Citation: AB Segarra, I Prieto, M Martínez-Cañamero, Manuel Ramírez-Sánchez. Is there a link between depression, neurochemical asymmetry and cardiovascular function?[J]. AIMS Neuroscience, 2020, 7(4): 360-372. doi: 10.3934/Neuroscience.2020022

| [1] |
Kaltenboeck A, Harmer C (2018) The neuroscience of depressive disorders: A brief review of the past and some considerations about the future. Brain Neurosci Adv 2: 239821281879926. doi: 10.1177/2398212818799269

|
| [2] |
Prieto I, Segarra AB, Martinez-Canamero M, et al. (2017) Bidirectional asymmetry in the neurovisceral communication for the cardiovascular control: New insights. Endocr Regul 51: 157-167. doi: 10.1515/enr-2017-0017
|
| [3] |
Segarra AB, Prieto-Gomez I, Banegas I, et al. (2019) Functional and neurometabolic asymmetry in SHR and WKY rats following vasoactive treatments. Sci Rep 9: 16098. doi: 10.1038/s41598-019-52658-9
|
| [4] |
Madison A, Kiecolt-Glaser JK (2019) Stress, depression, diet, and the gut microbiota: human-bacteria interactions at the core of psychoneuroimmunology and nutrition. Curr Opin Behav Sci 28: 105-110. doi: 10.1016/j.cobeha.2019.01.011
|
| [5] |
Harmer CJ, Duman RS, Cowen PJ (2017) How do antidepressants work? New perspectives for refining future treatment approaches. Lancet Psychiatry 4: 409-418. doi: 10.1016/S2215-0366(17)30015-9
|
| [6] |
Prieto I, Segarra AB, De Gasparo M, et al. (2016) Neuropeptidases, Stress and Memory—A Promising Perspective. AIMS Neurosci 3: 487-501. doi: 10.3934/Neuroscience.2016.4.487
|
| [7] |
Bogdan R, Pizzagalli DA (2006) Acute stress reduces reward responsiveness: implications for depression. Biol Psychiatry 60: 1147-1154. doi: 10.1016/j.biopsych.2006.03.037
|
| [8] |
Barber BA, Kohl KL, Kassam-Adams N, et al. (2014) Acute stress, depression, and anxiety symptoms among English and Spanish speaking children with recent trauma exposure. J Clin Psychol Med Settings 21: 66-71. doi: 10.1007/s10880-013-9382-z
|
| [9] | Broca MP (1861) Remarques sur le siége de la faculté du language articulé, suivies d'une observation d'aphémie (perte de la parole). Bull Soc Anat (París) VI: 330-357. |
| [10] |
Corballis MC (2014) Left brain, right brain: facts and fantasies. PLoS Biol 12: e1001767. doi: 10.1371/journal.pbio.1001767
|
| [11] | Hellige JB (1993) Hemispheric asymmetry: what's right and what's left London: Harvard University Press. |
| [12] |
Rogers LJ, Vallortigara G, Andrew RJ (2013) Divided Brains. The biology and behaviour of brain asymmetries Cambridge: Cambridge University Press. doi: 10.1017/CBO9780511793899
|
| [13] | Gazzaniga MS (2015) Tales from both sides of the brain. A life in neuroscience New York: Harper Collins. |
| [14] |
Zimmerberg B, Glick SD, Jerussi TP (1974) Neurochemical correlate of a spatial preference in rats. Science 185: 623-625. doi: 10.1126/science.185.4151.623
|
| [15] |
Oke A, Keller R, Mefford I, et al. (1978) Lateralization of norepinephrine in human thalamus. Science 200: 1411-1413. doi: 10.1126/science.663623
|
| [16] | Bernard C (1878) Etude sur la physiologie du coeur. La Sci Exp 316-366. |
| [17] |
Domínguez-Vías G, Aretxaga G, Prieto I, et al. (2020) Asymmetrical influence of a standard light/dark cycle and constant light conditions on the alanyl-aminopeptidase activity of the left and right retinas in adult male rats. Exp Eye Res 198: 108149. doi: 10.1016/j.exer.2020.108149
|
| [18] |
Segarra AB, Prieto I, Banegas I, et al. (2012) Asymmetrical effect of captopril on the angiotensinase activity in frontal cortex and plasma of the spontaneously hypertensive rats: expanding the model of neuroendocrine integration. Behav Brain Res 230: 423-427. doi: 10.1016/j.bbr.2012.02.039
|
| [19] |
Segarra AB, Prieto I, Banegas I, et al. (2013) The brain-heart connection: frontal cortex and left ventricle angiotensinase activities in control and captopril-treated hypertensive rats—a bilateral study. Int J Hypertens 2013: 156179. doi: 10.1155/2013/156179
|
| [20] |
Prieto I, Segarra AB, Villarejo AB, et al. (2019) Neuropeptidase activity in the frontal cortex of Wistar-Kyoto and spontaneously hypertensive rats treated with vasoactive drugs: a bilateral study. J Hypertens 37: 612-628. doi: 10.1097/HJH.0000000000001884
|
| [21] |
Henriques JB, Davidson RJ (1991) Left frontal hypoactivation in depression. J Abnorm Psychol 100: 535-545. doi: 10.1037/0021-843X.100.4.535
|
| [22] |
Ramírez M, Prieto I, Vives F, et al. (2004) Neuropeptides, neuropeptidases and brain asymmetry. Curr Protein Pept Sci 5: 497-506. doi: 10.2174/1389203043379350
|
| [23] |
Cohen BE, Edmondson D, Kronish IM (2015) State of the Art Review: Depression, Stress, Anxiety, and Cardiovascular Disease. Am J Hypertens 28: 1295-1302. doi: 10.1093/ajh/hpv047
|
| [24] | Liguori I, Russo G, Curcio F, et al. (2018) Depression and chronic heart failure in the elderly: an intriguing relationship. J Geriatr Cardiol 15: 451-459. |
| [25] |
Testa G, Cacciatore F, Galizia G, et al. (2011) Depressive symptoms predict mortality in elderly subjects with chronic heart failure. Eur J Clin Invest 41: 1310-1317. doi: 10.1111/j.1365-2362.2011.02544.x
|
| [26] | Agustini B, Mohebbi M, Woods RL, et al. (2020) The association of antihypertensive use and depressive symptoms in a large older population with hypertension living in Australia and the United States: a cross-sectional study. J Hum Hypertens 30. |
| [27] |
Eze-Nliam CM, Thombs BD, Lima BB, et al. (2010) The association of depression with adherence to antihypertensive medications: a systematic review. J Hypertens 28: 1785-1795. doi: 10.1097/HJH.0b013e32833b4a6f
|
| [28] |
Bautista LE, Vera-Cala LM, Colombo C, et al. (2012) Symptoms of depression and anxiety and adherence to antihypertensive medication. Am J Hypertens 25: 505-511. doi: 10.1038/ajh.2011.256
|
| [29] |
Braszko JJ, Karwowska-Polecka W, Halicka D, et al. (2003) Captopril and enalapril improve cognition and depressed mood in hypertensive patients. J Basic Clin Physiol Pharmacol 14: 323-343. doi: 10.1515/JBCPP.2003.14.4.323
|
| [30] |
Cacciatore F, Amarelli C, Maiello C, et al. (2020) Effect of Sacubitril-Valsartan in reducing depression in patients with advanced heart failure. J Affect Disord 272: 132-137. doi: 10.1016/j.jad.2020.03.158
|
| [31] |
Rotenberg VS (2008) Functional brain asymmetry as a determinative factor in the treatment of depression: theoretical implications. Prog Neuropsychopharmacol Biol Psychiatry 32: 1772-1777. doi: 10.1016/j.pnpbp.2008.08.011
|
| [32] |
Banegas I, Prieto I, Segarra AB, et al. (2011) Blood pressure increased dramatically in hypertensive rats after left hemisphere lesions with 6-hydroxydopamine. Neurosci Lett 500: 148-150. doi: 10.1016/j.neulet.2011.06.025
|
| [33] | Segarra AB, Banegas I, Prieto I, et al. (2016) Brain asymmetry and dopamine: beyond motor implications in Parkinson's disease and experimental hemiparkinsonism. Rev Neurol 63: 415-421. |
| [34] |
Banegas I, Prieto I, Segarra AB, et al. (2019) Angiotensin II, dopamine and nitric oxide. An asymmetrical neurovisceral interaction between brain and plasma to regulate blood pressure. AIMS Neurosci 6: 116-127. doi: 10.3934/Neuroscience.2019.3.116
|
| [35] |
Banegas I, Segarra AB, Prieto I, et al. (2019) Asymmetrical response of aminopeptidase A in the medial prefrontal cortex and striatum of 6-OHDA-unilaterally-lesioned Wistar Kyoto and spontaneously hypertensive rats. Pharmacol Biochem Behav 182: 12-21. doi: 10.1016/j.pbb.2019.05.007
|
| [36] |
Guo SX, Kendrick KM, Zhang J, et al. (2013) Brain-wide functional inter-hemispheric disconnection is a potential biomarker for schizophrenia and distinguishes it from depression. Neuroimage Clin 2: 818-826. doi: 10.1016/j.nicl.2013.06.008
|
| [37] |
Xu K, Jiang WY, Ren L, et al. (2013) Impaired interhemispheric connectivity in medication-naive patients with major depressive disorder. J Psychiatry Neurosci 38: 43-48. doi: 10.1503/jpn.110132
|
| [38] |
Ben-Shimol E, Gass N, Vollmayr B, et al. (2015) Reduced connectivity and inter-hemispheric symmetry of the sensory system in a rat model of vulnerability to developing depression. Neuroscience 310: 742-750. doi: 10.1016/j.neuroscience.2015.09.057
|
| [39] |
Bohlender J, Imboden H (2012) Angiotensinergic neurotransmission in the peripheral autonomic nervous system. Front Biosci (Landmark Ed) 17: 2419-2432. doi: 10.2741/4062
|
| [40] |
Foster PS, Harrison DW (2006) Magnitude of cerebral asymmetry at rest: covariation with baseline cardiovascular activity. Brain Cogn 61: 286-297. doi: 10.1016/j.bandc.2006.02.004
|
| [41] |
Swislocki AL, LaPier TL, Khuu DT, et al. (1999) Metabolic, hemodynamic, and cardiac effects of captopril in young, spontaneously hypertensive rats. Am J Hypertens 12: 581-589. doi: 10.1016/S0895-7061(99)00012-6
|
| [42] |
Thayer JF, Lane RD (2009) Claude Bernard and the heart-brain connection: further elaboration of a model of neurovisceral integration. Neurosci Biobehav Rev 33: 81-88. doi: 10.1016/j.neubiorev.2008.08.004
|
| [43] |
Holzer P, Farzi A (2014) Neuropeptides and the microbiota-gut-brain axis. Adv Exp Med Biol 817: 195-219. doi: 10.1007/978-1-4939-0897-4_9
|
| [44] |
Prieto I, Hidalgo M, Segarra AB, et al. (2018) Influence of a diet enriched with virgin olive oil or butter on mouse gut microbiota and its correlation to physiological and biochemical parameters related to metabolic syndrome. PLoS One 13: e0190368. doi: 10.1371/journal.pone.0190368
|
| [45] |
Hidalgo M, Prieto I, Abriouel H, et al. (2018) Changes in Gut Microbiota Linked to a Reduction in Systolic Blood Pressure in Spontaneously Hypertensive Rats Fed an Extra Virgin Olive Oil-Enriched Diet. Plant Foods Hum Nutr 73: 1-6. doi: 10.1007/s11130-017-0650-1
|
| [46] |
Fujiwara Y, Kubo M, Kohata Y, et al. (2011) Association between left-handedness and gastrointestinal symptoms. Digestion 84: 114-118. doi: 10.1159/000324680
|
| [47] |
Morris DL, Montgomery SM, Galloway ML, et al. (2001) Inflammatory bowel disease and laterality: is left handedness a risk? Gut 49: 199-202. doi: 10.1136/gut.49.2.199
|
| [48] |
Denny K (2009) Handedness and depression: evidence from a large population survey. Laterality 14: 246-255. doi: 10.1080/13576500802362869
|
| [49] |
Işcen S, Özenç S, Tavlasoglu U (2014) Association between left-handedness and cardiac autonomic function in healthy young men. Pacing Clin Electrophysiol 37: 884-888. doi: 10.1111/pace.12365
|
| [50] |
Vagena E, Ryu JK, Baeza-Raja B, et al. (2019) A high-fat diet promotes depression-like behavior in mice by suppressing hypothalamic PKA signaling. Transl Psychiatry 9: 141. doi: 10.1038/s41398-019-0470-1
|
| [51] |
Sarris J, Murphy J, Mischoulon D, et al. (2016) Adjunctive Nutraceuticals for Depression: A Systematic Review and Meta-Analyses. Am J Psychiatry 173: 575-587. doi: 10.1176/appi.ajp.2016.15091228
|
| [52] |
Segarra AB, Ramirez M, Banegas I, et al. (2008) Dietary fat influences testosterone, cholesterol, aminopeptidase A, and blood pressure in male rats. Horm Metab Res 40: 289-291. doi: 10.1055/s-2008-1046800
|
| [53] |
Vancassel S, Aïd S, Pifferi F, et al. (2005) Cerebral asymmetry and behavioral lateralization in rats chronically lacking n-3 polyunsaturated fatty acids. Biol Psychiatry 58: 805-811. doi: 10.1016/j.biopsych.2005.04.045
|
| [54] |
Tryon MS, Stanhope KL, Epel ES, et al. (2015) Excessive Sugar Consumption May Be a Difficult Habit to Break: A View From the Brain and Body. J Clin Endocrinol Metab 100: 2239-2247. doi: 10.1210/jc.2014-4353
|
| [55] |
Redondo-Useros N, Nova E, González-Zancada N, et al. (2020) Microbiota and Lifestyle: A Special Focus on Diet. Nutrients 12: E1776. doi: 10.3390/nu12061776
|
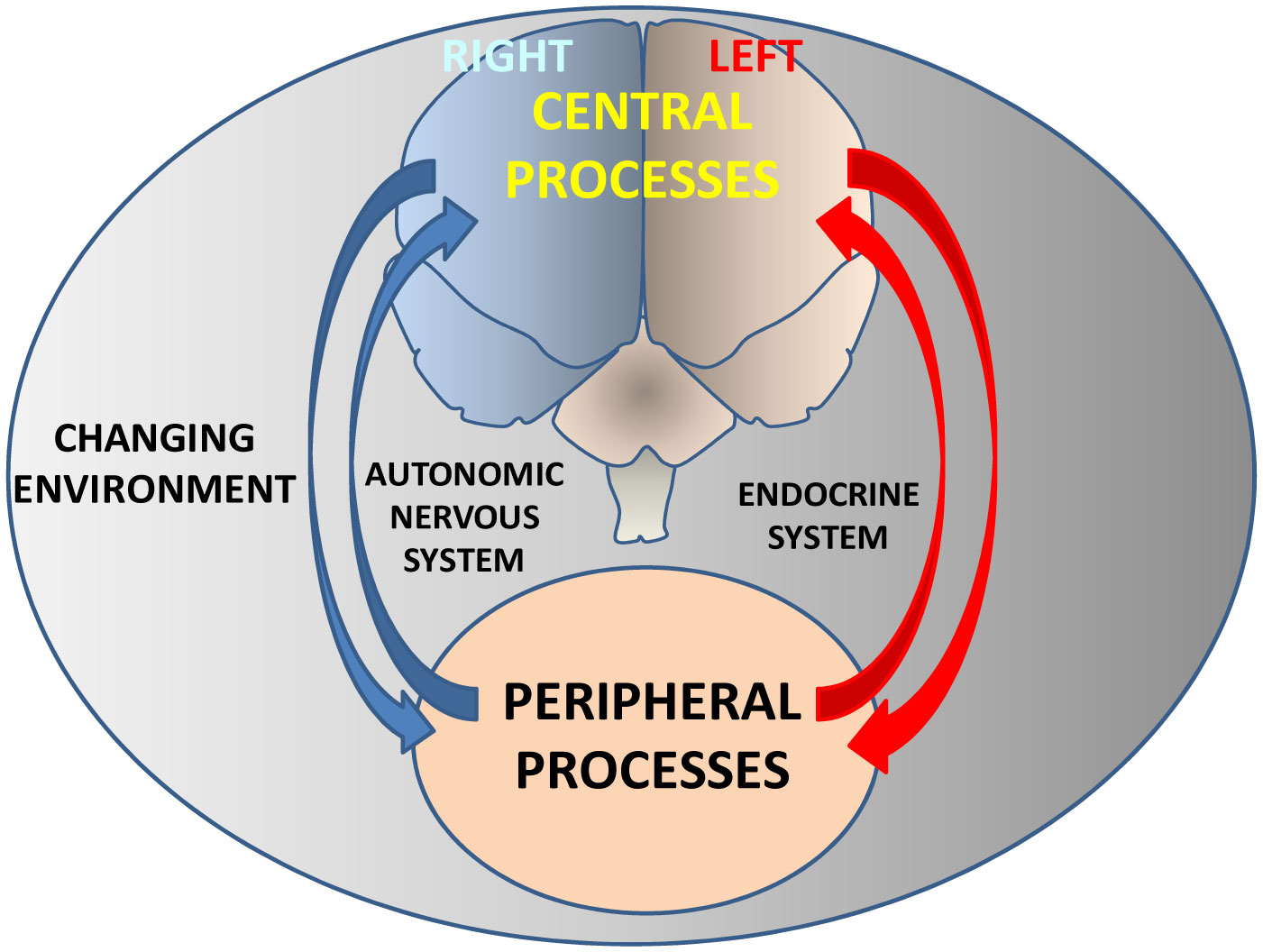
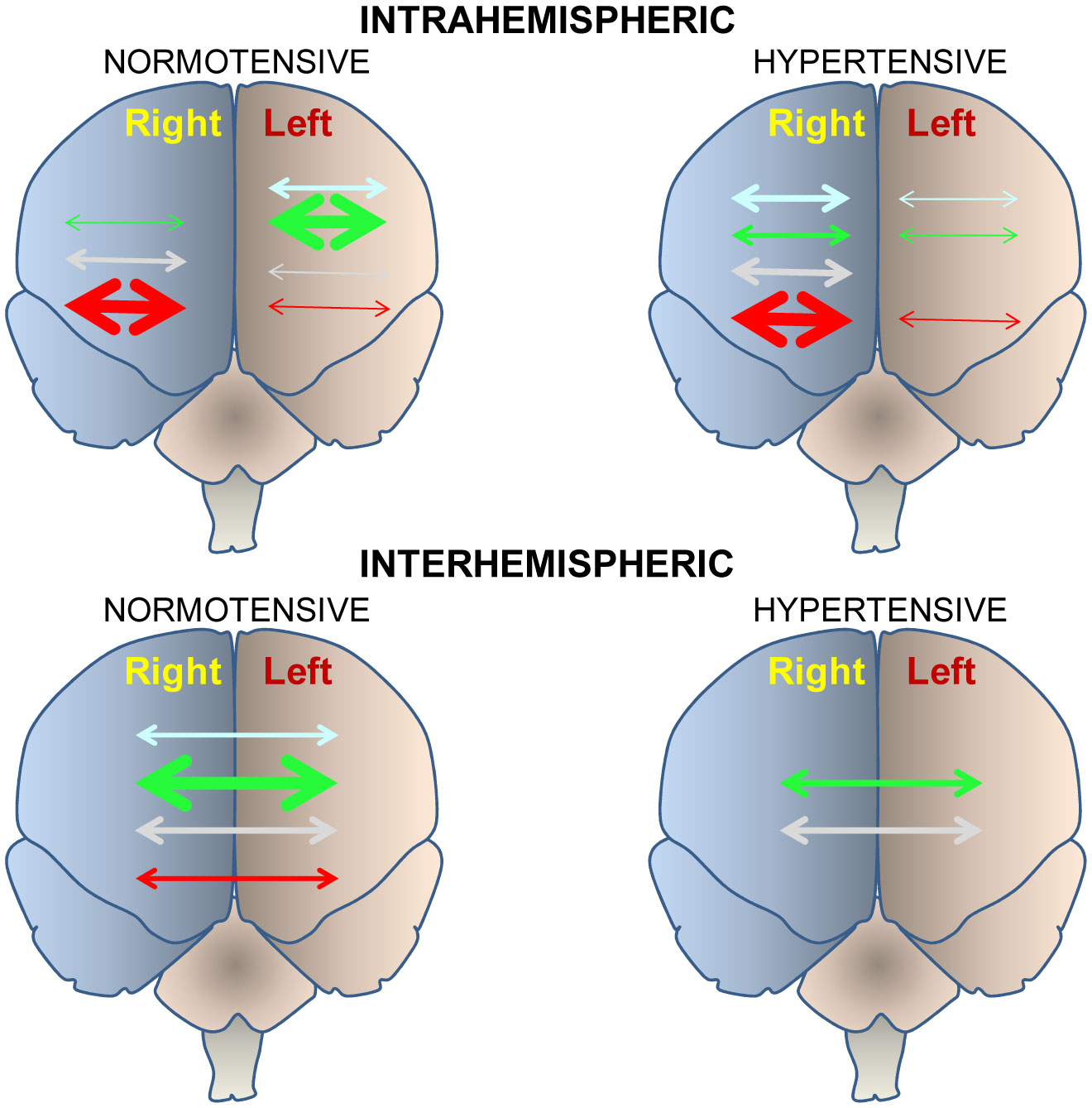
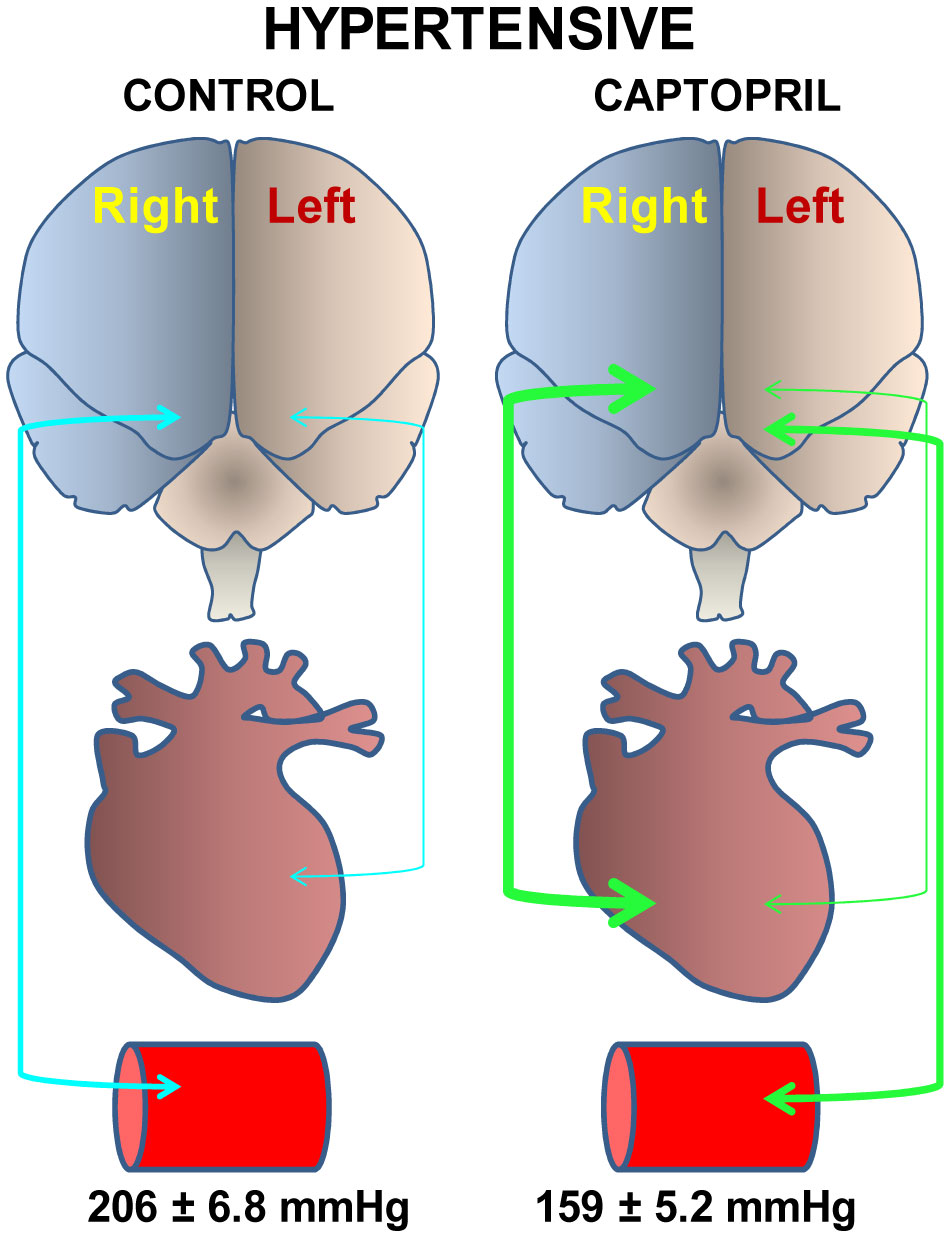
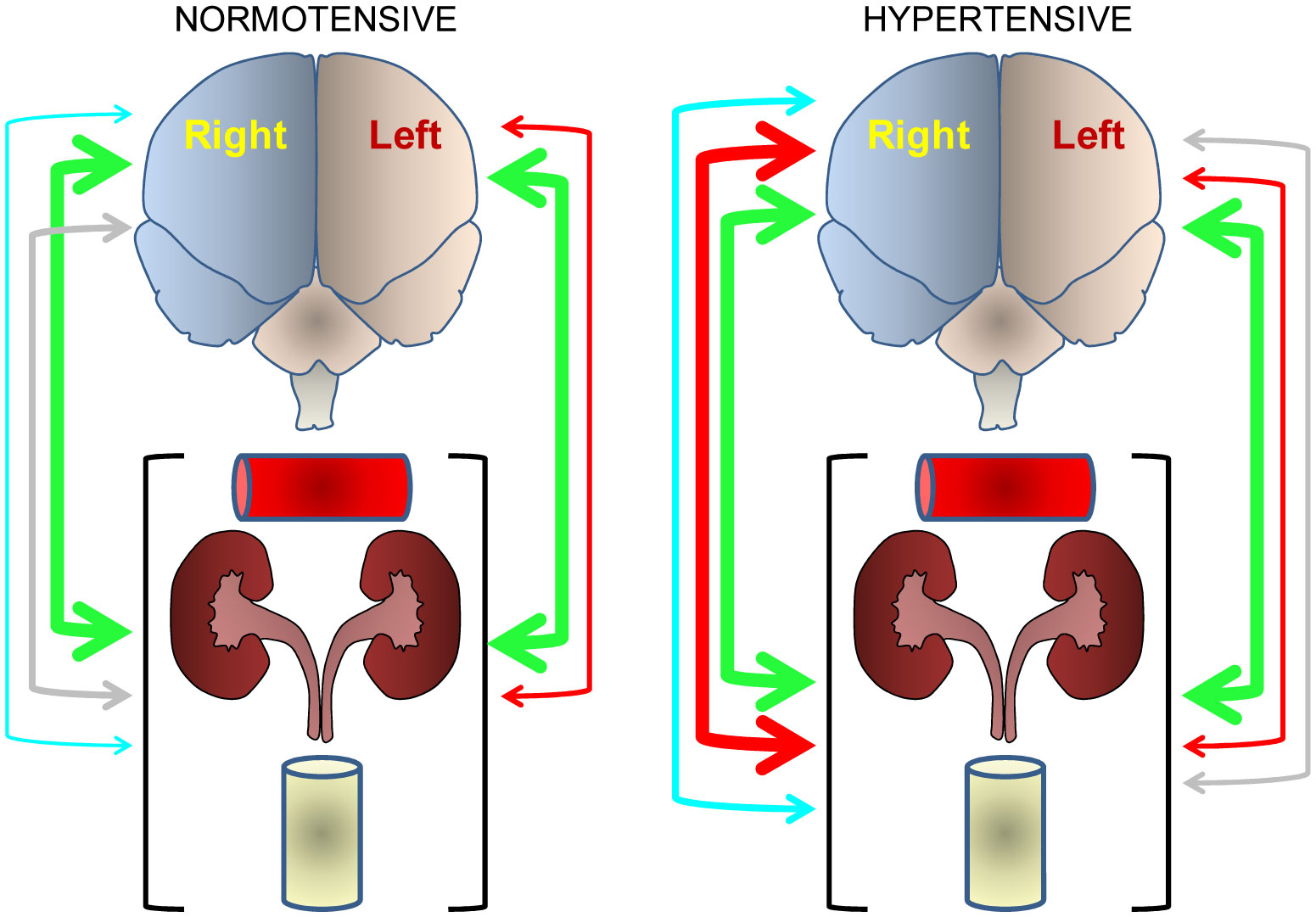
Figures(4) / Tables(1)

AB Segarra, I Prieto, M Martínez-Cañamero, Manuel Ramírez-Sánchez. Is there a link between depression, neurochemical asymmetry and cardiovascular function?[J]. AIMS Neuroscience, 2020, 7(4): 360-372. doi: 10.3934/Neuroscience.2020022







 DownLoad:
DownLoad: