-8_9 |
| [17] |
J. Kang, Z. Xiong, D. Niyato, Y. Zou, Y. Zhang, M. Guizani, Reliable federated learning for mobile networks, IEEE Wireless Commun., 27 (2020), 72–80. https://doi.org/10.1109/MWC.001.1900119 doi: 10.1109/MWC.001.1900119
|
| [18] |
J. Guo, L. Xiong, J. Li, J. Liu, S. Tian, H. Li, An incentive mechanism for horizontal federated learning based on the principle of compound interest, Phys. Commun., 60 (2023), 102128. https://doi.org/10.1016/j.phycom.2023.102128 doi: 10.1016/j.phycom.2023.102128
|
| [19] | B. McMahan, E. Moore, D. Ramage, S. Hampson, B. A. y Arcas, Communication-efficient learning of deep networks from decentralized data, in Artificial Intelligence and Statistics, PMLR, (2017), 1273–1282. 10.48550/arXiv.1602.05629 |
| [20] | Y. Zhao, M. Li, L. Lai, N. Suda, D. Civin, V. Chandra, Federated learning with non-iid data, preprint, arXiv: 1806.00582. https://doi.org/10.48550/arXiv.1806.00582 |
| [21] | B. Luo, W. Xiao, S. Wang, J. Huang, L. Tassiulas, Tackling system and statistical heterogeneity for federated learning with adaptive client sampling, in IEEE INFOCOM 2022-IEEE Conference on Computer Communications, (2022), 1739–1748. https://doi.org/10.1109/INFOCOM48880.2022.9796935 |
| [22] |
H. Wu, P. Wang, Node selection toward faster convergence for federated learning on non-iid data, IEEE Trans. Network Sci. Eng., 9 (2022), 3099–3111. https://doi.org/10.1109/TNSE.2022.3146399 doi: 10.1109/TNSE.2022.3146399
|
| [23] |
A. Chen, Y. Fu, Z. Sha, G. Lu, An emd-based adaptive client selection algorithm for federated learning in heterogeneous data scenarios, Front. Plant Sci., 13 (2022), 908814. https://doi.org/10.3389/fpls.2022.908814 doi: 10.3389/fpls.2022.908814
|
| [24] |
Y. Lv, H. Ding, H. Wu, Y. Zhao, L. Zhang, FedRDS: federated learning on non-iid data via regularization and data sharing, Appl. Sci., 13 (2023), 12962. https://doi.org/10.3390/app132312962 doi: 10.3390/app132312962
|
| [25] |
J. Kang, Z. Xiong, D. Niyato, S. Xie, J. Zhang, Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory, IEEE Internet of Things J., 6 (2019), 10700–10714. https://doi.org/10.1109/JIOT.2019.2940820 doi: 10.1109/JIOT.2019.2940820
|
| [26] | N. H. Tran, W. Bao, A. Zomaya, M. N. Nguyen, C. S. Hong, Federated learning over wireless networks: optimization model design and analysis, in IEEE INFOCOM 2019-IEEE Conference on Computer Communications, (2019), 1387–1395. https://doi.org/10.1109/INFOCOM.2019.8737464 |
| [27] |
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, V. Smith, Federated optimization in heterogeneous networks, Proc. Mach. Learn. Sys., 2 (2022), 429–450. https://doi.org/10.48550/arXiv.1812.06127 doi: 10.48550/arXiv.1812.06127
|





Figures(6)
Xiaoyu Jiang, Ruichun Gu, Huan Zhan. Research on incentive mechanisms for anti-heterogeneous federated learning based on reputation and contribution[J]. Electronic Research Archive, 2024, 32(3): 1731-1748. doi: 10.3934/era.2024079







 DownLoad:
DownLoad: