Citation: Timothy P. Bata, Uriah Alexander Lar, Nuhu K. Samaila, Hyeladi U. Dibal, Raymond I. Daspan, Lekmang C. Isah, Ajol A. Fube, Simon Y. Ikyoive, Ezekiel H. Elijah, John Jitong Shirputda. Effect of biodegradation and water washing on oil properties[J]. AIMS Geosciences, 2018, 4(1): 21-35. doi: 10.3934/geosci.2018.1.21

| [1] |
Head IM, Jones DM, Larter SR (2003) Biological activity in the deep subsurface and the origin of heavy oil. Nature 426: 344–352. doi: 10.1038/nature02134

|
| [2] |
Larter S, Huang H, Adams J, et al. (2006) The controls on the composition of biodegraded oils in the deep subsurface: Part II-Geological controls on subsurface biodegradation fluxes and constraints on reservoir-fluid property prediction. AAPG Bull 90: 921–938. doi: 10.1306/01270605130
|
| [3] |
Krumholz LR, Mckinley JP, Ulrich GA, et al. (1997) Confined subsurface microbial communities in Cretaceous rock. Nature 386: 64–66. doi: 10.1038/386064a0
|
| [4] |
Bata T, Parnell J, Samaila NK, et al. (2015) Geochemical evidence for a Cretaceous oil sand (Bima oil sand) in the Chad Basin, Nigeria. J Afr Earth Sci 111: 148–155. doi: 10.1016/j.jafrearsci.2015.07.026
|
| [5] |
Bata T, Parnell J, Bowden S, et al. (2016) Origin of Heavy Oil in Cretaceous Petroleum Reservoirs. Bull Can Pet Geol 64: 106–118. doi: 10.2113/gscpgbull.64.2.106
|
| [6] | Bata T (2016) Geochemical Consequences of Cretaceous Sea Level Rise. Unpublished PhD thesis submitted to the Department of Geology and Petroleum Geology, University of Aberdeen. Available from: http://ethos.bl.uk/OrderDetails.do?uin=uk.bl.ethos.690589. |
| [7] |
López L (2014) Study of the biodegradation levels of oils from the Orinoco Oil Belt (Junin area) using different biodegradation scales. Org Geochem 66: 60–69. doi: 10.1016/j.orggeochem.2013.10.014
|
| [8] |
Wenger LM, Davis CL, Isaksen GH (2002) Multiple controls on petroleum biodegradation and impact in oil quality. SPE Reservoir Eval Eng 5: 375–383. doi: 10.2118/80168-PA
|
| [9] | Peters KE, Walters CC, Moldowan JM (2005) The Biomarker Guide: Biomarkers and isotopes in petroleum exploration and Earth history, v. 2. Biomarkers Isot Pet Syst Earth Hist Ed 2: 490. |
| [10] | Palmer SE (1984) Effect of water washing on C15+ hydrocarbon fraction of crude oils from northwest Palawan, Philippines. AAPG Bull 68: 137–149. |
| [11] |
Kuo LC (1994) An experimental study of crude oil alteration in reservoir rocks by water washing. Org Geochem 21: 465–479. doi: 10.1016/0146-6380(94)90098-1
|
| [12] | ASTM D4124, (2000) Standard test method for separation of asphalt into four fractions, In: American Society for Testing and Materials, West Conshohocken, PA. |
| [13] | ASTM D974-97, (2013) Standard test method for acid and base numbers by colour indicator titration, In: American Society for Testing and Materials, West Conshohocken, PA. |
| [14] |
Gouch MA, Rhead MM, Rowland SJ (1992) Biodegradation studies of unresolved complex mixtures of hydrocarbons: Model UCM hydrocarbons and the aliphatic UCM. Org Geochem 18: 17–22. doi: 10.1016/0146-6380(92)90139-O
|
| [15] |
Frysinger GS, Gaines RB, Xu L, et al. (2003) Resolving the unresolved complex mixture in petroleum-contained sediments. Environ Sci Technol 37: 1653–1662. doi: 10.1021/es020742n
|
| [16] |
Ventura GT, Kenig F, Reddy CM, et al. (2008) Analysis of unresolved complex mixtures of hydrocarbons extracted from Late Archean sediments by comprehensive two-dimensional gas chromatography (GC × GC). Org Geochem 39: 846–867. doi: 10.1016/j.orggeochem.2008.03.006
|
| [17] |
Parnell J, Bellis D, Feldmann J, et al. (2015) Selenium and tellurium enrichment in palaeo-oil reservoirs. J Geochem Explor 148: 169–173. doi: 10.1016/j.gexplo.2014.09.006
|
| [18] |
Bennett B, Adams JJ, Gray ND, et al. (2013) The controls on the composition of biodegraded oils in the deep subsurface-Part 3: The impact of microorganism distribution on petroleum geochemical gradients in biodegraded petroleum reservoirs. Org Geochem 56: 94–105. doi: 10.1016/j.orggeochem.2012.12.011
|
| [19] | Head IM, Gray ND, Larter SR (2014) Life in the slow lane; biogeochemistry of biodegraded petroleum containing reservoirs and implications for energy recovery and carbon management. Front Microbiol 5: 1–23. |
| [20] |
Wenger LM, Davis CL, Isaksen GH (2002) Multiple controls on petroleum biodegradation and impact in oil quality. SPE Reservoir Eval Eng 5: 375–383. doi: 10.2118/80168-PA
|
| [21] | Xinheng C, Songbai T (2011) Review and comprehensive analysis of composition and origin of high acidity crude oils. China Pet Process Petrochem Technol 13: 6–15. |
| [22] | Behar FH, Albrecht P (1984) Correlations between carboxylic acids and hydrocarbons in several crude oils. Alteration by biodegradation. Org Geochem 6: 597–604. |
| [23] |
Jaffé R, Gallardo M (1993) Application of carboxylic acid biomarkers as indicators of biodegradation and migration of crude oils from the Maracaibo Basin, western Venezuela. Org Geochem 20: 973–984. doi: 10.1016/0146-6380(93)90107-M
|
| [24] | Olsen SD, (1998) The relationship between biodegradation, total acid number (TAN) and metals in oils, In: Preprints of the American Chemical Society, Division of Petroleum Chemistry, 3: 142–145. |
| [25] |
Meredith W, Kelland SJ, Jones DM (2000) Influence of biodegradation on crude oil acidity and carboxylic acid composition. Org Geochem 31: 1059–1073. doi: 10.1016/S0146-6380(00)00136-4
|
| [26] | Mackenzie AS, Wolff GA, Maxwell JR, (1983) Fatty acids in biodegraded petroleums. Possible origins and significance, In: Bjorøy M, et al., Eds., Advances in Organic Geochemistry, John Wiley, Chichester, UK, 637–649. |
| [27] | Montgomery W, Sephton MA, Watson JS, et al. (2015) Minimising hydrogen sulphide generation during steam assisted production of heavy oil. Sci Rep 5: 1–6. |
| [28] |
Milner CWD, Rogers MA, Evans CR (1977) Petroleum transformations in reservoirs. J Geochem Explor 7: 101–153. doi: 10.1016/0375-6742(77)90079-6
|
| [29] | Connan J (1984) Biodegradation of crude oils in reservoirs. In: Brooks J, Welte DH, Eds., Advances in Petroleum Geochemistry 1, London: Academic Press, 299–335. |
| [30] | Palmer SE (1993) Effect of biodegradation and water washing on crude oil composition. In: M.H. Engel, S.A. Macko, Eds., Organic Geochemistry, Plenum, New York, 861. |
| [31] | Jones DM, Head IM, Gray ND, et al. (2008) Crude oil biodegradation via methanogenesis in subsurface petroleum reservoirs. Nature 451: 170–180. |
| [32] | Larter SR, Head IM, Bennett B, et al. (2013) The roles of water in subsurface petroleum biodegradation-Part 1. The role of water radiolysis. Geoconvention Integr 1–4. |
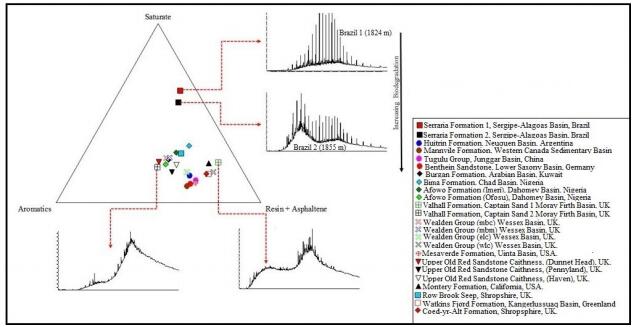
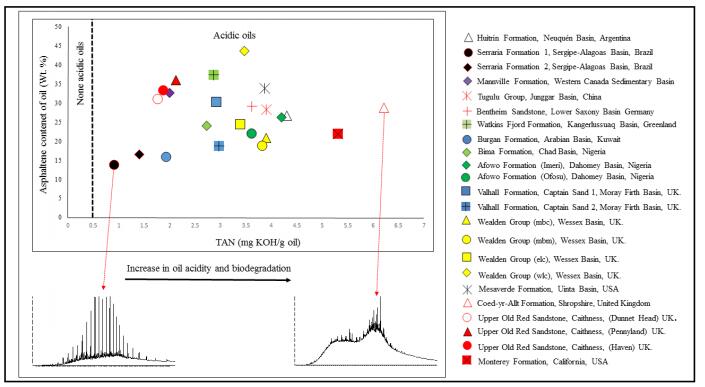
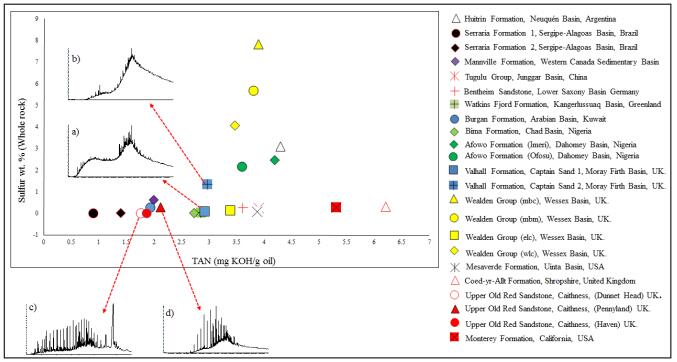
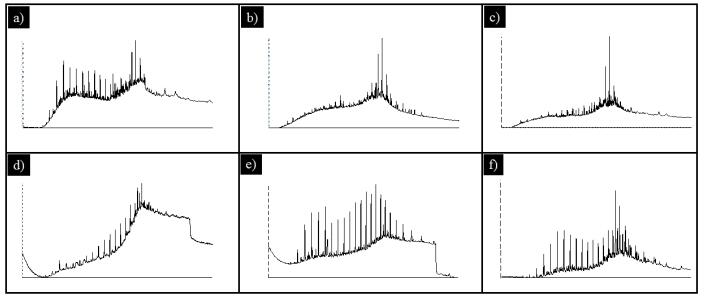
Figures(6) / Tables(1)

Timothy P. Bata, Uriah Alexander Lar, Nuhu K. Samaila, Hyeladi U. Dibal, Raymond I. Daspan, Lekmang C. Isah, Ajol A. Fube, Simon Y. Ikyoive, Ezekiel H. Elijah, John Jitong Shirputda. Effect of biodegradation and water washing on oil properties[J]. AIMS Geosciences, 2018, 4(1): 21-35. doi: 10.3934/geosci.2018.1.21







 DownLoad:
DownLoad: