Citation: Shahid Latif, Firuza Mustafa. Trivariate distribution modelling of flood characteristics using copula function—A case study for Kelantan River basin in Malaysia[J]. AIMS Geosciences, 2020, 6(1): 92-130. doi: 10.3934/geosci.2020007

| [1] | Rao AR, Hameed KH (2000) Flood frequency analysis. CRC Press, Boca Raton, Fla. |
| [2] | Zhang L (2005) Multivariate hydrological frequency analysis and risk mapping. Doctoral dissertation, Beijing Normal University. |
| [3] |
Ganguli P, Reddy MJ (2013) Probabilistic assessments of flood risks using trivariate copulas. Theor Appl Climatol 111: 341-360. doi: 10.1007/s00704-012-0664-4

|
| [4] |
Yue S (2000) The bivariate lognormal distribution to model a multivariate flood episode. Hydrol Processes 14: 2575-2588. doi: 10.1002/1099-1085(20001015)14:14<2575::AID-HYP115>3.0.CO;2-L
|
| [5] |
Yue S, Rasmussen P (2002) Bivariate frequency analysis: discussion of some useful concepts in hydrological applications. Hydrol Processes 16: 2881-2898. doi: 10.1002/hyp.1185
|
| [6] |
Yue S, Wang CY (2004) A comparison of two bivariate extreme value distribution. Stoch Environ Res Risk Assess 18: 61-66. doi: 10.1007/s00477-003-0124-x
|
| [7] |
Zhang L, Singh VP (2006) Bivariate flood frequency analysis using copula method. J Hydrol Eng 11: 150-164. doi: 10.1061/(ASCE)1084-0699(2006)11:2(150)
|
| [8] |
Zhang L, Singh VP (2007) Trivariate flood frequency analysis using the Gumbel-Hougaard copula. J Hydrol Eng 12: 431-439. doi: 10.1061/(ASCE)1084-0699(2007)12:4(431)
|
| [9] |
Reddy MJ, Ganguli P (2012) Bivariate Flood Frequency Analysis of Upper Godavari River Flows Using Archimedean Copulas. Water Resour Manage 26: 3995-4018. doi: 10.1007/s11269-012-0124-z
|
| [10] |
Salvadori G (2004) Bivariate return periods via-2 copulas. Stat Methodol 1: 129-144. doi: 10.1016/j.stamet.2004.07.002
|
| [11] |
Graler B, van den Berg M, Vandenberg S, et al. (2013) Multivariate return periods in hydrology: a critical and practical review focusing on synthetic design hydrograph estimation. Hydrol Earth Syst Sci 17: 1281-1296. doi: 10.5194/hess-17-1281-2013
|
| [12] |
Krstanovic PF, Singh VP (1987) A multivariate stochastic flood analysis using entropy. In: Singh VP (Ed.), Hydrologic Frequency Modelling, Baton Rouge, U.S.A., 515-539. doi: 10.1007/978-94-009-3953-0_37
|
| [13] |
Escalante-Sanboval CA, Raynal-Villasenor JA (1998) Multivariate estimation of floods: the trivariate gumble distribution. J Stat Comput Simul 61: 313-340. doi: 10.1080/00949659808811917
|
| [14] |
Sandoval CE, Raynal-Villasenor J (2008) Trivariate generalized extreme value distribution in flood frequency analysis. Hydrol Sci J 53: 550-567. doi: 10.1623/hysj.53.3.550
|
| [15] |
Song S, Singh VP (2010) Meta-elliptical copulas for drought frequency analysis of periodic hydrologic data. Environ Res Hazard Assess 24: 425-444. doi: 10.1007/s00477-009-0331-1
|
| [16] |
De Michele C, Salvadori G (2003) A generalized Pareto intensity-duration model of storm rainfall exploiting 2-copulas. J Geophys Res Atmos 108: 4067. doi: 10.1029/2002JD002534
|
| [17] |
Grimaldi S, Serinaldi F (2006) Asymmetric copula in multivariate flood frequency analysis. Adv Water Resour 29: 1155-1167. doi: 10.1016/j.advwatres.2005.09.005
|
| [18] |
Salvadori G, De Michele C (2006) Statistical characterization of temporal structure of storms. Adv Water Resour 29: 827-842. doi: 10.1016/j.advwatres.2005.07.013
|
| [19] | Saklar A (1959) Functions de repartition n dimensions et leurs marges. Publications de l'Institut de Statistique de l'Université de Paris 8: 229-231. |
| [20] | Nelsen RB (2006) An introduction to copulas, Springer, New York. |
| [21] |
Genest C, Favre AC (2007) Everything you always wanted to know about copula modelling but were afraid to ask. J Hydrol Eng 12: 347-368. doi: 10.1061/(ASCE)1084-0699(2007)12:4(347)
|
| [22] | Favre AC, El Adlouni S, Perreault L, et al. (2004) Multivariate hydrological frequency analysis using copulas. Water Resour Res 40. |
| [23] |
Renard B, Lang M (2007) Use of a Gaussian copula for multivariate extreme value analysis: Some case studies in hydrology. Adv Water Resour 30: 897-912. doi: 10.1016/j.advwatres.2006.08.001
|
| [24] |
Serinaldi F, Grimaldi S (2007) Fully nested 3-copula procedure and application on hydrological data. J Hydrol Eng 12: 420-430. doi: 10.1061/(ASCE)1084-0699(2007)12:4(420)
|
| [25] |
Genest C, Favre AC, Beliveau J, et al. (2007) Metaelliptical copulas and their use in frequency analysis of multivariate hydrological data. Water Resour Res 43: W09401. doi: 10.1029/2006WR005275
|
| [26] |
Li F, Zheng Q (2016) Probabilistic modelling of flood events using the entropy copula. Adv Water Resour 97: 233-240. doi: 10.1016/j.advwatres.2016.09.016
|
| [27] | Drainage and Irrigation Department Malaysia (2004) Annual flood report of DID for Peninsular Malaysia. Unpublished report. DID: Kuala Lumpur. |
| [28] | Malaysian Meteorological Department (2007) Report on Heavy Rainfall that Caused Floods in Kelantan and Terengganu. Unpublished report. MMD: Kuala Lumpur. |
| [29] |
Adnan NA, Atkinson PM (2011) Exploring the impact of climate and land use changes on streamflow trends in a monsoon catchment. Int J Climatol 31:815-831. doi: 10.1002/joc.2112
|
| [30] |
Madadgar S, Moradkhani H (2013) Drought Analysis under Climate Change Using Copula. J Hydrol Eng 18: 746-759. doi: 10.1061/(ASCE)HE.1943-5584.0000532
|
| [31] | Salvadori G, De Michele C (2010) Multivariate multiparameters extreme value models and return periods: A Copula approach. Water Resour Res 46. |
| [32] |
Shiau JT (2006) Fitting drought duration and severity with two dimensional copulas. Water Resour Manage 20: 795-815. doi: 10.1007/s11269-005-9008-9
|
| [33] |
Zhang R, Chen X, Cheng Q, et al. (2016) Joint probability of precipitation and reservoir storage for drought estimation in the headwater basin of the Huaihe River, China. Stoch Environ Res Risk Assess 30: 1641-1657. doi: 10.1007/s00477-016-1249-z
|
| [34] | Kamarunzaman IF, Zin WZW, Ariff NM (2018) A Generalized Bivariate Copula for Flood Analysis in Peninsular Malaysia. Preprints, 2018080118. |
| [35] | Couasnon A, Sebastian A, Morales-Napoles O (2018) A Copula-Based Bayesian Network for Modeling Compound Flood Hazard from Riverine and Coastal Interactions at the Catchment Scale: An Application to the Houston Ship Channel, Texas. Water 10: 1190. |
| [36] |
Genest C, Ghoudi K, Rivest LP (1995) A semiparametric estimation procedure of dependence parameters in multivariate families of distributions. Biometrika 82: 543-552. doi: 10.1093/biomet/82.3.543
|
| [37] |
Xu Y, Huang G, Fan Y (2015) Multivariate flood risk analysis for Wei River. Stoch Environ Res Risk Assess 31: 225-242. doi: 10.1007/s00477-015-1196-0
|
| [38] |
De Michele C, Salvadori G, Canossi M, et al. (2005) Bivariate statistical approach to check the adequacy of dam spillway. J Hydrol Eng 10: 50-57. doi: 10.1061/(ASCE)1084-0699(2005)10:1(50)
|
| [39] |
Klein B, Pahlow M, Hundecha Y, et al. (2010) Probability analysis of hydrological loads for the design of flood control system using copulas. J Hydrol Eng 15: 360-369. doi: 10.1061/(ASCE)HE.1943-5584.0000204
|
| [40] |
Genest C, Rémillard B (2008) Validity of the parametric bootstrap for goodness-of-fit testing in semiparametric models. Annales de l'Institut Henri Poincare: Probabilites et Statistiques 44: 1096-1127. doi: 10.1214/07-AIHP148
|
| [41] |
Genest C, Rémillard B, Beaudoin D (2009) Goodness-of-fit tests for copulas: A review and a power study. Insur Math Econ 44: 199-214. doi: 10.1016/j.insmatheco.2007.10.005
|
| [42] |
Kojadinovic I, Yan J, Holmes M (2011) Fast large-sample goodness-of-fit tests for copulas. Stat Sin 21: 841-871. doi: 10.5705/ss.2011.037a
|
| [43] |
Kojadinovic I, Yan J (2011) A goodness-of-fit test for multivariate multiparameter copulas based on multiplier central limit theorems. Stat Comput 21: 17-30. doi: 10.1007/s11222-009-9142-y
|
| [44] |
Zhang S, Okhrin O, Zhou QM, et al. (2016) Goodness-of-fit Test for Specification of Semiparametric Copula Dependence Models. J Econometrics 193: 215-233. doi: 10.1016/j.jeconom.2016.02.017
|
| [45] |
Salvadori G, De Michele C (2004) Frequency analysis via copulas: theoretical aspects and applications to hydrological events. Water Resour Res 40: W12511. doi: 10.1029/2004WR003133
|
| [46] |
Fisher NI, Switzer P (2001) Graphical assessments of dependence: is a picture worth 100 tests? Am Stat 55: 233-239. doi: 10.1198/000313001317098248
|
| [47] |
Genest C, Boies JC (2003) Detecting dependence with Kendall plots. Am Stat 57: 275-284. doi: 10.1198/0003130032431
|
| [48] |
Gringorten II (1963) A plotting rule of extreme probability paper. J Geophys Res 68: 813-814. doi: 10.1029/JZ068i003p00813
|
| [49] | Karmakar S, Simonovic SP (2008) Bivariate flood frequency analysis. Part-1: Determination of marginal by parametric and non-parametric techniques. J Flood Risk Manage 1: 190-200. |
| [50] |
Cohn TA, Lane WL, Baier WG (1997) An algorithm for computing moments-based flood quantile estimates when historical flood information is available. Water Resour Res 33: 2089-2096. doi: 10.1029/97WR01640
|
| [51] |
Hosking JRM, Walis JR (1987) Parameter and quantile estimations for the generalized Pareto distributions. Technometrics 29: 339-349. doi: 10.1080/00401706.1987.10488243
|
| [52] |
Anderson TW, Darling DA (1954) A test of goodness of fit. J Am Stat Assoc 49: 765-769. doi: 10.1080/01621459.1954.10501232
|
| [53] |
Akaike H (1974) A new look at the statistical model identification. IEEE Trans Autom Control 19: 716-723. doi: 10.1109/TAC.1974.1100705
|
| [54] |
Schwarz GE (1978) Estimating the dimension of a model. Ann Stat 6: 461-464. doi: 10.1214/aos/1176344136
|
| [55] | Hannan EJ, Quinn BG (1979) The Determination of the Order of an Autoregression. J R Stat Soc Series B Stat Methodol 41: 190-195. |
| [56] |
Moriasi DN, Arnold JG, Van Liew MW, et al. (2007) Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans ASABE 50: 885-900. doi: 10.13031/2013.23153
|
| [57] | Genest C, Huang W, Dufour JM (2013) A regularized goodness-of-fit test for copulas. J Soc Fr Stat 154: 64-77. |
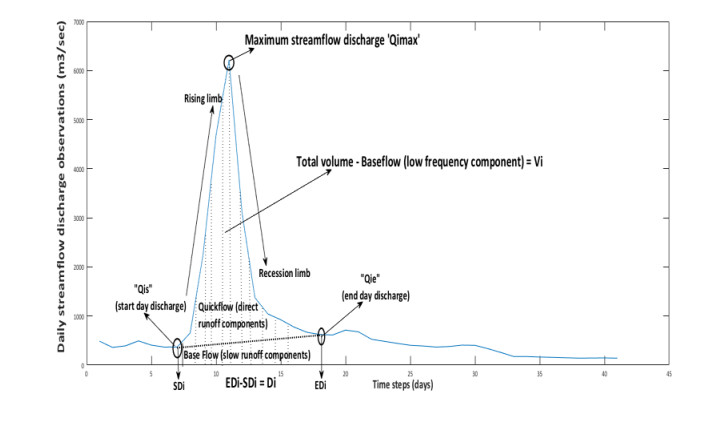
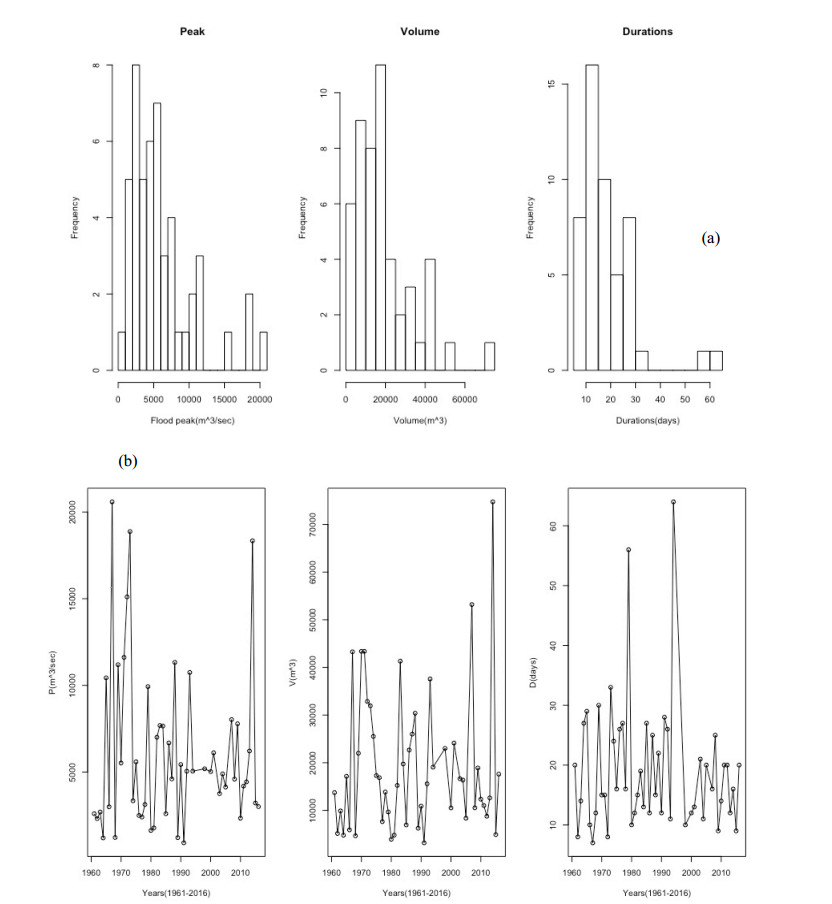
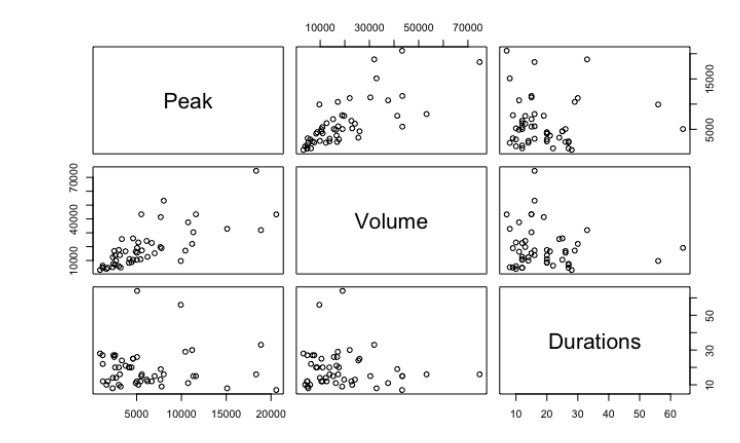
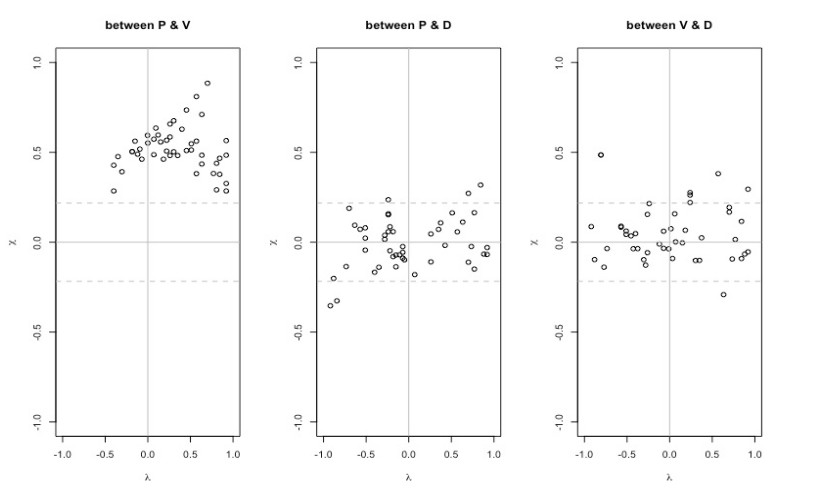
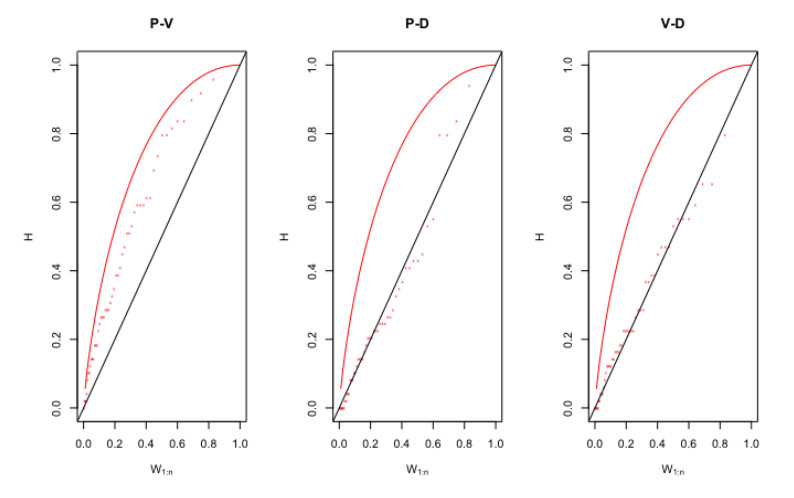
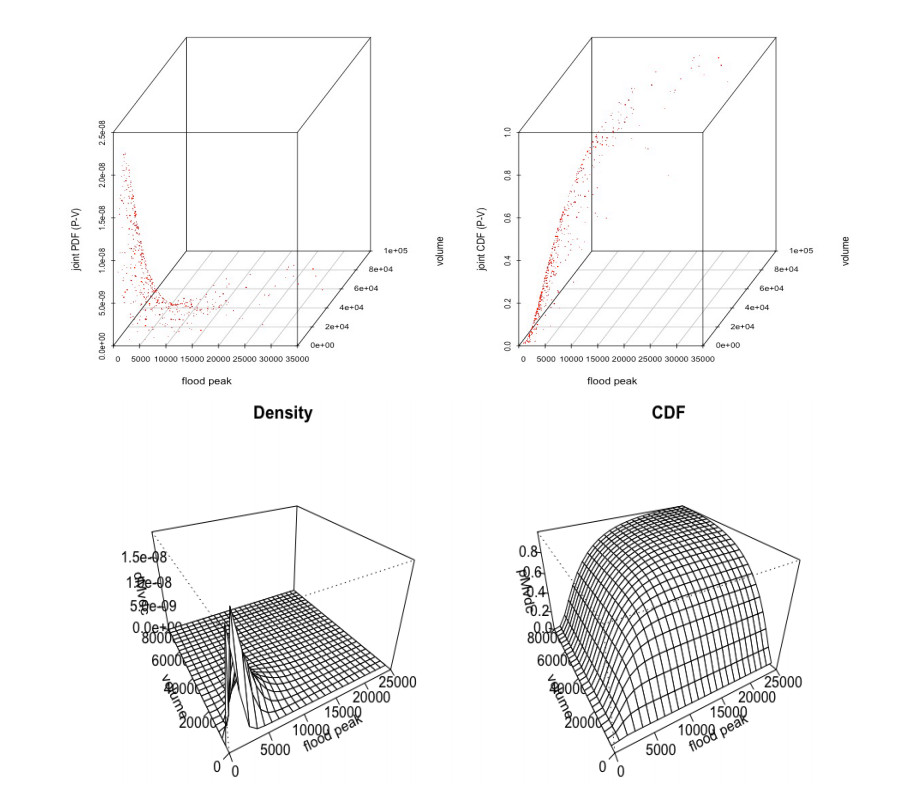
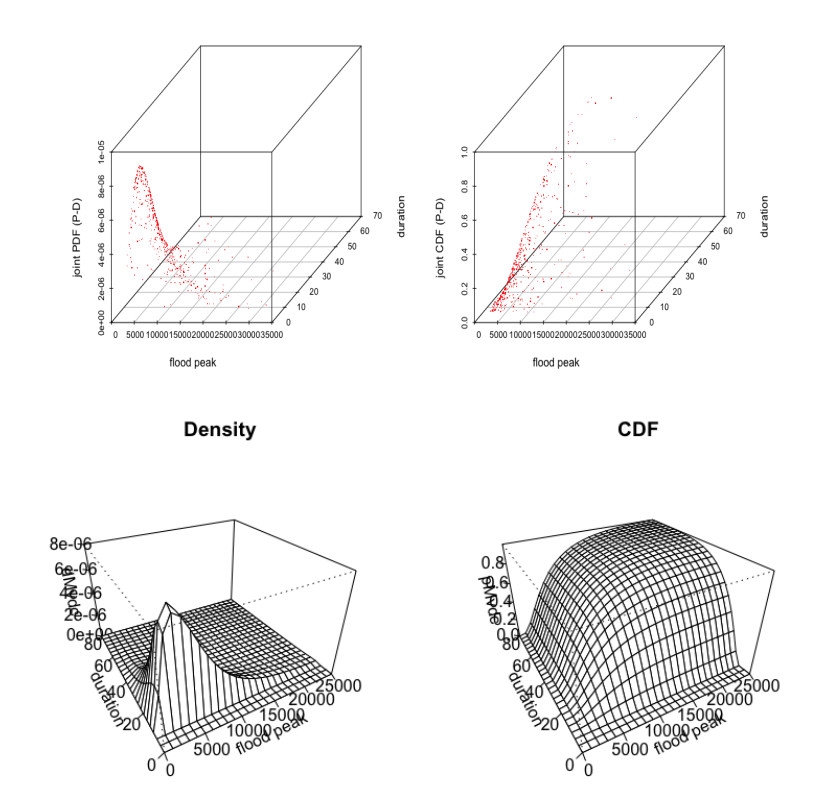
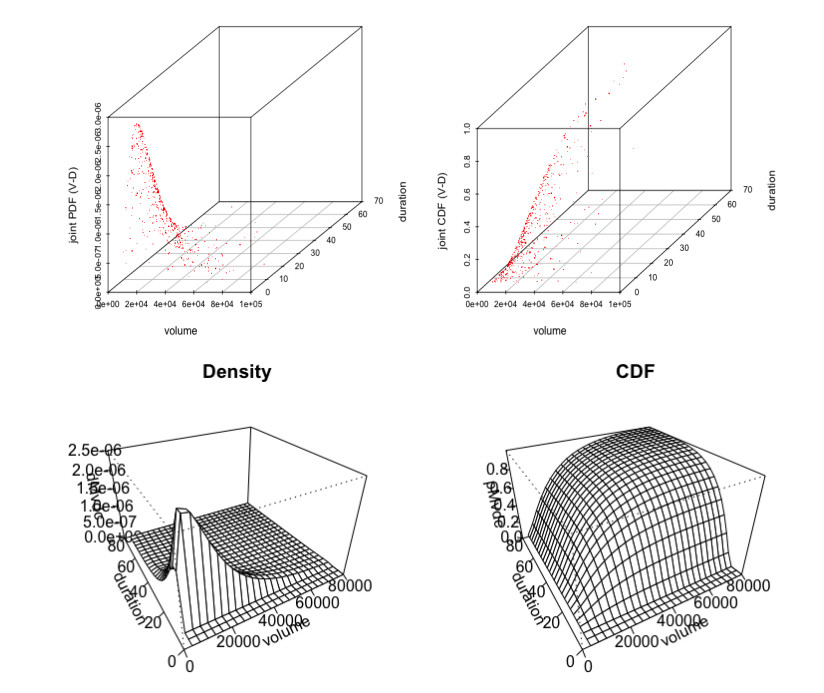
Figures(8) / Tables(14)

Shahid Latif, Firuza Mustafa. Trivariate distribution modelling of flood characteristics using copula function—A case study for Kelantan River basin in Malaysia[J]. AIMS Geosciences, 2020, 6(1): 92-130. doi: 10.3934/geosci.2020007







 DownLoad:
DownLoad: