Citation: Dominik Flore, Konrad Wegener. Influence of fibre volume fraction and temperature on fatigue life of glass fibre reinforced plastics[J]. AIMS Materials Science, 2016, 3(3): 770-795. doi: 10.3934/matersci.2016.3.770

| [1] | Lässig R, Eisenhut M, Mathias A, et al. (2012) Serienproduktion von hochfesten Faserverbundbauteilen: VDMA Verlag. |
| [2] | Schürmann H (2007) Konstruieren mit Faser-Kunststoff-Verbunden. Berlin: Springer. 672 S. p. |
| [3] | Vassilopoulos AP, Keller T (2011) Fatigue of fiber-reinforced composites. London: Springer. 238 S. p. |
| [4] | Fertig III RS, Kenik DJ (2011) Predicting Composite Fatigue Life Using Constituent-Level Physics. AIAA/ASME/ASCE/AHS/ASC Structures, Structural Dynamics and Materials Conference. Denver, Colorado. |
| [5] | Krüger H (2012) Ein physikalisch basiertes Ermüdungsschädigungsmodell zur Degradationsberechnung von Faser-Kunststoff-Verbunden [Ph.D Thesis]: Leibniz-Universität Hannover. |
| [6] | Talreja R, Singh CV (2012) Damage and Failure of Composite Materials. Cambridge: Cambridge University Press, 1-304 p. |
| [7] | Salkind MJ (2011) Fatigue of Composites. Composite Materials: Testing and Design (Second Conference). Philadelphia. |
| [8] | Kensche CW (1996) Fatigue of materials and components for wind turbine rotor blades. Brussels: German Aerospace Research Establishment. |
| [9] | Harris B (2003) Fatigue in composites science and technology of the fatigue response of fibre-reinforced plastics. Boca Raton: Elsevier Science Ltd 742 S. p. |
| [10] |
Pandita SD, Huysmans G, Wevers M, et al. (2001) Tensile fatigue behaviour of glass plain-weave fabric composites in on- and off-axis directions. Compos Part A-Appl S 32: 1533-1539. doi: 10.1016/S1359-835X(01)00053-7

|
| [11] |
Kawai M, Yajima S, Hachinohe A, et al. (2001) High-temperature off-axis fatigue behaviour of unidirectional carbon-fibre-reinforced composites with different resin matrices. Compos Sci Technol 61: 1285-1302. doi: 10.1016/S0266-3538(01)00027-6
|
| [12] |
Quaresimin M, Susmel L, Talreja R (2010) Fatigue behaviour and life assessment of composite laminates under multiaxial loadings. Int J Fatigue 32: 2-16. doi: 10.1016/j.ijfatigue.2009.02.012
|
| [13] |
Kawai M (2004) A phenomenological model for off-axis fatigue behavior of unidirectional polymer matrix composites under different stress ratios. Compos Part A-Appl S 35: 955-963. doi: 10.1016/j.compositesa.2004.01.004
|
| [14] |
Kawai M, Kato K (2006) Effects of R-ratio on the off-axis fatigue behavior of unidirectional hybrid GFRP/Al laminates at room temperature. Int J Fatigue 28: 1226-1238. doi: 10.1016/j.ijfatigue.2006.02.020
|
| [15] |
Vassilopoulos AP, Manshadi BD, Keller T (2010) Influence of the constant life diagram formulation on the fatigue life prediction of composite materials. Int J Fatigue 32: 659-669. doi: 10.1016/j.ijfatigue.2009.09.008
|
| [16] |
Flore D, Wegener K (2016) Modelling the mean stress effect on fatigue life of fibre reinforced plastics. Int J Fatigue 82: 689-699. doi: 10.1016/j.ijfatigue.2015.09.027
|
| [17] |
Van Paepegem W, Degrieck J (2001) Fatigue damage modeling of fibre-reinforced composite materials: review. Appl Mech Rev 54: 279-300. doi: 10.1115/1.1381395
|
| [18] | Kawai M, Teranuma T (2012) A multiaxial fatigue failure criterion based on the principal constant life diagrams for unidirectional carbon/epoxy laminates. Compos Part A 43: 1252-1266. |
| [19] | Papanicolaou GC, Zaoutsos SP (2011) Viscoelastic constitutive modeling of creep and stress relaxation in polymers and polymer matrix composites. In: Guedes RM, editor. Creep and fatigue in polymer matrix composites. Cambridge: Woodhead Publishing Limited. pp. 572. |
| [20] | Dillard DA (1990) Viscoelastic Behavior of Laminated Composite Materials. In: Reifsnider KL, editor. Fatigue of Composite Materials: Elsevier Science Publishers B.V.,. |
| [21] |
Song J, Wen WD, Cui HT, et al. (2015) Effects of temperature and fiber volume fraction on mechanical properties of T300/QY8911-IV composites. J Reinf Plast Comp 34: 157-172. doi: 10.1177/0731684414565939
|
| [22] | Vasiliev VV, Morozov EV (2013) Advanced mechanics of composite materials and structural elements. Amsterdam: Elsevier. 818 S. p. |
| [23] | Rejab MRM, Theng CW, Rahman MM, et al. An Investigation into the Effects of Fibre Volume Fraction on GFRP Plate; 2008. |
| [24] |
Karahan M (2012) The effect of fibre volume fraction on damage initiation and propagation of woven carbon-epoxy multi-layer composites. Text Res J 82: 45-61. doi: 10.1177/0040517511416282
|
| [25] |
He HW, Gao F (2015) Effect of Fiber Volume Fraction on the Flexural Properties of Unidirectional Carbon Fiber/Epoxy Composites. Int J Polym Anal Ch 20: 180-189. doi: 10.1080/1023666X.2015.989076
|
| [26] |
Allah MHA, Abdin EM, Selmy AI, et al. (1996) Effect of fibre volume fraction on the fatigue behaviour of grp pultruded rod composites. Compos Sci Technol 56: 23-29. doi: 10.1016/0266-3538(95)00125-5
|
| [27] |
Mini KM, Lakshmanan M, Mathew L, et al. (2012) Effect of fibre volume fraction on fatigue behaviour of glass fibre reinforced composite. Fatigue Fract Eng M 35: 1160-1166. doi: 10.1111/j.1460-2695.2012.01709.x
|
| [28] | Samborsky DD, Mandell JF, Cairns DS (2002) Sandia Contractors report-Fatigue of composite materials and substructures for wind turbine blades. Montana State University. |
| [29] |
Barbero EJ, Trovillion J, Mayugo JA, et al. (2006) Finite element modeling of plain weave fabrics from photomicrograph measurements. Compos Struct 73: 41-52. doi: 10.1016/j.compstruct.2005.01.030
|
| [30] |
Kuhn JL, Charalambides PG (1999) Modeling of plain weave fabric composite geometry. J Compos Mater 33: 188-220. doi: 10.1177/002199839903300301
|
| [31] |
Sun CT, Vaidya RS (1996) Prediction of composite properties, from a representative volume element. Compos Sci Technol 56: 171-179. doi: 10.1016/0266-3538(95)00141-7
|
| [32] | Talreja R, Singh CV (2012) Damage and Failure of Composite Materials. Cambridge Cambridge University Press 1-304 p. |
| [33] |
Kennedy CR, Bradaigh CMO, Leen SB (2013) A multiaxial fatigue damage model for fibre reinforced polymer composites. Compos Struct 106: 201-210. doi: 10.1016/j.compstruct.2013.05.024
|
| [34] | Stellbrink K (1996) Micromechanics of Composites: Composite Properties of Fibre and Matrix Constituents. Cincinnati: Hanser. |
| [35] | Pristavok J (2006) Mikromechanische Untersuchung an Epoxidharz Glasfaser Verbunden unter zyklischer Beanspruchung [Ph.D. Thesis]: Technische Universität Dresden. |
| [36] |
Soden PD, Hinton MJ, Kaddour AS (1998) Lamina properties, lay-up configurations and loading conditions for a range of fibre-reinforced composite laminates. Compos Sci Technol 58: 1011-1022. doi: 10.1016/S0266-3538(98)00078-5
|
| [37] |
Hashin Z (1980) Failure Criteria for Unidirectional Fiber Composites. J Appl Mech-T Asme 47: 329-334. doi: 10.1115/1.3153664
|
| [38] | Miner MA (1945) Cumulative Damage in Fatigue. J Appl Mech-T Asme 12: A159-A164. |
| [39] |
Van Paepegem W, Degrieck J (2002) Effects of load sequence and block loading on the fatigue response of fiber-reinforced composites. Mech Adv Mater Struc 9: 19-35. doi: 10.1080/153764902317224851
|
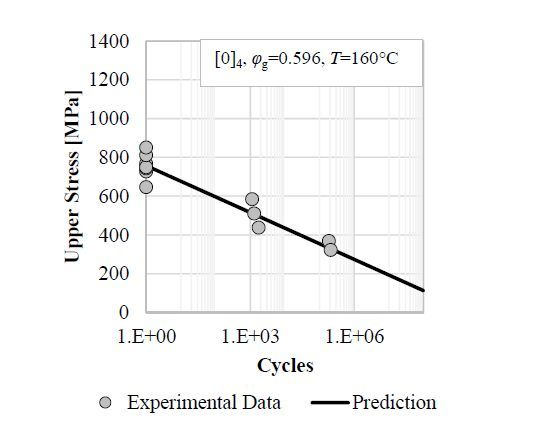
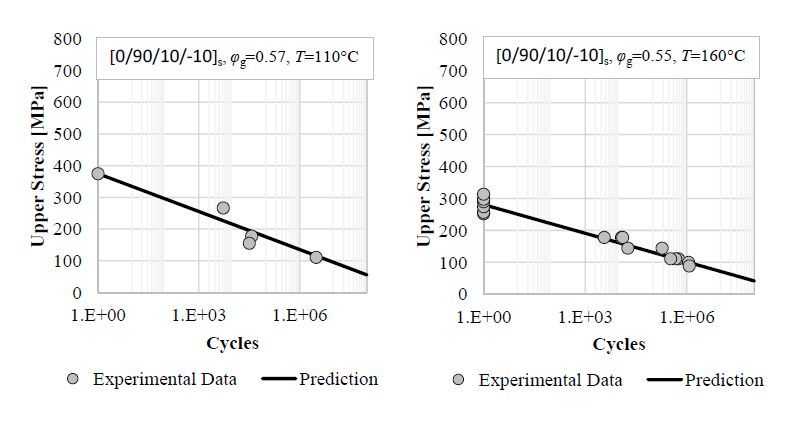
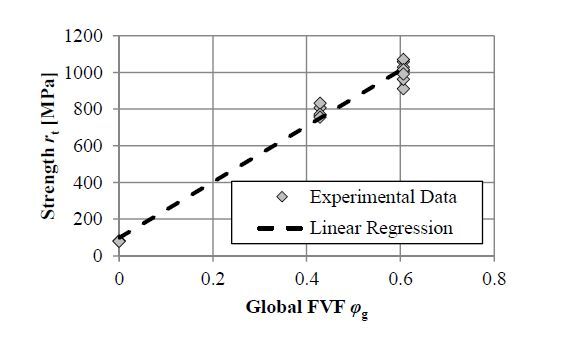
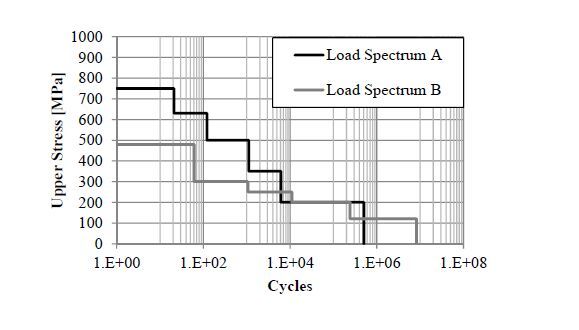
Figures(25) / Tables(5)

Dominik Flore, Konrad Wegener. Influence of fibre volume fraction and temperature on fatigue life of glass fibre reinforced plastics[J]. AIMS Materials Science, 2016, 3(3): 770-795. doi: 10.3934/matersci.2016.3.770







 DownLoad:
DownLoad: