Citation: Bo Wang, Yabin Li, Xue Sui, Ming Li, Yanqing Guo. Joint statistics matching for camera model identification of recompressed images[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 5041-5061. doi: 10.3934/mbe.2019254

| [1] | M. C. Stamm, M. Wu and K. J. R. Liu, Information forensics: An overview of the first decade, IEEE Access, 1 (2013), 167–200. |
| [2] | A. Piva, An overview on image forensics, Isrn Signal Process., 2013. |
| [3] | M. Kirchner and T. Gloe, Forensic camera model identification, in Handbook of Digital Forensics of Multimedia Data and Devices, Chichester, U.K.: Wiley, 2015, 329–374. |
| [4] | J. Lukáš, J. Fridrich and M. Goljan, Determining digital image origin using sensor imperfections, in Proc. SPIE, San Jose, CA, USA, 2005, 249–260. |
| [5] | M. Chen, J. J. Fridrich and M. Goljan, Digital imaging sensor identification (further study)., in Proc. SPIE, San Jose, CA, USA, 2007, 65050P–65050P13. |
| [6] | C. T. Li, Source camera identification using enhanced sensor pattern noise, IEEE Trans. Inf. Foren. Secur., 5 (2010), 280–287. |
| [7] | X. Kang, Y. Li, Z. Qu, et al., Enhanced source camera identification performance with a camera reference phase sensor, IEEE Trans. Inf. Foren. Secur., 7 (2012), 393–402. |
| [8] | A. Lawgaly, F. Khelifi and A. Bouridane, Weighted averaging-based sensor pattern noise esti-mation for source camera identification, in Proc. IEEE Int. Conf. Image Process., Paris, France, 2014, 5357–5361. |
| [9] | A. Lawgaly and F. Khelifi, Sensor pattern noise estimation based on improved locally adaptive dct filtering and weighted averaging for source camera identification and verification, IEEE Trans. Inf. Foren. Secur., 12 (2017), 392–404. |
| [10] | Y. Hu, C. T. Li and Z. Lai, Fast source camera identification using matching signs between query and reference fingerprints, Mult. Tool. Appl., 74 (2015), 7405–7428. |
| [11] | S. Bayram, H. T. Sencar and N. Memon, Sensor fingerprint identification through composite fingerprints and group testing, IEEE Trans. Inf. Foren. Secur., 10 (2015), 597–612. |
| [12] | D. Valsesia, G. Coluccia, T. Bianchi, et al., Compressed fingerprint matching and camera identi-fication via random projections, IEEE Trans. Inf. Foren. Secur., 10 (2015), 1472–1485. |
| [13] | R. Li, C. T. Li and Y. Guan, Inference of a compact representation of sensor fingerprint for source camera identification, Patt. Recogn., 74 (2018), 556 – 567. |
| [14] | Y. Hu, C. T. Li, C. Zhou, et al., Source camera identification issues: forensic features selection and robustness, Int. J. Digit. Crime Foren., 3 (2011), 1–15. |
| [15] | M. Kharrazi, H. T. Sencar and N. Memon, Blind source camera identification, in Proc. IEEE Int. Conf. Image Process., vol. 1, Singapore, 2004, 709–712. |
| [16] | K. San Choi, E. Y. Lam and K. K. Wong, Source camera identification by jpeg compression statistics for image forensics, in Proc. IEEE Region 10 Conf., Hong Kong, China, 2006, 1–4. |
| [17] | B. Wang, Y. Guo, X. Kong, et al., Source camera identification forensics based on wavelet features, in Proc. IEEE Fifth Int. Conf. Intelligent Inf. Hiding and Multimedia Signal Process., Kyoto, Japan, 2009, 702–705. |
| [18] | S. Bayram, H. Sencar, N. Memon, et al., Source camera identification based on cfa interpolation, in Proc. IEEE Int. Conf. Image Process., vol. 3, Genova, Italy, 2005, 69–72. |
| [19] | J. S. Ho, O. C. Au, J. Zhou, et al., Inter-channel demosaicking traces for digital image forensics, in Proc. IEEE Int. Conf. Multimedia Expo, Suntec, Singapore, 2010, 1475–1480. |
| [20] | Y. Hu, C. T. Li, X. Lin, et al., An improved algorithm for camera model identification using inter-channel demosaicking traces, in 8th Int. Conf. Intelligent Inform. Hiding and Multimedia Signal Process., Piraeus, Greece, 2012, 325–330. |
| [21] | G. Xu and Y. Q. Shi, Camera model identification using local binary patterns, in Proc. IEEE Int. Conf. Multimedia Expo, Melbourne, VIC, Australia, 2012, 392–397. |
| [22] | B. Xu, X. Wang, X. Zhou, et al., Source camera identification from image texture features, Neurocomputing, 207 (2016), 131–140. |
| [23] | C. Chen and M. C. Stamm, Camera model identification framework using an ensemble of de-mosaicing features, in Proc. IEEE International Workshop on Information Forensics and Security (WIFS), 2015, 1–6. |
| [24] | A. Tuama, F. Comby and M. Chaumont, Camera model identification based machine learning approach with high order statistics features, in Proc. 24th European Signal Processing Conference (EUSIPCO), 2016, 1183–1187. |
| [25] | A. Roy, R. S. Chakraborty, U. Sameer, et al., Camera source identification using discrete cosine transform residue features and ensemble classifier, in Proc. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2017. |
| [26] | L. Zeng, X. Kong, M. Li, et al., Jpeg quantization table mismatched steganalysis via robust dis-criminative feature transformation., in Proc. SPIE Media Watermarking, Security, and Forensics, San Francisco, CA, USA, 2015, 94090U–94090U9. |
| [27] | S. J. Pan, I. W. Tsang, J. T. Kwok, et al., Domain adaptation via transfer component analysis, IEEE Trans. Neural Netw., 22 (2011), 199–210. |
| [28] | M. Long, J. Wang, G. Ding, et al., Transfer feature learning with joint distribution adaptation, in Proc. IEEE Int. Conf. Comput. Vision, San Francisco, CA, USA, 2013, 2200–2207. |
| [29] | X. Li, X. Kong, B. Wang, et al., Generalized transfer component analysis for mismatched jpeg steganalysis, in Proc. IEEE Int. Conf. Image Process., Melbourne, VIC, Australia, 2013, 4432–4436. |
| [30] | L. Luo, X. Wang, S. Hu, et al., Close yet distinctive domain adaptation, arXiv:1704.04235. |
| [31] | G. Zhang, B. Wang and Y. Li, Cross-class and inter-class alignment based camera source identi-fication for re-compression images, in Proc. IEEE Int. Conf. Image Graphics, Shanghai, China, 2017. |
| [32] | A. Gretton, K. M. Borgwardt, M. Rasch, et al., A kernel method for the two-sample-problem, in Proc. Advances Neural Inf. Process. Syst., Vancouver, BC, Canada, 2007, 513–520. |
| [33] | B. Quanz, J. Huan and M. Mishra, Knowledge transfer with low-quality data: A feature extraction issue, IEEE Trans. Knowl. Data Eng., 24 (2012), 1789–1802. |
| [34] | E. Zhong, W. Fan, J. Peng, et al., Cross domain distribution adaptation via kernel mapping, in Proc. 15th ACM SIGKDD Int. Conf. on Knowl. Discovery Data Mining, Paris, France, 2009, 1027–1036. |
| [35] | T. Gloe and R. Böhme, The dresden image database for benchmarking digital image forensics, J. Digit. Forensic Pract., 3 (2010), 150–159. |

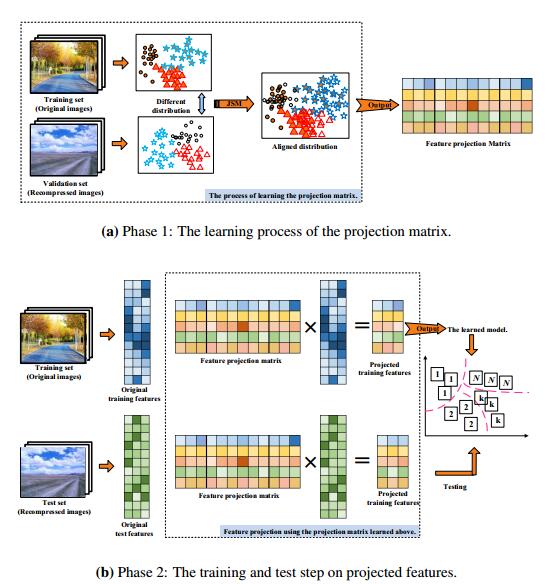

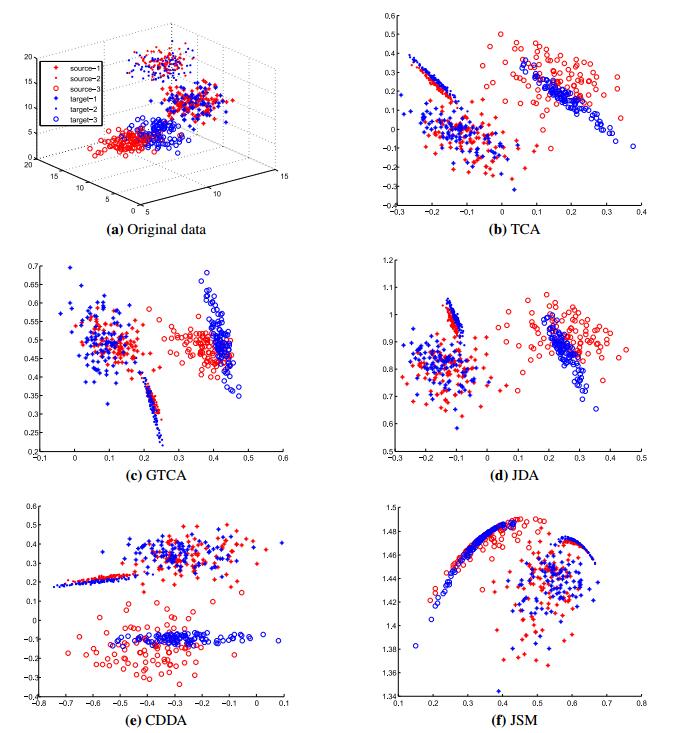
Figures(4) / Tables(5)

Bo Wang, Yabin Li, Xue Sui, Ming Li, Yanqing Guo. Joint statistics matching for camera model identification of recompressed images[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 5041-5061. doi: 10.3934/mbe.2019254







 DownLoad:
DownLoad: