Citation: Miin-Shen Yang, Wajid Ali. Fuzzy Gaussian Lasso clustering with application to cancer data[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 250-265. doi: 10.3934/mbe.2020014

| [1] | L. Kaufman, P.J. Rousseeuw, Finding Groups in Data: An Introduction to Cluster Analysis, Wiley-Interscience, New York, 2009. |
| [2] | J. C. Bezdek, Pattern Recognition with fuzzy objective function algorithms, Plenum Press, New York, 1981. |
| [3] | D. Jiang, C. Tang and A. Zhang, Cluster analysis for gene expression data: A survey, IEEE Trans. Knowl. Data Eng.,16 (2004), 1370-1386. |
| [4] | J. M. T. Wu, C. W. Lin, P. Fournier-Viger, et al., The density-based clustering method for privacy-preserving data mining, Math. Biosci. Eng., 16 (2019), 1718-1728. |
| [5] | M. S. Yang, C. Y. Lai and C. Y. Lin, A robust EM clustering algorithm for Gaussian mixture models, Pattern Recognit., 45 (2012), 3950-3961. |
| [6] | A. K. Jain, Data clustering: 50 years beyond k-means, Pattern Recognition Lett., 31 (2010), 651-666. |
| [7] | A. Baraldi and P. Blonda, A survey of fuzzy clustering algorithms for pattern recognition-part I and part II, IEEE Trans. Syst. Man Cybern. B, 29 (1999), 778-785. |
| [8] | M. S. Yang and Y. Nataliani, Robust-learning fuzzy c-means clustering algorithm with unknown number of clusters, Pattern Recogni t., 71 (2017), 45-59. |
| [9] | R. Krishnapuram and J. M. Keller, A possibilistic approach to clustering, IEEE Trans. Fuzzy Syst., 1 (1993), 98-110. |
| [10] | M. S. Yang, S. J. Chang-Chien and Y. Nataliani, A fully-unsupervised possibilistic c-means clustering method, IEEE Access, 6 (2018), 78308-78320. |
| [11] | A. P. Dempster, N. M. Laird and D. B. Rubin, Maximum likelihood from incomplete data via the EM algorithm (with discussion), J. R. Stat. Soc. Ser. B, 39 (1977), 1-38. |
| [12] | W. Pan and X. Shen, Penalized model-based clustering with application to variable selection, J. Mach. Learn. Res., 8 (2007), 1145-1164. |
| [13] | R. Tibshirani, Regression shrinkage and selection via the Lasso, J. R. Stat. Soc. Ser. B, 58 (1996), 267-288. |
| [14] | J. D. Banfield and A. E. Raftery, Model-based Gaussian and non-Gaussian Clustering, Biometrics, 49 (1993), 803-821. |
| [15] | A. J. Scott and M. J. Symons, Clustering methods based on likelihood ratio criteria, Biometrics, 27 (1971), 387-397. |
| [16] | M. J. Symons, Clustering criteria and multivariate normal mixtures, Biometrics,37 (1981), 35-43. |
| [17] | R. Wehrens, L. M. C. Buydens, C. Fraley, et al., Model-based clustering for image segmentation and large datasets via sampling, J. Classif., 21 (2004), 231-253. |
| [18] | W. C. Young, A. E. Raftery and K. Y. Yeung, Model-based clustering with data correction for removing artifacts in geneexpression data, Ann. Appl. Stat., 11 (2017), 1998-2026. |
| [19] | T. Akilan, Q. M. J. Wu and Y. Yang, Fusion-based foreground enhancement for background subtraction using multivariate multi-model Gaussian distribution, Inf. Sci., 430-431 (2018), 414-431. |
| [20] | M. S. Yang, S. J. Chang-Chien and Y. Nataliani, Unsupervised fuzzy model-based Gaussian clustering,Inf. Sci., 481 (2019), 1-23. |
| [21] | L. A. Zadeh, Fuzzy sets, Inf. Control, 8 (1965), 338-353. |
| [22] | M. S. Yang and Y. Nataliani, A feature-reduction fuzzy clustering algorithm based on feature-weighted entropy,IEEE Trans. Fuzzy Syst., 26(2018), 817-835. |
| [23] | K. Voevodski, M. F. Balcan, H. Röglin, et al., Active clustering of biological sequences, J. Mach. Learn. Res., 13 (2012), 203-225. |
| [24] | D. Gaweł and K. Fujarewicz, On the sensitivity of feature ranked lists for large-scale biological data, Math. Biosci. Eng., 10 (2013), 667-690. |
| [25] | J. Xiong, Essential Bioinformatics, Cambridge University Press, New York, 2006. |
| [26] | R. Jiang, X. Zhang, M. Q. Zhang, Basics of Bioinformatics, Springer-Verlag Berlin An, 2013. |
| [27] | E. H. Ruspini, A new approach to clustering,Inf. Control, 15 (1969), 22-32. |
| [28] | D. M. Witten and R. Tibshirani, A framework for feature selection in clustering, J. Am. Stat. Assoc.,105 (2010), 713-726. |
| [29] | E. A. Castro and X. Pu, A simple approach to sparse clustering, Comput. Stat. Data Anal.,105 (2017), 217-228. |
| [30] | X. Qiu, Y. Qiu, G. Feng, et al., A sparse fuzzy c-means algorithm base on sparse clustering framework, Neurocomputing,157 (2015), 290-295. |
| [31] | X. Chang, Q. Wang, Y. Liu, et al., Sparse regularization in fuzzy c-means for high-dimensional data clustering,IEEE Trans. Cybern., 47 (2017), 2616-2627. |
| [32] | T. Hastie, R. Tibshirani and M. Wainwright, Statistical Learning with Sparsity: The lasso and Generalization, Chapman and Hall/CRC press, New York, (2015). |
| [33] | C. L. Blake and C. J. Merz, UCI repository of machine learning database, a huge collection of artificial and real-world data sets, (1988). |
| [34] | N. K. Phan, Biological therapy: A new age of cancer treatment, Biomed. Res. Ther., 1 (2014), 32-34. |
| [35] | Global Health Observatory (GHO) data, World Health Organization, Geneva, 2018. Available from: https://www.who.int/gho/en/. |
| [36] | F. Bray, J. Ferlay, I. Soerjomataram, et al., A. Jemal, Global cancer statistics 2018: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries, CA A Cancer J. Clin., 68 (2018), 394-424. |
| [37] | D. N. K. Boulos and R. R. Ghali, Awareness of breast cancer among female students at Ain Shams University, Egypt, Glob. J. Health Sci., 6 (2014), 154-161. |
| [38] | K. McPherson, C. M. Steel and J. M. Dixon, Breast cancer-epidemiology, risk factors, and genetics, BMJ, 321 (2000), 624-628. |
| [39] | R. R. Janghel, A. Shukla, R. Tiwari, et al., Intelligent decision support system for breast cancer, International Conference in Swarm Intelligence, Beijing, China, 2010, 351-358. Available from: https://link_springer.gg363.site/chapter/10.1007/978-3-642-13498-2_46#citeas. |
| [40] | W. N. Street, W. H. Wolberg and O. L. Mangasarian, Nuclear feature extraction for breast tumor diagnosis, Biomedical image processing and biomedical visualization, 1905 (1993), 861-870. Available from: https://doi.org/10.1117/12.148698. |
| [41] | A. R. Marley and H. Nan, Epidemiology of colorectal cancer, Int. J. Mol. Epidemiol. Genet., 7 (2016), 105-114. |
| [42] | M. Arnold, M. S. Sierra, M. Laversanne, et al., Global patterns and trends in colorectal cancer incidence and mortality, Gut, 66 (2017), 683-691. |
| [43] | Cancer Stat Facts: Leukemia, National Cancer Institute, Surveillance Epidemiology and End Results Program, 2006-2010. Available from: http://seer.cancer.gov/statfacts/html/leuks.html. |
| [44] | A. S. Davis, A. J. Viera and M. D. Mead, Leukemia: An overview for primary care, Am. Fam. Physician, 89 (2014), 731-738. |
| [45] | T. R. Golub, D. K. Slonim, P. Tamayo, et al., Molecular classification of cancer: Class discovery and class prediction by gene expression monitoring, Science,286 (1999), 531-537. |
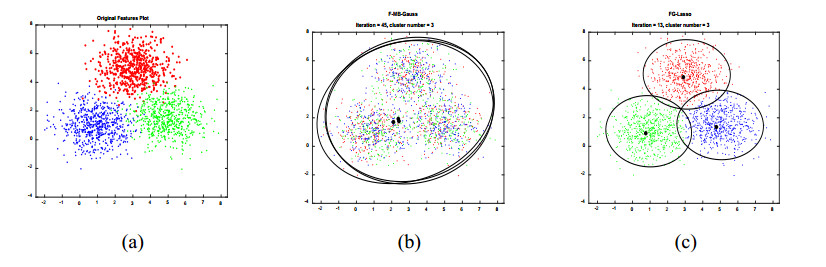
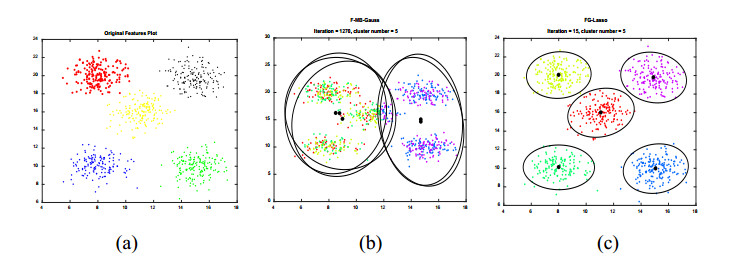
Figures(2) / Tables(7)

Miin-Shen Yang, Wajid Ali. Fuzzy Gaussian Lasso clustering with application to cancer data[J]. Mathematical Biosciences and Engineering, 2020, 17(1): 250-265. doi: 10.3934/mbe.2020014







 DownLoad:
DownLoad: