Citation: Romilda Z. Boerleider, Nel Roeleveld, Paul T.J. Scheepers. Human biological monitoring of mercury for exposure assessment[J]. AIMS Environmental Science, 2017, 4(2): 251-276. doi: 10.3934/environsci.2017.2.251

| [1] |
Counter SA, Buchanan LH (2004) Mercury exposure in children: a review. Toxicol Appl Pharmacol 198: 209-230. doi: 10.1016/j.taap.2003.11.032

|
| [2] |
Bose-O'Reilly S, McCarty KM, Steckling N, et al. (2010) Mercury exposure and children's health. Curr Probl Pediatr Adolesc Health Care 40: 186-215. doi: 10.1016/j.cppeds.2010.07.002
|
| [3] | UNEP (United Nations Environment Programme), Mercury, Negotiations: The Mercury, Negotiations: The Negotiating Process, 2013. Available from: http://www.unep.org/hazardoussubstances/Mercury/Negotiations/tabid/3320/Default.aspx |
| [4] | WHO (World Health Organisation), Mercury and health, 2008. Available from: http://www.who.int/mediacentre/factsheets/fs361/en/. |
| [5] | U.S. EPA (Environmental Protection Agency) (1990) An assessment of exposure to mercury in the United States. Washington: EPA. |
| [6] | United Nations Environment Programme-Chemicals, Global mercury assessment. UNEP Chemicals, 2002. Available from: http://www.unep.org/gc/gc22/Document/UNEP-GC22-INF3.pdf. |
| [7] |
Sandborgh-Englund G, Elinder CG, Johanson G, et al. (1998) The absorption, blood levels, and excretion of mercury after a single dose of mercury vapor in humans. Toxicol Appl Pharmacol 150: 146-153. doi: 10.1006/taap.1998.8400
|
| [8] | Kudsk FN (1965) Absorption of mercury vapour from the respiratory tract in man. Acta Pharmacol Toxicol (Copenh) 23: 250-262. |
| [9] |
AlSaleh I, AlDoush I (1997) Mercury content in skin-lightening creams and potential hazards to the health of Saudi women. J Toxicol Environ Health 51: 123-130. doi: 10.1080/00984109708984016
|
| [10] | WHO, Guidance for identifying populations at risk from mercury exposure. UNEP DTIE Chemicals Branch, 2008. Avaliable from: http://www.who.int/foodsafety/publications/risk-mercury-exposure/en/. |
| [11] |
Hursh JB, Clarkson TW, Miles EF, et al. (1989) Percutaneous absorption of mercury vapor by man. Arch Environ Health 44: 120-127. doi: 10.1080/00039896.1989.9934385
|
| [12] |
Bose-O'Reilly S, Lettmeier B, Gothe RM, et al. (2008) Mercury as a serious health hazard for children in gold mining areas. Environ Res 107: 89-97. doi: 10.1016/j.envres.2008.01.009
|
| [13] | Agency for Toxic Substances and Disease Registry (ATSDR), Toxicological Profile for Mercury. US Department of Health and Human Services, Public Health Service, ATSDR, 1999. Available from: http://www.atsdr.cdc.gov/toxprofiles/tp46.html. |
| [14] | Gibb H, O'Leary KG (2014) Mercury Exposure and Health Impacts among Individuals in the Artisanal and Small-Scale Gold Mining Community: A Comprehensive Review. Environ Health Perspect 122: 667-672. |
| [15] |
Marsh DO, Myers GJ, Clarkson TW, et al. (1980) Fetal methylmercury poisoning: clinical and toxicological data on 29 cases. Ann Neurol 7: 348-353. doi: 10.1002/ana.410070412
|
| [16] | Solan TD, Lindow SW (2014) Mercury exposure in pregnancy: a review. J Perinat Med 42: 725-729. |
| [17] |
Axelrad DA, Bellinger DC, Ryan LM, et al. (2007) Dose-response relationship of prenatal mercury exposure and IQ: an integrative analysis of epidemiologic data. Environ Health Perspect 115: 609-615. doi: 10.1289/ehp.9303
|
| [18] | Jacobson JL, Muckle G, Ayotte P, et al. (2015) Relation of prenatal methylmercury exposure from environmental sources to childhood IQ. Environ Health Perspect 123: 827-833. |
| [19] |
Bellinger DC, O'Leary K, Rainis H, et al. (2016) Country-specific estimates of the incidence of intellectual disability associated with prenatal exposure to methylmercury. Environ Res 147: 159-163. doi: 10.1016/j.envres.2015.10.006
|
| [20] |
Snoj Tratnik J, Falnoga I, Trdin A, et al. (2017) Prenatal mercury exposure, neurodevelopment and apolipoprotein E genetic polymorphism. Environ Res 152: 375-385. doi: 10.1016/j.envres.2016.08.035
|
| [21] |
Angerer J, Ewers U, Wilhelm M (2007) Human biomonitoring: state of the art. Int J Hyg Environ Health 210: 201-228. doi: 10.1016/j.ijheh.2007.01.024
|
| [22] |
Schulz C, Angerer J, Ewers U, et al. (2007) The German human biomonitoring commission. Int J Hyg Environ Health 210: 373-382. doi: 10.1016/j.ijheh.2007.01.035
|
| [23] |
Scheepers PTJ, Bos PMJ, Konings J, et al. (2011) Application of biological monitoring for exposure assessment following chemical incidents: A procedure for decision making. J Expo Sci Environ Epidemiol 21: 247-261. doi: 10.1038/jes.2010.4
|
| [24] |
Scheepers PT, van Ballegooij-Gevers M, Jans H (2014) Biological monitoring involving children exposed to mercury from a barometer in a private residence. Toxicol Lett 231: 365-373. doi: 10.1016/j.toxlet.2014.03.017
|
| [25] |
Krystek P, Favaro P, Bode P, et al. (2012) Methyl mercury in nail clippings in relation to fish consumption analysis with gas chromatography coupled to inductively coupled plasma mass spectrometry: a first orientation. Talanta 97: 83-86. doi: 10.1016/j.talanta.2012.03.065
|
| [26] |
Sakamoto M, Murata K, Domingo JL, et al. (2016) Implications of mercury concentrations in umbilical cord tissue in relation to maternal hair segments as biomarkers for prenatal exposure to methylmercury. Environ Res 149: 282-287. doi: 10.1016/j.envres.2016.04.023
|
| [27] |
Sandborgh-Englund G, Einarsson C, Sandstrom M, et al. (2004) Gastrointestinal absorption of metallic mercury. Arch Environ Health 59: 449-454. doi: 10.1080/00039890409603424
|
| [28] | ACGIH (2013) Biological exposure index (BEI) documentation. American Conference of Governmental Industrial Hygienists, Cincinnati, OH. |
| [29] |
Hursh JB, Cherian MG, Clarkson TW, et al. (1976) Clearance of mercury (HG-197, HG-203) vapor inhaled by human subjects. Arch Environ Health 31: 302-309. doi: 10.1080/00039896.1976.10667240
|
| [30] |
Magos L, Halbach S, Clarkson TW (1978) Role of catalase in the oxidation of mercury vapor. Biochem Pharmacol 27: 1373-1377. doi: 10.1016/0006-2952(78)90122-3
|
| [31] |
Piotrowski JK, Trojanowska B, Wisniewska-Knypl JM, et al. (1974) Mercury binding in the kidney and liver of rats repeatedly exposed to mercuric chloride: induction of metallothionein by mercury and cadmium. Toxicol Appl Pharmacol 27: 11-19. doi: 10.1016/0041-008X(74)90169-0
|
| [32] |
Cherian MG, Hursh JB, Clarkson TW, et al. (1978) Radioactive mercury distribution in biological fluids and excretion in human subjects after inhalation of mercury vapor. Arch Environ Health 33: 109-114. doi: 10.1080/00039896.1978.10667318
|
| [33] |
Jonsson F, Sandborgh-Englund G, Johanson G (1999) A compartmental model for the kinetics of mercury vapor in humans. Toxicol Appl Pharmacol 155: 161-168. doi: 10.1006/taap.1998.8585
|
| [34] | International Agency for Research on Cancer (IARC), 2012. Agents reviewed by the IARC monographs, volumes 1-116. |
| [35] |
Clarkson TW, Magos L (2006) The toxicology of mercury and its chemical compounds. Crit Rev Toxicol 36: 609-662. doi: 10.1080/10408440600845619
|
| [36] |
Pogarev SE, Ryzhov V, Mashyanov N, et al. (2002) Direct measurement of the mercury content of exhaled air: a new approach for determination of the mercury dose received. Anal Bioanal Chem 374: 1039-1044. doi: 10.1007/s00216-002-1601-7
|
| [37] | Nakaaki K, Fukabori S, Tjada O (1978) On the evaluation of mercury exposure-A proposal of the standard value for health care of workers. J Sci Labour 54: 1-8. |
| [38] | National Research Council (2000) Toxicological Effects of Mercury. Washington, D.C.: National Academy Press. |
| [39] | Schaller KH, (1988) Mercury, In: Angerer, J, Schaller, K.H. Author, Analyses of hazardous Substances in Biological Materials, Vol 2, Weinheim: VCH, 195-211. |
| [40] | Anthemidis AN, Zachariadis GA, Michos CE, et al. (2004) Time-based on-line preconcentration cold vapour generation procedure for ultra-trace mercury determination with inductively coupled plasma atomic emission spectrometry. Anal Bioanal Chem 379: 764-769. |
| [41] |
Bergdahl IA, Schutz A, Hansson GA (1995) Automated determination of inorganic mercury in blood after sulfuric acid treatment using cold vapour atomic absorption spectrometry and an inductively heated gold trap. Analyst 120: 1205-1209. doi: 10.1039/AN9952001205
|
| [42] |
Anthemidis AN, Zachariadis GA, Stratis JA (2004) Development of a sequential injection system for trace mercury determination by cold vapour atomic absorption spectrometry utilizing an integrated gas-liquid separator/reactor. Talanta 64: 1053-1057. doi: 10.1016/j.talanta.2004.05.003
|
| [43] |
Pellizzari ED, Fernando R, Cramer GM, et al. (1999) Analysis of mercury in hair of EPA region V population. J Expo Anal Environ Epidemiol 9: 393-401. doi: 10.1038/sj.jea.7500056
|
| [44] |
McDowell MA, Dillion CF, Osterloh J, et al. (2004) Hair mercury levels in US children and women of childbearing age: reference range data from NHANES 1999-2000. Environ Health Perspect 112: 1165-1171. doi: 10.1289/ehp.7046
|
| [45] | Deutsche Forschungsgemeinschaft (DFG), (2005) Addendum to Mercury and its Inorganic Compounds, In: BAT Value Documentations, Vol 5, Weinheim: Wiley-VCH, 71-115. |
| [46] |
Schulz C, Wilhelm M, Heudorf U, et al. (2011) Update of the reference and HBM values derived by the German Human Biomonitoring Commission. Int J Hyg Environ Health 215: 26-35. doi: 10.1016/j.ijheh.2011.06.007
|
| [47] | Carpi A, Lindberg SE, Prestbo EM, et al. (1997) Methyl mercury contamination and emission to the atmosphere from soil amended with municipal sewage sludge. J Environ Qual 26: 1650-1655. |
| [48] |
Halbach S (1985) The octanol/water distribution of mercury compounds. Arch Toxicol 57: 139-141. doi: 10.1007/BF00343125
|
| [49] | National Research Council (US) Committee on the Toxicological Effects of Methylmercury, (2000) Toxicological Effects of Methylmercury. Washington DC: National Academies Press (US). |
| [50] |
Skerfving S (1988) Mercury in women exposed to methylmercury through fish consumption, and in their newborn babies and breast milk. Bull Environ Contam Toxicol 41: 475-482. doi: 10.1007/BF02020989
|
| [51] | Bernhoft RA (2012) Mercury toxicity and treatment: a review of the literature. J Environ Public Health 2012: 1-10. |
| [52] |
Aberg B, Ekman L, Falk R, et al. (1969) Metabolism of methyl mercury (203Hg) compounds in man. Arch Environ Health 19: 478-484. doi: 10.1080/00039896.1969.10666872
|
| [53] | Bernard SR, Purdue P (1984) Metabolic models for methyl and inorganic mercury. Health Phys 46: 695-699. |
| [54] | Miettinen JK, Rahola T, Hattula T, et al. (1971) Elimination of 203Hg-methylmercury in man. Ann Clin Res 3: 116-122. |
| [55] | Poulin J, Gibb H (2008) Mercury: assessing the burden of disease at national and local levels, In: Prüss-Üstün, A. Editor, Environmental Burden of Disease Series, No. 16, Geneva: WHO (World Health Organization), Available from: |
| [56] |
Clarkson TW (1993) Mercury: major issues in environmental health. Environ Health Perspect 100: 31-38. doi: 10.1289/ehp.9310031
|
| [57] |
Kershaw TG, Clarkson TW, Dhahir PH (1980) The relationship between blood levels and dose of methylmercury in man. Arch Environ Health 35: 28-36. doi: 10.1080/00039896.1980.10667458
|
| [58] |
Sherlock J, Hislop J, Newton D, et al. (1984) Elevation of mercury in human blood from controlled chronic ingestion of methylmercury in fish. Hum Exp Toxicol 3: 117-131. doi: 10.1177/096032718400300205
|
| [59] |
Cox C, Clarkson TW, Marsh DO, et al. (1989) Dose-response analysis of infants prenatally exposed to methyl mercury: an application of a single compartment model to single-strand hair analysis. Environ Res 49: 318-332. doi: 10.1016/S0013-9351(89)80075-1
|
| [60] |
Cooper GA, Kronstrand R, Kintz P, et al. (2012) Society of hair testing guidelines for drug testing in hair. Forensic Sci Int 218: 20-24. doi: 10.1016/j.forsciint.2011.10.024
|
| [61] |
Stern AH, Smith AE (2003) An assessment of the cord blood: maternal blood methylmercury ratio: implications for risk assessment. Environ Health Perspect 111: 1465-1470. doi: 10.1289/ehp.6187
|
| [62] |
Bose-O'Reilly S, Drasch G, Beinhoff C, et al. (2010) Health assessment of artisanal gold miners in Indonesia. Sci Total Environ 408: 713-725. doi: 10.1016/j.scitotenv.2009.10.070
|
| [63] |
Kim BG, Jo EM, Kim GY, et al. (2012) Analysis of methylmercury concentration in the blood of koreans by using cold vapor atomic fluorescence spectrophotometry. Ann Lab Med 32: 31-37. doi: 10.3343/alm.2012.32.1.31
|
| [64] |
Akagi H, Malm O, Kinjo Y, et al. (1995) Methylmercury pollution in the Amazon, Brazil. Sci Total Environ 175: 85-95. doi: 10.1016/0048-9697(95)04905-3
|
| [65] |
Malm O, Branches FJ, Akagi H, et al. (1995) Mercury and methylmercury in fish and human hair from the Tapajos river basin, Brazil. Sci Total Environ 175: 141-150. doi: 10.1016/0048-9697(95)04910-X
|
| [66] |
Yamamoto R, Suzuki T (1978) Effects of artificial hair-waving on hair mercury values. Int Arch Occup Environ Health 42: 1-9. doi: 10.1007/BF00385706
|
| [67] |
Yamaguchi S, Matsumoto H, Kaku S, et al. (1975) Factors affecting the amount of mercury in human scalp hair. Am J Public Health 65: 484-488. doi: 10.2105/AJPH.65.5.484
|
| [68] | Nuttall KL (2006) Interpreting hair mercury levels in individual patients. Ann Clin Lab Sci 36: 248-261. |
| [69] | Sherman LS, Blum JD, Franzblau A, et al. (2013) New insight into biomarkers of human mercury exposure using naturally occurring mercury stable isotopes. Environ Sci Technol 47: 3403-3409. |
| [70] | IPCS (International Programme on Chemical Safety) (2000) Environmental health criteria 214, Human exposure assessment. World Health Organization, Geneva. Available from: http://www.inchem.org/documents/ehc/ehc/ehc214.htm. |
| [71] |
Johnsson C, Schutz A, Sallsten G (2005) Impact of consumption of freshwater fish on mercury levels in hair, blood, urine, and alveolar air. J Toxicol Environ Health Part A 68: 129-140. doi: 10.1080/15287390590885992
|
| [72] | Obi E, Okafor C, Igwebe A, et al. (2015) Elevated prenatal methylmercury exposure in Nigeria: Evidence from maternal and cord blood. Chemosphere 119: 485-489. |
| [73] | Mahaffey KR, Clickner RP, Bodurow CC (2004) Blood organic mercury and dietary mercury intake: national health and nutrition examination survey, 1999 and 2000. Environ Health Perspect 112: 562-570. |
| [74] |
Grandjean P, Budtz-Jorgensen E, White RF, et al. (1999) Methylmercury exposure biomarkers as indicators of neurotoxicity in children aged 7 years. Am J Epidemiol 150: 301-305. doi: 10.1093/oxfordjournals.aje.a010002
|
| [75] |
Grandjean P, Budtz-Jorgensen E, Jorgensen PJ, et al. (2005) Umbilical cord mercury concentration as biomarker of prenatal exposure to methylmercury. Environ Health Perspect 113: 905-908. doi: 10.1289/ehp.7842
|
| [76] |
Kristensen AK, Thomsen JF, Mikkelsen S (2014) A review of mercury exposure among artisanal small-scale gold miners in developing countries. Int Arch Occup Environ Health 87: 579-590. doi: 10.1007/s00420-013-0902-9
|
| [77] | Clarkson TW (2002) The three modern faces of mercury. Environ Health Perspect 110(Suppl 1): 11-23. |
| [78] | Tsuji JS, Williams PRD, Edwards MR, et al. (2003) Evaluation of mercury in urine as an indicator of exposure to low levels of mercury vapor. Environ Health Perspect 111: 623-630. |
| [79] | Nuttall KL (2004) Interpreting mercury in blood and urine of individual patients. Ann Clin Lab Sci 34: 235-250. |
| [80] | Jung RC, Aaronson J (1980) Death following inhalation of mercury vapor at home. West J Med 132: 539-543. |
| [81] |
Wilhelm M, Schulz C, Schwenk M (2006) Revised and new reference values for arsenic, cadmium, lead, and mercury in blood or urine of children: basis for validation of human biomonitoring data in environmental medicine. Int J Hyg Environ Health 209: 301-305. doi: 10.1016/j.ijheh.2006.01.004
|
| [82] |
Davidson PW, Myers GJ, Cox C, et al. (1998) Effects of prenatal and postnatal methylmercury exposure from fish consumption on neurodevelopment: outcomes at 66 months of age in the Seychelles child development study. JAMA 280: 701-707. doi: 10.1001/jama.280.8.701
|
| [83] | IPCS (International Programme on Chemical Safety) (1990) Environmental Health Criteria 101, Methylmercury. World Health Organization, Geneva. Available from: http://www.inchem.org/documents/ehc/ehc/ehc101.htm |
| [84] |
Díez S, Montuori P, Pagano A, et al. (2008) Hair mercury levels in an urban population from southern Italy: Fish consumption as a determinant of exposure. Environ Int 34: 162-167. doi: 10.1016/j.envint.2007.07.015
|
| [85] | Cernichiari E, Brewer R, Myers GJ, et al. (1995) Monitoring methylmercury during pregnancy: maternal hair predicts fetal brain exposure. Neurotoxicology 16: 705-710. |
| [86] | Crump KS, Van Landingham C, Shamlaye C, et al. (2000) Benchmark concentrations for methylmercury obtained from the Seychelles Child Development Study. Environ Health Perspect 108: 257-263. |
| [87] |
Liberda EN, Tsuji LJ, Martin ID, et al. (2014) The complexity of hair/blood mercury concentration ratios and its implications. Environ Res 134: 286-294. doi: 10.1016/j.envres.2014.08.007
|
| [88] |
Ha E, Basu N, Bose-O'Reilly S, et al. (2017) Current progress on understanding the impact of mercury on human health. Environ Res 152: 419-433. doi: 10.1016/j.envres.2016.06.042
|
| [89] |
Yaginuma-Sakurai K, Murata K, Iwai-Shimada M, et al. (2012) Hair-to-blood ratio and biological half-life of mercury: experimental study of methylmercury exposure through fish consumption in humans. J Toxicol Sci 37: 123-130. doi: 10.2131/jts.37.123
|
| [90] | Queipo AS, Rodríguez-González P, García Alonso JI.(2016) Evidence of the direct adsorption of mercury in human hair during occupational exposure to mercury vapour. J Trace Elem Med Biol 36: 16-21. |
| [91] | Veiga MM, Baker RF (2004) Protocols for Environmental and Health Assessment of Mercury Released by Artisanal and Small-scale Gold Miners. Vienna: GEF/UNDP/UNIDO Global Mercury Project. |
| [92] |
Myers GJ, Davidson PW, Cox C, et al. (2003) Prenatal methylmercury exposure from ocean fish consumption in the Seychelles child development study. Lancet 361: 1686-1692. doi: 10.1016/S0140-6736(03)13371-5
|
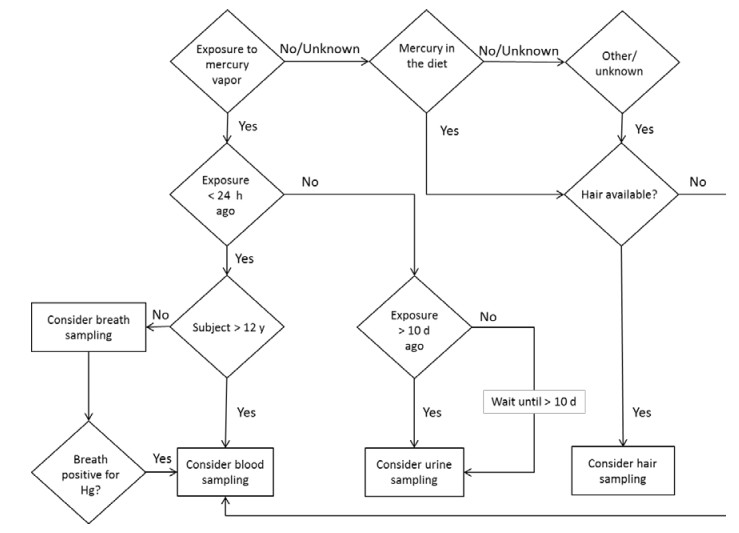
Figures(1) / Tables(3)

Romilda Z. Boerleider, Nel Roeleveld, Paul T.J. Scheepers. Human biological monitoring of mercury for exposure assessment[J]. AIMS Environmental Science, 2017, 4(2): 251-276. doi: 10.3934/environsci.2017.2.251







 DownLoad:
DownLoad: