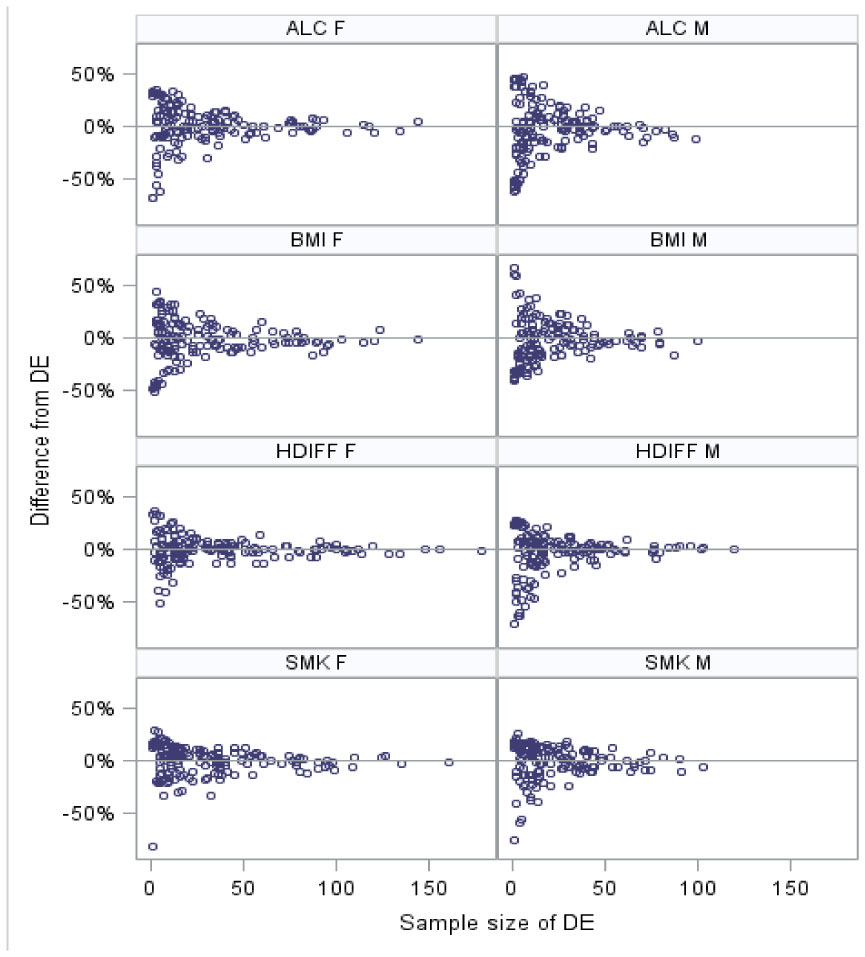
Regular health surveys can produce reliable estimates at higher geographic levels but not for small areas. Alternatives are to aggregate data over several years or use model-based methods. We created and evaluated model-based estimates for four health-related outcomes by gender, for 153 Local Government Areas using data from the New South Wales Population Health Survey. The evaluation examined evidence on bias and determined the covariates available and appropriate for each outcome variable. The evaluation considered the likely precision of the resulting estimates. The bias and precision of results for single years (2006–2008) for each outcome variable using six covariate specifications were compared with direct survey estimates based on a single year's data and those obtained by aggregating over seven years. A practical issue is how to choose covariates to include in the models as the best covariate specification varies between outcome variables. Model-based results had median root mean squared errors between 3.3% and 5.5% (max 5.2% and 11.3% respectively) and median relative root mean squared errors between 6.8% and 24.5% (max 11.7% and 41.5% respectively). The model-based estimates were unbiased compared with direct estimates based on one or seven years of data and when aggregated to a point where direct estimates were reliable. The bias and reliability assessment process provides a way for policymakers to have confidence in model-based estimates.
Citation: Diane Hindmarsh, David Steel. Creating local estimates from a population health survey: practical application of small area estimation methods[J]. AIMS Public Health, 2020, 7(2): 403-424. doi: 10.3934/publichealth.2020034
Regular health surveys can produce reliable estimates at higher geographic levels but not for small areas. Alternatives are to aggregate data over several years or use model-based methods. We created and evaluated model-based estimates for four health-related outcomes by gender, for 153 Local Government Areas using data from the New South Wales Population Health Survey. The evaluation examined evidence on bias and determined the covariates available and appropriate for each outcome variable. The evaluation considered the likely precision of the resulting estimates. The bias and precision of results for single years (2006–2008) for each outcome variable using six covariate specifications were compared with direct survey estimates based on a single year's data and those obtained by aggregating over seven years. A practical issue is how to choose covariates to include in the models as the best covariate specification varies between outcome variables. Model-based results had median root mean squared errors between 3.3% and 5.5% (max 5.2% and 11.3% respectively) and median relative root mean squared errors between 6.8% and 24.5% (max 11.7% and 41.5% respectively). The model-based estimates were unbiased compared with direct estimates based on one or seven years of data and when aggregated to a point where direct estimates were reliable. The bias and reliability assessment process provides a way for policymakers to have confidence in model-based estimates.

| [1] | (2000) National Research CouncilSmall-area estimates of school-age children in poverty: evaluation of current methodology. US Panel on Estimates of Poverty for Small Geographic Areas. National Academy Press. |
| [2] | Statistics Canada (2015) Regional Health Indicators. Available from: http://www.statcan.gc.ca/pub/82-221-x/2012002/quality-qualite/qua1-eng.htm#a11. |
| [3] | Queensland Health (2011) Self reported health status: 2009–2010: Local Government Area summary report. Available from: http://www.health.qld.gov.au/ph/Documents/epi/srhs0910lgasummary.pdf. |
| [4] | CDC (2007) 2007 SMART BRFSS MMSA Methodology. Available from: http://www.cdc.gov/brfss/smart/2007.htm. |
| [5] |
Rao J (2003) Small Area Estimation (Methods and Applications) Hoboken, NJ: John Wiley & Sons. doi: 10.1002/0471722189

|
| [6] | Centre for Epidemiology and Evidence (2017) Overview of Survey. Available from: http://www.health.nsw.gov.au/surveys/adult/Pages/overview-of-survey.aspx. |
| [7] | Barr M, Baker D, Gorringe M, et al. (2008) NSW Population Health Survey: Description of Methods. Available from: http://www.health.nsw.gov.au/resources/publichealth/surveys/health_survey_methods.pdf. |
| [8] | Centre for Epidemiology and Research (2012) Health Statistics New South Wales. Available from: http://www.healthstats.nsw.gov.au. |
| [9] | Public Health Division (2000) Report on the 1997 and 1998 NSW Health Surveys. Available from: http://www.health,nsw.gov.au/publichealth/surveys/hsa/9798/methods.htm. |
| [10] |
Barr ML, Ferguson RA, Hughes PJ, et al. (2014) Developing a weighting strategy to include mobile phone numbers into an ongoing population health survey using an overlapping dual-frame design with limited benchmark information. BMC Med Res Methodol 14: 102-111. doi: 10.1186/1471-2288-14-102
|
| [11] | Australian Bureau of Statistics (2006) Statistical Geography Volume 1-Australian Standard Geographical Classification. Available from: http://www.ausstats.abs.gov.au/ausstats/subscriber.nsf/0/3E15ACB95DA01A65CA2571AA0018369F/$File/12160_2006.pdf. |
| [12] | Australian Bureau of Statistics (2007) 2006 Census community profile series: Basic community profile. Available from: http://www.Censusdata.abs.gov.au/ABSNavigation/prenav/PopularAreas?collection=Census/period=2006. |
| [13] | Australian Bureau of Statistics (2010) National Regional Profile, 2005 to 2009 (CSV file). Available from: http://www.abs.gov.au/AUSSTATS/abs@.nsf/DetailsPage/1379.0.55.012005\%20to\%202009?OpenDocument. |
| [14] | Glover J, Tennant S (2010) Social Health Atlas of New South Wales (including ACT) Local Government Areas, 2010. Available from: http://www.publichealth.gov.au/interactive-mapping/a-social-health-atlas-of-australia_-2010.html. |
| [15] | Hindmarsh DM (2013) Small area estimation for health surveys. Doctor thesis. University of Wollongong: School of Mathematics and Applied Statistics. |
| [16] | Saei A, Chambers R (2003) Small Area Estimation Under Linear and Generalized Linear Mixed Models with Time and Area Effects. Southampton Statistical Sciences Research Institute Methodology Working Paper, M03 . |
| [17] | Chambers R, Skinner CJ (2003) Analysis of Survey Data. Wiley Series in Survey Methodology Chichester, UK: Wiley. |
| [18] |
Pereira L, Coehlo P (2010) Assessing different uncertainty measures of EBLUP: a resampling-based approach. J Stat Computation Simul 80: 713-725. doi: 10.1080/00949650902766860
|
| [19] |
Rodriguez G, Elo I (2003) Intra-class correlation in random-effects models for binary data. Stata J 3: 32-46. doi: 10.1177/1536867X0300300102
|
| [20] |
Nagelkerke NJ (1991) A note on a general definition of the coefficient of determination. Biometrika 78: 691-692. doi: 10.1093/biomet/78.3.691
|
| [21] |
Gelman A, Goodrich B, Gabry J, et al. (2019) R-Squared for Bayesian Regression Models. Am Stat 73: 307-309. doi: 10.1080/00031305.2018.1549100
|
| [22] | Scholes S, Pickering K, Rayat P (2007) Healthy lifestyle behaviours: model based estimates for Middle Layer Super Output Areas and Local Authorities in England, 2003–2005. User Guide. Information Centre and National Centre for Social Research, Colchester Available from: www.ic.nhs.uk/statistics-and-data-collections/population-and-geography/neighbourhood-statistics/neighbourhood-statistics:-model-based-estimates-of-healthy-lifestyles-behaviours-2003-05. |
| [23] | Brown G, Chambers R, Heady P, et al. (2001) Evaluation of small area estimation methods - an application to unemployment estimates from the UK LFS. Available from: https://www.researchgate.net/publication/237775200. |
| [24] |
Vlassoff C, Garcia Moreno C (2002) Placing gender at the centre of health programming: challenges and limitations. Soc Sci Med 54: 1713-1723. doi: 10.1016/S0277-9536(01)00339-2
|
| [25] | Schneider KL, Lapane K, Clark MA, et al. (2009) Using small-area estimation to describe county-level disparities in mammography. Prev Chronic Dis 6. |
| [26] | Singh BB, Shukla GK, Kundu D (2005) Spatio-temporal models in small area estimation. Surv Methodol 31: 183-195. |
| [27] |
Srebotnjak T, Mokdad AH, Murray CJ (2010) A novel framework for validating and applying standardised small area measurement strategies. Popul Health Metr 8: 26. doi: 10.1186/1478-7954-8-26
|
| [28] |
Lawson A, Browne W, VidalRodeiro C (2003) Disease Mapping with WinBUGS and MLwiN Chichester, England: John Wiley and Sons Ltd. doi: 10.1002/0470856068
|
| [29] | ABS (2006) A Guide to Small Area Estimation-Version 1.1. Available from: http://www.nss.gov.au/nss/home.nsf/pages/Small+Areas+Estimates. |
| [30] |
Zhang X, Holt JB, Lu H, et al. (2014) Multilevel regression and poststratification for small-area estimation of population health outcomes: a case study of chronic obstructive pulmonary disease prevalence using the behavioral risk factor surveillance system. Am J Epidemiol 179: 1025-1033. doi: 10.1093/aje/kwu018
|
| [31] | Loux T (2020) Multilevel regression with poststratification for local estimation: example and lessons learned. Presented at Conference on Statistical Practice Sacramento, USA: Available from: https://ww2.amstat.org/meetings/csp/2020/onlineprogram/AbstractDetails.cfm?AbstractID=303940. |
| [32] | Gomez-Rubio V, Best N, Richardson S, et al. (2010) Bayesian Statistics for Small Area Estimation. Technical report (unpublished), Imperial College London Available from: http://eprints.ncrm.ac.uk/1686/1/BayesianSAE.pdf. |
| [33] | Mukhopadhyay PK, McDowell A (2011) Small Area Estimation for survey data analysis using SAS software. Available from: http://support.sas.com/resources/papers/proceedings11/336-2011.pdf. |
| [34] |
Zhao Y, Staudenmayer J, Coull BA, et al. (2006) General design Bayesian generalised linear mixed models. Stat Sci 21: 35-51. doi: 10.1214/088342306000000015
|
 publichealth-07-02-034-s001.pdf publichealth-07-02-034-s001.pdf |
 |
| publichealth-07-02-034-s002.xlsx |
|
Figures(1) / Tables(11)

Diane Hindmarsh, David Steel. Creating local estimates from a population health survey: practical application of small area estimation methods[J]. AIMS Public Health, 2020, 7(2): 403-424. doi: 10.3934/publichealth.2020034







 DownLoad:
DownLoad: